Slack上でLLMを活用する社内チャットボット「しぇるぱ」の実装事例を紹介

1. はじめに
こんにちは、共通サービス開発グループの鳥居(@yu_torii)です。主にバックエンド/フロントエンド領域を担当しています。
KINTO 会員プラットフォーム開発チームでフロントエンドエンジニアを務めながら、社内での生成 AI 活用にも携わっています。
本記事では、Slack 上で LLM を活用する社内チャットボット「しぇるぱ」の RAG や Slack リアクションを活用した翻訳機能を紹介します。
しぇるぱは、社内での生成 AI 活用を目指して開発された Slack チャットボットです。
フロントエンド開発を省略して素早く社内に展開し、社員が普段使う Slack 上で生成 AI を自然に利用できる環境を目標としています。
「しぇるぱ」という名前はエベレスト登山のガイドとして知られるシェルパ族に由来し、彼らが登山者を支える頼れる存在であるように、しぇるぱもまた社内の業務効率の向上や情報共有の円滑化のための頼れるパートナーでありたいという願いが込められています。
ちなみに、バナーの「しぇるぱ」さんはクリエイティブグループの方が KINTO テクノジーズ全体会議(KTC 超本部会)に際してサプライズで描いてくれたものです。ありがとうございます!
この取り組みは、生成 AI 活用プロジェクトを推進する和田さん(@cognac_n)との協力により進められました。RAG パイプラインの導入、ローカル開発環境の整備、Slack 絵文字リアクションを活用した翻訳・要約機能など、多角的な改善を行い、社内での生成 AI 利活用を推進しています。
和田さんの記事はこちら
なお、RAG や生成 AI 技術そのものの詳細解説は省き、実装や機能追加の過程を中心にまとめています。
また、しぇるぱの LLM は Azure OpenAI を利用しています。
この記事で得られること
-
Slack Botによる生成AIを活用したチャット機能の利用方法
Slack と LLM を組み合わせ、絵文字リアクションや自然なメッセージ投稿で翻訳・要約を呼び出すチャットボット実装例を紹介 -
HTMLサニタイズを含むConfluenceデータ取得の工夫
Confluence ドキュメントを Go で取得し、HTML サニタイズにより要約・Embedding に適したテキストを整える方法 -
FAISS とS3を使った簡易的なRAGパイプライン導入
FAISS インデックスと S3 を活用した簡易 RAG パイプライン導入の手順と注意点を解説
応答速度はあまり早くないものの、低コストで簡易的な RAG を組み込む際の実装ステップや注意点をまとめます。
目次(展開)
2. 全体アーキテクチャの概要
ここでは、しぇるぱが生成 AI による回答を返すまでの流れを、「ユーザとの生成 AI チャット機能」と「Confluence ドキュメントをインデックス化する処理」という 2 つの視点で整理します。
ユーザとの生成AIチャット機能の処理
-
Slackでしぇるぱを呼び出す
しぇるぱの呼び出し方は、チャットでの呼び出しと、リアクション絵文字での呼び出しの 2 通りがあります。
