My Experience Trying Out Strands Agents

Introduction
Hello!
I’m Uehira from the DataOps Group in the Data Strategy Division at KINTO Technologies.
I’m mainly responsible for the development, maintenance, and operation of our internal data analytics platform and an in-house AI-powered application called "cirro."
"cirro" uses Amazon Bedrock for its AI capabilities, and we interact with it via the AWS Converse API.
In this article, I’ll share how I tested Strands Agents in a local environment to explore tool integration and multi-agent functionality for potential use in "cirro."
Intended Audience
This article is intended for readers who have experience using Amazon Bedrock via the Converse API or Invoke Model API.
What Is Strands Agents?
Strands Agents is an open-source SDK for building AI agents, released on May 16, 2025, on the AWS Open Source Blog.
The diagram below is from the official Amazon Web Services blog:
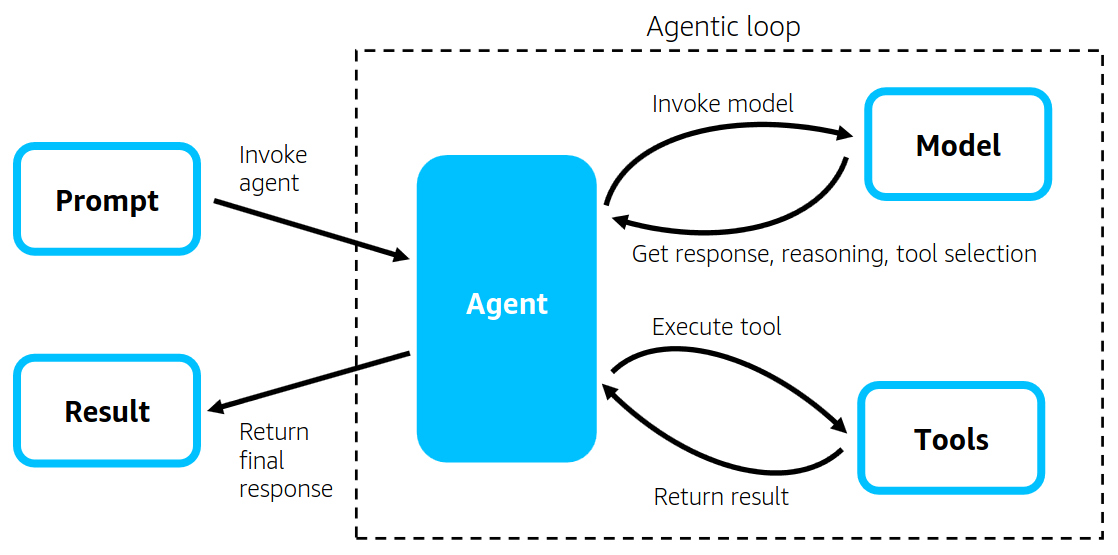
As shown in the diagram, implementing an AI that can use tools requires a processing structure known as an Agentic Loop.
This loop allows the AI to determine whether its response should go directly to the user or whether it should take further action using a tool.
With Strands Agents, you can build AI agents that include this loop without needing to implement it manually.
Source: Introducing Strands Agents – An Open-Source AI Agent SDK
Running Strands Agents in a Local Environment
*This section assumes that you have prior experience using Bedrock via the Converse API or similar tools.
Therefore, basic setup steps such as configuring model permissions are omitted. Exception handling is also skipped, as this is a sample implementation.
Setup
- Libraries Install the required libraries with the following command:
pip install strands-agents strands-agents-tools
Execution ①
If you're lucky, the following minimal code might work:
from strands import Agent
agent = Agent()
agent("こんにちは!")
This code appears in many blog posts, but it didn't work in my environment. 😂
Which makes sense—after all, it doesn’t specify the model or the Bedrock region...
Execution ②
To call the model properly, you need to explicitly specify the model and region like this:
In this example, we assume an environment similar to ours, where you log in via SSO and obtain permissions through a switch role.
【Point】
- Make sure the model and region you specify are accessible with the assumed role.
Example: Model: anthropic.claude-3-sonnet-20240229-v1:0 Region: us-east-1 *The region is specified in the profile when creating the session.
import boto3
from strands import Agent
from strands.models import BedrockModel
if __name__ == "__main__":
# セッション作成
session = boto3.Session(profile_name='<スイッチ先のロール>')
# モデル設定
bedrock_model = BedrockModel(
boto_session=session,
model_id="us.amazon.nova-pro-v1:0",
temperature=0.0,
max_tokens=1024,
top_p=0.1,
top_k=1,
# Trueにするとストリーミングで出力される。
# ストリーミングでツール利用がサポートされないモデルがあるため、OFF
streaming=False
)
# エージェントのインスタンスを作成
agent = Agent(model=bedrock_model)
# 質問を投げる
query = "こんにちは!"
response = agent(query)
print(response)
Now you can call Bedrock with parameters like temperature, just like you would with the Converse API. 🙌
But if you're using Strands Agents, of course you'll want to call a tool!
Execution ③
If you define a tool as shown below, the agent will use the appropriate tool based on the question and return a response after executing the Agentic Loop.
【Point】
- The function you want to use as a tool is decorated with "@tool".
