Developing a CMDB Chatbot Function with Generative AI and Text-to-SQL

Introduction
Hello! I am Yamada, and I develop and operate in-house tools in the Platform Engineering Team of KINTO Technologies' (KTC) Platform Group. If you want to know more about the CMDB developed by the Platform Engineering team, please check out the article below!
This time, I would like to talk about how we implemented a CMDB data search function and CSV output function in a chatbot, one of the CMDB functions, using generative AI and Text-to-SQL.
The CMDB chatbot allows you to ask questions about how to use the CMDB or about the data managed in the CMDB. Questions about the CMDB data had been originally answered using a RAG mechanism using ChromaDB, but we moved to a Text-to-SQL implementation for the following reasons:
Advantages of Text-to-SQL over RAG
- Data accuracy and real-time availability
- The latest data can be retrieved in real time directly from the CMDB database.
- No additional processing is required to update data.
- System simplification
- No infrastructure for vector DB or embedding processing is required (ChromaDB and additional batches for embedded data are no longer required).
For these reasons, we decided that Text-to-SQL is more suitable for a system that handles structured data such as CMDB.
What Is Text-to-SQL?
Text-to-SQL is a technology for converting natural language queries into SQL queries. This allows even users without knowledge of SQL to easily extract the necessary information from the database.
