AI-SPM Initiatives for Securing LLM Applications

Introduction
Hello, I’m Tada from the Security CoE Group at KINTO Technologies. I usually work in the Osaka Office. Our group is taking on various challenges related to cloud security, with the mission of "implementing guardrail monitoring and kaizen activities in real time" in a multi-cloud environment. You can find a summary of what activities our members’ daily activities on this blog.
Background
Following the trend of developing LLM (Large Language Model) applications in the world, our product team has been actively developing numerous LLM applications, many of which have progressed to the PoC or product-ready stage. Meanwhile, as a group responsible for monitoring cloud security, it is essential that we implement appropriate security measures for these applications as well.
Our LLM applications are primarily developed on AWS, Google Cloud, and Azure, and are often built using generative AI services provided by cloud vendors. Our group monitors and operates Cloud Security Posture Management (CSPM). However, currently there are no CSPM controls specifically tailored for generative AI-related services. For example, in the case of AWS, neither the AWS Foundational Security Best Practices (FSBP) nor the Center for Internet Security (CIS) provide direct controls related to generative AI services.
Therefore, our group has established guidelines to be followed when developing LLM applications using each cloud vendor’s generative AI services. The guidelines also include recommended usage practices and configuration methods for each vendor’s generative AI services. In other words, the configuration methods described in the guidelines are the controls that should be monitored as part of CSPM. Additionally, the control is implemented in Rego language and is operated as part of CSPM for AWS Bedrock.
The term AI-SPM in the title stands for AI Security Posture Management. It is defined as "a solution for visualizing, managing, and mitigating security and compliance risks of AI-related assets such as AI, machine learning (ML), and generative AI models." Given this definition, I deliberately chose to name this initiative AI-SPM.
Security Guidelines to be Followed for LLM Applications
In creating the guidelines, we referred to the OWASP Top 10 for LLM Applications 2025. This document is probably a go-to resource when discussing LLM application security. This OWASP document lists the top 10 most critical vulnerabilities commonly seen in LLM applications and includes sections such as "Overview," "Examples of Vulnerabilities," "Mitigation Strategies," and "Attack Scenarios." Based on this content, I reviewed the services and features used in each cloud environment and considered best practices for developing LLM applications accordingly.
The first risk listed in the top 10 is "LLM01: Prompt Injection."
This refers to the risk that malicious input may unintentionally manipulate the behavior of LLM, resulting in data leakage or unauthorized actions. To prevent and mitigate this risk, validation and filtering of input to LLM is an effective measure. When implementing this prevention and mitigation measure on cloud services, AWS offers a feature in Amazon Bedrock Guardrails to filter prompt attacks. So, enabling this feature serves as an effective countermeasure. After that, by checking whether this feature is enabled as a CSPM control, it becomes possible to achieve both visibility and kaizen.
Below is a summary of the most common risks from the Top 10, along with corresponding "Prevention and Mitigation Strategies" and "Implementation of CSPM controls" for AWS services.
| Top 10 | Risk Overview | Prevention and Mitigation Strategies | Implementation on AWS | Implementation of CSPM controls |
|---|---|---|---|---|
| LLM01: Prompt Injection | Risk that malicious input (prompts) may unintentionally manipulate the behavior of LLM, leading to data leakage or unauthorized actions. | Model behavior restrictions, input/output validation, filtering, authority control, and human approval, etc. | Use the "Prompt attacks" content filters in Amazon Bedrock Guardrails. | Ensure that the configure prompt attacks filter is enabled, the action is set to "Block," and the threshold is set to "HIGH." |
| LLM02: Sensitive Information Disclosure | Risk of sensitive information, such as personal information or confidential data, may be leaked through the model’s responses or behavior. | Output validation and filtering, training data management, and access controls. | Use the "Sensitive information filters" in Amazon Bedrock Guardrails. | Verify that the Sensitive information filters are enabled for Output. |
| LLM06: Excessive Agency | Risk of unintended actions or manipulations due to granting excessive autonomy or authority to LLMs or their agents | Enforcement of least authority, human approval, and authority auditing. | Use the "Agent" feature in Amazon Bedrock Builder tools. | When using Agents, verify that Guardrail details are properly associated with them. |
| LLM09: Misinformation | Risk that the LLM may generate outputs containing misinformation or bias, causing adverse effects on users or society. | Train on diverse and reliable data, fact-check, and provide source attribution. | Use the "contextual grounding check" feature in Amazon Bedrock Guardrails. | Verify that contextual grounding check is enabled. |
| LLM10: Unbounded Consumption | Uncontrolled resource consumption by LLMs may lead to DoS, increased costs, and service outages, resulting from unrestricted requests or computational usage. | Resource limits, quota settings, and usage monitoring | Use the "Model invocation logging" feature in Amazon Bedrock. | Verify that Model Invocation Logging is enabled. |
I presented the above content at a co-hosted event, Cloud Security Night #2, held in May. Please feel free to refer to the materials here for more details.
