Introducing Sherpa: The Internal Slack Chatbot Leveraging LLM

1. Introduction
Hello, this is Torii (@yu_torii) from the Common Service Development Group. I'm a fullstack software engineer, primarily working on both backend and frontend development. As part of the KINTO Member Platform Development Team, I focus on frontend engineering while also contributing to internal initiatives involving generative AI.
This article introduces Sherpa, our internal chatbot powered by LLM and integrated into Slack. We’ll explore its RAG capabilities and its translation function, which works through Slack reactions.
Sherpa is designed to facilitate generative AI adoption within the company by enabling employees to naturally interact with AI in their daily Slack conversations. The goal is to eliminate the need for frontend development and deploy it quickly within the company, enhancing efficiency and collaboration. The name Sherpa is inspired by the Sherpa people, known for guiding climbers on Mount Everest. Just as Sherpas are reliable supporters for mountaineers, Sherpa aims to be a dependable assistant for improving work efficiency and streamlining information sharing within the company.
By the way, the Sherpa on the banner was generated by team members of the Creative Group as a surprise reveal for the KINTO Technologies General Meeting (KTC CHO All-Hands Meeting). A big thank you to them!
This initiative was carried out in collaboration with Wada-san (@cognac_n), who is leading the Generative AI Development Project. We have been driving the adoption of generative AI within the company through various improvements, such as introducing a RAG pipeline, setting up a local development environment, and implementing a translation and summarization feature using Slack emoji reactions.
Click here for Wada-san's article
Note that this article does not go into detail about RAG or generative AI technology itself. Instead, it focuses on the implementation process and feature enhancements. Additionally, Sherpa's LLM runs on Azure OpenAI.
What You Will Gain from This Article
-
How to use chat functions powered by generative AI in a Slack Bot
This article introduces an implementation example of a chatbot that combines Slack and LLM, allowing users to trigger translations and summaries using emoji reactions or natural message posts. -
Techniques for retrieving Confluence data, including HTML sanitization
Learn how to fetch Confluence documents using Go and sanitize HTML to prepare text for summarization and embedding. -
Implementing a simple RAG pipeline using FAISS and S3
This section explains the steps and considerations for setting up a simple RAG pipeline using the FAISS indexing and S3. While the response speed may not be very fast, this approach provides a cost-effective way to integrate a basic RAG system.
Table of Contents (Expanded)
2. Overview of the Overall Architecture
Here, we will explain the process by which Sherpa returns answers using generative AI from two perspectives: - The generative AI chat function with users - The process of indexing Confluence documents.
Processing Generative AI Chat Functions with Users
-
Calling Sherpa on Slack There are two ways to call Sherpa: via chat or with a reaction emoji. Users can call Sherpa by mentioning it in a channel or sending a direct message to request a generative AI response. A reaction call allows you to request a translation or summary of a message by adding a translation/summary emoji reaction.
-
Go Slack Bot Lambda
The bot that handles Slack events is built with Go and runs on AWS Lambda. It receives questions and reactions, then determines processing based on the request type. When using Azure OpenAI for LLM queries or retrieving embedded data, this component generates requests and forwards them to Python Lambda. -
Request to LLM and RAG reference in Python Lambda
Python Lambda is divided into functions responsible for LLM queries, RAG references, and related processes. It receives requests from Go Lambda, queries the LLM, and generates an answer using RAG. -
Returning an answer to Slack The generated answer is sent back to Slack via Go Slack Bot Lambda. The translation and summary functions that can be invoked via emoji reactions are also integrated into this flow.
Architecture diagram (processing user requests)
The Process of Indexing Confluence Documents
To use the RAG pipeline, you need to prepare your Confluence documents in a way that makes them easy to summarize and embed. These preprocessing steps are structured into workflows using StepFunctions and are executed automatically on a scheduled basis.
-
Document retrieval and HTML sanitization (Go implementation)
A Lambda function implemented in Go retrieves documents from the Confluence API, cleans up HTML tags, and makes the text more manageable.
The sanitized text is output as JSON. -
Summary processing (Go + Python Lambda invocation)
Summarization aims to refine the text, making it easier to process with Embedding and RAG.
The Go implementation of Lambda invokes a Python Lambda that processes requests to the Azure OpenAI Chat API, shortens the text, and converts it back to JSON. -
FAISS indexing and S3 storage (Indexer Lambda)
The Indexer Lambda embeds the summarized text and generates a FAISS index, then stores the index and meta information in S3.
This enables instant retrieval of indexed data upon a query, ensuring the RAG pipeline runs smoothly.
Architecture diagram (Confluence document indexing flow)
By combining this pre-processing with request-time processing, Sherpa enables generative AI responses that incorporate company-specific knowledge with simple operations in Slack. In the following chapters, we'll dive deeper into these components.
3. AI-Powered Chat Function Using Slack Bot
The previous chapter provided an overview of the architecture. In this chapter, we’ll focus on how users can make use of Sherpa’s features with simple, natural interactions in Slack, and how these features can benefit them.
Here, we will illustrate what Sherpa can do and which scenarios it can be useful in, while the next chapters will systematically explain the implementation details.
Chat Function and Reaction Function
Sherpa offers a variety of generative AI capabilities, powered by natural interactions within Slack.
-
Chat function:
By posting a question, attaching files or images, including external links, or sending a message in a specific format, users can trigger LLM queries or, in certain cases, RAG searches to obtain relevant answers.
By integrating AI into Slack, an everyday tool, users can seamlessly adopt generative AI without the need to learn new environments or commands. -
Reaction function:
By simply adding specific emoji reactions to a message, users can trigger translations, delete messages, and perform other actions—enabling additional operations without requiring commands.
Chat Function: Usage Scenario
-
Basic Questions and Answers
Simply posting a question allows users to receive AI-generated responses through LLM.- Example scenario:
Asking "What are the steps for this project?" provides an instant answer, taking into account thread history and speaker context for a more accurate response.
- Example scenario:
-
File, image, and external link processing
Attaching a file and asking "Summarize this" will generate a summary of the document.
Uploading an image allows Sherpa to extract text and provide relevant answers.
Sharing an external link enables the bot to analyze and summarize webpage content, incorporating it into the LLM-generated response.- Example scenario:
-Get a short summary of meeting notes from a text file. -Extract text information from an image. -Generate a concise summary of an external article.
- Example scenario:
-
Confluence page lookup (RAG integration)
:confluence: By using index:Index name, users can perform a RAG-based search on Confluence pages containing company documentation, such as internal rules and application procedures.- Example scenario:
If company policies and procedures are documented in Confluence, users can instantly access relevant information tailored to internal workflows. - Example scenario:
Easily retrieve project-specific settings and instructions. that would otherwise be difficult to search for.
- Example scenario:
Reaction Feature: Usage Scenario
Adding specific emoji reactions makes calling up functions even more intuitive.
-
Translation:
Adding a translation emoji automatically translates the message into the specified language, helping break down language barriers and improve communication. -
Message deletion
Unnecessary Sherpa responses can be deleted instantly by adding a single emoji, keeping Slack channels organized.
