The Future of Generative AI: Unsolved challenges

The other day, during a casual chat with a colleague, he suddenly said: "AI has come so far in the blink of an eye. I can't even imagine what it'll be like in five years."
I'm not an AI expert, but it just so happens I've looked into it a little bit. And the answer to that question isn't as simple as saying "It'll get way better."
The thing is, there are some deep-rooted challenges in how the technology actually works.
I’m no expert, but here’s my take. I'd like to share what some of these challenges are, and what might help us get past them.
Humans as the Bottleneck
As you know, generative AI, including Large Language Models, needs a whole lot of data to learn.
And by "a whole lot," I mean enormous.
That data is collected from publicly available sources through web crawling and scraping, as well as from books, code repositories, and so on.
And the key is that all of that content is created by humans.
But we humans just aren't fast enough. We can't produce new data at the rate AI is consuming it now.
According to a paper by Pablo Villalobos from the research institute Epoch AI, if current trends continue, we could run out of high-quality, publicly available human-generated text data sometime between 2026 and 2032.
In other words, "scaling up with more data" may not work anymore beyond that point. Simply because there isn't enough new human-generated content left to feed these models.
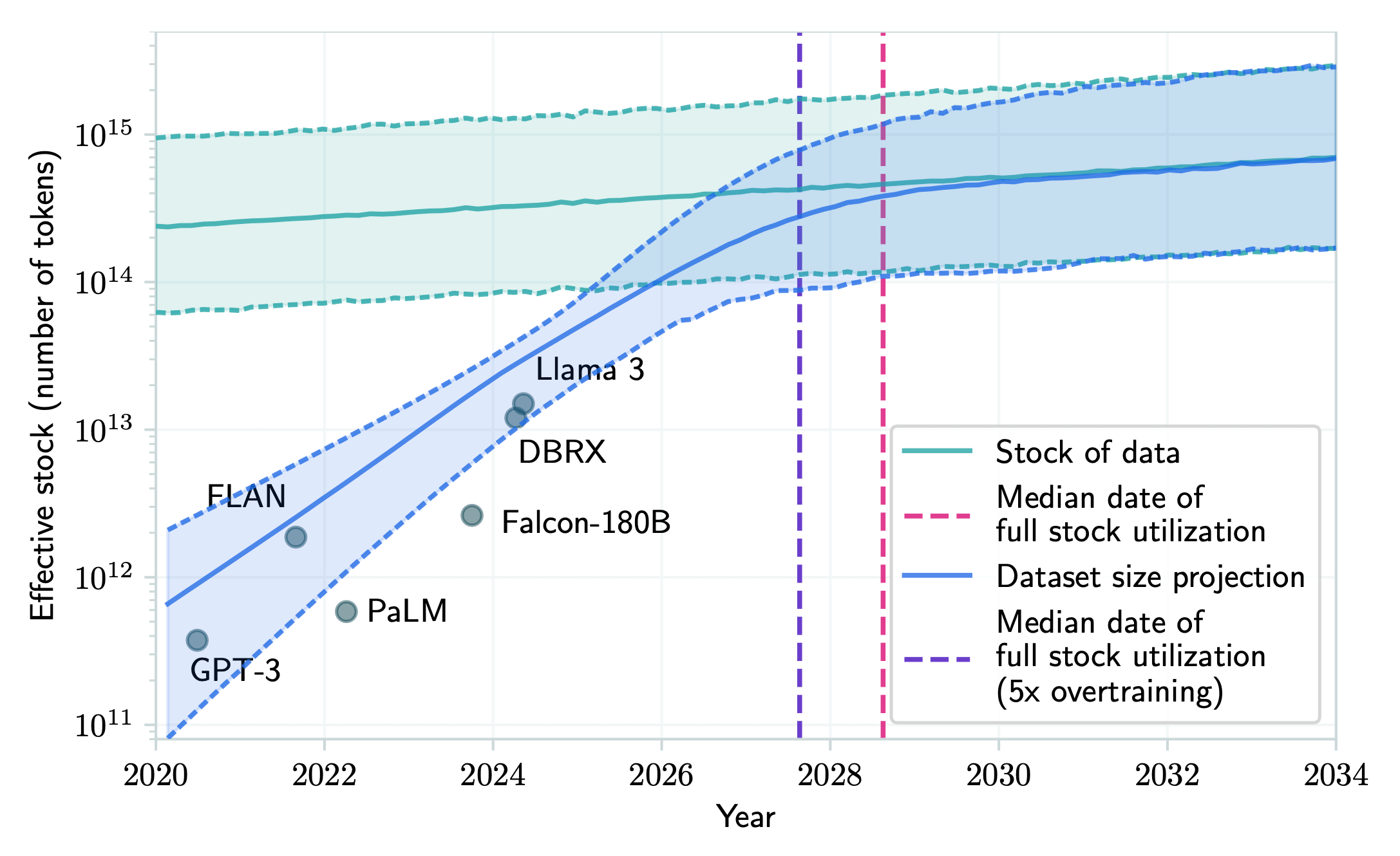 Forecasting Human-Generated Public Text and Data Consumption in LLMs
Forecasting Human-Generated Public Text and Data Consumption in LLMs
Reusing data (a technique called multi-epoch learning) has some effect, but it's not a fundamental solution.