チャットでの呼び出しは、チャンネルでメンションを付けて投稿するか、ダイレクトメッセージで直接投稿することで、生成 AI による回答をリクエストできます。
リアクションでの呼び出しは、翻訳・要約用の絵文字リアクションを付けることで、そのメッセージの翻訳や要約をリクエストできます。 -
Go Slack Bot Lambda
Slack イベントを受け取る Bot は Go で実装し、Lambda 上で動作します。
ユーザからの質問やリアクションを受け取り、リクエストの種類に応じて処理を振り分けます。
LLM へのリクエストや、Embedding 済みデータの参照など Azure OpenAI を利用する場合は、ここでリクエストを生成し、Python Lambda へ送信します。 -
Python LambdaでのLLMへのリクエスト・RAG参照
Python Lambda は機能ごとに分割し、LLM 問い合わせや RAG 参照などを担当します。
Go Lambda からのリクエストを受け取り、LLM への問い合わせや RAG による回答生成を行います。 -
Slackへの回答返送
生成された回答は、Go Slack Bot Lambda を経由して Slack へ返送します。
絵文字リアクションで呼び出す翻訳・要約機能も、このフローに組み込まれています。
アーキテクチャ図(ユーザからの呼び出しに対応する処理)
Confluence ドキュメントをインデックス化する処理
RAG パイプラインを利用するには、Confluence ドキュメントを要約・Embedding しやすい状態に整える必要があります。これらの前処理は StepFunctions でワークフロー化し、定期的かつ自動的に実行しています。
-
ドキュメント取得・HTMLサニタイズ(Go実装)
Go で実装した Lambda が Confluence API からドキュメントを取得し、HTML タグを整理してテキストを扱いやすい状態にします。
サニタイズ済みテキストは JSON として出力します。 -
要約処理(Go + Python Lambda呼び出し)
要約処理の目的は、テキストを Embedding や RAG で扱いやすい範囲に絞ることです。
Go 実装の Lambda が Azure OpenAI Chat API のリクエスト処理を行う Python Lambda を呼び出し、テキストを短く整え、再び JSON 化します。 -
FAISSインデックス化とS3保存(Indexer Lambda)
要約後のテキストを Embedding し、FAISS インデックスを生成する Indexer Lambda がインデックスやメタ情報を S3 へ格納します。
これにより、問い合わせ発生時にはインデックス済みデータを即座に参照でき、RAG パイプラインがスムーズに稼働します。
アーキテクチャ図(Confluence ドキュメントのインデックス化フロー)
こうした事前処理と問い合わせ時の処理が組み合わさることで、しぇるぱは Slack 上の簡易な操作で社内特有のナレッジを反映した生成 AI 回答を返せるようになっています。