Benefits of This Configuration
-
Seamless and intuitive AI usage:
Users can use AI without needing new commands—they simply interact with Slack as they normally do (e.g., posting messages, adding emojis reactions), reducing learning costs. -
Embedding AI into everyday tool (Slack):
By integrating generative AI directly into Slack, AI can be naturally incorporated into daily workflows without friction. Additionally, reaction-based interactions enable users to perform actions like translation and deletion without typing commands, making AI even more accessible. -
Scalable and easily extendable:
If new models or additional features need to be introduced, the existing flow (chat-based queries and emoji interactions) can be easily expanded by adding conditions.
3.5 Actual Use Cases
Below are some real-world examples of how Sherpa is used within Slack.
Example 1: Image Recognition
When you attach an image to a message, Sherpa recognizes the text within the image and responds with its content.
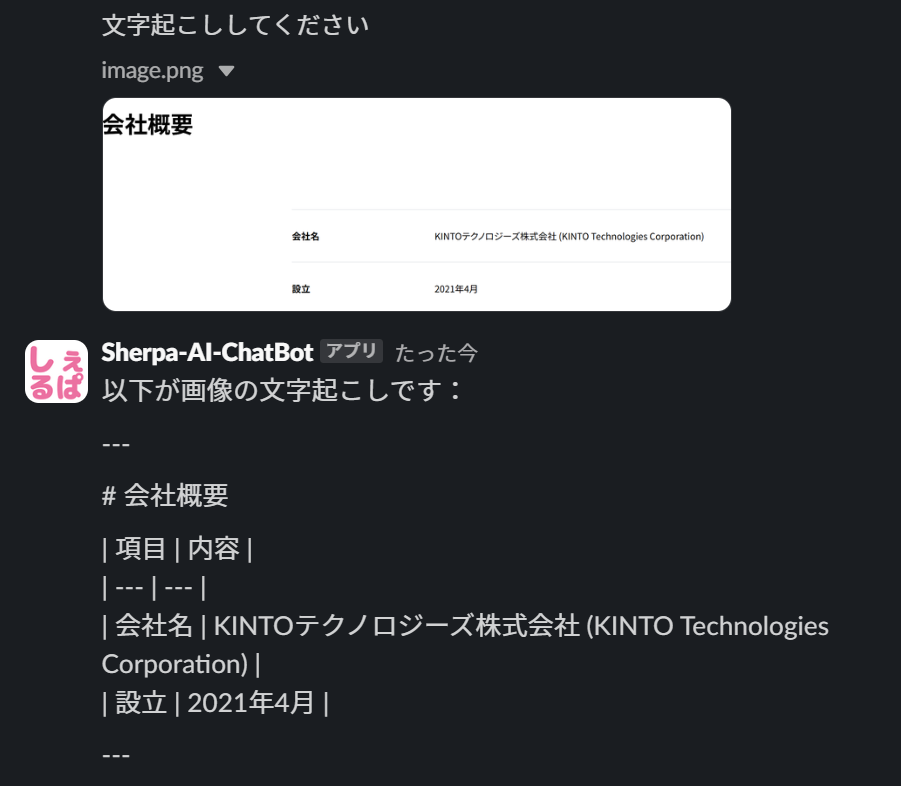 Image Recognition
Image Recognition
Example 2: Answers Based on Confluence Documentation
By using :confluence: emoji, users can retrieve answers based on the Confluence documentation.
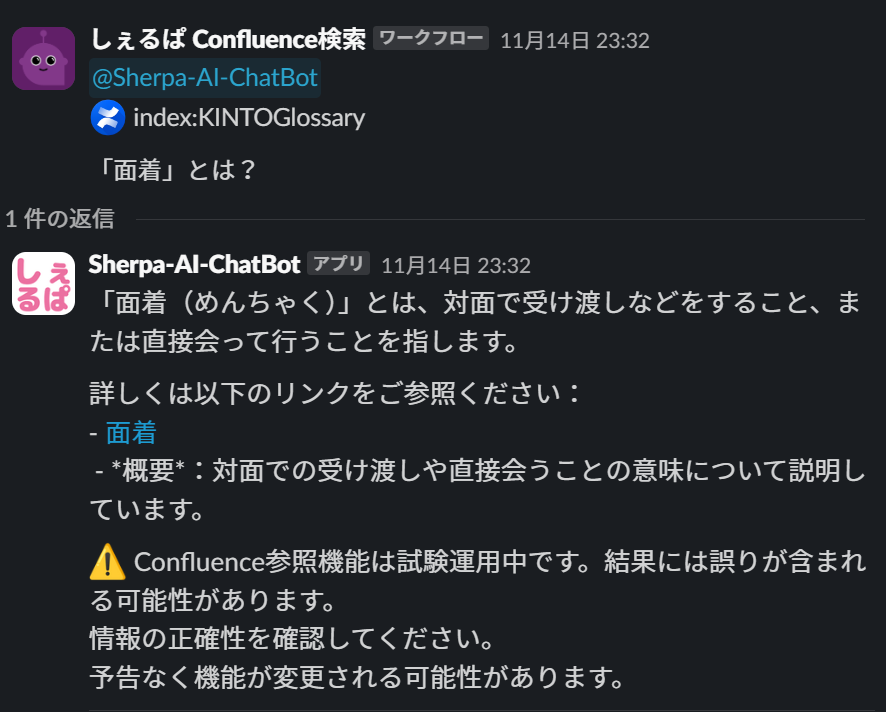 Answer based on Confluence documentation
Answer based on Confluence documentation
As shown above, Sherpa can be triggered from workflows, allowing it to function similarly to a prompt store.