This makes it possible to retrieve data such as products, domains, teams, users, and vulnerability information including ECR and VMDR managed in the CMDB database from natural language queries.
The following are some examples of matters that could be utilized within KTC:
- Retrieving a list of domains that have not been properly managed (domains not linked to products in the CMDB)
- Retrieving Atlassian IDs of all employees
- This is because the MSP (Managed Service Provider) team creates tickets for requests such as addressing PC vulnerabilities, by mentioning (tagging) the relevant individuals.
- Aggregation of the number of vulnerabilities detected in resources related to the products for which each group is responsible
- Extraction of products for which the AWS resource start/stop schedule has not been set.
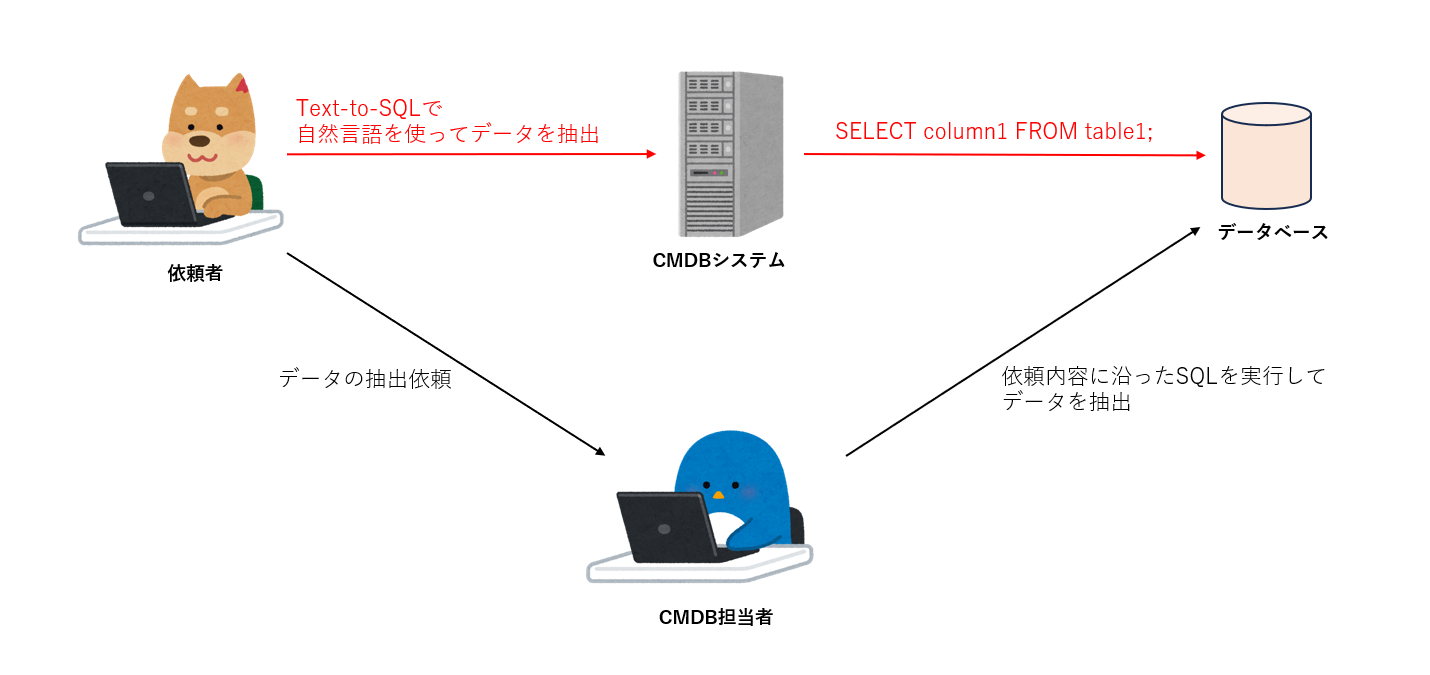
Previously, when a request to extract such data came to the Platform Engineering team, a person in charge would run a SQL query directly from the CMDB database to extract and process the data, then hand it over to the requester. When requesters become able to extract data using Text-to-SQL in the CMDB chatbot, they will be able to easily extract data without having to go through the trouble of asking a person in charge, as shown in the figure below:
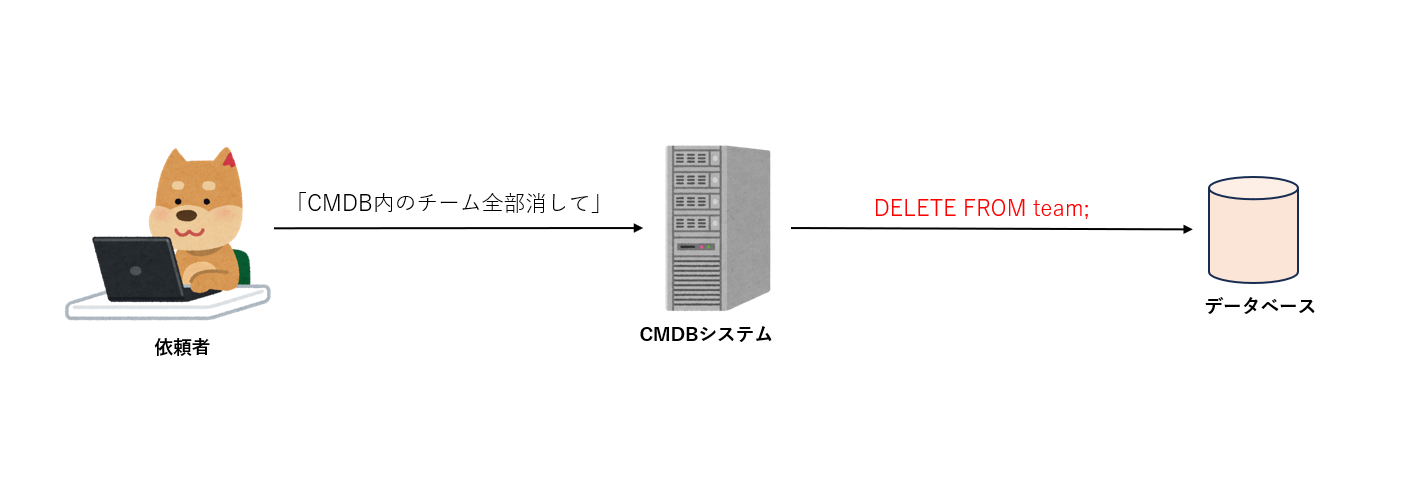
Text-to-SQL is a convenient feature, but you must be aware of the risk of insecure SQL generation. While the following figure illustrates an extreme case, since SQL is generated from natural language, there is a risk of unintentionally generating SQL statements that update or delete data or modify table structures.
