生成AIの未来:いまだに解決されない課題

先日、同僚との何気ない会話の中で、こんな言葉をふいに投げかけられました。
「AIって、あっという間にここまで来たよね。あと5年もしたら、何ができるようになるか想像もつかないよ。」
自分はAIの専門家ではありません。ですが、たまたまその分野について少し調べたことがあるんです。
そして、その問いに対する答えは「もっと進化してすごくなる」という単純なものではありません。
というのも、AIの発展には、その技術の本質に根ざした壁がいくつか存在しているのです。
繰り返しますが、自分は専門家ではありません。
ただ、その壁とは何か、そしてそれをどう乗り越えられる可能性があるのか、それをお話ししたいと思います。
ボトルネックとしての人間
ご存知のとおり、大規模言語モデルをはじめとする生成AIは、学習のためにデータを必要とします。
しかも、その量は膨大です。
そのデータは、Webクローリングやスクレイピングを通じてインターネット上の公開情報から収集されたり、本やコードのリポジトリなどから集められたりします。
そして重要なのは、それらのコンテンツは基本的に人間が作っているという点です。
ですが、私たち人間は、AIが消費できる速度で新しいデータを作るには、あまりにも遅すぎるのです。
Epoch AI研究所のPablo Villalobosさんが執筆した論文によると、現在の傾向が続けば、2026年から2032年の間に、高品質で公開されている人間のテキストデータが枯渇するとされています。
つまり、それ以降は「データを増やしてスケールさせる」というアプローチが通用しなくなるかもしれません。なぜなら、学習に使える新しい人間由来のコンテンツが、もう十分に残っていないからです。
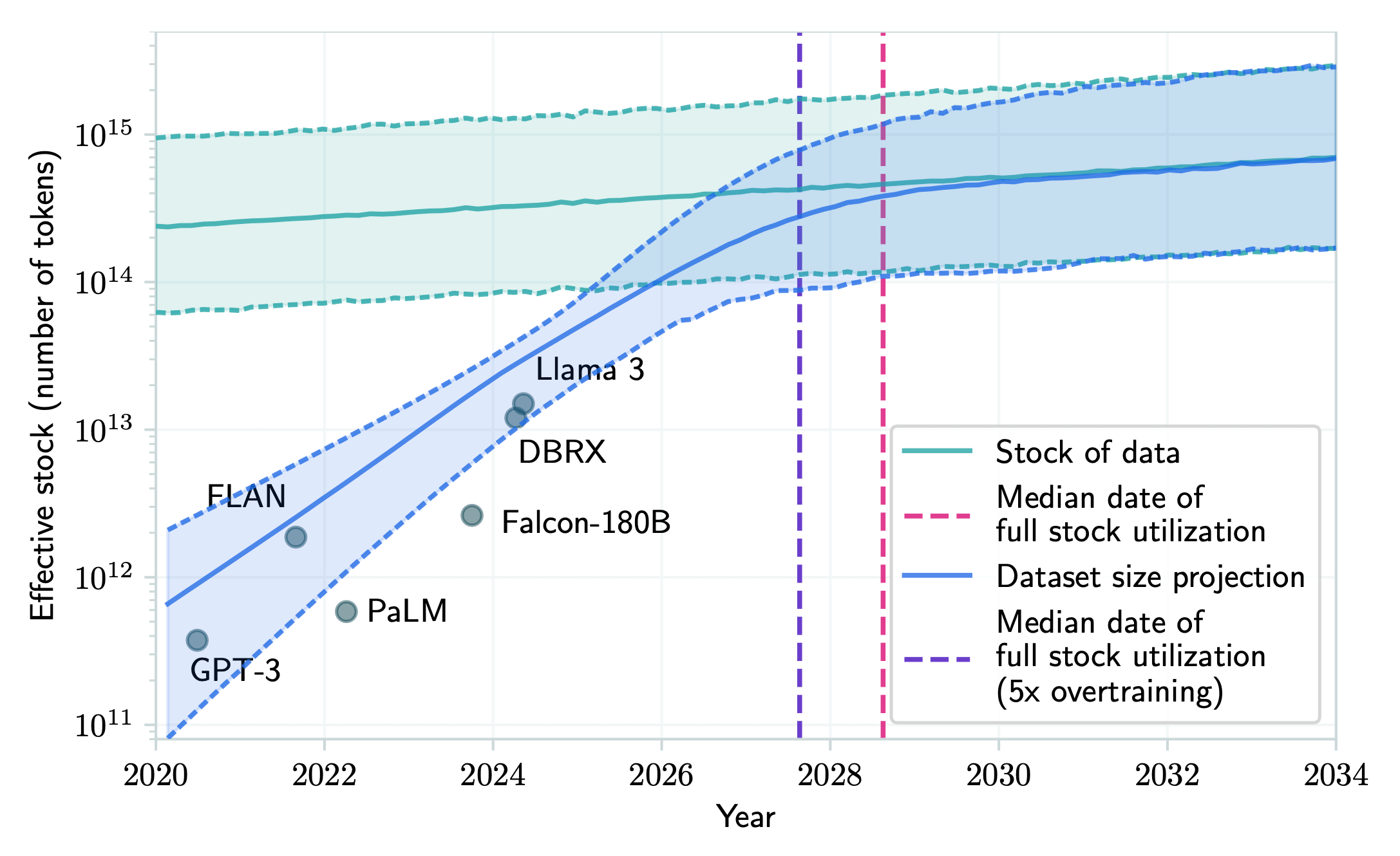
人間が生成した公開テキストの実効ストックおよびLLM学習におけるデータ消費量の予測
データの再利用(いわゆるマルチエポック学習)は一定の効果がありますが、根本的な解決にはなりません。