Example 3: Requesting English Translations via the Translation Reaction
Add translation reactions to messages that users want to translate into English
To share a Japanese message with an English speaker, simply add the :sherpa_translate_to_english: reaction emoji. This will automatically translate the message into English. 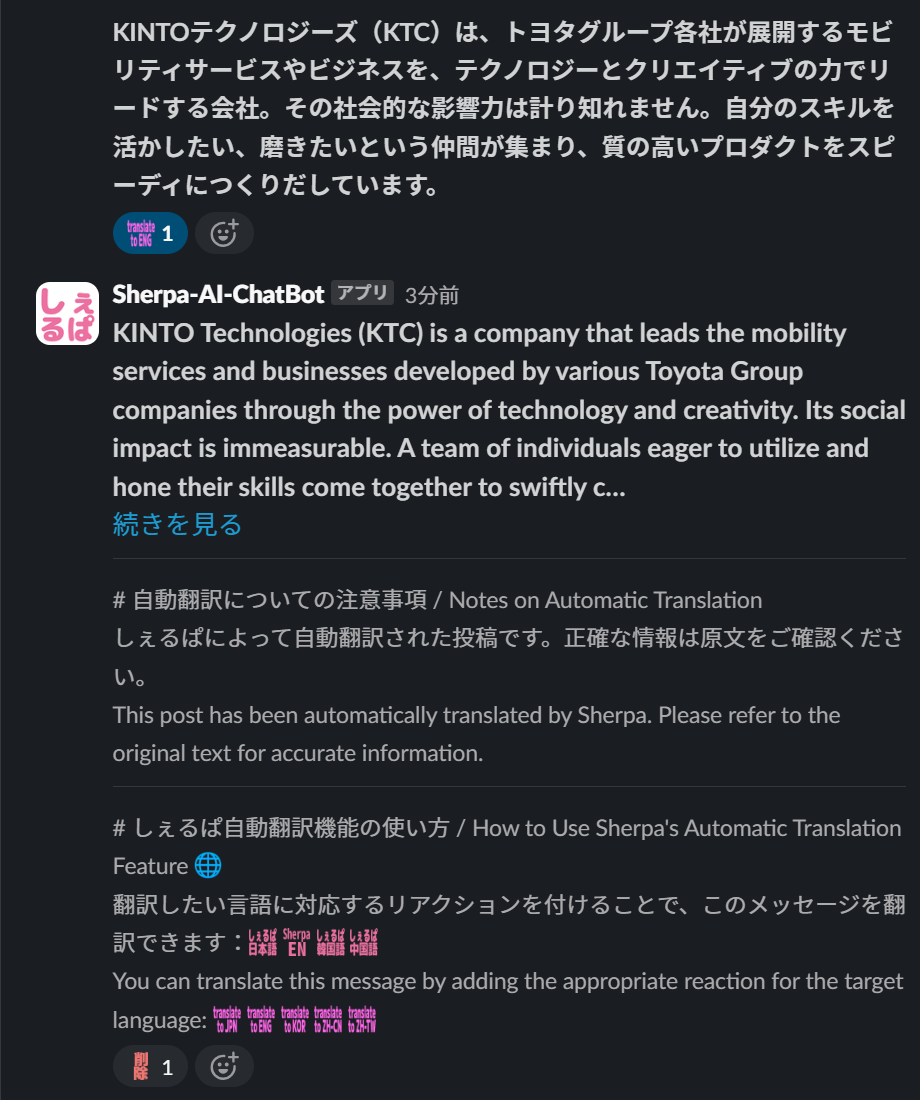 English translation reaction
English translation reaction
To prevent misunderstandings and ensure users do not overly rely on automatic translations, a notification in multiple languages clarifies that the translation was AI-generated. Additionally, we provide instructions on how to use the feature to encourage adoption. Besides English, Sherpa supports translation into multiple languages.
Summary of Chapter 3
In this chapter, we focused on the user perspective—"what can be done with what operations." Building on the usage scenarios discussed here, the following chapters will systematically explain the implementation details. We will cover: - How to integrate Go-based bot with Python Lambdas. - How Slack events are processed and how RAG search works. - The details of the file extraction and sanitization processes.
4. Implementation Policy and Internal Design
In this chapter, we will explain the implementation policy and internal design behind how Sherpa provides a variety of generative AI functions through Slack messages and reactions.
This section focuses on the overall concept, role distribution, and scalability considerations. Specific code snippets and configuration files will be provided in the next chapter.
Overall Process Flow
-
Slack event reception (Go Lambda)
Events occurring in Slack—such as message posts, file attachments, image uploads, external link insertions, and emoji reactions—are sent to an AWS Lambda function written in Go via the Slack API.
The Go function then analyzes these events and determines the appropriate action based on user intent (e.g., normal chat, translation, Confluence reference). -
Text processing and sanitization on the Go side
Text is extracted from external links or files and added to the prompt as context. When referencing external links, meaningful tags such astable,ol,ulare preserved while unnecessary tags are removed to optimize token usage. -
LLM queries and RAG searches on the Python side
If necessary, the Go function invokes a Python Lambda for LLM queries or a separate Python Lambda for RAG searches (e.g., for Confluence references).
For example, if:confluence:is included in the request, the Go function calls the RAG search Lambda. If no index is specified, it defaults to the primary index.
Otherwise, the text is passed to the LLM Lambda for standard query processing. -
Reply and display in Slack
The Python Lambda returns the generated response to the Go function, which then posts it back to Slack.
This enables users to access advanced features through familiar Slack interactions—such as emojis, keywords, and file attachments—without needing to memorize commands.
Function Determination by Conditional Branching
Processing is routed based on specific emojis (e.g., :confluence:), keywords, the presence of files or images, and whether an external link is included.
To add new features, simply introduce new conditions on the Go side and, if necessary, extend the logic for invoking the corresponding Python Lambdas (e.g., for LLM or RAG tasks).
The Role of Sanitization
Sanitizing on the Go side removes unnecessary HTML tags to improve token efficiency and ensure clean input for the model.
Key structural elements such as table, ol, and ul are retained to preserve the information structure and maintain useful context for the model.
Limiting RAG Usage to Confluence References
RAG search is only performed when explicitly specified with :confluence:.
By default, summarization, translation, and Q&A tasks are handled via direct LLM queries, ensuring RAG logic is triggered only for Confluence references.
Embedding generation for Confluence documents and FAISS index updates are handled periodically by StepFunctions, ensuring that the latest index is always available for queries.
Considerations for Scalability and Maintainability
Conditional branching based on emojis, keywords, or the presence of files/images minimizes the number of code modifications required when introducing new features, enhancing maintainability.
The separation of concerns—where text formatting and sanitization are handled on the Go side, while LLM queries and RAG searches are managed on the Python side—improves code clarity and facilitates future model replacements or additional processing logic.
In the next chapter, we will introduce specific code snippets and configuration examples based on these design principles.
5. Introduction to Code examples and Configuration Files
This chapter introduces a brief implementation example based on the implementation policy and design concepts explained in Chapter 4.
This chapter contains the following sections:
-
5.1 [Go] Receiving and parsing Slack events
Explains how to use Slack's Events API to receive and process events such as messages and emoji reactions. -
5.2 [Go] HTML text sanitization
Provides an example of sanitizing HTML when referencing external links. -
5.3 [Python] Example of an LLM query
Shows how to query an LLM using a Python-based Lambda function. -
5.4 [Python] Example of a RAG search call
Demonstrates how to perform a RAG search call, such as for Confluence lookups. -
5.5 [Python] Embedding and FAISS indexing.
Provides an example of Lambda code that periodically embeds Confluence documents and updates the FAISS index.
5.1 [Go] Receiving and Parsing Slack Events
This section explains the basic steps for using the Slack Events API to receive and analyze events with Go code on AWS Lambda.
We will also cover the settings on the Slack side (OAuth & Permissions, event subscription) and how to check the scopes required when using the chat.postMessage method (such as chat:write), to clarify the necessary preparations before implementation.
Configuration Steps on Slack Side
-
Create an app and check the App ID:
Create a new app at https://api.slack.com/apps.
Once created, find your App ID (a string starting withA) on the Basic Information page (https://api.slack.com/apps/APP_ID/general, whereAPP_IDis a unique ID for your app).
This App ID identifies your Slack App and can be used to access the URLs forOAuth & PermissionsandEvent Subscriptionspages described below. -
Granting scopes via OAuth & Permissions:
Visit the OAuth & Permissions page (https://api.slack.com/apps/APP_ID/oauth) and add the necessary scopes to Bot Token Scopes.
