Introducing an evaluation system into generative AI application development to improve accuracy: Initiatives to automate database design reviews

Hello. We are @p2sk and @hoshino from the DBRE team.
The DBRE (Database Reliability Engineering) team is a cross-functional organization focused on resolving database (DB) issues and developing platforms.
In this article, we introduce an automatic review function for DB table designs built with a serverless architecture using AWS's generative AI service “Amazon Bedrock.” This function works with GitHub Actions, and when a pull request (PR) is opened, the AI automatically reviews it and proposes corrections as comments. We also explain how we designed and implemented the evaluation of generative AI applications. We explain the evaluation methods adopted for each of the three phases in the LLMOps lifecycle (i.e., model selection, development, and operation phases), and in particular introduce generative AI- based automated evaluation utilizing "LLM-as-a-Judge" in the operation phase.
Purpose of this article
This article aims to provide easy-to-understand information on generative AI application evaluation, ranging from abstract concepts to concrete implementation examples. By reading this article, we hope that even engineers who do not have specialized knowledge of machine learning, like our DBRE team, will gain a better understanding of the generative AI development lifecycle. We will also introduce the challenges we faced when using generative AI in our services and how we solved them, with concrete examples. In addition, you can read this article also as one implementation example for the "Considerations and Strategies for Practical Implementation of LLM" introduced in the session "Best Practices for Implementing Generative AI Functions in Content Review" held at the recent AWS AI Day.
I hope this article will be of some help to you.
Table of Contents
This article is structured as follows. This is a long article, so if you’re just interested in how the system works, I recommend you read up to the section on the "Completed System." If you’re interested in developing generative AI applications, I recommend you continue reading beyond that.
- Background
- Design
- Completed System (with demo video)
- Ideas in Implementation
- Evaluation of Generative AI Applications
- Lessons Learned and Future Prospects
- Conclusion
Background
Importance of database table design
Generally, DB tables have the characteristic that once they are created, they are difficult to modify. As the service grows, the amount of data and frequency of references tend to increase, so we want to avoid as much as possible carrying technical debt that makes us regret later, saying, "I should have done it this way at the design stage...". Therefore, it is important to have a system in place that allows tables to be created with "good design" based on unified standards. "10 Things to Do to Get Started with Databases on AWS" also states that a table design is still a valuable task, even though database management has been automated in the cloud.
In addition, the spread of generative AI is making the data infrastructure even more important. Tables designed with uniform standards are easy to analyze, and easy-to-understand naming and appropriate comments have the advantage of providing good context for generative AI.
Given this background, the quality of DB table design has a greater impact on an organization than ever before. One way to ensure quality is creating in-house guidelines and conducting reviews based on them.
Our current situation regarding reviews
At our company, table design reviews are carried out by the person in charge of each product. The DBRE team has provided the "Design Guidelines," but they are currently non-binding. We considered having DBRE review the table designs of all products across the board, but since there are dozens of products, we were concerned that if DBRE acted like a gatekeeper, it would become a bottleneck in development, so we gave up on the idea.
Against this background, we, DBRE team, have decided to develop an automatic review system that acts as a guardrail and apply the system to our products.
Design
Abstract architecture diagram and functional requirements
The following is the abstract architecture diagram for the automatic table design review function. 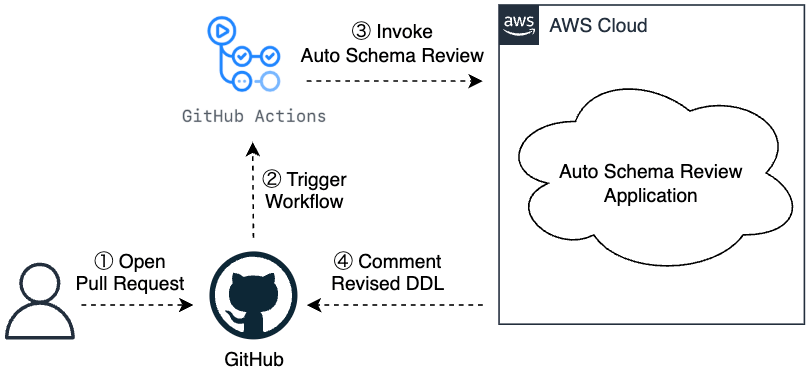
To continuously perform automated reviews, it is important to integrate them into the development workflow. For this reason, we have adopted a system that triggers via a PR the automatic execution of an application on AWS and provides feedback within the PR, including comments on suggested corrections to the table definition (DDL). The requirements for an application are as follows:
- The ability to set our company's own review criteria
- To complement human reviews, it should be as accurate as possible, even if not 100%.
Policies for implementing review function
There are two possible policies for automating table design reviews: (1) Review through syntax analysis and (2) Review through generative AI. The characteristics of each policy are summarized as follows: 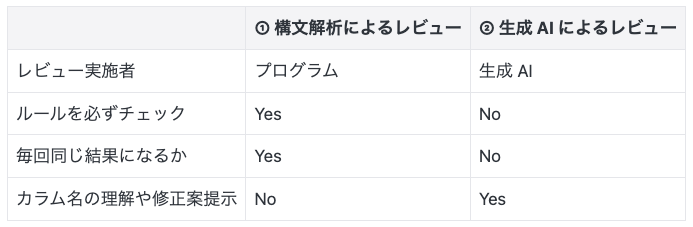
Ideally, (1) should be applied to review criteria that can be handled through syntax analysis, and (2) to other review criteria. For example, the verification of the naming rule "Object names should be defined in Lower Snake Case" can be handled by (1). On the other hand, subjective criteria, such as "giving object names that allow inferring the stored data," are better suited for (2).
Ideally, the two policies should be used separately depending on the review criteria, but this time we have decided to implement only "(2) Review through generative AI" for the following reasons.
- (1) is feasible, but (2) is something whose feasibility we cannot determine until we try it, so we have decided it is worth attempting first.
- By implementing the items that can be handled by (1) also in (2), we aim to gain insights into the accuracy and implementation costs of both policies.
Review target guidelines
To shorten the time to delivery, we have narrowed the review items down to the following six:
- An index must comply with the DBRE team's designated naming rules.
- Object names are defined in Lower Snake Case.
- Object names must consist of alphanumeric characters and underscores only.
- Object names must not use Roman characters.
- Object names that allow inferring the stored data must be assigned.
- Columns that store boolean values should be named without using "flag".
The top three can be addressed with syntactic analysis, but the bottom three are likely to be better addressed with generative AI, which also provides suggested corrections.
Why create a dedicated system?
Although several "systems (mechanisms) for review using generative AI" already exist, we have determined that they do not meet our requirements, so we have decided to create a dedicated system. For example, PR-Agent and CodeRabbit are well-known generative AI review services. Our company has also adopted PR-Agent for reviewing codes and tech blogs. In addition, GitHub Copilot's automated review function is currently available as Public Preview and may become generally available in the future. This function also allows you to have your code reviewed in Visual Studio Code before pushing it, and it is expected that the "generative AI review system" will become more seamlessly integrated into development flows in the future. Additionally, you can define your own coding standards in the GitHub management screen and have Copilot review based on them.