So, you need to avoid generating unsafe SQL by the following methods:
- Connecting to a Read Only DB endpoint
- Set DB users to Read Only permissions
- Carrying out a validation check to ensure that commands other than
SELECTare not executed in application implementation
System Configuration
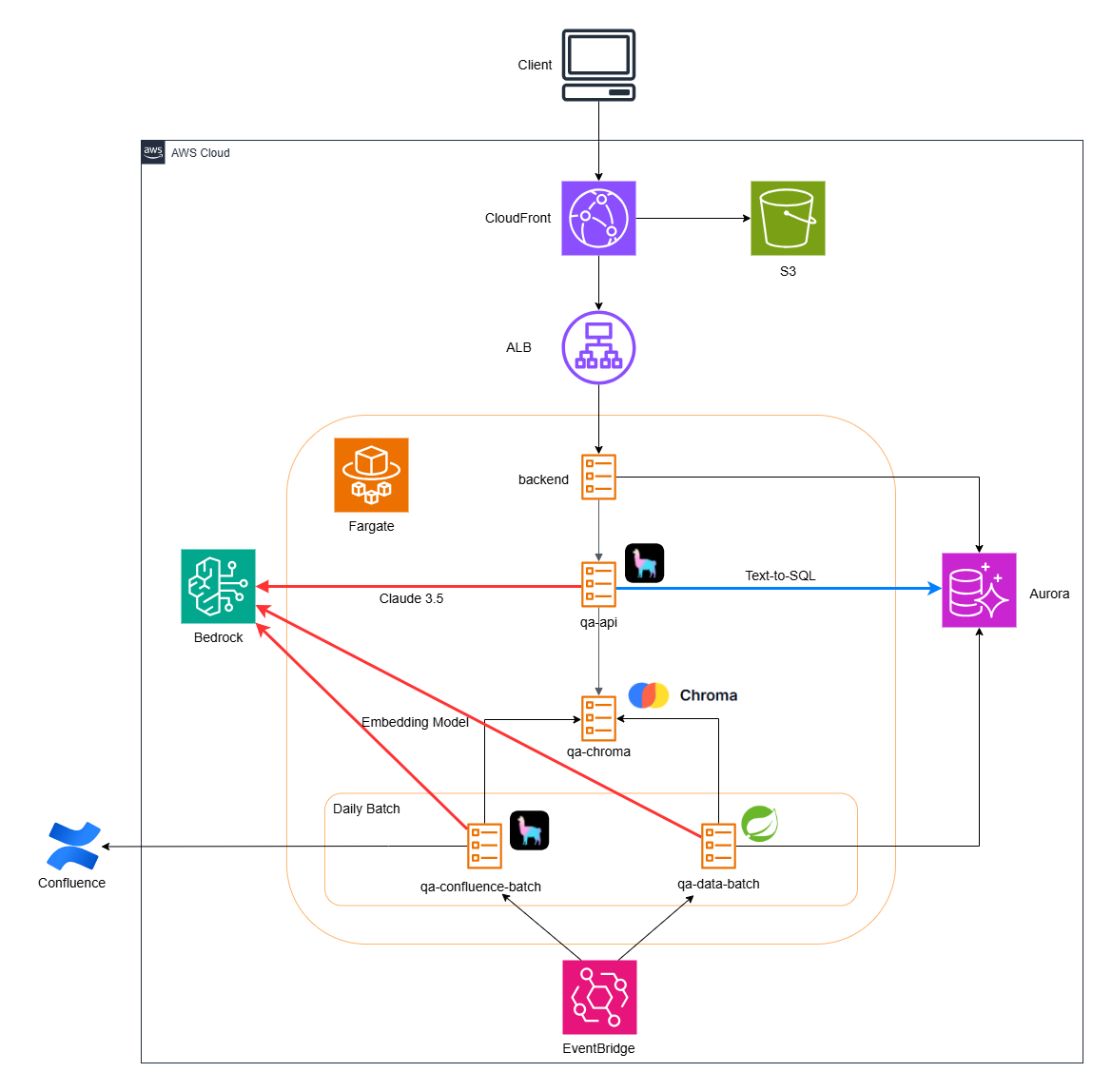
Here is the architecture of the CMDB. Resources that are not relevant to this article have been excluded. As I explained at the beginning, we had originally used ChromaDB as a vector DB, obtained information on how to use the CMDB from Confluence (implemented with LlamaIndex), and retrieved CMDB data from a database (implemented with Spring AI), then entered both into ChromaDB.
This time, we have migrated answers to questions about CMDB data from the RAG feature in Spring AI + ChromaDB to a feature using Text-to-SQL.