For example, if thechat.postMessagemethod is needed to post messages to a channel, checking this page (https://api.slack.com/methods/chat.postMessage) under "Required scopes" will indicate thatchat:writeis required.
After granting the scope, click "reinstall your app" to apply the changes in your workspace. Then, the changes will be reflected.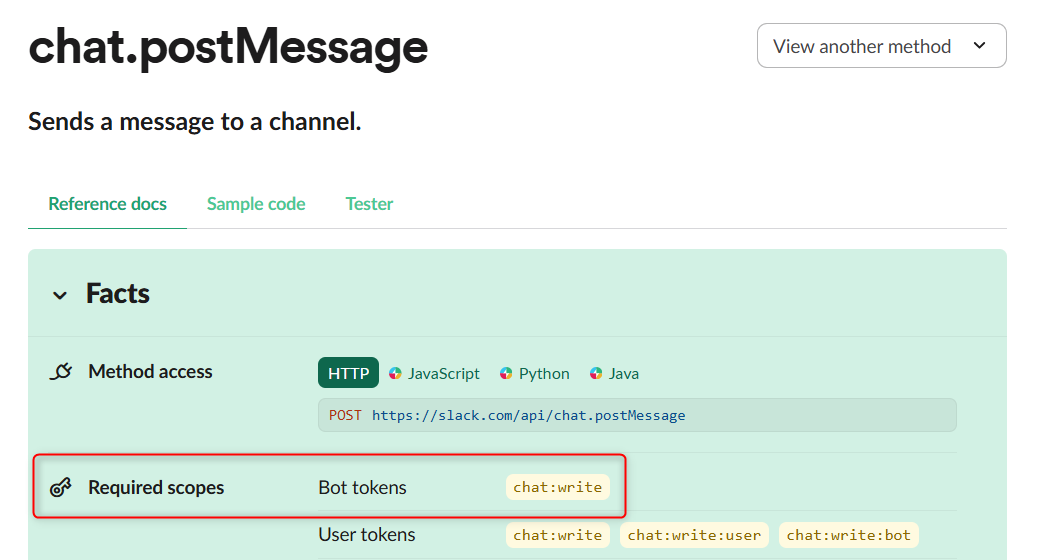 Checking required scopes
Checking required scopes 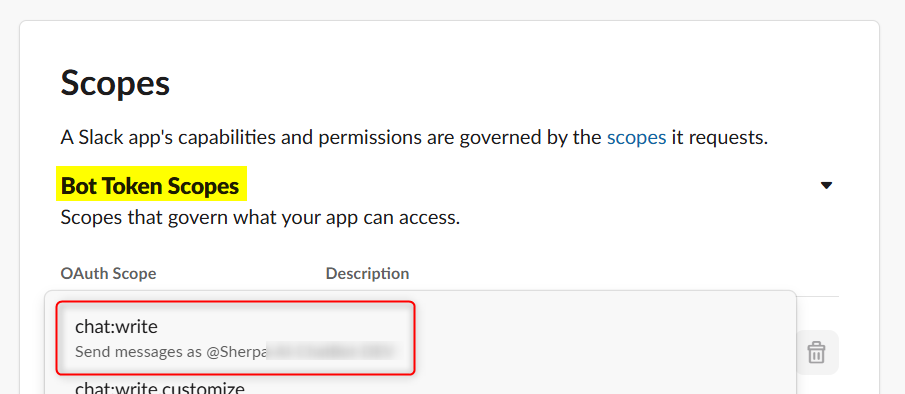 Setting scope
Setting scope -
Enabling the Events API and subscribing to events:
Enable the Events API on the "Event Subscriptions" page (https://api.slack.com/apps/APP_ID/event-subscriptions) and set the AWS Lambda endpoint described below in "Request URL".
Add the events you want to subscribe to, such asmessage.channelsorreaction_added. This allows Slack to send a notification to the specified URL whenever a subscribed event occurs.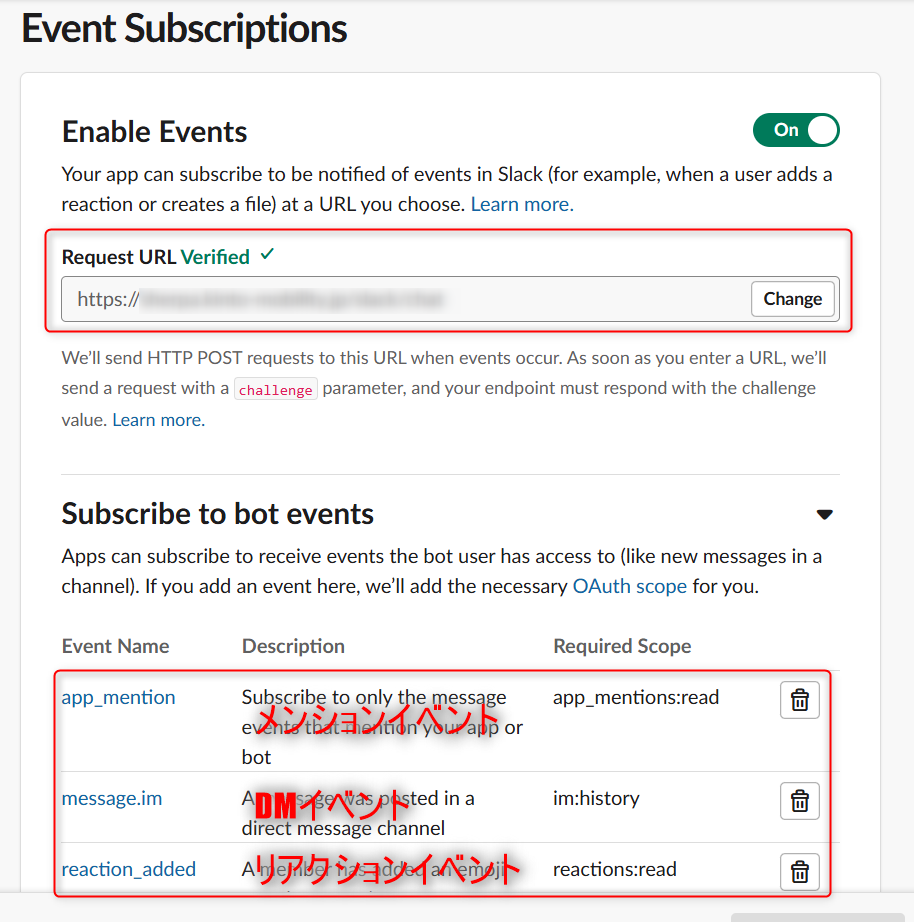
Event Reception and Analysis on AWS Lambda
Once the configuration is complete on the Slack side, Slack will send a POST request to AWS Lambda via API Gateway whenever a subscribed event occurs.
Step 1: Parsing Slack Events
Use the slack-go/slackevents package to parse the received JSON into an EventsAPIEvent structure.