Implementing CSPM Controls with Rego
Now that the CSPM controls have been defined, the next step is to develop a mechanism for checking the control configurations. In our group, we operate CSPM using Security Hub for AWS, Sysdig for Google Cloud, and Defender for Cloud for Azure. While using a unified tool would be ideal, we don’t heavily rely on cloud provider consoles. Instead, we monitor CSPM alerts through APIs and send notifications to Slack when necessary. As such, the lack of tool integration hasn’t posed any particular inconvenience.
For the CSPM controls of the LLM application, we decided to implement them using Rego, the policy language used in Sysdig’s CSPM features. The reason we chose Rego is that it’s OSS, and for defining evaluation logic for cloud infrastructure settings, such as CSPM controls, it offers a relatively low learning curve and is easy to develop with.
Below is the LLM01:Prompt Injection control implemented in Rego. What it does is set risky == true (risk present) as the default value. If the ContentPolicy.Filters setting in Bedrock Guardrails has Type == PROMPT_ATTACK and InputStrength==HIGH, it determines that the Prompt attack filter is enabled and the threshold is set to High. In this case, it sets risky == false, meaning no risk is present.
default risky := true
risky := false if {
some filter in input.ContentPolicy.Filters
lower(filter.Type) == "prompt_attack"
lower(filter.InputStrength) == "high"
}
This Rego needs to be deployed to Sysdig as a Sysdig custom control. For detailed instructions on how to create and deploy custom controls, please see the official Sysdig blog here. We also used this as a reference during our development process. While not covered in this blog post, we accumulated a great deal of know-how on creating custom controls.
Custom controls must be deployed to Sysdig as a terraform. The following is the final main.tf used to create the custom control.
terraform {
required_providers {
sysdig = {
source = "sysdiglabs/sysdig"
version = ">=0.5"
}
}
}
variable "sysdig_secure_api_token" {
description = "Sysdig Secure API Token"
type = string
}
provider "sysdig" {
sysdig_secure_url="https://app.us4.sysdig.com"
sysdig_secure_api_token = var.sysdig_secure_api_token
}
resource "sysdig_secure_posture_control" "configure_prompt_attack_strength_for_amazon_bedrock_guardrails" {
name = "Configure Prompt Attack Strength for Amazon Bedrock Guardrails"
description = "Ensure that prompt attack strength is set to HIGH for your Amazon Bedrock guardrails. Setting prompt attack strength to HIGH in guardrails helps protect against malicious inputs designed to bypass safety measures and generate harmful content."
resource_kind = "AWS_BEDROCK_GUARDRAIL"
severity = "High"
rego = <<-EOF
package sysdig
import future.keywords.if
import future.keywords.in
default risky := true
risky := false if {
some filter in input.ContentPolicy.Filters
lower(filter.Type) == "prompt_attack"
lower(filter.InputStrength) == "high"
}
EOF
remediation_details = <<-EOF
## Remediation Impact
This control will help you ensure that your Amazon Bedrock guardrails are configured with high prompt attack strength, which is crucial for protecting against malicious inputs designed to bypass safety measures and generate harmful content.
## Remediation Steps
1. Navigate to the [Amazon Bedrock console](https://console.aws.amazon.com/bedrock/home).
2. Select the guardrail you want to modify.
3. In the guardrail settings, locate the "Content Policy" section.
4. Ensure that the "Prompt Attack" filter is set to "High" for the "Input Strength".
5. Save the changes to the guardrail configuration.
6. Repeat this process for any other guardrails in your AWS environment.
## Remediate Using Command Line
You can use the AWS CLI to update the guardrail configuration. Run the following command to set the prompt attack strength to HIGH for a specific guardrail:
```bash
aws bedrock update-guardrail --guardrail-id <guardrail-id> --content-policy ’{"Filters": [{"Type": "prompt_attack", "InputStrength": "high"}]}’
```
Replace `<guardrail-id>` with the ID of your guardrail.
Repeat this command for other guardrails in your AWS environment.
## Additional Information
For more information on configuring Amazon Bedrock guardrails, refer to the [Amazon Bedrock documentation](https://docs.aws.amazon.com/bedrock/latest/userguide/guardrails.html).