The following are some reasons why we want to build our own system:
- It is difficult to check a large number of guidelines with high accuracy using generative AI, and we have determined that it is currently challenging to handle this with external services.
- We want to adjust the feedback method flexibly.
- Example: Columns like "data1" have ambiguous meanings, so it is difficult to suggest corrections, so we want to keep them in comments only.
- In the future, we aim to improve accuracy with a hybrid structure combining syntax analysis.
Next, we will introduce the completed system.
Completed system
Demo video
After the PR is created, GitHub Actions is executed, and the generative AI provides feedback on the review results as comments on the PR. The actual processing time is approximately 1 minute and 40 seconds, but the waiting time has been omitted from the video. The cost of the generative AI when using Claude 3.5 Sonnet is estimated to be approximately 0.1 USD per DDL review. https://www.youtube.com/watch?v=bGcXu9FjmJI
Architecture
The final architecture is as shown in the diagram below. Note that we have built an evaluation application separately to tune the prompts used, which will be described in detail later. 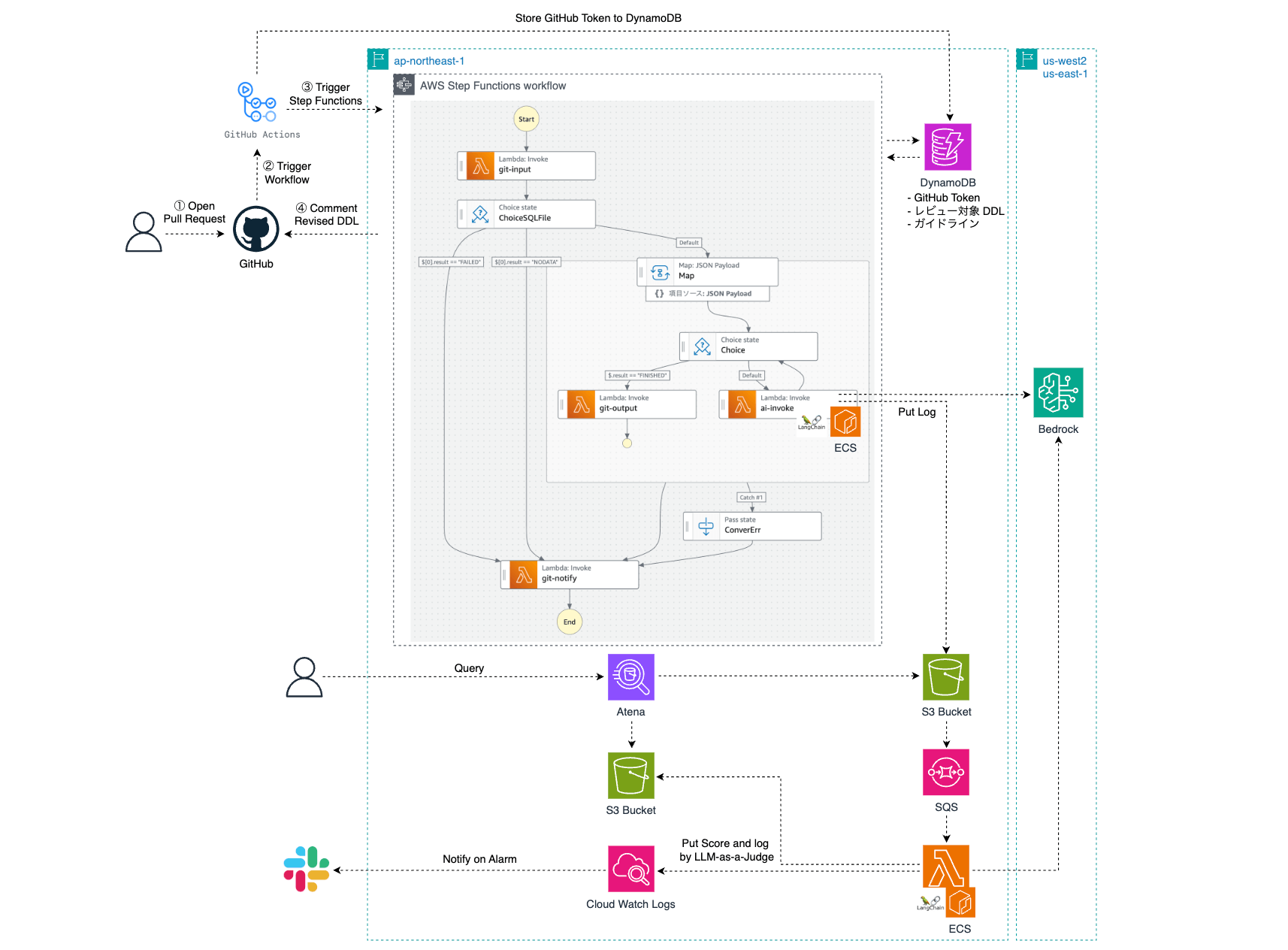
Process Flow
When a PR is opened, a GitHub Actions workflow is triggered, and an AWS Step Function is started. At this stage, save the PR URL and the GITHUB_TOKEN generated in the workflow to DynamoDB. The reason for not passing DDL directly to Step Functions is to avoid input character limits. Extract the DDL on the Lambda side based on the PR URL. Step Functions uses a Map state to review each DDL in parallel. Only one guideline should be checked per review. To review based on multiple guideline criteria, the "post-correction DDL" obtained from the first prompt is repeatedly passed to the next prompt, generating the final DDL (the reason will be explained later). After completing the review, provide feedback as a comment on the PR. The review results are stored in S3, and the generative AI evaluates them using LLM-as-a-Judge (more details will be provided later).