This makes it easier to identify event types, such as URL validation and CallbackEvent.
func parseSlackEvent(body string) (*slackevents.EventsAPIEvent, error) {
event, err := slackevents.ParseEvent(json.RawMessage(body), slackevents.OptionNoVerifyToken())
if err != nil {
return nil, fmt.Errorf("Failed to parse Slack event: %w", err)
}
return &event, nil
}
Step 2: Handling URL Verification Requests
When setting up the integration, Slack will initially send an event with type=url_verification. To verify the URL, simply return the challenge value as received. Once verified, Slack will continue sending event notifications.
func handleURLVerification(body string) (events.APIGatewayProxyResponse, error) {
var r struct {
Challenge string `json:"challenge"`
}
if err := json.Unmarshal([]byte(body), &r); err != nil {
return createErrorResponse(400, err)
}
return events.APIGatewayProxyResponse{
StatusCode: 200,
Body: r.Challenge,
}, nil
}
Step 3: Verifying Signatures and Ignoring Retry Requests
Slack includes a request signature that allows verification of authenticity (implementation omitted).
Additionally, in case of a failure or outage, Slack may resend the request as a retry. The X-Slack-Retry-Num header can be used to identify retry attempts and prevent processing the same event multiple times.
func verifySlackRequest(body string, headers http.Header) error {
// Signature verification process (omitted)
return nil
}
func isSlackRetry(headers http.Header) bool {
return headers.Get("X-Slack-Retry-Num") != ""
}
func createIgnoredRetryResponse() (events.APIGatewayProxyResponse, error) {
responseBody, _ := json.Marshal(map[string]string{"message": "Ignoring Slack retry request"})
return events.APIGatewayProxyResponse{
StatusCode: 200,
Headers: map[string]string{"Content-Type": "application/json"},
Body: string(responseBody),
}, nil
}
Step 4: Handling CallbackEvent
The CallbackEvent includes actions such as message postings and adding reactions. At this stage, the system checks whether :confluence: is included in the message, if a file is attached, or if a translation-related emoji is present. Based on this assessment, it proceeds to text processing and Python Lambda invocation, as described in section 5.2 and beyond.
// handleCallbackEvent processes callback events (covered in Section 5.1).
func handleCallbackEvent(ctx context.Context, isOrchestrator bool, event *slackevents.EventsAPIEvent) (events.APIGatewayProxyResponse, error) {
innerEvent := event.InnerEvent
switch innerEvent.Data.(type) {
case *slackevents.AppMentionEvent:
// Processing for AppMentionEvent (details explained in 5.2)
case *slackevents.MessageEvent:
// Processing for MessageEvent (details explained in 5.2)
case *slackevents.ReactionAddedEvent:
// Processing for ReactionAddedEvent (details explained in 5.2)
}
return events.APIGatewayProxyResponse{Body: "OK", StatusCode: http.StatusOK}, nil
}
Complete Handler Code Example
These steps combine to define an AWS Lambda handler.
Complete code example of the handler
func handler(ctx context.Context, request events.APIGatewayProxyRequest) (events.APIGatewayProxyResponse, error) {
event, err := parseSlackEvent(request.Body)
if err != nil {
return createErrorResponse(400, err)
}
if event.Type == slackevents.URLVerification {
return handleURLVerification(request.Body)
}
headers := convertToHTTPHeader(request.Headers)
err = verifySlackRequest(request.Body, headers)
if err != nil {
return createErrorResponse(http.StatusUnauthorized, fmt.Errorf("Failed to validate request: %w", err))
}
if isSlackRetry(headers) {
return createIgnoredRetryResponse()
}
if event.Type == slackevents.CallbackEvent {
return handleCallbackEvent(ctx, event)
}
return events.APIGatewayProxyResponse{Body: "OK", StatusCode: 200}, nil
}
func convertToHTTPHeader(headers map[string]string) http.Header {
httpHeaders := http.Header{}
for key, value := range headers {
httpHeaders.Set(key, value)
}
return httpHeaders
}
func createErrorResponse(statusCode int, err error) (events.APIGatewayProxyResponse, error) {
responseBody, _ := json.Marshal(map[string]string{"error": err.Error()})
return events.APIGatewayProxyResponse{
StatusCode: statusCode,
Headers: map[string]string{"Content-Type": "application/json"},
Body: string(responseBody),
}, err
}
Summary of 5.1
In this section, we explained how to obtain the Slack App's App ID, grant scopes using OAuth & Permissions, and configure event subscriptions in Event Subscriptions. We also covered the process of receiving and parsing Slack events, including handling URL verification, signature validation, ignoring retry requests, and processing CallbackEvents.
From section 5.2 onwards, we will introduce specific examples of CallbackEvent processing, text handling in Go, and sending queries to Python Lambda.
5.2 [Go] HTML Text Sanitization
Sanitizing External Link References
HTML text retrieved from external links may contain unnecessary tags such as script and style, which are not needed for generating responses. Passing this directly to the LLM increases the token count, leading to higher model costs and potentially reducing response accuracy. The following code uses the bluemonday package for basic sanitization. It removes unnecessary tags while preserving important ones like table, ol, and ul, ensuring the text remains well-structured and readable. Additionally, the addNewlinesForTags function inserts line breaks after specific tags, improving text formatting. This helps optimize queries to the model by ensuring that only the necessary information is passed in a structured and efficient format.
func sanitizeContent(htmlContent string) string {
// Basic sanitization
ugcPolicy := bluemonday.UGCPolicy()
sanitized := ugcPolicy.Sanitize(htmlContent)
// Allow specific tags in a custom policy
customPolicy := bluemonday.NewPolicy()
customPolicy.AllowLists()
customPolicy.AllowTables()
customPolicy.AllowAttrs("href").OnElements("a")
// Add line breaks after specific tags to improve readability
formattedContent := addNewlinesForTags(sanitized, "p")
// Apply final sanitization after enforcing the custom policy
finalContent := customPolicy.Sanitize(formattedContent)
return finalContent
}
func addNewlinesForTags(htmlStr string, tags ...string) string {
for _, tag := range tags {
closeTag := fmt.Sprintf("</%s>", tag)
htmlStr = strings.ReplaceAll(htmlStr, closeTag, closeTag+"\n")
}
return htmlStr
}
This process ensures that the model receives only text with unnecessary tags removed, improving response accuracy and cost efficiency. By preserving essential structures such as tables and bullet points while inserting line breaks after specific tags, the model can better interpret the provided context.
5.3 [Python] Example of an LLM Query
Below is an example of how to query an LLM (e.g. Azure OpenAI) in Python. With OpenAIClientFactory, you can dynamically switch models and endpoints, enabling the reuse of a common client creation process across multiple Lambda handlers.
Client Creation Process
OpenAIClientFactory dynamically generates a client for either Azure OpenAI or OpenAI, depending on api_type and model.