## Contact Information
Slack Channel: #security-coe-group
EOF
}
Initially, Sysdig did not support Amazon Bedrock as a target resource for CSPM. However, after reaching out to Sysdig, they responded with impressive speed, which made this initiative possible. Beyond the functionality, this kind of responsiveness is incredibly reassuring as a Sysdig user.
Following the same approach, we implemented several of the controls listed in the Security Guidelines to be Followed for LLM Applications using Rego and deployed them to Sysdig.
AI-SPM Operations by Sysdig
Several of the custom controls that were deployed are defined as custom policies, enabling visibility into AWS Bedrock resources. Based on the results of this visibility, any identified issues are addressed through kaizen. In our company, our group submits kaizen requests to the product development group, always including both the issue and kaizen methods.
The screen below shows the Sysdig console, where the CSPM control for LLM01:Prompt Injection is being reviewed. The control name is Configure Prompt Attack Strength for Amazon Bedrock Guardrails. The naming was done to align with its intended role. The status indicates that there are three AWS Bedrock Guardrail resources, one is marked as Failling, while the remaining two are Passing.
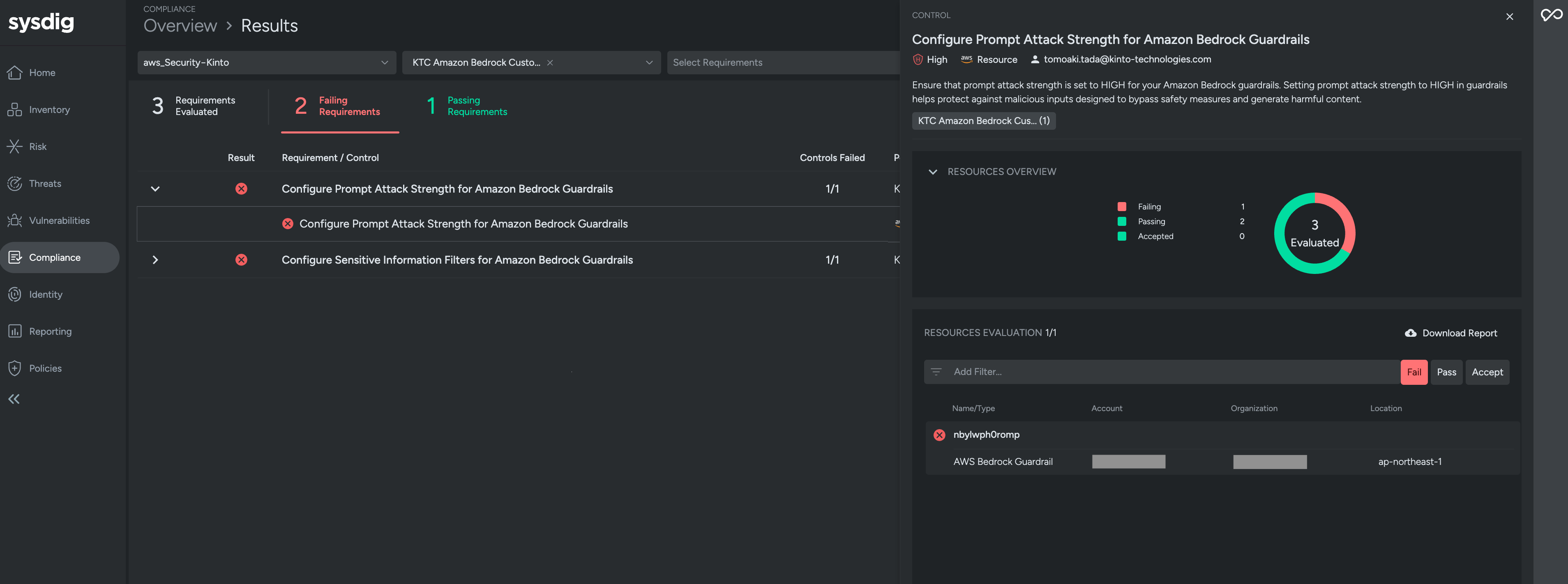
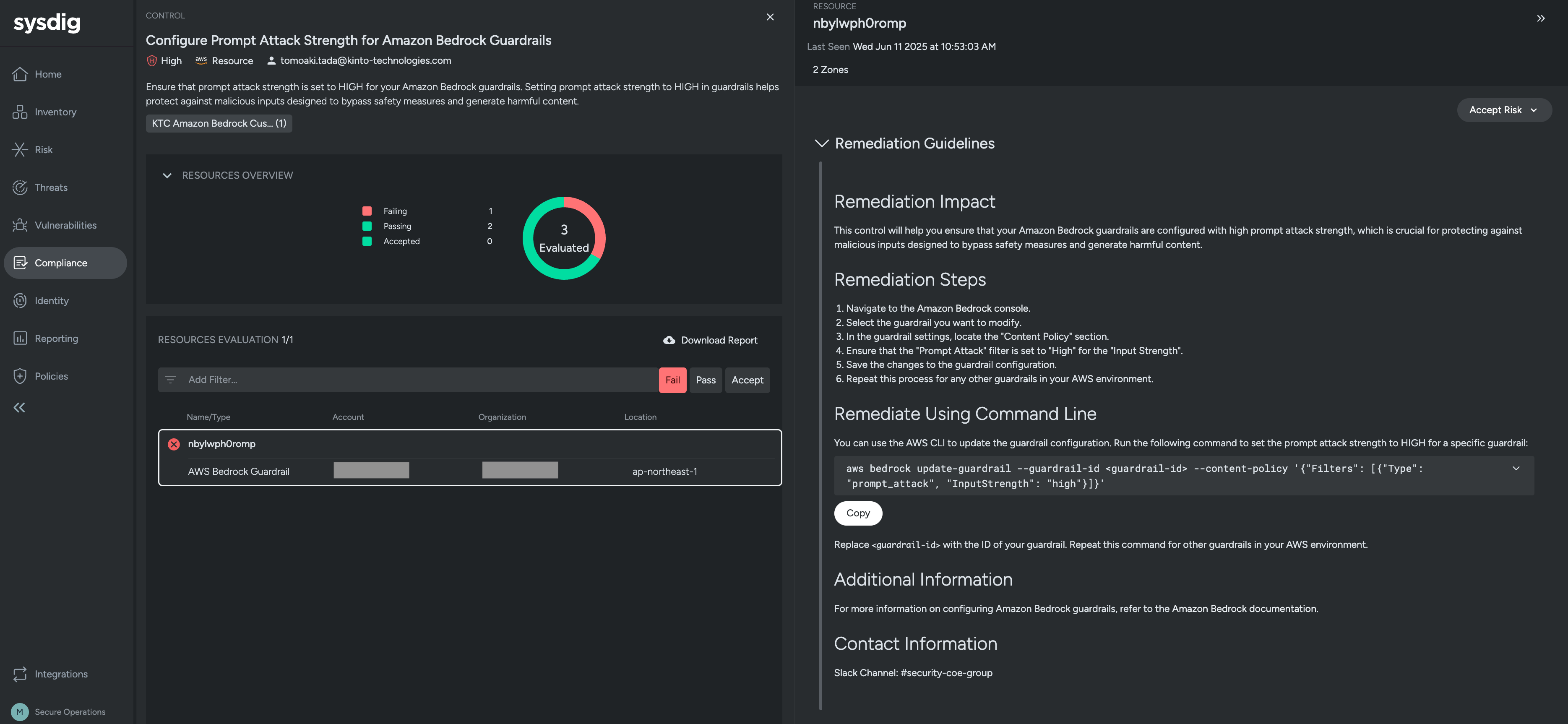
By drilling down into the above screen, you can see the impact of kaizen and how to kaizen. This content also reflects the contents written in main.tf.