以降の章では、これらの要素についてさらに詳細を見ていきます。
3. Slack Botによる生成AIを活用したチャット機能
前章でアーキテクチャの全体像を示しましたが、本章では、ユーザが Slack 上で自然な操作を行うだけで得られる機能について、その使い方や有用性に焦点を当てます。
ここでは「何ができるか」「どんなシナリオで役立つか」という利用イメージを示し、実装詳細は次章以降で体系的に紹介します。
「チャット機能」と「リアクション機能」
しぇるぱは、Slack 上での自然な操作を原動力に、多様な生成 AI 機能を提供します。
-
チャット機能:
質問を投稿したり、ファイルや画像、外部リンクを貼ったり、特定の形式でメッセージを送ることで、LLM への問い合わせや(特定の場合)RAG 検索が行われ、必要な回答が得られます。
Slack という日常的なツールに機能を統合することで、ユーザは新たな環境やコマンドを学ぶ必要なく、生成 AI を自然に日常業務へ取り込むことができます。 -
リアクション機能:
特定の絵文字リアクションをメッセージに付与するだけで翻訳やしぇるぱ発言の削除などをトリガーでき、コマンドレスでの追加操作が可能になります。
チャット機能:利用シナリオ
-
基本的な質問・回答
普通に質問を投稿するだけで、LLM を通じて回答を取得できます。- 利用シーン例:
「このプロジェクトの手順は?」と尋ねれば即座に回答が得られ、スレッド内の履歴や発言者情報を考慮して文脈に沿った応答が可能です。
- 利用シーン例:
-
ファイル・画像・外部リンク参照
ファイルを貼り付けて「要約して」と依頼すれば、ファイル内容を要約。
画像を添付すれば文字起こしや画像内容を踏まえた回答が可能。
外部リンクを貼れば、そのページ内容を整理して LLM 回答に生かせます。- 利用シーン例:
会議メモが入ったテキストファイルを「要約して」で短いサマリを得る、画像内文字情報を抜き出す、外部記事リンクを要約するといった、手間を省く活用ができます。
- 利用シーン例:
-
Confluenceページ参照(RAG活用)
:confluence: index:Index名で、社内でのルールや申請方法等のドキュメントが含まれた Confluence ページを RAG 検索。- 利用シーン例:
社内申請手順や内部ルールが Confluence にまとまっている場合、必要な情報を即座に引き出し、一般的な回答以上に社内事情に即したアドバイスが得られます。 - 利用シーン例:
プロジェクト独自の手順書や設定値を検索して、その内容を回答に反映。検索しづらい情報を簡単に引き出せます。
- 利用シーン例:
リアクション機能:利用シナリオ
特定の絵文字リアクションを付けることで、さらに直感的な機能呼び出しが可能です。
-
翻訳:
翻訳用絵文字を付ければ、そのメッセージを指定言語へ翻訳可能です。言語の壁を低くし、コミュニケーションを円滑化します。 -
削除
不要になったしぇるぱ発言を絵文字 1 つで簡易に削除し、チャンネルを整理できます。
この構成のメリット
-
