新卒データアナリストがデータエンジニアになるまで

はじめに
こんにちは。分析グループでデータエンジニアをしている小池です。新卒入社した前職では主にサービスグロースのための分析を行っていたのですが、現職ではデータ分析基盤の開発をしています。平たくいえば、データアナリストからデータエンジニアへキャリアチェンジしたというわけです。この記事では、私がデータアナリストからデータエンジニアになるまでのお話をしていければと思います。
データアナリストやデータエンジニアとは
データアナリストとデータエンジニアの責務がわからないかたもいらっしゃると思いますので、まずはそこから説明します。それぞれの職種の責務は次の図のようになっています。
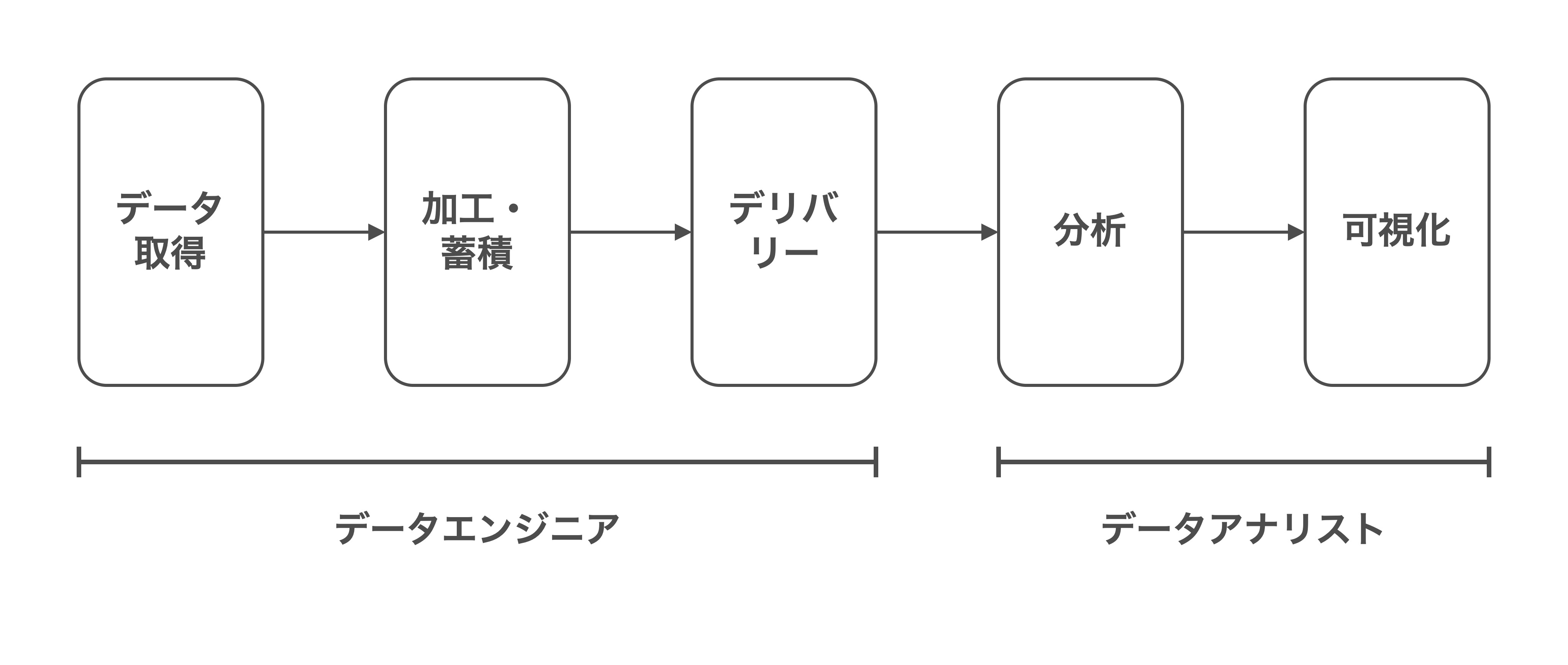
データエンジニアは、データアナリストが集計・分析するためのデータを用意する役割を担います。具体的な業務内容としては次のようになります。
- 他システム、別データソースからのデータ取得
- 1で取得したデータをデータアナリストが使いやすいような形に加工
- 2で加工したデータにデータアナリストがアクセスできるようデリバリー
対して、データアナリストはデータを集計・分析し、ビジネスをどう改善すればよいか示唆出しをする役割を担っています。具体的な業務内容としては次のようになります。
- データエンジニアが用意したデータをSQLなどを用いて集計
- 1で集計したデータを分析
- 2で分析した結果を元にビジネスをどう改善すればよいか示唆出し
あるいは、次のような業務も行います。
- データエンジニアが用意したデータをSQLなどを用いて集計
- 1で集計したデータをダッシュボードにまとめ、データを定点観測できる環境を整備
なんとなくイメージはつかめたでしょうか?