- Tools are passed as a list of functions, like this:
Agent(model=bedrock_model, tools=[get_time])
import boto3
from strands import Agent
from strands.models import BedrockModel
#------ツール用に読み込んだライブラリ------------
from strands import tool
from datetime import datetime
# ツールの定義
@tool(name="get_time", description="時刻を回答します。")
def get_time() -> str:
"""
現在の時刻を返すツール。
"""
current_time = datetime.now().strftime("%Y-%m-%d %H:%M:%S")
return f"現在の時刻は {current_time} です。"
if __name__ == "__main__":
# セッション作成
session = boto3.Session(profile_name='<スイッチ先のロール>')
# モデル設定
bedrock_model = BedrockModel(
boto_session=session,
model_id="us.amazon.nova-pro-v1:0",
temperature=0.0,
max_tokens=1024,
top_p=0.1,
top_k=1,
# Trueにするとストリーミングで出力される。
# ストリーミングでツール利用がサポートされないモデルがあるため、OFF
streaming=False
)
# ツールを使用するエージェントのインスタンスを作成
agent = Agent(model=bedrock_model, tools=[get_time])
# 質問を投げる。 ツールを使用しないとAIは時刻が判別できない。
query = "こんにちは! 今何時?"
response = agent(query)
print(response)
In my environment, I got the following response:
<thinking> 現在の時刻を調べる必要があります。 そのためには、`get_time`ツールを使用します。 </thinking>
Tool #1: get_time
Hello! 現在の時刻は 2025-07-09 20:11:51 です。 Hello! 現在の時刻は 2025-07-09 20:11:51 です。
Advanced Use
Regarding the tool, in the previous example, it simply returned logic-based output.
However, if you create an agent within the tool and incorporate additional logic, such as having the agent verify a response,
you can easily build a multi-agent system where one AI calls another.
Here’s a modified version of the tool that returns not only the current time, but also a trivia fact provided by a child agent:
【Point】
- We’re reusing the
sessionobject declared in the global scope underif __name__ == "__main__":.
If you don't do this, model setup takes about a minute in my environment.
This is probably due to the time required to allocate resources.
@tool(name="get_time", description="現在日時と、日時にちなんだトリビアを回答します。")
def get_time() -> str:
"""
現在の時刻を返すツール。
注意:この関数では boto3.Session を使った BedrockModel の初期化に
グローバルスコープで定義された `session` 変数が必要です。
`session` は `if __name__ == "__main__":` ブロックなどで事前に定義しておく必要があります。
"""
current_time = datetime.now().strftime("%Y-%m-%d %H:%M:%S")
# モデル設定
bedrock_model = BedrockModel(
boto_session=session,
model_id="us.anthropic.claude-sonnet-4-20250514-v1:0",
temperature=0.0,
max_tokens=1024,
top_p=0.1,
top_k=1,
streaming=False
)
agent = Agent(model=bedrock_model)
# ここが子エージェントから回答を得る部分!
response = agent(f"現在の時刻は {current_time} です。 日時と日付にちなんだトリビアを1つ教えてください。")
return f"現在の時刻は {current_time} です。{response}"
Here’s the final response I got from the AI:
Hello! The current time is 2025-07-10 18:51:23. Today is "Natto Day"!
This commemorative day was established based on the wordplay "7 (na) 10 (to)." It was started in 1992 by the Kansai Natto Industry Cooperative Association to promote natto consumption in the Kansai region.
Interestingly, while natto has long been popular in the Kanto region, many people in Kansai don't like it. This day was created in hopes of encouraging more people in Kansai to enjoy natto. Today, "Natto Day" is recognized nationwide, and many supermarkets offer special discounts on natto to celebrate.
Since it's around dinner time, how about giving natto a try today?
Notes
While multi-agent systems are relatively easy to implement,
in practice, calling multiple AIs increases both token usage and response time, which makes it tricky to decide when to use them.
Below is a breakdown of the processing costs when using both a parent and a child agent:
| Category | Parent Agent | Child Agent | Total |
|---|---|---|---|
| Input Tokens | 1086 | 54 | 1140 |
| Output Tokens | 256 | 219 | 475 |
| Processing Time | 7.2 sec | 7.3 sec | 14.5 sec |
As you can see, the overall processing time doubles when the child agent's response is included.
For that reason, it may be more practical to limit multi-agent use to cases where output diversity is required or the task is too complex to handle with rule-based logic.
Conclusion
This time, in order to expand the AI utilization system "cirro" developed by the Data Strategy Division,
I introduced the key points for running Strands Agents based on my testing.
There were more unexpected pitfalls than I had anticipated, and I hope this article will be helpful when you try it out yourself.
Using Strands Agents makes it easy to extend functionality with tools and child agents.
At the same time, some challenges became apparent, such as increased processing time and token usage, as well as permission management when integrating with systems.
The "cirro" system mentioned in this article is a completely serverless system developed in Python,
and one of its key features is that users can flexibly expand tasks and reference data on their own.
Currently, we are using it for dashboard guidance, survey analysis, and other internal applications.
There is an introductory article on AWS about it, and I hope to share more details in the future!
AWS Cirro Introduction Article
関連記事 | Related Posts

We are hiring!
生成AIエンジニア/AIファーストG/東京・名古屋・大阪・福岡
AIファーストGについて生成AIの活用を通じて、KINTO及びKINTOテクノロジーズへ事業貢献することをミッションに2024年1月に新設されたプロジェクトチームです。生成AI技術は生まれて日が浅く、その技術を業務活用する仕事には定説がありません。
【クラウドエンジニア(クラウド活用の推進)】Cloud Infrastructure G/東京・名古屋・大阪・福岡
KINTO Tech BlogCloud InfrastructureグループについてAWSを主としたクラウドインフラの設計、構築、運用を主に担当しています。