さらに悪いことに、現在急増しているデータの中には、質の低いものが多く含まれています。例えば、スパム、SNSのコメント、極端に偏った情報、誤情報、違法なコンテンツなどです。
また、人間が生成するデータは、英語のような広く使われている言語に比べて、あまり普及していない言語では自然と蓄積のペースが遅くなることも指摘しておくべきかもしれません。
そのため、そういった言語においては「人間が作るデータ量」と「AIのデータ需要」とのギャップが、さらに深刻になる可能性があります。
では、どうすればよいのでしょうか? 提案されている解決策の例としては、以下のようなものがあります:
-
合成データ(つまりAIが生成したデータ)を学習に使う
分野によっては効果が見込めますが、「モデル崩壊」というリスクも伴います。この問題については次のセクションで詳しく説明します。 -
非公開データを活用する
つまり、企業などが保有しているデータをAI学習に利用するということです。当然ながら、法的・倫理的に重大な問題が生じます。実際に、New York Timesのように、自社コンテンツのスクレイピングをAIベンダーに禁止する企業も出てきています。 -
効率性の向上
単に大きくするのではなく、賢く学習させるというアプローチです。
実際、最近のモデルではその兆しが見え始めています。ChatGPTなどを使っていると、「推論(reasoning)」のような、ただの記憶の再生ではなく、複数のステップを論理的につなげる動きが見られるようになっています。
生成モデルの近親交配
先ほど触れたように、学習に使えるデータ量を増やす方法のひとつが、データを生成してしまうことです。
ですが、これには独自のリスクがついてきます。
こちらの論文では、ケンブリッジ大学のZakhar Shumaylovさんが、「人間ではなく、過去のAIモデルが生成したデータで次世代のモデルを学習させると何が起こるのか?」を調査しています。
著者らは、モデル崩壊(Model Collapse)と呼ばれる危険なフィードバックループを指摘しています。
AI生成データでの学習が繰り返されると、モデルは現実世界の本来のデータ分布から徐々にズレていきます。