However, in actual operations, we rarely access the Sysdig console directly. Instead, we typically check alerts through the Sysdig API.
Conclusion
In this article, I introduced an approach to securing LLM applications by developing Rego-based configuration checks for Amazon Bedrock and operating them using Sysdig. The guidelines not only include Amazon Bedrock but also Azure AI Foundry and Google Cloud Vertex AI, and we plan to continue developing Rego policies and operating them through Sysdig.
In addition to traditional CSPM, AI-SPM must go beyond general cloud infrastructure security, such as AI-specific challenges and the protection of data assets, which traditional CSPM cannot fully cover. AI technology is evolving rapidly, with new concepts such as MCP and A2A emerging recently. It is also important to promote security measures that correspond to these developments.
We will continue to enhance the security of AI applications while staying aligned with new technologies and challenges.
Lastly
The Security CoE Group is looking for people to work with us. We welcome not only those with hands-on experience in cloud security but also those who may not have experience but have a keen interest in the field. Please feel free to contact us.
For more information, please check here.
関連記事 | Related Posts

We are hiring!
【クラウドエンジニア】Cloud Infrastructure G/東京・大阪・福岡
KINTO Tech BlogWantedlyストーリーCloud InfrastructureグループについてAWSを主としたクラウドインフラの設計、構築、運用を主に担当しています。
【クラウドプラットフォームエンジニア】プラットフォームG/東京・大阪・福岡
プラットフォームグループについてAWS を中心とするインフラ上で稼働するアプリケーション運用改善のサポートを担当しています。