これを踏まえて、この記事では私がデータアナリストからデータエンジニアへとキャリアチェンジし駆け出しデータエンジニアとして駆けてゆくさまをお見せできればと思います。同じくデータエンジニアへキャリアチェンジしようとしているかたがたの参考になれば幸いです。
KINTOテクノロジーズのデータアーキテクチャ
データ基盤の開発についての話をする前に、まずは当社のデータアーキテクチャについて説明します。主にAWSのサービスを用いて構成されており、大まかなデータの流れは次のようになっています。
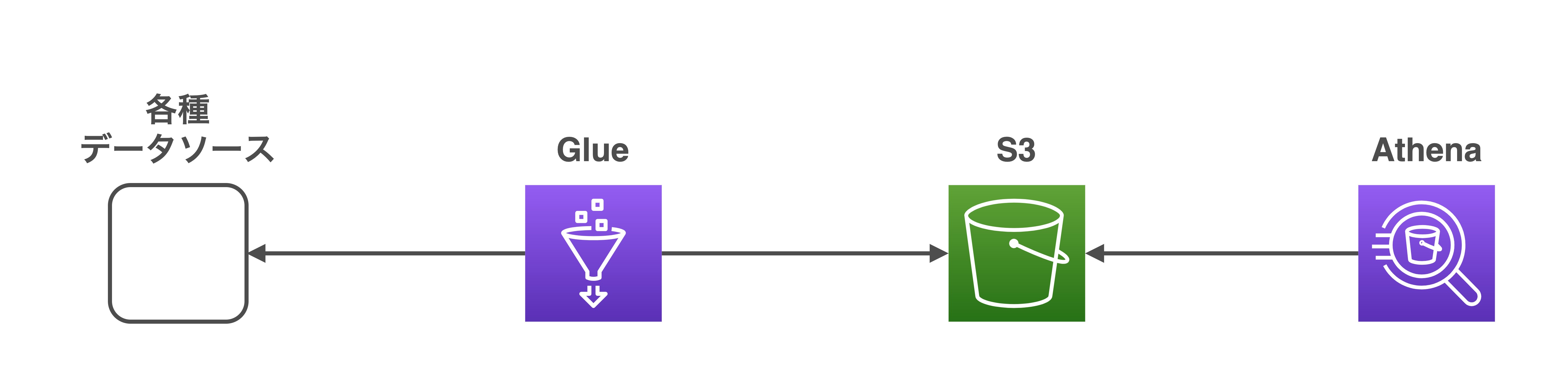
- Glueというサービスを用いて外部ソースから取得したデータを変換・加工してS3に保存
- Athenaというサービスを用いてS3のデータに対しSQL検索
当社のデータエンジニアは主に1の部分を行い、さまざまなデータをAthenaで集計・分析できるような環境づくりを行っています。
Glueのワークフロー開発
データアーキテクチャについて理解したところで、データアナリストからエンジニアへの第一歩として開発したGlueワークフローについての説明をします。Glueには主に次の3つの機能が搭載されています。
- ジョブ : 分析の前処理(データ抽出、変換、ロード)を実行する機能
- クローラ : データカタログへメタデータを作成する機能
- トリガー : ジョブ、クローラを手動または自動で実行する機能
ジョブは分析の前処理を実行する機能のことです。たとえば、CSVデータを読み込んで加工し出力するといった一連の処理を一つのジョブとして定義できます。クローラはデータカタログへメタデータを作成する機能を持っています。テーブルの入出力形式や列名などのデータ型を定義し、それをデータカタログという箱に入れることができるというイメージです。トリガーはジョブ、クローラを手動または自動で実行する機能のことです。毎日決まった時間に実行させたり、一つ前のジョブが正常終了したときに実行させたりできます。また、これら三つを一連の処理としてまとめて管理しやすくしたものをワークフローといいます。
私は「外部ソースからのデータをAthenaで集計できるようにする」ワークフローを開発することでデータの流れを大まかに理解し、データエンジニアとしての一歩を踏み出すことができました。ところで、前職でデータアナリストをやっていたころはデータエンジニアが整形したデータを集計・分析するという環境だったため、データがどのように作られているかどうかには気を配ることはあまりできていませんでした。しかし、この開発でトリガーやジョブの組み合わせ方などデータの前処理部分の理解を深めることができたのはとても大きな経験になりました。
アナリストとエンジニアのスキルセットの比較
ここまでデータエンジニアの業務について述べてきましたが、私の考えるデータアナリストとデータエンジニアそれぞれに必要なスキルセットを整理してみます。
データアナリストのスキルセット
- 分析設計
- 集計
- 分析
- 分析結果の説明
まず、データアナリストに必要なスキルとして分析設計の能力が挙げられます。たとえば、マーケターに「このデータがほしい」と言われたとします。言われるがままにそのデータを出すこともできますが、それだと手戻りが発生してしまうこともあります。そのため、そのデータを出したい理由は何なのかを質問することで元々の目的を明確にし、どんなデータを出して分析すればその目的が達成できるかを定めるといったことが必要になります。これが分析設計です。
続いて、集計する能力です。これは、SQLなどを用いてほしいデータを抽出することを指します。SQLを書いて抽出したデータにミスがないかをチェックするための検算や、ミスが起きにくいSQLの書き方を身につけるのは意外と難しいです。