自然な操作で活用可能:
ユーザは慣れた Slack 操作(メッセージ投稿、絵文字付与など)だけで生成 AI 機能を使え、学習コストを低減できます。 -
日常ツールへの統合で生成AI定着:
Slack という普段使うコミュニケーション基盤に機能を溶け込ませることで、生成 AI を身近に利用することが可能です。またリアクション機能は文字入力をすることなく、翻訳や削除などの操作ができるため、手軽に利用できます。 -
拡張に対応しやすい土台:
今後、新たなモデルや追加機能を組み込みたくなった場合も、既存のフロー(質問投稿、絵文字操作)に条件を増やすだけで拡張可能です。
3.5 実際の利用例
ここで、しぇるぱが Slack 上でどのように使われているか、実際のシナリオをいくつか紹介します。
例1:画像の認識
メッセージに画像を添付すると、しぇるぱは画像内のテキストを認識し、その内容を回答します。
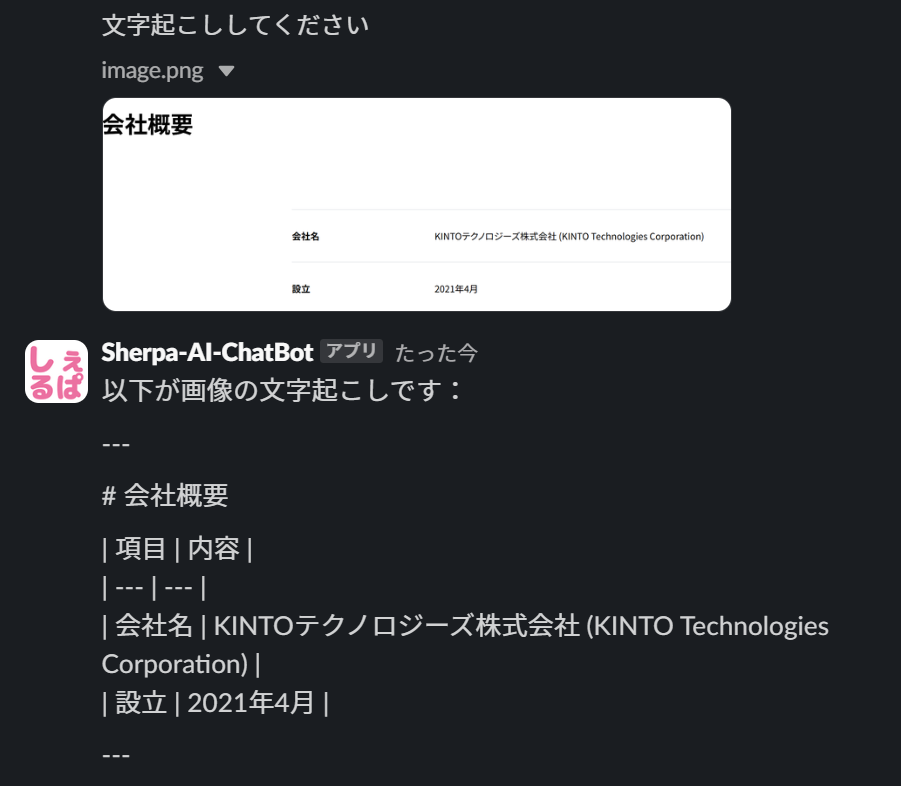
画像の認識
例2:Confluenceドキュメントに基づく回答
:confluence: という絵文字を使うことで、Confluence ドキュメントを参照した回答を得ることができます。
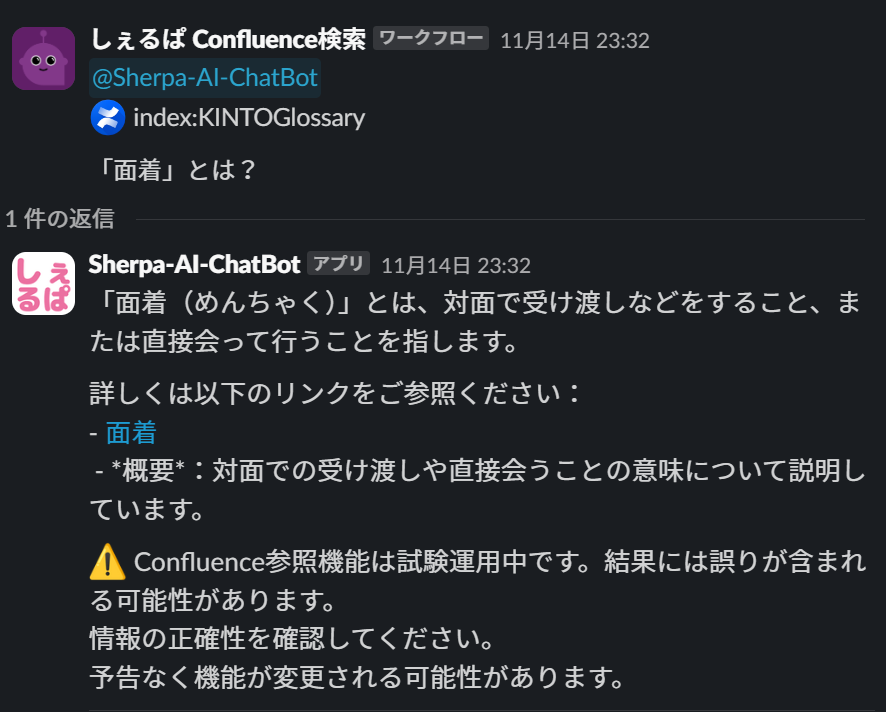
Confluenceドキュメントに基づく回答
ご覧の通り、しぇるぱはワークフローから呼び出すことも可能で、プロンプトストアのような利用も可能です。
例3:翻訳リアクションでの英訳依頼
ユーザが英訳したいメッセージに翻訳リアクションを付与
英語話者に共有したい日本語メッセージに :sherpa_translate_to_english: といったリアクション絵文字を付けると、そのメッセージのテキストが自動で英訳されます。
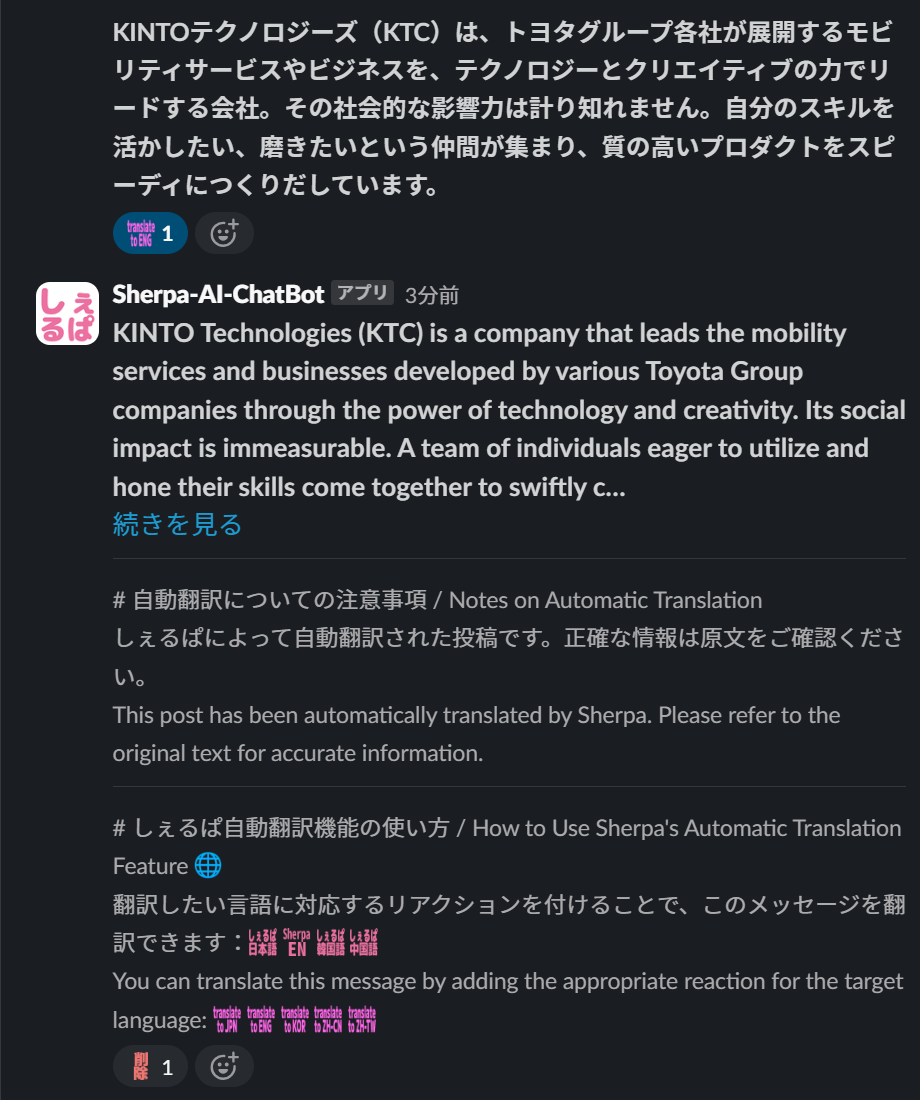
英語翻訳リアクション
翻訳内容を過信しないように、自動翻訳であることを複数言語で通知することで、誤解を防ぎます。
また、機能を普及させるために、利用方法も記載しています。
英訳の他に複数言語の翻訳機能を提供しています。
3章まとめ
本章では、「どんな操作で何ができるか」というユーザ視点の使い方に注目しました。
ここで得た利用イメージを基に、次の章以降で実装内容を体系的に示し、Go 製 Bot や Python Lambda の連携方法、Slack イベントの処理や RAG 検索のしくみ、ファイル抽出やサニタイズ処理などの詳細を紹介します。
4. 実装方針と内部設計
この章では、しぇるぱが Slack のメッセージやリアクションを通じて多様な生成 AI 機能を提供するための実装方針と内部設計について説明します。
ここで紹介するのは、あくまで全体的な考え方や役割分担、拡張性への配慮に関する部分です。具体的なコードや設定ファイルは次章以降に記載します。
全体的な処理フロー
-
Slackイベント受信(Go Lambda)
Slack で行われるメッセージ投稿、ファイル添付、画像挿入、外部リンク記載、絵文字リアクションなどのイベントは、Slack API 経由で Go 実装の AWS Lambda へ通知されます。