To make matters worse, a lot of the data currently proliferating is of poor quality. For example, spam, social media comments, extremely biased information, misinformation, even illegal content.
Also, it's worth pointing out that in languages less commonly used than English, the pace at which human-generated content accumulates is naturally much slower.
Therefore, in such languages, the gap between the amount of data created by humans and the data needs of AI could become an even bigger problem.
So, what should we do about it? Here are a few of the proposed solutions:
-
Using synthetic data (i.e., data generated by AI itself) for training
While this can be effective in some areas, it also comes with a risk of "model collapse." I'll get into the details in the next section. -
Utilizing non-public data
This means using proprietary data held by companies for AI training. This obviously raises serious legal and ethical questions. In fact, some companies, such as the New York Times, have already banned AI vendors from scraping their content. -
Improving model efficiency
Instead of just making models bigger, the idea is to train them to learn smarter.
Actually, we're starting to see signs of this shift. When using tools like ChatGPT, we can see something like "reasoning" where the model links multiple steps logically, rather than just recalling memorized information.
Inbreeding in Generative Models
As mentioned earlier, one way to increase the amount of training data is to generate more of it.
But this comes with its own risks.
In this paper, Zakhar Shumaylov from the University of Cambridge investigates the question: "What happens when we train a next-generation model on data generated by past AI models, rather than by humans?"
The authors point to a dangerous feedback loop called model collapse.
When AI-generated data is used over and over again for training, the model gradually drifts away from the original distribution of real-world data.
As a result, its outputs become more generic, monotonous, and distorted. In particular, rare and subtle features are more likely to get lost.
This mainly happens for two reasons:
- Statistical errors build up over generations, due to a limited sample
- Functional errors emerge because the model can't perfectly reproduce complex data distributions
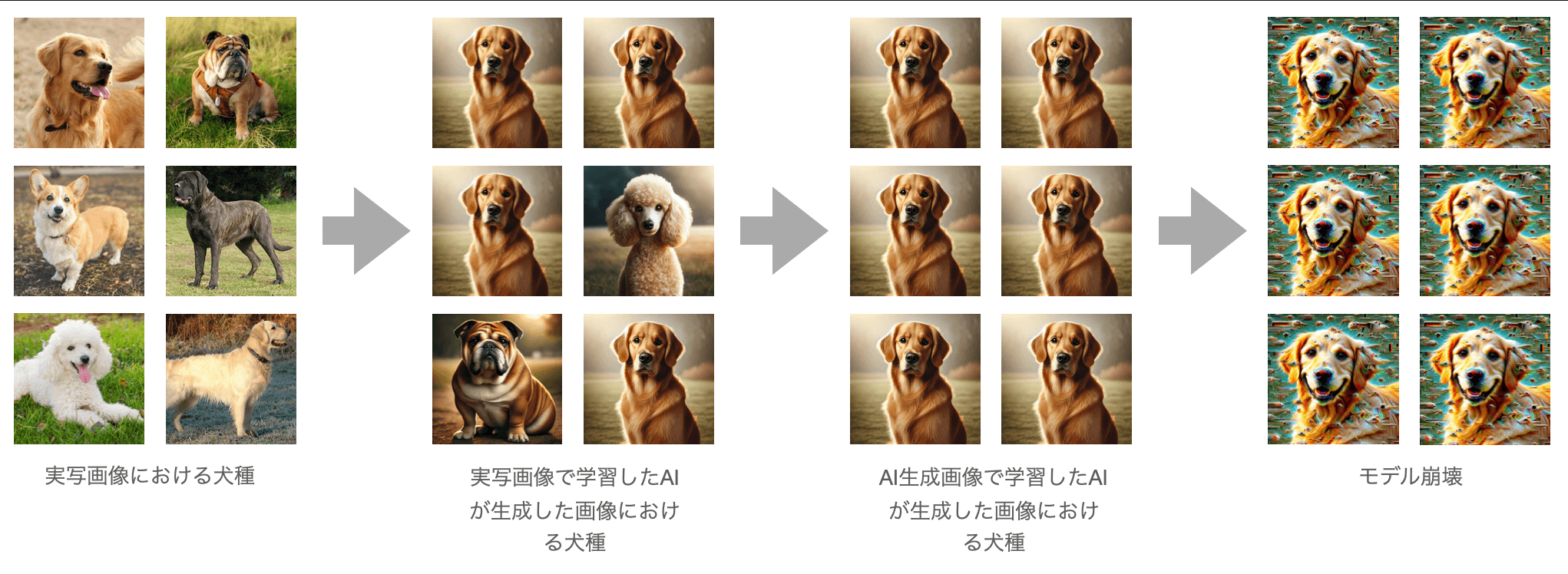
Visual images of model collapse
Interestingly, keeping just 10% of the original human-generated data can help reduce model collapse to some extent.