次に、分析する能力です。ベースとなるのは、主観を入れず論理的に物事を考えられる能力です。ここに、統計や機械学習などの知識が必要になる場合があります。
最後に、分析結果を説明する能力です。いくら高度な分析を行ったとしても、その分析結果がビジネスに活かせなければ価値があるとは言えません。意思決定者に適切な説明を行い、理解してもらうところまでできて初めて価値が出てきます。
データエンジニアのスキルセット
- データパイプラインの設計
- コードの設計
- データ加工
まずは、データパイプラインの設計能力です。本記事で説明したことと照らし合わせると、データ加工のワークフローをどのように構成すれば求めているデータを作れるかどうかを見定める力といえばよいでしょうか。
続いてはコードの設計能力です。これはデータエンジニアだけではなくすべてのエンジニアに共通することだと思いますが、コードは書いて終わりではなく、のちのち修正する必要が出てくる可能性があります。そのため、いかに保守運用しやすいコードを書くかということは重要です。
最後に、データ加工の能力です。主にSQLやPythonを使うため、これらを満足に扱える能力が必要になってきます。
以上がデータアナリストとデータエンジニアのスキルセットの比較です。
今後の展望
ここまで、データアナリストからデータエンジニアへキャリアチェンジしてからの半年間についてお伝えしてきました。振り返ってみると、データエンジニアとしてのスキルを少しずつつけることができていますが、今度は開発に集中しすぎてデータアナリストとしての視点を失いつつあるような気がしています。そこで、今後の展望としては「利用者が使いやすい基盤を作る」ことを意識できればと考えています。開発者にとってどんなに美しいデータ基盤を作ったとしても、データアナリストが適切にビジネスサイドへアウトプットしていかないとビジネス的な価値があるとは⾔えません。そうならないために、データアナリストとしての経験もデータエンジニアとしての経験も活かして一気通貫でデータを価値につなげられるような人材になれるよう日々邁進していきます!
関連記事 | Related Posts
新卒データアナリストがデータエンジニアになるまで

A Look into the KINTO Technologies Analysis Group
Building a Speedy Analytics Platform with Auto-Expansion ETL Using AWS Glue
KINTOテクノロジーズ 分析グループを紹介します
What’s this 40-something person with no web experience doing here?

Building a culture of MLOps by holding a SageMaker Study Session (4/4)
We are hiring!
【シニアデータサイエンティスト(Python)】データサイエンスG/東京・大阪・名古屋・福岡
募集背景KINTOでは、事業成長とともに、データを活用したマーケティング分析の重要性が高まっています。市場やお客様の変化を捉え、より良い顧客体験を提供するため、施策の評価や課題発見、改善提案を推進できる体制強化が必要となりました。
ビジネスアナリスト(マーケティング/事業分析)/分析プロデュースG/東京・大阪・福岡
デジタル戦略部 分析プロデュースグループについて本グループは、『KINTO』において経営注力のもと立ち上げられた分析組織です。決まった正解が少ない環境の中で、「なぜ」を起点に事業と向き合い、分析を軸に意思決定を前に進める役割を担っています。