Examples of the results are shown below. 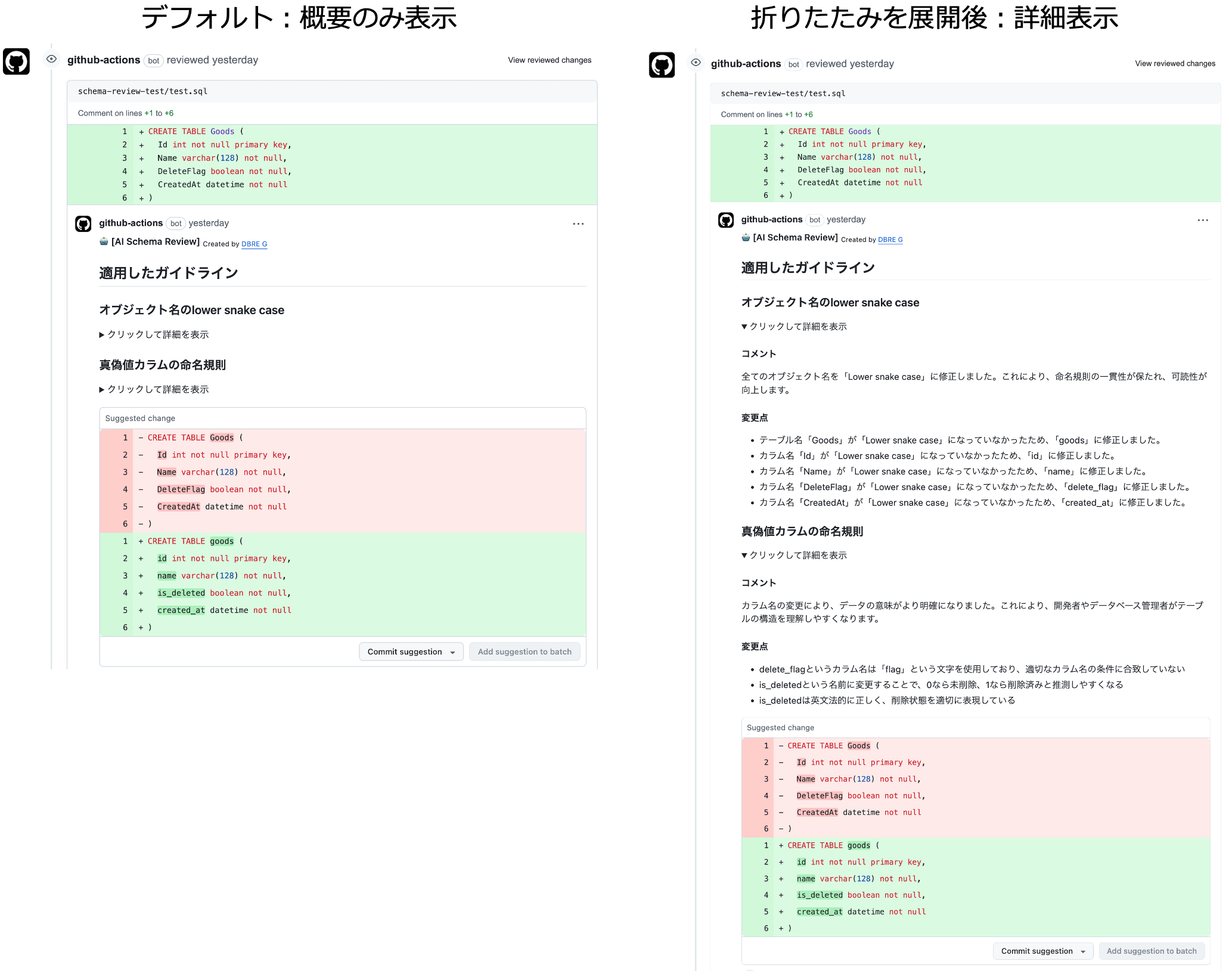
As feedback from the generative AI, the "applied guidelines" and "suggested corrections" are provided as comments (on the left side of the image). The details have been collapsed and can be expanded to check the specific corrections and comments made to the DDL (on the right side of the image).
Steps required for implementation
The table design review feature can be implemented in just two steps. Since it can be set up in just a few minutes, you can easily introduce it and start the generative AI review immediately.
- Register the key required to access AWS resources in GitHub Actions Secrets.
- Add a GitHub Actions workflow for the review function to the target GitHub repository.
- Simply add the product name to the template file provided by the DBRE team.
Next, we will introduce some of the ideas we came up with for our implementation.
Ideas in Implementation
Utilization of container images and Step Functions
Initially, we planned to implement it using only Lambda, but we encountered the following challenges.
- The library size is too large and exceeds the 250 MB deployment package size limit for Lambda.
- When chaining and evaluating multiple guideline criteria, there is a concern that the maximum execution time of Lambda (15 minutes) may be reached.
- When serially processing DDLs, the execution time increases as the number of DDLs increases.
To solve issue 1, we adopted container images for Lambda. To solve 2 and 3, we introduced Step Functions and changed the design so that each Lambda execution evaluates one DDL against one guideline criterion. Furthermore, by using Map state to perform parallel processing for each DDL, we ensured that the overall processing time is not affected by the number of DDLs. The diagram below shows the implementation of the Map state, where the prompt chain is realized in the loop section.
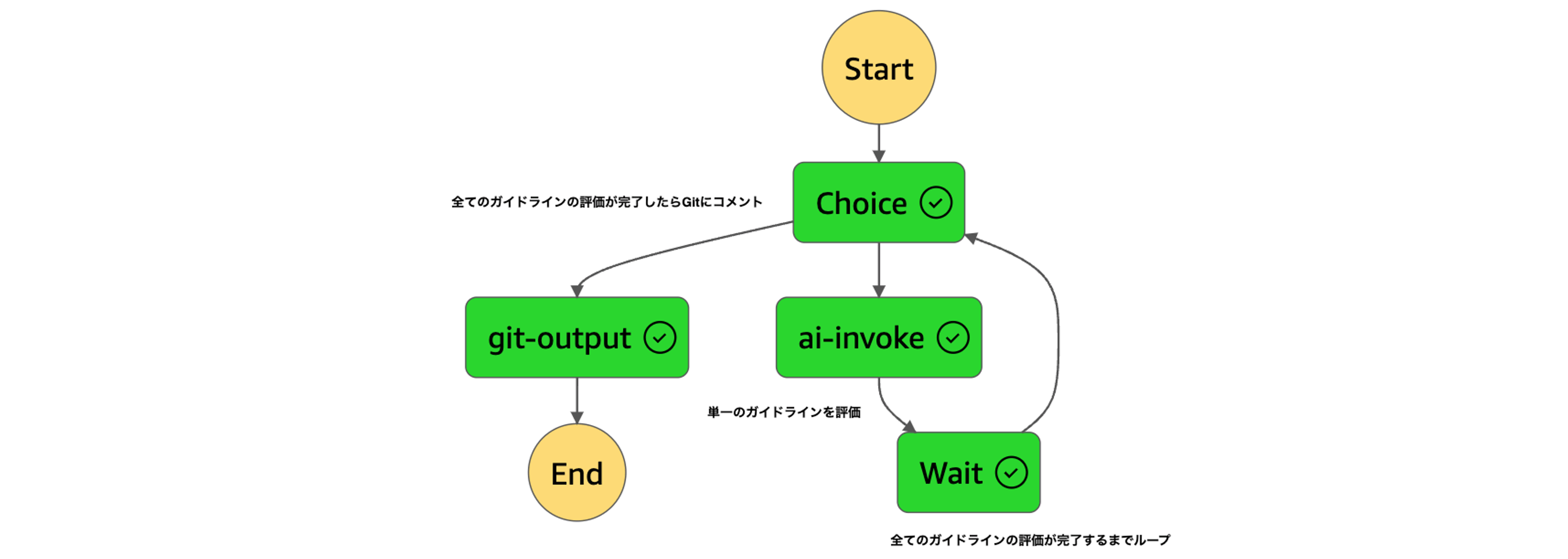
Measures against Bedrock API throttling
During the review, Bedrock's InvokeModel requests occurred according to the number of DDLs multiplied by the number of guidelines, and errors sometimes occurred due to quota limits. According to the AWS documentation, this limit cannot be relaxed. For this reason, we introduced a mechanism to distribute requests on a per-DDL basis across multiple regions and, in the event of an error, retry in yet another region. This has led to stable reviews, mostly without reaching the RateLimit.