その結果、出力はより一般的に、単調に、そして歪んだものになっていくのです。特に、まれで繊細な特徴は失われやすくなります。
これは主に以下の2つの理由によって起こります:
- 有限なサンプルにより統計的な誤差が世代を重ねるごとに蓄積される
- 複雑な分布を完全には再現できないことで機能的な誤差が生じる
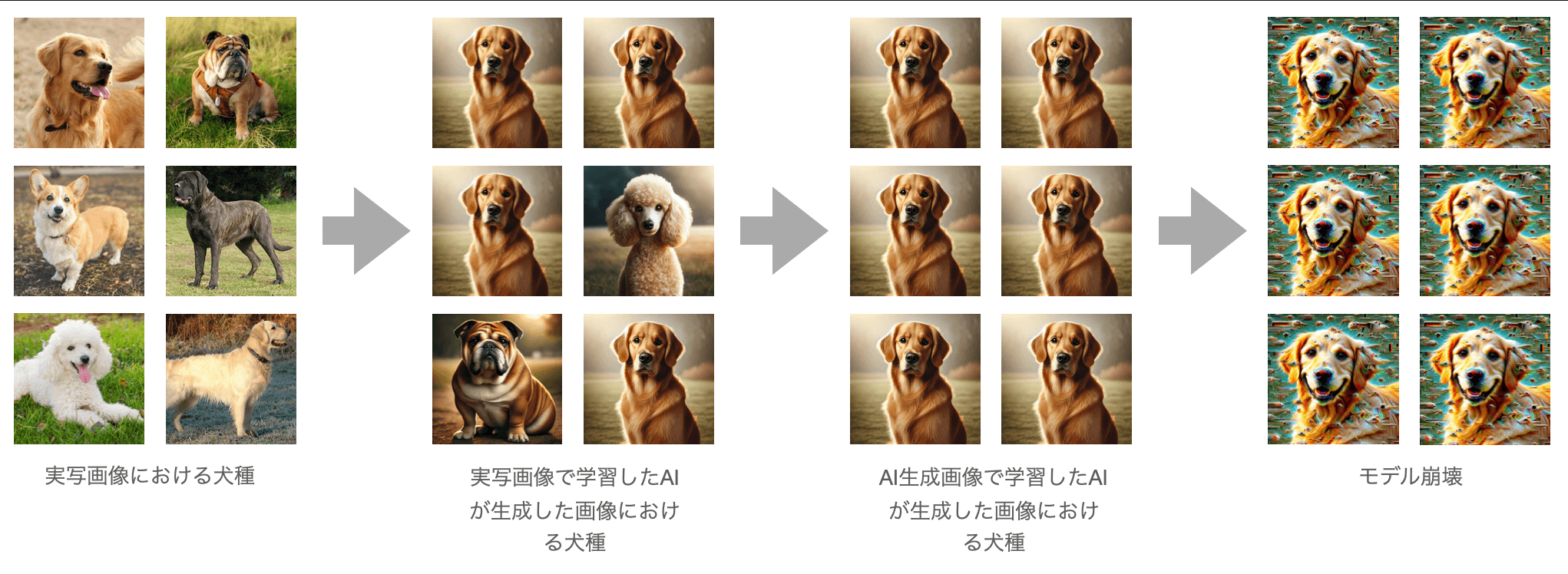
モデル崩壊の視覚的イメージ
興味深いことに、人間が生成した元データを10%だけでも保持すれば、モデル崩壊をある程度抑える効果があります。
ですが、完全に防ぐことはできません。
人間による本物のデータを意図的に残さない限り、AIモデルはどんどん狭くて自己強化的な世界観に閉じこもっていくことになります。
まさにデジタルな近親交配です。
さらに、イーストカロライナ大学のGabrielle Steinさんは、AI同士でデータを受け渡す形の「クロスモデル学習」でこの問題が回避できるのかを検証しました。
結論としては…あまり効果はなかったようです。
彼女の研究では、100%、75%、50%、25%、0%といった異なる人間データの割合でトレーニングを実施しました。
その結果、以下のような傾向が見られました:
- 合成データの割合が増えるにつれて、言語的多様性が徐々に減少
- 特定の割合で急激に崩壊が進むような「転換点」は見られなかった
- わずかでも人間のデータを混ぜることで、劣化のスピードは抑えられた
彼女は、全体の半分以上を確実に人間が書いたと確認できるコンテンツで構成することが、モデル崩壊を初期段階で食い止める有効な対策だと提案しています。
インターネット上で目にするデータの多くがAIによって生成されたものであり、しかもAIの学習素材のほとんどがインターネットから集められていることを考えると、AIの未来はやや暗いものに見えてくるかもしれません。
AI生成コンテンツが学習データにますます入り込むことで、将来的にモデル崩壊を引き起こすリスクが高まっているのです。
しかし、状況を打開できるかもしれない新たな先進的アプローチも登場しつつあります。
次に来るものは?