Since API keys and endpoints are retrieved from environment variables and secret management services, code modifications are minimized even when updating models or configurations.
import openai
from shared.secrets import get_secret
class OpenAIClientFactory:
@staticmethod
def create_client(region="eastus2", model="gpt-4o") -> openai.OpenAI:
secret = get_secret()
api_type = secret.get("openai_api_type", "azure")
if api_type == "azure":
return openai.AzureOpenAI(
api_key=secret.get(f"azure_openai_api_key_{region}"),
azure_endpoint=secret.get(f"azure_openai_endpoint_{region}"),
api_version=secret.get(
f"azure_openai_api_version_{region}", "2024-07-01-preview"
),
)
elif api_type == "openai":
return openai.OpenAI(api_key=secret.get("openai_api_key"))
raise ValueError(f"Invalid api_type: {api_type}")
LLM Query Processing
The chatCompletionHandler function extracts messages, model, temperature, and other parameters from the JSON received in the HTTP request. It then queries the LLM using the client generated by OpenAIClientFactory.
Responses are returned in JSON format. If an error occurs, a properly formatted error response is generated using a common error handling function.
import json
from typing import Any, Dict, List
import openai
from openai.types.chat import ChatCompletionMessageParam
from shared.openai_client import OpenAIClientFactory
def chatCompletionHandler(event: Dict[str, Any], context: Any) -> Dict[str, Any]:
request_body = json.loads(event["body"])
messages: List[ChatCompletionMessageParam] = request_body.get("messages", [])
model = request_body.get("model", "gpt-4o")
client = OpenAIClientFactory.create_client(model=model)
temperature = request_body.get("temperature", 0.7)
max_tokens = request_body.get("max_tokens", 4000)
response_format = request_body.get("response_format", None)
completion = client.chat.completions.create(
model=model,
stream=False,
messages=messages,
max_tokens=max_tokens,
frequency_penalty=0,
presence_penalty=0,
temperature=temperature,
response_format=response_format,
)
return {
"statusCode": 200,
"body": json.dumps(completion.to_dict()),
"headers": {
"Content-Type": "application/json",
"Access-Control-Allow-Origin": "*",
"Access-Control-Allow-Methods": "OPTIONS,POST",
"Access-Control-Allow-Headers": "Content-Type,X-Amz-Date,Authorization,X-Api-Key,X-Amz-Security-Token",
},
}
This mechanism allows different Lambda handlers to make LLM queries using the same procedure, ensuring flexibility in adapting to models and endpoint changes.
5.4 [Python] Example of a RAG Search Call
This section provides instructions on performing a Retrieval Augmented Generation (RAG) search in Python.
By vectorizing internal knowledge, such as Confluence documents, and performing similarity searches using the FAISS index, it is possible to integrate highly relevant information into LLM responses.
A key consideration is the handling of the faiss library. faiss is a large package and may exceed the capacity limits of the Lambda Layers. To work around this, it is common to use EFS or containerize the Lambda function.
To simplify deployment, the setup_faiss function dynamically downloads and extracts faiss from S3, then adds it to sys.path, making faiss available at runtime.
What is FAISS?
FAISS (Facebook AI Similarity Search) is an approximate nearest neighbor search library developed by Meta (Facebook). It provides tools for creating indexes to efficiently search for similar images and text.
FAISS Setup Using the setup_faiss Function
To use FAISS in the Lambda environment, the setup_faiss function performs the following steps:
-
Build and archive the faiss package in a local/CI environment
Developers install thefaiss-cpupackage in a CI environment such as GitHub Actions and package the necessary binaries into atar.gzarchive. -
Upload to S3
The archivedfaiss_package.tar.gzis uploaded to an S3 bucket.
By storing the package in an appropriate bucket and path (e.g., for staging or production), the Lambda function can dynamically retrieve it during execution. -
Dynamic loading with
setup_faisswhen running Lambda
In the Lambda execution environment, thesetup_faissfunction downloads and extractsfaiss_package.tar.gzfrom S3 at startup and adds it tosys.path.
This enables the Lambda function to runimport faiss, allowing for efficient vector searches using embeddings.
Example: Uploading the FAISS Package to S3 Using GitHub Actions
The following GitHub Actions workflow demonstrates how to install faiss-cpu, package it for Lambda use, and upload it to S3.
This setup uses GitHub Actions Secrets and Environment Variables to manage AWS credentials and S3 bucket names securely, avoiding hardcoded values.
name: Build and Upload FAISS
on:
workflow_dispatch:
inputs:
environment:
description: Deployment Environment
type: environment
default: dev
jobs:
build-and-upload-faiss:
environment: ${{ inputs.environment }}
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- uses: actions/setup-python@v5
with:
python-version: "3.11"
# Install required packages (faiss-cpu)
- name: Install faiss-cpu
run: |
set -e
echo "Installing faiss-cpu..."
pip install faiss-cpu --no-deps
# Archive the faiss binary
- name: Archive faiss binaries
run: |
mkdir -p faiss_package
pip install --target=faiss_package faiss-cpu
tar -czvf faiss_package.tar.gz faiss_package
# Set AWS credentials (configure Secrets or Roles based on your environment)
- name: Configure AWS credentials
uses: aws-actions/configure-aws-credentials@v3
with:
aws-access-key-id: ${{ secrets.CICD_AWS_ACCESS_KEY_ID }}
aws-secret-access-key: ${{ secrets.CICD_AWS_SECRET_ACCESS_KEY }}
aws-region: ap-northeast-1
# Upload to S3
- name: Upload faiss binaries to S3
run: |
echo "Uploading faiss_package.tar.gz to S3..."
aws s3 cp faiss_package.tar.gz s3://${{ secrets.AWS_S3_BUCKET }}/lambda/faiss_package.tar.gz
echo "Upload complete."
In the above example, faiss_package.tar.gz is uploaded to S3 with the key lambda/faiss_package.tar.gz.
Dynamic Loading Process on Lambda side (setup_faiss function)
The setup_faiss function handles the dynamic loading of FAISS at runtime. It downloads faiss_package.tar.gz from S3, extracts it to the /tmp directory, and appends the package path to sys.path. This enables import faiss to be executed within Lambda, allowing FAISS index lookups to be performed.
# setup_faiss example: Download the FAISS package from S3 and add it to sys.path
import os
import sys
import tarfile
from shared.logger import getLogger
from shared.s3_client import S3Client
logger = getLogger(__name__)
def setup_faiss(s3_client: S3Client, s3_bucket: str) -> None:
try:
import faiss
logger.info("faiss has already been imported.")
except ImportError:
logger.info("faiss not found. Downloading from S3.")
faiss_package_key = "lambda/faiss_package.tar.gz"
faiss_package_path = "/tmp/faiss_package.tar.gz"
faiss_extract_path = "/tmp/faiss_package"
# Download the package from S3 and extract it
s3_client.download_file(bucket_name=s3_bucket, key=faiss_package_key, file_path=faiss_package_path)
with tarfile.open(faiss_package_path, "r:gz") as tar:
for member in tar.getmembers():
member.name = os.path.relpath(member.name, start=member.name.split("/")[0])
tar.extract(member, faiss_extract_path)
sys.path.insert(0, faiss_extract_path)
import faiss
logger.info("faiss was imported successfully.")