However, we are currently using cross-region inference, which dynamically routes traffic among multiple regions and allows us to delegate throttling countermeasures to AWS, so we plan to transition to this in the future.
Organizing the way to grant permissions to execute GitHub API from Lambda
In order to enable Lambda to "obtain the changed files of the target PR" and "post comments on the target PR," we compared the following three methods of granting permissions.
| Token type | Expiration date | Advantages | Disadvantages |
|---|---|---|---|
| Personal Access Token | Depending on the setting, it can be unlimited | The scope of the permissions is broad. | Dependency on individuals |
| GITHUB_TOKEN | Only during workflow execution | Easy to obtain | Concerns about insufficient permissions depending on the processing of the target |
| GitHub App(installation access token) | 1 hour | Granting permissions not supported by GITHUB_TOKEN is also possible | Increased complexity of the steps involved in introduction to a product |
This time we have adopted GITHUB_TOKEN for the following reasons:
- Tokens are short-lived (only for the duration of the workflow) and pose a low security risk.
- Token issuance and management are automated, reducing the operational burden.
- Permissions necessary for this processing can be granted.
The tokens are stored in DynamoDB with a time to live (TTL) and are retrieved and used by Lambda when needed. This allows you to use tokens safely without needing to check whether the token-passing process has been logged.
In the following, we present evaluation examples of generative AI applications.
Evaluation of Generative AI Applications
For generative AI application evaluation, we referred to the diagram below from Microsoft's documentation.
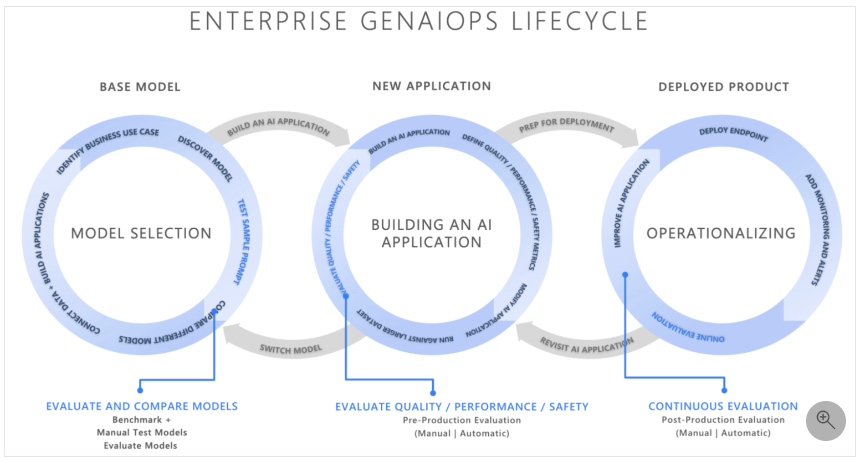
Source: Microsoft - Evaluation of Generative AI Applications
According to this diagram, there are three types of evaluations that should be performed during the GenAIOps (LLMOps, because the target in this case is LLM) lifecycle.
- Model selection phase
- Evaluating the base models and deciding which model to use
- Application development phase
- Evaluating the application output (≒ response of the generative AI) from the perspectives of quality, safety, etc., and tuning it
- Post-deployment operation phase
- Even after deployment to the production environment, quality, safety, etc., are evaluated continuously.
Below, we will introduce some examples of how evaluations were conducted in each phase.
Evaluation during the model selection phase
This time, we selected an Amazon Bedrock platform model and evaluated it based on the scores from Chatbot Arena and the advice of our in-house generative AI experts and adopted Claude from Anthropic. We reviewed the DDL using Claude 3.0 Opus, which was the highest-performing model at the time of our launch, and confirmed its accuracy to a certain extent. Each model has different base performance, response speed, and monetary costs, but since reviews in this case are infrequent and there is no requirement for "maximum speed," we selected the model with the greatest emphasis on performance. Based on Claude's best practices, we determined that further accuracy could be achieved through prompt tuning and moved on to the next phase.
Meanwhile, the higher-performance and faster Claude 3.5 Sonnet was released, which further improved the inference accuracy.
Evaluation during the application development phase
Generative AI evaluation methods are clearly summarized in the article here. As the article states,
"Various evaluation patterns are possible depending on the presence or absence of a prompt, foundational model, and RAG,"
the evaluation pattern will vary depending on "what is being evaluated.” This time, we will focus on the evaluation of a "single prompt" and provide a concrete example of the design and implementation for the specific use case, which involves "having a database table design reviewed according to our company's guidelines."
Prompt tuning and evaluation flow
Prompt tuning and evaluation were carried out according to the diagram below, as described in Claude's documentation. 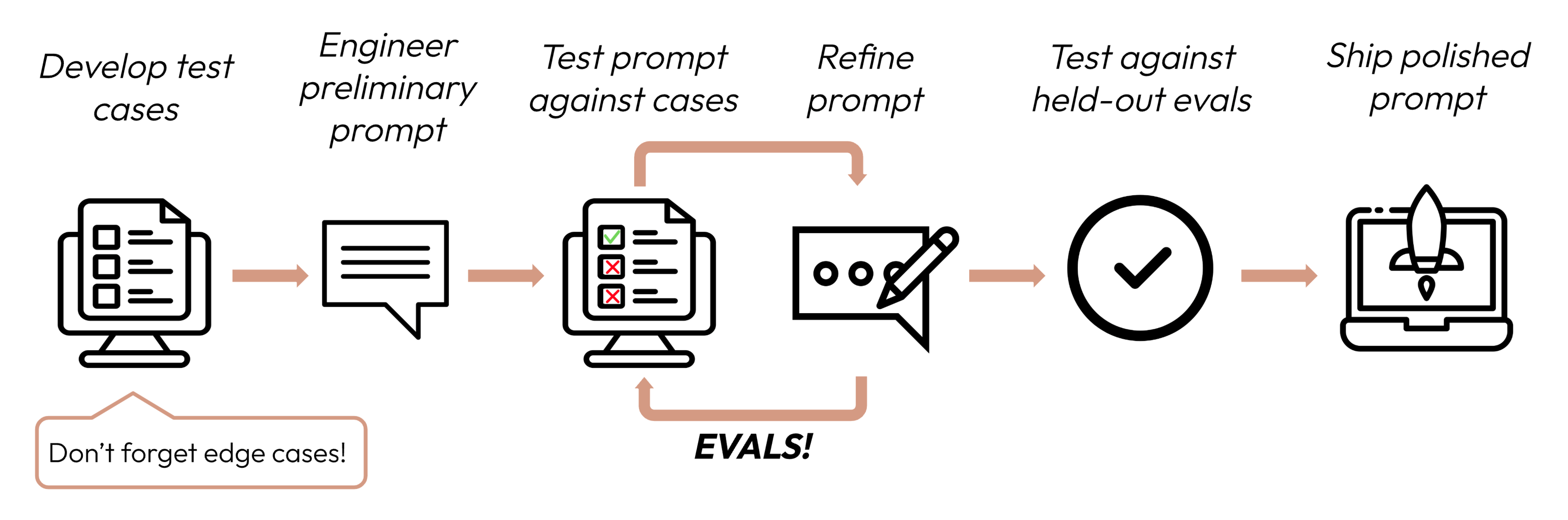 Source: Anthropic company - Create strong empirical evaluations
Source: Anthropic company - Create strong empirical evaluations
The key point is to define an evaluation perspective, such as "how close the prompt execution result is to expectations," as a "score calculated in some way," and to adopt the prompt with the best score. Without an evaluation system (mechanism), determining the improvement in accuracy before and after tuning may rely on subjective judgment, which could lead to ambiguity and an increase in work time.