Go 側はこれらのイベントを解析し、ユーザが求める処理(通常のチャット、翻訳、Confluence 参照など)を判定します。 -
Go側でのテキスト処理・サニタイズ
外部リンクやファイルからテキストを取得し、コンテキストとしてプロンプトに追加します。
外部リンクを参照する場合はtable、ol、ulなど意味のあるタグは残し、不要なタグだけを除去してトークンを節約します。 -
Python側でのLLM問い合わせ・RAG検索
必要な場合、Go 側は LLM 問い合わせ用の Python Lambda(LLM 用)か、RAG 検索用の Python Lambda(Confluence 参照用)を呼び出します。
例えば、:confluence:が含まれていれば RAG 検索用 Lambda を呼び出し、index が指定されていなければデフォルトインデックスで検索します。
そうでなければ通常は LLM 用 Lambda へテキストを渡し、LLM への問い合わせを行います。 -
回答返却とSlack表示
Python 側の Lambda が生成した回答を Go 側に戻し、Go 側が Slack へ投稿します。
これにより、ユーザはコマンドを暗記する必要なく、絵文字やキーワード、ファイル添付など日常的な操作だけで高度な機能を利用できます。
条件分岐による機能判定
特定の絵文字(:confluence: など)やキーワード、ファイルや画像の有無、外部リンク存在などにより処理を振り分けます。
新機能を追加する場合は、Go 側で新たな条件を追加して、必要なら対応する Python 側の Lambda(LLM 用、RAG 用など)を呼び出すロジックを増やすことで実現できます。
サニタイズの役割
Go 側でサニタイズし、不要な HTML タグを除去することで、モデルへ渡すテキストを効率的に扱い、トークン消費を抑えます。
table、ol、ul など意味あるタグは残して情報構造を保持し、モデルにとって有用な文脈を損ねないようにしています。
RAG利用をConfluence参照に限定
RAG 検索は :confluence: 指定時のみ利用します。
これにより通常の要約や翻訳、Q&A は LLM 直接問い合わせで済み、RAG 関連ロジックは Confluence 参照時だけ発動します。
Confluence ドキュメントの Embedding 生成や FAISS インデックス更新は StepFunctions で定期的に実行し、問い合わせ時には常に最新インデックスを利用できます。
拡張性・保守性への考慮
絵文字やキーワード、ファイル・画像の有無による条件分岐は、機能を増やす際の変更箇所を少なく保ち、保守性を高めます。
Go 側でテキスト整形やサニタイズ、Python 側で LLM 問い合わせ・RAG 検索を行う役割分担も、コードの見通しを良くし、将来的なモデル切り替えや処理追加を容易にします。
次章では、これらの方針を踏まえた具体的なコードスニペットや設定ファイル例を紹介します。
5. コード例と設定ファイルの紹介