ここまで紹介してきた課題を解決するために、比較的新しいアプローチが最近少しずつ登場しています。
恒久的な解決策とはいかないまでも、「近親交配+データ不足による崩壊」をしばらくのあいだ先延ばしにすることはできるかもしれません。
すでにひとつ例として挙げたのが、AIの「推論(Reasoning)」です。
これは、ChatGPTのようなモデルが最終的な回答を出す前に、複数のステップで内部的に思考・判断を行うような動きです。
もうひとつ有望とされているのが、検索拡張生成(Retrieval-Augmented Generation / RAG)という手法です。
簡単に言えば、AIモデルが学習済みデータだけでなく、外部から提供されたドキュメントの情報も使って応答を生成するというアプローチです。
たとえば、LLMにPDFファイルを読み込ませたり、回答の前にインターネット検索させたりするようなケースが該当します。
とはいえ、察しがつくかもしれませんが、これも本質的なデータ不足の問題を解決するわけではありません。
なぜなら、モデルに与えられる新しい情報には限りがあるからです。
では、まだ本格的には実現されていないものの、有望とされるアプローチは何でしょうか?
その一例が、仮想現実環境+エンボディド・エージェント(Synthetic Reality + Embodied Agents)という方向性です。
これはAI開発において従来とはまったく異なる発想です。
静的なデータセットから受動的に学ぶのではなく、AIエージェントを動的な仮想環境に配置し、目標達成のために行動・探索・適応をさせるのです。
そこで得られるのは、結果を体験し、仮説を試し、戦略を立てる中で自ら生成したデータです。
それは、文脈があり、多様性があり、因果関係に基づいた、極めて質の高い情報です。
この方法であれば、無限に近いバリエーションを持つ環境の中で、持続可能かつ自己更新型の学習が可能になります。
人間が書いたテキストの枯渇に依存せず、AI自身の出力に閉じこもるリスクも避けられます。
……とはいえ、現時点ではまだこの段階には到達していません。
つまり、退屈な作業をいろいろとAIに押し付けることには成功しましたが──
少なくとも今後しばらくの間は、私たち自身がそれなりに働く必要がありそうです。
それでは、また!
関連記事 | Related Posts
生成AIの未来:いまだに解決されない課題

Introduction to our Generative AI Development Project

Exploring DeepSeek R1 with Azure AI Foundry

Is Generative AI Leading Users to Tech Support Scam Websites?

Introducing an evaluation system into generative AI application development to improve accuracy: Initiatives to automate database design reviews

How to Auto-Generate Tech Blog Cover Images with an Image‑Generation AI
We are hiring!
生成AIエンジニア/AIファーストG/東京・名古屋・大阪・福岡
AIファーストGについて生成AIの活用を通じて、KINTO及びKINTOテクノロジーズへ事業貢献することをミッションに2024年1月に新設されたプロジェクトチームです。生成AI技術は生まれて日が浅く、その技術を業務活用する仕事には定説がありません。
【UI/UXデザイナー】クリエイティブ室/東京・大阪・福岡
クリエイティブGについてKINTOやトヨタが抱えている課題やサービスの状況に応じて、色々なプロジェクトが発生しそれにクリエイティブ力で応えるグループです。所属しているメンバーはそれぞれ異なる技術や経験を持っているので、クリエイティブの側面からサービスの改善案を出し、周りを巻き込みながらプロジェクトを進めています。