In the following, we will first introduce the generative AI evaluation method, followed by examples of prompt tuning.
What is "generative AI evaluation"?
The page for the generative AI evaluation product called "deep checks" states the following about evaluation.
Evaluation = Quality + Compliance
I felt that this was the most concise way to evaluate generative AI applications. Breaking it down further, the article here classifies the criteria for evaluating service providers into four perspectives: "truthfulness, safety, fairness, and robustness." The evaluation criteria and score calculation method should be selected according to the properties of the application. For example, Amazon Bedrock uses different metrics for different tasks, such as "BERT score" for text summarization and "F1 score" for question answering.
Method for calculating evaluation scores
anthropic-cookbook classifies the methods for calculating scores into the following three main categories: 
Summary of the score calculation methods described in anthropic-cookbook
You can choose to use cloud services, OSS, or create your own score calculation logic. In any case, you need to set your own evaluation criteria. For example, if the LLM's output is in JSON format, "matching each element" may be more appropriate than "matching the entire string."
Regarding model-based grading, the code provided in anthropic-cookbook can be expressed more concisely as follows:
def model_based_grading(answer_by_llm, rubric):
Prompt = f""" Evaluating the answer within the <answer> tag based on the perspective of the <rubric> tag. Answering "correct" or "incorrect."
<answer>{answer_by_llm}</answer>
<rubric>{rubric}</rubric>
"""
return llm_invoke(prompt) # Pass the created prompt to LLM for inference
rubric = "Correct answers must include at least two different training plans."
answer_by_llm_1 = "The recommended exercises are push-ups, squats, and sit-ups." # Actually, the output of LLM
grade = model_based_grading(answer_by_llm_1, rubric)
"print(grade) # It should be output as "correct"
answer_by_llm_2 = “The recommended training is push-ups.” # Actually, the output of LLM
grade = model_based_grading(answer_by_llm_2, rubric)
print(grade) # It should be output as "incorrect."
Summary of evaluation
To summarize the content covered so far, the evaluation method is illustrated as the diagram below. 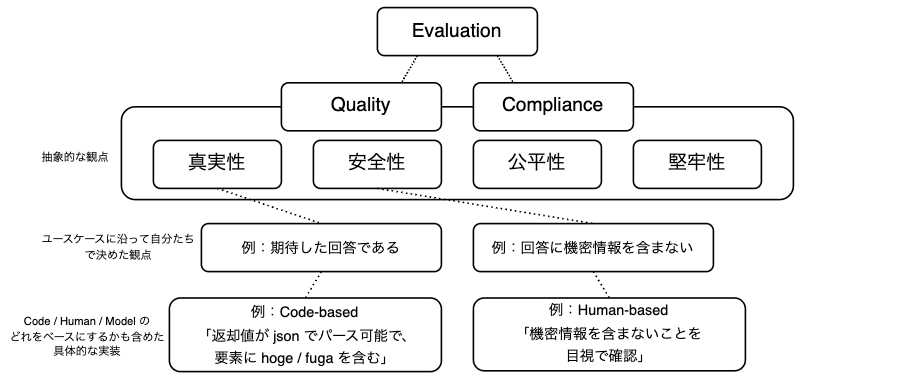
Abstractly, the evaluation of generative AI breaks down into Quality and Compliance. These are further broken down, and specific evaluation criteria are set for each use case. Each criterion needs to be quantified, and this can be achieved based on “Code,” “Human,” or “Model.”
In the following, we will explain the specific evaluation method from the perspective of "database table design review."
Evaluation design in DB table design review
We chose a code-based approach to quality evaluation for the following reasons:
- The cycle of evaluation and tuning by humans increases man-hours and is not worth the resulting benefits.
- We also considered a model-based approach, but since we wanted to assign the best score for a perfect match with the correct DDL, we concluded that a code-based approach was more appropriate.
Since it is difficult to newly implement "similarity in DDL" with the correct data, we adopted the Levenshtein Distance, a method for measuring the distance between texts, as the score calculation method. With this method, a perfect match has a distance of 0, and the higher the value, the lower the similarity. However, since this is not an indicator that completely represents "similarity in DDL," we basically aimed for a score of 0 for all datasets and performed prompt tuning on datasets with non-0 scores. The algorithm is also provided by LangChain's String Evaluators (String Distance), which is what we use.
On the other hand, from a compliance perspective, we decided that it was unnecessary this time because it is an in-house application and the implementation limits user input embedded in the prompt to DDL.
Implementation of evaluation
The flow of the implemented evaluation is as follows. 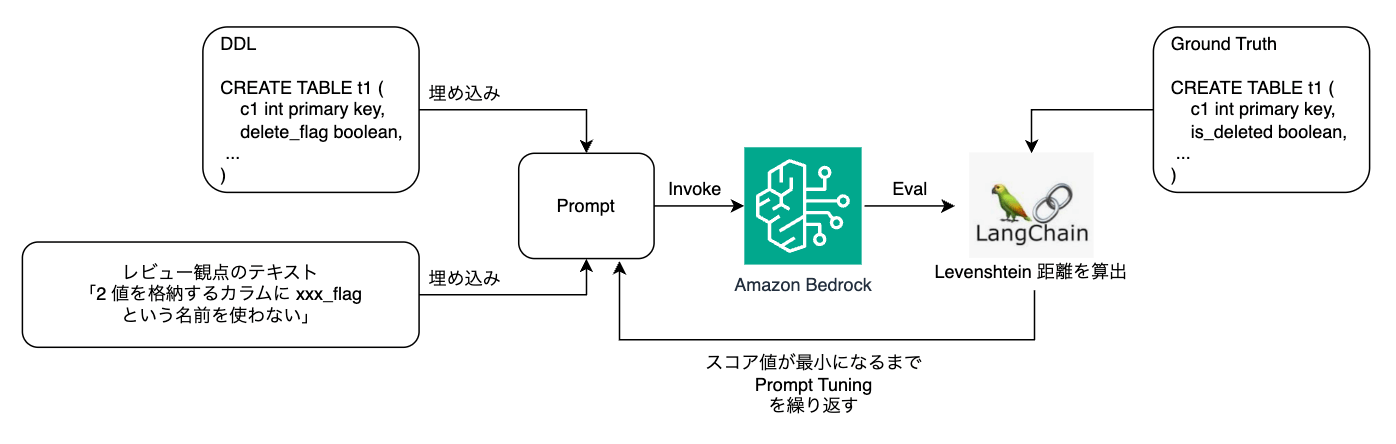
For each review perspective, we created 10 patterns of datasets combining input DDL and correct answer DDL. To efficiently repeat prompt tuning and evaluation, we developed a dedicated application using Python andStreamlit. The dataset is saved in jsonl format, and when you specify the file, the evaluation is automatically performed and the results are displayed. Each json contains the "evaluation target guideline", "parameters for invoking LLM", "input DDL", and "correct DDL" as shown below.