Text-to-SQL Implementation
From here on, I would like to explain the implementation while showing you the actual code.
CMDB Data Search Function
Retrieving Schema Information
First, retrieve the schema information required to generate SQL in LLM. The less schema information there is, the higher the accuracy, so we have adopted a method of specifying only the necessary tables.
Since the comments for table columns are important as judgment criteria when the LLM generates SQL statements, all of them need to be added beforehand.
def fetch_db_schema():
cmdb_tables=['table1', 'table2', ...]
cmdb_tables_str = ', '.join([f"'{table}'" for table in cmdb_tables])
query = f"""
SELECT
t.TABLE_SCHEMA,
t.TABLE_NAME,
t.TABLE_COMMENT,
c.COLUMN_NAME,
c.DATA_TYPE,
c.COLUMN_KEY,
c.COLUMN_COMMENT
FROM information_schema.COLUMNS c
INNER JOIN information_schema.TABLES t ON c.TABLE_SCHEMA = t.TABLE_SCHEMA AND c.TABLE_NAME = t.TABLE_NAME
WHERE t.TABLE_SCHEMA = 'cmdb' AND t.TABLE_NAME IN ({cmdb_tables_str})
ORDER BY
t.TABLE_SCHEMA,
t.TABLE_NAME,
c.COLUMN_NAME
"""
connection = get_db_connection()
try:
cursor = connection.cursor()
cursor.execute(query)
return cursor.fetchall()
finally:
cursor.close()
connection.close()
Example of retrieved results
| TABLE_SCHEMA | TABLE_NAME | TABLE_COMMENT | COLUMN_NAME | DATA_TYPE | COLUMN_KEY | COLUMN_COMMENT |
|---|---|---|---|---|---|---|
| cmdb | product | Product table | product_id | bigint | PRI | Product ID |
| cmdb | product | Product table | product_name | varchar | Product name | |
| cmdb | product | Product table | group_id | varchar | Product's responsible department (group) ID | |
| cmdb | product | Product table | delete_flag | bit | Logical deletion flag 1=deleted, 0=not deleted |
Formatting the retrieved schema information into text for the prompt to be passed to the LLM
def format_schema(schema_data):
schema_str = ''
for row in schema_data:
schema_str += f"Schema: {row[0]}, Table Name: {row[1]}, Table Comment: {row[2]}, Column Name: {row[3]}, Data Type: {row[4]}, Primary Key: {'yes' if row[5] == 'PRI' else 'no'}, Column Comment: {row[6]}\n"
return schema_str
Convert each column into the following text and pass the schema information to LLM.
Schema: cmdb, Table Name: product, Table Comment: プロダクトテーブル, Column Name: product_id, Data Type: bigint, Primary Key: PRI, Column Comment: プロダクトID
Schema: cmdb, Table Name: product, Table Comment: プロダクトテーブル, Column Name: product_name, Data Type: varchar, Primary Key: no, Column Comment: プロダクト名
Schema: cmdb, Table Name: product, Table Comment: プロダクトテーブル, Column Name: group_id, Data Type: varchar, Primary Key: no, Column Comment: プロダクトの担当部署(グループ)ID
Schema: cmdb, Table Name: product, Table Comment: プロダクトテーブル, Column Name: delete_flag, Data Type: bit, Primary Key: no, Column Comment: 論理削除フラグ 1=削除, 0=未削除
Generating SQL queries from questions and schema information from the CMDB chatbot, using LLM
This is the Text-to-SQL portion, where SQL queries are generated from natural language. Based on the questions and schema information, we specify various conditions in the prompt and have LLM generate SQL.
For example, the following conditions can be specified:
- Generate valid queries for
MySQL:8.0 - Use fuzzy search for condition expressions other than ID
- Basically, exclude logically deleted data from search
- Do not generate anything other than SQL statements
- Addition of context information
- Convert questions in the forms of "... of KTC" and "... of CMDB" into "All...”
- Convert questions about region to those about AWS region
- Convert
Tokyo regiontoap-northeast-1
- Convert
The instruction "Do not generate anything other than SQL statements" is particularly important. When this was not conveyed properly, responses often ended up including unnecessary text such as: "Based on the provided information, the following SQL has been generated: SELECT~”
So, a prompt is needed that ensures SQL statements only in the form of "SELECT~" are generated without generating unnecessary text, explanations, or markdown formatting.
def generate_sql(schema_str, query):
prompt = f"""
Generate a SQL query based on the given MySQL database schema, system contexts, and question.