However, it cannot be completely prevented.
Unless we make a deliberate effort to preserve real, human-generated data, AI models will increasingly end up trapped in a narrow, self-reinforcing worldview.
It's effectively digital inbreeding.
Furthermore, Gabrielle Stein from East Carolina University explored whether this issue could be avoided by using "cross-model learning," in which AIs exchange and learn from each other's data.
The conclusion? It didn't really make much of a difference.
In her study, she trained models on different proportions of human data: 100%, 75%, 50%, 25%, and 0%.
The results showed the following trends:
- As the proportion of synthetic data increased, linguistic diversity steadily declined
- No "tipping point" was observed where performance suddenly collapsed at a specific percentage
- Even a small amount of human data helped slow the rate of degradation
She suggests that to avoid early-stage model collapse, at least half of the training data should reliably come from confirmed human-written content.
Considering that much of the data we see online is generated by AI, and that most AI training data is scraped from the Internet, it paints a somewhat bleak picture for the future of AI.
As AI-generated content increasingly makes its way into training data, the risk of causing model collapse in the future keeps growing.
Still, there are some fresh, innovative approaches are emerging that could lead to a breakthrough.
What Comes Next?
To address the challenges I've covered so far, a few relatively new approaches have started to emerge.
While they're not permanent solutions, they might be able to delay the collapse caused by inbreeding and data shortages for a while.
One example already mentioned is AI reasoning.
This refers to behavior in models like ChatGPT, where the model goes through multiple steps of internal reasoning and judgment before producing a final answer.
Another promising method is called Retrieval-Augmented Generation (RAG).
Put simply, this approach lets AI models generate responses not just from their training data, but also by pulling in external documents.
For example, feeding a PDF into an LLM or letting it search the Internet before answering a question would fall into this category.
That said, as you can probably guess, this doesn't solve the underlying problem of a lack of data.
After all, the amount of new, reliable information we can feed into a model is still limited.
So, what are promising approaches that haven't been fully realized yet?
One example is the trend toward synthetic reality and embodied agents.
This is a completely different approach to AI development.
Instead of learning passively from static datasets, the idea is to place AI agents in dynamic virtual environments where they act, explore, and adapt to achieve goals.
The data obtained is self-generated, produced through experiencing results, testing hypotheses, and planning strategies.
It's contextual, diverse, grounded in interaction, and extremely high in quality.
This method enables sustainable and self-renewing learning in environments with near-infinite variation.
Regardless of the exhaustion of human-written text, it helps avoid the trap of AI being stuck in its own output.
...However, we're not there yet.
Sure, we've been successful at offloading all sorts of boring tasks onto AI.
But for now, it looks like we still have a fair amount of work to do ourselves.
Thanks for reading!
関連記事 | Related Posts





We are hiring!
生成AIエンジニア/AIファーストG/東京・名古屋・大阪・福岡
AIファーストGについて生成AIの活用を通じて、KINTO及びKINTOテクノロジーズへ事業貢献することをミッションに2024年1月に新設されたプロジェクトチームです。生成AI技術は生まれて日が浅く、その技術を業務活用する仕事には定説がありません。
【UI/UXデザイナー】クリエイティブ室/東京・大阪・福岡
クリエイティブGについてKINTOやトヨタが抱えている課題やサービスの状況に応じて、色々なプロジェクトが発生しそれにクリエイティブ力で応えるグループです。所属しているメンバーはそれぞれ異なる技術や経験を持っているので、クリエイティブの側面からサービスの改善案を出し、周りを巻き込みながらプロジェクトを進めています。
イベント情報
![[Mirror]不確実な事業環境を突破した、成長企業6社独自のエンジニアリング](/assets/banners/thumb1.png)