{
"guidline_ids": [1,2],
"top_p": 0,
"temperature": 0,
"max_tokens": 10000,
"input_ddl": "CREATE TABLE sample_table (...);",
"ground_truth": "CREATE TABLE sample_table (...);"
}
When displaying individual results, the diff between the output DDL and the correct DDL is displayed, making it possible to visualize the differences (= tuning points). 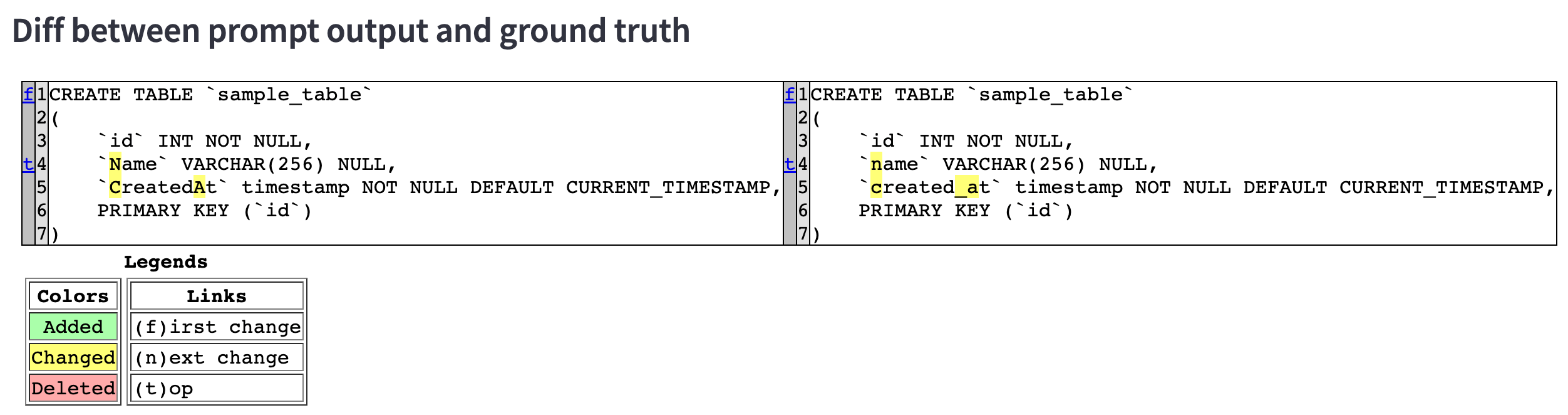
Once the evaluation is complete, you can also check the aggregated score results. 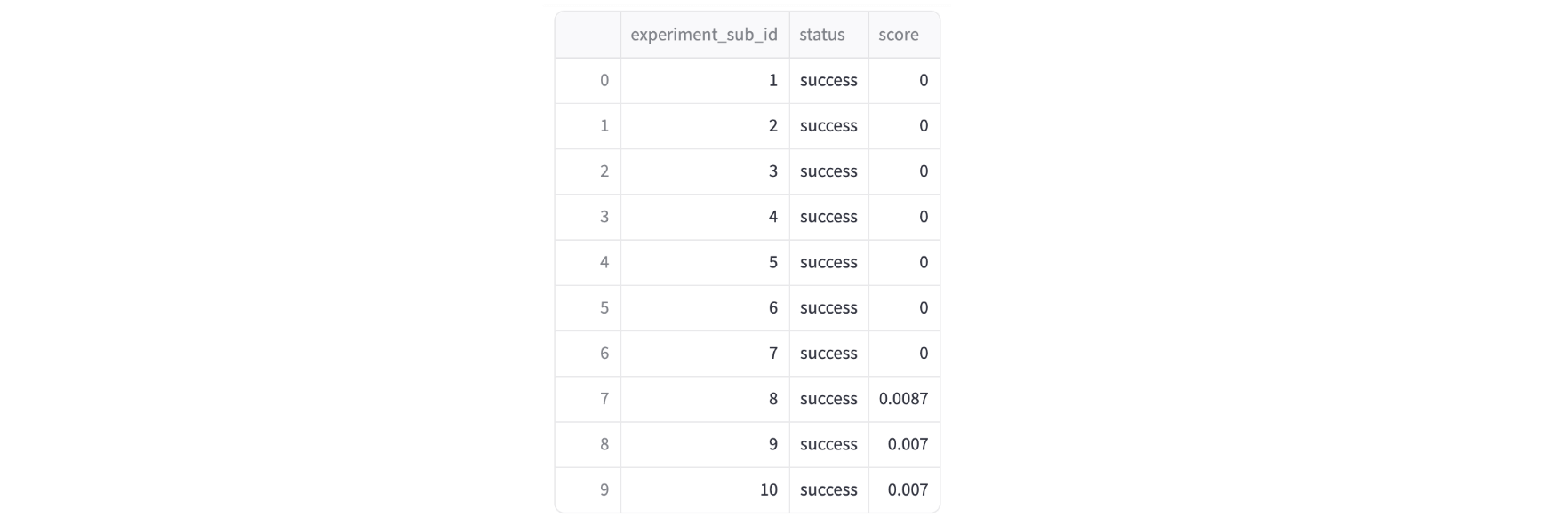
Prompt tuning
Based on Claude's documentation, we created and tuned the prompts, keeping the following points in mind, and ultimately achieved the best results (0 score) for almost all 60 datasets.
- Setting roles
- Utilizing XML tags
- Letting Claude think (instructing Claude to show its thinking process to make debugging easier when the answer is disappointing)
- Few-Shot Prompting (providing example output)
- Putting reference data at the beginning and instructions at the end
- Giving clear and specific instructions
- Chaining prompts
There are many well-known techniques, so we won't go into detail here, but let us provide some additional information on the last two points.
"Giving clear and specific instructions"
Initially, we embedded the text of our in-house table design guidelines directly into the prompt. However, the guidelines only described "how things should be" and did not include "specific steps to correct the errors." Therefore, we rewrote them into "specific correction instructions" in a step-by-step format. For example, we revised the guideline "Do not use xxx_flag for column names that store boolean values" as follows:
Follow the steps below to extract the column name storing the Boolean value and change it to an appropriate column name if necessary.