Follow these rules strictly:
1. Use MySQL 8.0 syntax.
2. Use `schema_name.table_name` format for all table references.
3. For WHERE clauses:
- Primarily use name fields for conditions, not ID fields
- Primarily use name fields for conditions, not ID fields
- Use LIKE '%value%' for non-ID fields (fuzzy search)
- Use exact matching for ID fields
- Use exact matching for ID fields
- Include "delete_flag = 0" for normal searches
- Use "delete_flag = 1" only when the question specifically asks for "deleted" items
CRITICAL INSTRUCTIONS:
- Output MUST contain ONLY valid SQL query.
- DO NOT include any explanations, comments, or additional text.
- DO NOT use markdown formatting.
- DO NOT generate invalid SQL query.
- DO NOT generate invalid SQL query.
Process:
1. Carefully review and understand the schema.
2. Generate the SQL query using ONLY existing tables and columns. 3. Double-check query against schema for validity.
System Contexts: - Company:
KINTO Technologies Corporation (KTC) - System:
Configuration Management Database (CMDB)
- Regions: AWS Regions (e.g., Tokyo region = ap-northeast-1)
Interpretation Rules:
- "KTC" or "CMDB" in query:Refer to all information in the database
Examples:
"
Employees in KTC" -> "All users" "KTC's products" -> "All products"
"Domains on CMDB" -> "All domains"
- Region mentions:Interpret as AWS Regions
Example:
"
ECR repositories in Tokyo region" -> "ECR repositories in ap-northeast-1"
Database Schema:
{schema_str}
Question:
{query}
"""
return llm.complete(prompt).text.strip()
Perform validation checks on SQL generated by LLM and Text-to-SQL to allow only SELECT statements
To prevent the risk of unsafe SQL generation, we connect to a read-only DB endpoint, but check whether any SQL other than queries has been generated.
Execute the SQL query generated by LLM
Generate an answer in LLM based on the SQL query generated by LLM, the results of SQL execution, and the question.
Pass the last executed SQL query, the results of SQL execution, and the question to LLM to generate an answer.
Unlike the Text-to-SQL prompt, which includes many instructions, this prompt includes fewer instructions but still specifies not to include the DB schema configuration or physical names in the answer.
def generate_answer(executed_sql, sql_result, query):
prompt = f"""
Generate an answer based on the provided executed SQL, its result, and the question.
Ensure the answer does not include information about the database schema or the column names.
Respond in the same language as the question.
Executed SQL:
{executed_sql}
SQL Result:
{sql_result}
Question:
{query}
"""
return llm.stream_complete(prompt)
Execution Result
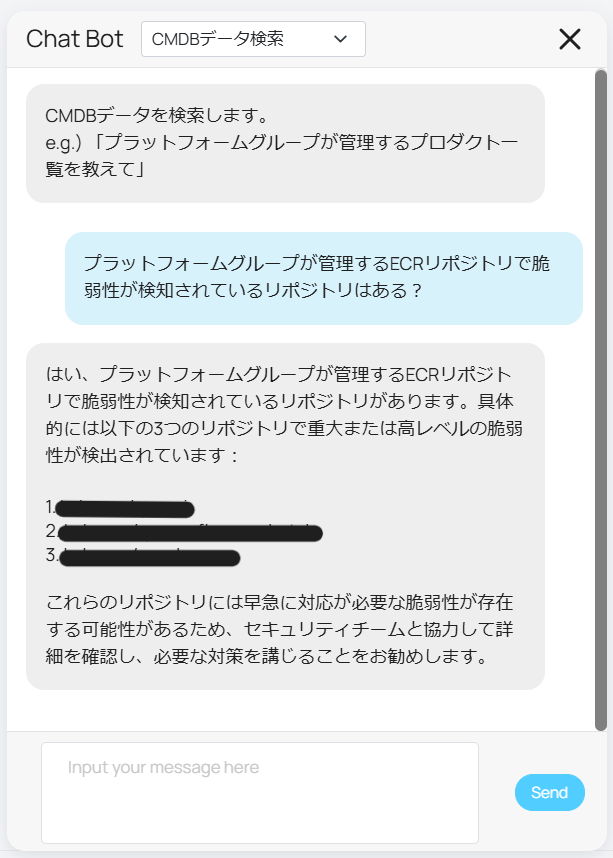
Question: Tell me the product of the platform group.