RAG Search Using Embeddings and FAISS Indexes
The search_data function loads the FAISS index retrieved from S3 locally and searches for documents that best match the query. Documents are vectorized using the Embeddings client (Azure OpenAI or OpenAI) generated by the get_embeddings function, enabling fast searches using faiss.
from typing import Any, Dict, List, Optional
from langchain_community.vectorstores import FAISS
from langchain_core.documents.base import Document
from langchain_core.vectorstores.base import VectorStoreRetriever
from shared.secrets import get_secret
from shared.logger import getLogger
from langchain_openai import AzureOpenAIEmbeddings, OpenAIEmbeddings
logger = getLogger(__name__)
def get_embeddings(secrets: Dict[str, str]):
api_type: str = secrets.get("openai_api_type", "azure")
if api_type == "azure":
return AzureOpenAIEmbeddings(
openai_api_key=secrets.get("azure_openai_api_key_eastus2"),
azure_endpoint=secrets.get("azure_openai_endpoint_eastus2"),
model="text-embedding-3-large",
api_version=secrets.get("azure_openai_api_version_eastus2", "2023-07-01-preview"),
)
elif api_type == "openai":
return OpenAIEmbeddings(
openai_api_key=secrets.get("openai_api_key"),
model="text-embedding-3-large",
)
else:
logger.error("An invalid API type specified.")
raise ValueError("Invalid api_type")
def search_data(
query: str,
index_folder_path: str,
search_type: str = "similarity",
score_threshold: Optional[float] = None,
k: Optional[int] = None,
fetch_k: Optional[int] = None,
lambda_mult: Optional[float] = None,
) -> List[Dict]:
secrets: Dict[str, str] = get_secret()
embeddings = get_embeddings(secrets)
db: FAISS = FAISS.load_local(
folder_path=index_folder_path,
embeddings=embeddings,
allow_dangerous_deserialization=True,
)
search_kwargs = {"k": k}
if search_type == "similarity_score_threshold" and score_threshold is not None:
search_kwargs["score_threshold"] = score_threshold
elif search_type == "mmr":
search_kwargs["fetch_k"] = fetch_k or k * 4
if lambda_mult is not None:
search_kwargs["lambda_mult"] = lambda_mult
retriever: VectorStoreRetriever = db.as_retriever(
search_type=search_type,
search_kwargs=search_kwargs,
)
results: List[Document] = retriever.invoke(input=query)
return [{"content": doc.page_content, "metadata": doc.metadata} for doc in results]
Asynchronous Downloads and Lambda Handlers
Within async_handler, setup_faiss is executed, and the FAISS index file is retrieved from S3 using download_files. Afterward, search_data performs a RAG search, and the results are returned in JSON format.
import asyncio
import json
import os
from shared.s3_client import S3Client
from shared.logger import getLogger
from shared.token_verifier import with_token_verification
logger = getLogger(__name__)
RESULT_NUM = 5
@with_token_verification
async def async_handler(event: Dict[str, Any], context: Any) -> Dict[str, Any]:
env = os.getenv("ENV")
s3_client = S3Client()
s3_bucket = "bucket-name"
setup_faiss(s3_client, s3_bucket)
request_body_str = event.get("body", "{}")
request_body = json.loads(request_body_str)
query = request_body.get("query")
index_path = request_body.get("index_path")
local_index_dir = "/tmp/index_faiss"
await download_files(s3_client, s3_bucket, index_path, local_index_dir)
results = search_data(
query,
local_index_dir,
search_type=request_body.get("search_type", "similarity"),
score_threshold=request_body.get("score_threshold"),
k=request_body.get("k", RESULT_NUM),
fetch_k=request_body.get("fetch_k"),
lambda_mult=request_body.get("lambda_mult"),
)
return create_response(200, results)
def retrieverHandler(event: Dict[str, Any], context: Any) -> Dict[str, Any]:
return asyncio.run(async_handler(event, context))
def create_response(status_code: int, body: Any) -> Dict[str, Any]:
return {
"statusCode": status_code,
"body": json.dumps(body, ensure_ascii=False),
"headers": {
"Content-Type": "application/json",
},
}
async def download_files(s3_client: S3Client, bucket: str, key: str, file_path: str) -> None:
loop = asyncio.get_running_loop()
await loop.run_in_executor(None, download_files_from_s3, s3_client, bucket, key, file_path)
def download_files_from_s3(s3_client: S3Client, s3_bucket: str, prefix: str, local_dir: str) -> None:
keys = s3_client.list_objects(bucket_name=s3_bucket, prefix=prefix)
if not keys:
logger.info(f"No file found in '{prefix}'")
return
for key in keys:
relative_path = os.path.relpath(key, prefix)
local_file_path = os.path.join(local_dir, relative_path)
os.makedirs(os.path.dirname(local_file_path), exist_ok=True)
s3_client.download_file(bucket_name=s3_bucket, key=key, file_path=local_file_path)
Summary of 5.4
- Avoid Lambda layer capacity issues with
setup_faissfaissdynamic loading. - Asynchronous I/O and S3 usage allow FAISS index to be loaded without containerization or EFS connectivity.
search_datasearches the embedded index, enabling RAG to quickly provide similar documents.
This enables high-speed knowledge searches using RAG, providing LLM answers enriched with company-specific information.
5.5 [Python] Embedding and FAISS Indexing
This section provides an example of periodic batch processing that embeds internal company documents (such as Confluence pages) and creates or updates the FAISS index.
The index used in the RAG pipeline is essential for generative AI to incorporate company-specific knowledge into its responses. To maintain accuracy, we regularly update embeddings and rebuild the FAISS index, ensuring that the latest information is always accessible.
Process Overview
- Retrieve JSON-formatted documents from S3.
- Generate embeddings for the retrieved documents (using the Embeddings API from OpenAI or Azure OpenAI).
- Index the embedded text using FAISS.
- Upload the FAISS index to S3.
By executing these steps periodically via Lambda batch processing or a Step Functions workflow, RAG searches will always use the latest index when queried.
Step 1: Loading a JSON document
Download and parse a JSON file from S3 (e.g., summarized Confluence pages) and convert it into a list of Document objects.
import json
from typing import Any, Dict, List
from langchain_core.documents.base import Document
from shared.logger import getLogger
logger = getLogger(__name__)
def load_json(file_path: str) -> List[Document]:
"""
Reads a JSON file and returns a list of Document objects.
The JSON format is expected to be: [{"title": "...", "content": "...", "id": "...", "url": "..."}]
"""
with open(file_path, "r", encoding="utf-8") as f:
data = json.load(f)
if not isinstance(data, list):
raise ValueError("The top-level JSON structure is not a list.")
documents = []
for record in data:
if not isinstance(record, dict):
logger.warning(f"Skipped record (not a dictionary): {record}")
continue
title = record.get("title", "")
content = record.get("content", "")
metadata = {
"id": record.get("id"),
"title": title,
"url": record.get("url"),
}
# Create a Document object combining the title and content
doc = Document(page_content=f"Title: {title}\nContent: {content}", metadata=metadata)
documents.append(doc)
logger.info(f"Loaded {len(documents)} documents.")
return documents
Step 2: Embedding and FAISS indexing
The vectorize_and_save function embeds the documents using the Embeddings client obtained from get_embeddings and creates a FAISS index. It then saves the index locally.
import os
from langchain_community.vectorstores import FAISS
from langchain_core.text_splitter import RecursiveCharacterTextSplitter
from shared.logger import getLogger
logger = getLogger(__name__)
def vectorize_and_save(documents: List[Document], output_dir: str, embeddings) -> None:
"""
Embed the documents, create a FAISS index, and save it locally.