1. Extract the name of the column that stores Boolean values. The criterion is whether the column uses the Boolean type or contains the word "flag."
2. Check the names of the Boolean columns one by one and understand the meaning of the columns first.
3. Check the names of the Boolean columns one by one, and if you determine there is a more appropriate name, modify the column name.
4. Regarding the appropriate column name conditions, refer to the <appropriate_column_name></appropriate_column_name> tag.
<appropriate_column_name>
Without using the word "flag"...
...
</appropriate_column_name>
"Chaining prompts"
The more guidelines there are to check, the more complex the prompts will become if you try to check them all in one go, raising concerns that checks will be missed or accuracy will decrease. For this reason, we limited the items that the AI checks in each prompt execution to one. We also reflected this in the architecture by passing the "corrected DDL" obtained in the first prompt as input for the next prompt (Chain), and repeating the process to obtain the final DDL. Chaining prompts also offers the following advantages:
- Since prompts are short and tasks are limited to one, accuracy improves.
- When adding guidelines, you only need to create a new prompt, so there is no impact on the accuracy of existing prompts.
On the other hand, the time and financial costs will increase as the number of LLM Invokes increases.
Evaluation during the post-deployment operational phase
In the prompt creation stage, we evaluated the quality using manually created correct answer data. However, in a production environment, no correct answer data exists, so a different approach for evaluation is required. So, we adopted LLM-as-a-Judge, an approach where an LLM evaluates its own responses. According to the Confident AI documentation, there are three methods to this approach.
- Single Output Scoring (no correct answer data)
- Giving the "LLM output" and "evaluation criteria" and having the LLM provide a score based on the criteria.
- Single Output Scoring (with correct answer data)
- In addition to the above, "correct answer data" is also provided. A more accurate evaluation can be expected.
- Pairwise Comparison
- Comparing two outputs and determining which is better. You define the criteria for "better" yourself.
This time, we used Single Output Scoring (with no correct answer data). This approach is also supported by LangChain, and we used the provided function. Currently, implementation by LangSmith is recommended.
The following two criteria are defined, and each is scored on a 10-point scale.
- Appropriateness
- Has the LLM output been appropriately corrected in accordance with the guidelines?
- Formatting Consistency
- Are there no unnecessary line breaks or spaces, and is the format consistent?
The code and prompt images are below:
input_prompt ="""
<input_sql_ddl>CREATE TABLE ...</input_sql_ddl>
<table_check_rule>Ambiguous object names are...</table_check_rule>
Instructions: Based on table_check_rule, correct input_sql_ddl to the appropriate DDL.
"""
output_ddl = "CREATE TABLE ..." # Actually, DDL generated by LLM is set
appropriateness_criteria = {
"appropriateness": """
Score 1: ...
...
Score 7: Responses generally following the input instructions have been generated with no more than two inappropriate corrections.
Score 10: Responses completely following the input instructions have been generated.
"""
}
evaluator = langchain.evaluation.load_evaluator(
"score_string", llm=model, criteria=appropriateness_criteria
)
result = evaluator.evaluate_strings(
prediction=output_ddl, input=input_prompt
)
print(result)
This implementation produces the following outputs: (Some parts omitted)
This answer completely follows the given instructions. The following are the reasons for the evaluation.
1. Extraction and evaluation of column names:
The answerer has extracted all column names and appropriately judged whether each column name could infer the contents of the data.
2. Identification of ambiguous column names:
All column names in the provided DDL clearly indicate their purposes and the type of stored data. For example, ...
...
This answer fully understands and properly executes the given instructions.
Rating: [[10]]
This mechanism corresponds to the red boxes in the architecture diagram below. 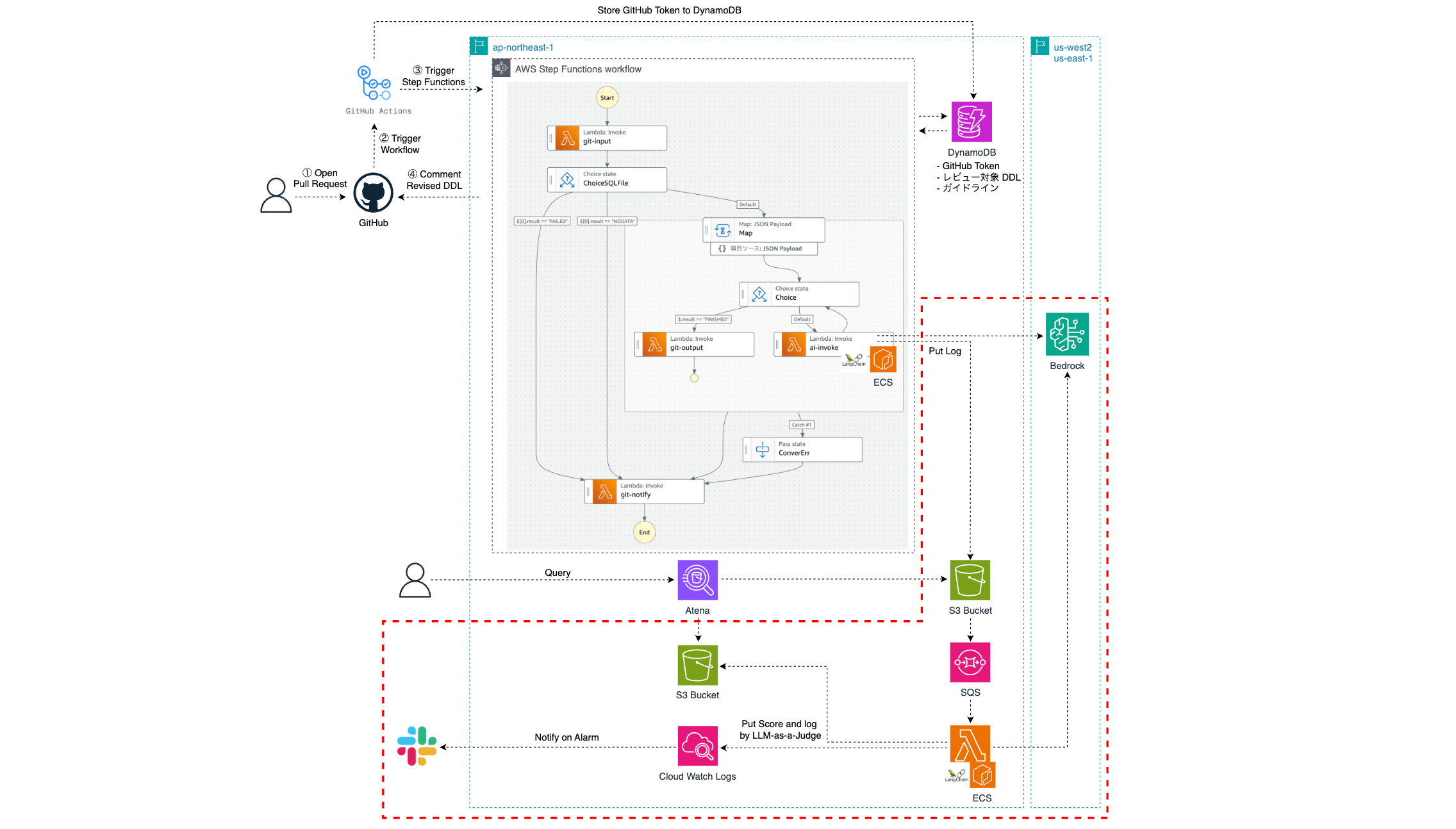
Once the LLM review results are stored in S3, the Lambda for LLM-as-a-Judge is launched asynchronously via SQS. This Lambda performs the evaluation, stores the results as logs in S3, and sends the score as a custom metric in CloudWatch. Moreover, CloudWatch Alarm will notify Slack if the threshold is not satisfied.