Based on this question and the database schema, LLM will generate SQL as follows:
Execution Result Question: Tell me the product of the platform group.
Based on this question and the database schema, LLM will generate SQL as follows:
SELECT product_name FROM product WHERE group_name LIKE '%プラットフォーム%' AND delete_flag = 0;
This information and the results of the SQL execution are then passed to the LLM to generate an answer.

This is the vulnerability information retrieved from the ECR scan results.
Generating a JSON object containing an SQL query using LLM based on the output request and schema information from the CMDB chatbot
Based on the natural language describing the CMDB data to be output as CSV, we will use LLM to generate a JSON object containing the column names to be output and the SQL statement to search for them. The conditions are basically the same as those for the CMDB data search function prompt, but they emphasize the instructions for generating a JSON object according to the template.
Here is the prompt:
prompt = f"""
Generate a SQL query and column names based on the given MySQL database schema, system contexts and question.
Follow these rules strictly:
1. Use MySQL 8.0 syntax.
2. Use `schema_name.table_name` format for all table references.
3. For WHERE clauses:
- Primarily use name fields for conditions, not ID fields
- Use LIKE '%value%' for non-ID fields (fuzzy search)
- Use exact matching for ID fields
- Include "delete_flag = 0" for normal searches
- Use "delete_flag = 1" only when the question specifically asks for "deleted" items
Process:
1. Carefully review and understand the schema.
2. Generate the SQL query using ONLY existing tables and columns.
3. Extract the column names from the query.
4. Double-check query against schema for validity.
System Contexts:
- Company: KINTO Technologies Corporation (KTC)
- System: Configuration Management Database (CMDB)
- Regions: AWS Regions (e.g., Tokyo region = ap-northeast-1)
Interpretation Rules:
- "KTC" or "CMDB" in query: Refer to all information in the database
Examples:
"Employees in KTC" -> "All users"
"KTC's products" -> "All products"
"Domains on CMDB" -> "All domains"
- Region mentions: Interpret as AWS Regions
Example:
"ECR repositories in Tokyo region" -> "ECR repositories in ap-northeast-1"
Output Format:
Respond ONLY with a JSON object containing the SQL query and column names:
{{
"sql_query": "SELECT t.column1, t.column2, t.column3 FROM schema_name.table_name t WHERE condition;",
"column_names": ["column1", "column2", "column3"]
}}
CRITICAL INSTRUCTIONS:
- Output MUST contain ONLY the JSON object specified above.
- DO NOT include any explanations, comments, or additional text.
- DO NOT use markdown formatting.
Ensure:
- "sql_query" contains only valid SQL syntax.
- "column_names" array exactly matches the columns in the SQL query.
Database Schema:
{schema_str}
Question:
{query}
"""
Performing validation checks on SQL generated by LLM and Text-to-SQL to allow only SELECT statements.
Execute SQL queries generated by LLM
This is the same as with the CMDB data search function.
Outputting a CSV file using the execution results
Use the SQL results and column names generated by LLM to output a CSV file.
column_names = response_json["column_names"] # LLMで生成したJSONオブジェクトからカラム名を取得
sql_result = execute_sql(response_json["sql_query"]) # LLMで生成したSQLの実行結果
csv_file_name = "output.csv"
with open(csv_file_name, mode="w", newline="", encoding="utf-8-sig") as file:
writer = csv.writer(file)
writer.writerow(column_names)
writer.writerows(sql_result)
return FileResponse(
csv_file_name,
media_type="text/csv",
headers={"Content-Disposition": 'attachment; filename="output.csv"'}
)
Execution Result
By specifying the content and columns you want to output and posting it in the chat, you can now output a CSV file as shown below.
First, LLM creates a JSON object like the one below from the chat messages and the database schema.