"""
# Split the document into smaller chunks using a text splitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1024, chunk_overlap=128)
split_docs = text_splitter.split_documents(documents)
logger.info(f"{len(split_docs)} split documents")
# Vectorize using embeddings and build FAISS index
db: FAISS = FAISS.from_documents(split_docs, embeddings)
logger.info("Vector DB construction completed.")
os.makedirs(output_dir, exist_ok=True)
db.save_local(output_dir)
logger.info(f"Vector DB saved to {output_dir}")
Step 3: Uploading the Index to S3
By uploading the locally created FAISS index to S3, it can be easily accessed by the RAG search Lambda.
from shared.s3_client import S3Client
from shared.logger import getLogger
logger = getLogger(__name__)
def upload_faiss_to_s3(s3_client: S3Client, s3_bucket: str, local_index_dir: str, index_s3_path: str) -> None:
"""
Upload the FAISS index to S3.
"""
index_files = ["index.faiss", "index.pkl"]
for file_name in index_files:
local_file_path = os.path.join(local_index_dir, file_name)
s3_index_key = os.path.join(index_s3_path, file_name)
s3_client.upload_file(local_file_path, s3_bucket, s3_index_key)
logger.info(f"FAISS index file uploaded to s3://{s3_bucket}/{s3_index_key}")
Step 4: Running the entire flow in Lambda
The index_to_s3 function encapsulates the entire process. It downloads JSON from S3, generates embeddings, creates a FAISS index, and uploads the index to S3. This process can be executed periodically using a workflow such as Step Functions, ensuring that the index remains up to date.
import os
from shared.faiss import setup_faiss
from shared.logger import getLogger
from shared.s3_client import S3Client
from shared.secrets import get_secret
logger = getLogger(__name__)
def index_to_s3(json_s3_key: str, index_s3_path: str) -> Dict[str, Any]:
"""
Download JSON from S3, generate embeddings, create a FAISS index, and upload the index to S3.
"""
env = os.getenv("ENV")
if env is None:
error_msg = "ENV environment variable not set."
logger.error(error_msg)
return {"status": "error", "message": error_msg}
try:
s3_client = S3Client()
s3_bucket = "bucket-name"
local_json_path = "/tmp/json_file.json"
local_index_dir = "/tmp/index"
# Set up faiss if necessary (download from S3)
setup_faiss(s3_client, s3_bucket)
# Download the JSON file from S3
s3_client.download_file(s3_bucket, json_s3_key, local_json_path)
documents = load_json(local_json_path)
# Get Embeddings client
secrets = get_secret()
embeddings = get_embeddings(secrets)
# Vectorization and FAISS indexing
vectorize_and_save(documents, local_index_dir, embeddings)
# Upload the index file to S3
upload_faiss_to_s3(s3_client, s3_bucket, local_index_dir, index_s3_path)
return {
"status": "success",
"message": "FAISS index created and uploaded to S3.”,
"output": {
"bucket": s3_bucket,
"index_key": index_s3_path,
},
}
except Exception as e:
logger.error(f"An error occurred during the indexing process: {e}")
return {"status": "error", "message": str(e)}
Summary of 5.5
load_jsonloads a JSON file, andvectorize_and_savegenerates embeddings and creates a FAISS index.upload_faiss_to_s3uploads the local index to S3.index_to_s3consolidates the entire process, ensuring that the latest index is created and updated through regular batch processing.
This enables automated batch processing to embed internal documents and maintain FAISS indexes for RAG searches.
6. Summary
In this article, we covered the development background and technical implementation of Sherpa, out internal chatbot powered by LLM and integrated into Slack. We also outlined the steps for implementing the RAG pipeline, sanitizing Confluence documents, building a search infrastructure using Embeddings and FAISS indexes, and extending functionality with features like translation and summarization.
This system enables employees to seamlessly integrate generative AI into their Slack workflow, allowing them to access advanced information capabilities without needing to learn new tools or commands.
7. Future Outlook
We will actively work on the following improvements and expansions to further enhance Sherpa.
-
Strengthening Azure-based deployment
We will fully integrate with Azure services such as Azure Functions and Azure CosmosDB, significantly improving the performance and scalability of the RAG pipeline.- Introducing Azure Cosmos DB Vector Search
We will implement vector search functionality on Azure Cosmos DB for NoSQL, enabling more advanced search capabilities. - Utilizing AI Document Intelligence
By actively incorporating AI Document Intelligence, we aim to expand the knowledge scope of RAG and enhance information utilization across a broader range of use cases.
- Introducing Azure Cosmos DB Vector Search
-
Diversification and sophistication of models
We will continue integrating cutting-edge models by expanding support beyond GPT-4o to include GPT-o1, Google Gemini, and other state-of-the-art AI models. -
Implementing Web UI
To overcome the expression and interaction limitations imposed by Slack, we will develop a Web UI, allowing for more diverse interactions and the flexible deployment of new features. -
Enhancing prompt management
We will template existing prompts, making them easily reusable across different use cases. Additionally, we will enhance the prompt-sharing functionality to further promote the adoption of generative AI across the company. -
Realizing multi-agent capabilities
By deploying specialized agents dedicated to tasks such as summarization, translation, and RAG search, and allowing flexible combinations through an Agent Builder, we will enable more advanced and adaptable information processing. -
Evaluating and improving RAG accuracy
We will build test sets and conduct automated answer evaluations to quantitatively measure accuracy and continuously improve quality. -
Enhancements based on user feedback
By incorporating real-world usage data and feedback, we will optimize dialogue flows, fine-tune prompts, and strengthen external service integrations, ensuring that Sherpa remains highly convenient and useful.
Through these efforts, we will continue evolving Sherpa, growing it into a powerful internal support tool that meets a wide range of business needs.
関連記事 | Related Posts





We are hiring!
生成AIエンジニア/AIファーストG/東京・名古屋・大阪・福岡
AIファーストGについて生成AIの活用を通じて、KINTO及びKINTOテクノロジーズへ事業貢献することをミッションに2024年1月に新設されたプロジェクトチームです。生成AI技術は生まれて日が浅く、その技術を業務活用する仕事には定説がありません。
【フロントエンドエンジニア(コンテンツ開発)】新車サブスク開発G/大阪・福岡
新車サブスク開発グループについてTOYOTAのクルマのサブスクリプションサービスである『 KINTO ONE 』のWebサイトの開発、運用をしています。業務内容トヨタグループの金融、モビリティサービスの内製開発組織である同社にて、自社サービスである、クルマのサブスクリプションサービス『KINTO ONE』のWebサイトコンテンツの開発・運用業務を担っていただきます。
イベント情報