This score is not 100% reliable, but since it is intended for an in-house system, it is an environment that makes it easier to get feedback from users. So, we have established a system to continuously monitor the performance using quantitative scores and collect user feedback on a regular basis.
Lessons Learned and Future Prospects
Finally, we will summarize what we learned from our attempt at developing generative AI applications and our future direction.
Evaluation is very important but difficult
By evaluating the prompt results from the same perspective, we were able to quickly repeat tuning and evaluation while eliminating subjectivity. This experience strongly highlighted the importance of evaluation design. However, the three evaluations in GenAIOps (during model selection, development, and operation) need to be judged for each use case, and we felt that "judging the validity of our evaluation design" was difficult. Furthermore, a lack of evaluation perspectives also poses the risk of delivering applications with compliance issues. We believe that, in the future, the provision of more systematic and managed evaluation methods and mechanisms will make it easier to realize GenAIOps.
Our scope of imagination for generative AI use cases has broadened.
By conducting research and implementing generative AI applications ourselves, we were able to gain a clearer understanding and broaden the range of use cases we can imagine. For example, we can now envision a system that combines agents with mechanisms for collecting information on lock contention, enabling more managed and faster incident investigations.
Utilizing generative AI as a replacement for programmable tasks
There are the following two main ways to use generative AI in application development.
- Having generative AI perform the task itself.
- Improving the productivity of program development with generative AI
This time, we used generative AI to implement not only tasks that should be inferred by generative AI, but also tasks that would normally be processed by a program. Initially, we had hoped that by devising innovative prompts, we might be able to obtain high-precision results quickly. But we soon became acutely aware that prompt tuning actually requires a lot of time. On the other hand, by running multiple Claude models on the same task, we found that the more accurate the model, the clearer the improvement in results. Furthermore, we found that more accurate models reduce unpredictable behaviors and require less time for prompt tuning.
Based on these experiences, if model accuracy continues to improve in the future, depending on the requirements, there may be an increasing number of cases where the approach of having a generative AI perform a task itself, instead of having it write a program to do so, will be chosen.
Future prospects
In the future, we plan to focus on the following:
- Expansion of response guidelines
- Expansion of introduced products
- Creating a hybrid configuration with programmatic syntax analysis
- Improved clarity when providing feedback on review results to users
- Expanding the current simplified LLMOps to not only include monitoring but also enable prompt and model improvements using logs
- Reference: Post by @Hiro_gamo
Conclusion
In this article, we introduced an automated review function for database table design, implemented using Amazon Bedrock within a Serverless architecture. We also explained how to evaluate generative AI applications. At the recent AWS AI Day session titled "Best Practices for Implementing Generative AI Functions in Content Review," key considerations and strategies for the practical introduction of LLMs (large language models) were presented. Below, we outline how our efforts align with the items covered in the session.
| Item | Content |
|---|---|
| Separation from other methods | ●The DBRE team is taking on the challenge of automation using LLM. ● In the future, we aim to combine LLM with a rule-based approach. |
| Accuracy | ● Designing evaluation criteria based on the use case "table design review" ● Developing a dedicated application to rapidly repeat prompt tuning and evaluation ● Executing prompt tuning according to the best practices for the selected model (Claude). ● Limiting the number of items the AI checks per prompt execution to one, combined with using prompt chains, to improve accuracy |
| Cost | ● Approximately $0.1 per DDL, depending on the number of characters in the DDL ● Model selection focusing on accuracy over cost (Claude 3.5 Sonnet) because of the low frequency of reviews ● We decided that using a prompt chain would similarly increase costs but provide the benefit of improved accuracy. |
| Availability/Throughput | ● Implementing request distribution and retry processing between regions with awareness of quotas ● We plan to transition to a more managed cross-region inference. |
| Response speed | ● Since there is no requirement to be "as fast as possible," the model selection prioritized accuracy over speed. ● Reviewing each DDL in parallel improved the speed. ● Responses were returned within 2-5 minutes for dozens of DDLs. |
| LLMOps | ● Continuous accuracy monitoring was performed using LLM-as-a-Judge. |
| Security | ● For integration with GitHub, a GITHUB_TOKEN valid only during the execution of the GHA workflow was adopted. ● Since in-house applications and inputs are limited to DDL, the evaluation of compliance with LLM responses has not been conducted yet. |
This product is currently being introduced into multiple products, and improvements will continue to be made based on user feedback. Generative AI applications, including development services such as Amazon Bedrock Prompt Flow, continue to evolve, and we believe they will become even more convenient in the future. We will continue to actively venture into the field of generative AI.
The KINTO Technologies DBRE team is actively looking for new members to join us! Casual interviews are also welcome, so if you're even slightly interested, feel free to contact us via DM on X (formerly Twitter). If you'd like, feel free to follow our company’s recruitment X account as well!
関連記事 | Related Posts
Introducing an evaluation system into generative AI application development to improve accuracy: Initiatives to automate database design reviews

A system for efficiently reviewing code and blogs: Introducing PR-Agent (Amazon Bedrock Claude3)
コードとブログの両方を効率的にレビューする仕組みについて:PR-Agent(Amazon Bedrock Claude3)の導入
GitHub Copilot Agentを使ってSQL作成を効率化!

生成AIの正確性を99%まで上げられる秘密:AWSの自動推論を実際に触ってみた
Streamlining SQL Creation Using GitHub Copilot Agent!
We are hiring!
リードエンジニア/プロジェクト推進G/東京・名古屋
業務内容バックエンド開発を中心に、サービスの企画から設計・開発・運用までプロダクトに関わっていただきます。サービスや会社の成長を考えて、自分やチームが何をすべきか自律的に動き、スピード感を持って開発に取り組むことを期待しています。
生成AIエンジニア/AIファーストG/東京・名古屋・大阪・福岡
AIファーストGについて生成AIの活用を通じて、KINTO及びKINTOテクノロジーズへ事業貢献することをミッションに2024年1月に新設されたプロジェクトチームです。生成AI技術は生まれて日が浅く、その技術を業務活用する仕事には定説がありません。