{
"sql_query": "SELECT service_name, group_name, repo_name, region, critical, high, total FROM ecr_scan_report WHERE delete_flag = 0;",
"column_names": ["プロダクト名", "部署名", "リポジトリ名", "リージョン名", "critical", "high", "total"]
}
The following is the process of executing SQL based on the above information and outputting a CSV file: 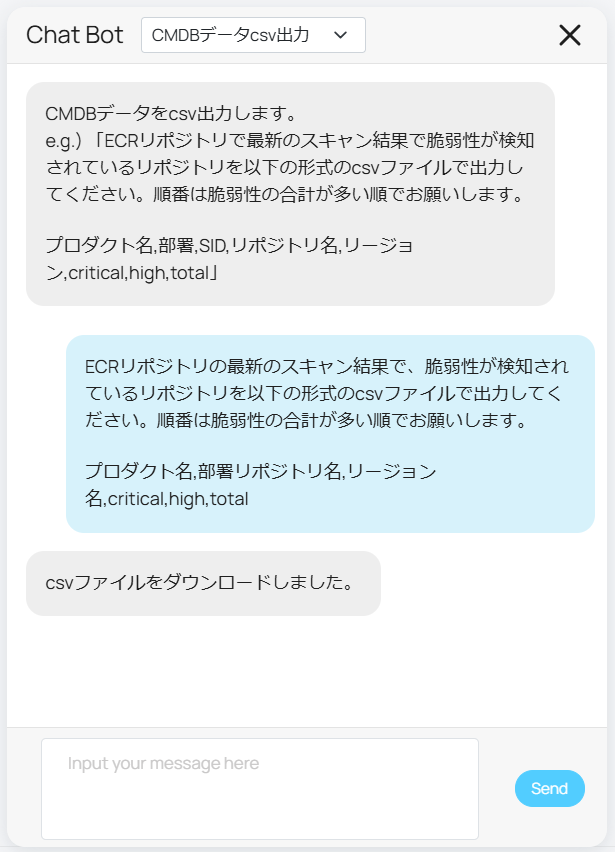
| Product name | Division name | Repository name | Region name | critical | high | total |
|---|---|---|---|---|---|---|
| CMDB | Platform | ××××× | ap-northeast-1 | 1 | 2 | 3 |
| CMDB | Platform | ××××× | ap-northeast-1 | 1 | 1 | 2 |
| CMDB | Platform | ××××× | ap-northeast-1 | 1 | 1 | 2 |
Next Steps
So far, we have utilized generative AI and Text-to-SQL to implement a CMDB data search function and a CSV data output function. However, there is still room for improvement, as outlined below:
- The CMDB data search function calls LLM twice, which makes it slow.
- Weak at answering complex and ambiguous questions
- Natural language is inherently ambiguous, allowing multiple interpretations of a question.
- Accurate understanding of schema
- Schema information is complex, and it is difficult to make the system understand the column relationship between the tables.
- Addition of context information
- Currently, the first prompt adds minimal context information. In anticipation of the future, when more context information will be added, we are considering methods to transform the question content from a large amount of context information into an appropriate question before the first LLM call. We are also exploring the possibility of fine-tuning with a dataset that includes KTC-specific context information for additional training.
- Implementing query routing
Since the APIs called from the front end are divided into two—one for CMDB data search and one for CSV output—we want to unify them into a single API and improve it so that it can determine which operation to call based on the content of the question.
Conclusion
This time, I discussed the CMDB data search function and CSV output function using generative AI and Text-to-SQL. It's difficult to keep up with new generative AI-related technologies as they continue to emerge every day. But as AI will be more involved in application development than ever before in the future, I would like to actively utilize any technologies that interest me or that seem applicable to our company's products.
関連記事 | Related Posts
We are hiring!
生成AIエンジニア/AIファーストG/東京・名古屋・大阪・福岡
AIファーストGについて生成AIの活用を通じて、KINTO及びKINTOテクノロジーズへ事業貢献することをミッションに2024年1月に新設されたプロジェクトチームです。生成AI技術は生まれて日が浅く、その技術を業務活用する仕事には定説がありません。
【シニアデータサイエンティスト(Python)】データサイエンスG/東京・大阪・名古屋・福岡
募集背景KINTOでは、事業成長とともに、データを活用したマーケティング分析の重要性が高まっています。市場やお客様の変化を捉え、より良い顧客体験を提供するため、施策の評価や課題発見、改善提案を推進できる体制強化が必要となりました。