この章では、第 4 章で説明した実装方針や設計上の考え方に基づいて、実装例を要点を絞って紹介します。
本章は次のセクションで構成します。
-
5.1 Slack イベント受信と解析(Go 側)
Slack の Events API を用いてメッセージや絵文字リアクションなどのイベントを受信・解析する方法を示します。 -
5.2 Go 側でサニタイズ例
外部リンク参照した際の HTML サニタイズ処理の例を示します。 -
5.3 Python 側 LLM 問い合わせの具体例
LLM(LLM)への問い合わせを行う Lambda のコード例を提示します。 -
5.4 Python 側 RAG 検索呼び出し例
Confluence 参照など RAG を使う場合の検索呼び出し例を紹介します。 -
5.5 Python 側 Embedding と FAISS インデックス化
Confluence ドキュメントを定期的に Embedding し、FAISS インデックスを更新する Lambda のコード例を示します。
5.1 [Go] Slackイベント受信と解析
このセクションでは、Slack の Events API を利用して、AWS Lambda 上で Go コードでイベントを受信・解析する基本的な流れを説明します。
Slack 側での設定(OAuth & Permissions、イベント購読)や、chat.postMessage メソッド利用時に必要なスコープ(chat:write など)の確認方法にも触れ、読者が実装を始めるまでに必要な準備を明確にします。
Slack側での設定手順
-
App作成とApp IDの確認:
https://api.slack.com/appsで新規 App を作成します。
作成後、Basic Information ページ(https://api.slack.com/apps/APP_ID/general、APP_IDは App 固有の ID)で App ID(Aで始まる文字列)を確認します。
この App ID は Slack App の識別子であり、後述のOAuth & PermissionsやEvent Subscriptionsページの URL アクセスに用いることができます。 -
OAuth & Permissionsでスコープ付与:
「OAuth & Permissions」ページ(https://api.slack.com/apps/APP_ID/oauth)にアクセスし、Bot Token Scopes に必要なスコープを追加します。
例えば、チャンネルへメッセージ投稿にchat.postMessageメソッドが必要である場合、https://api.slack.com/methods/chat.postMessageで「Required scopes」を確認するとchat:writeが必要であるとわかります。
スコープ付与後、「reinstall your app」をクリックし、ワークスペースに再インストールすると、変更が反映されます。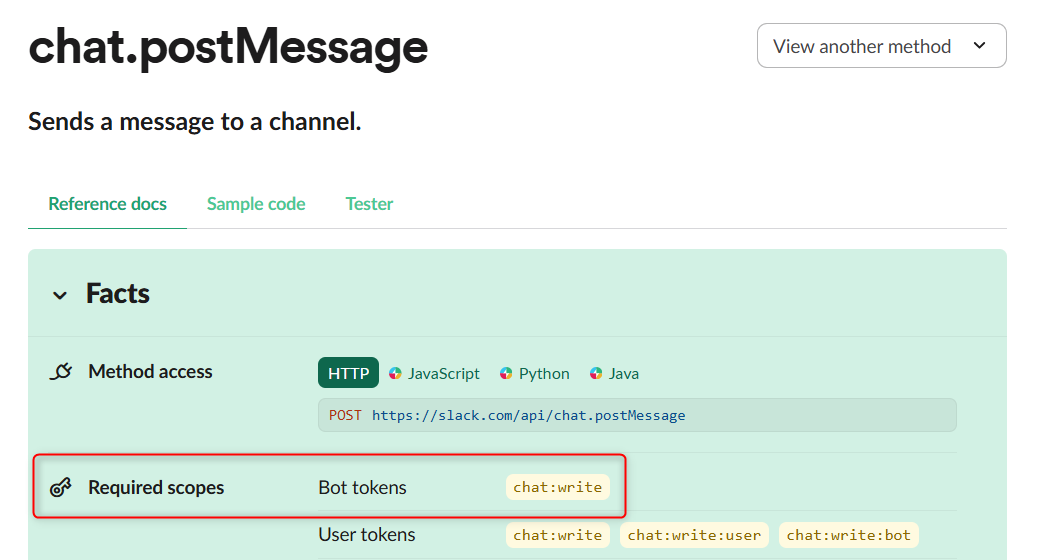
Required scopesの確認
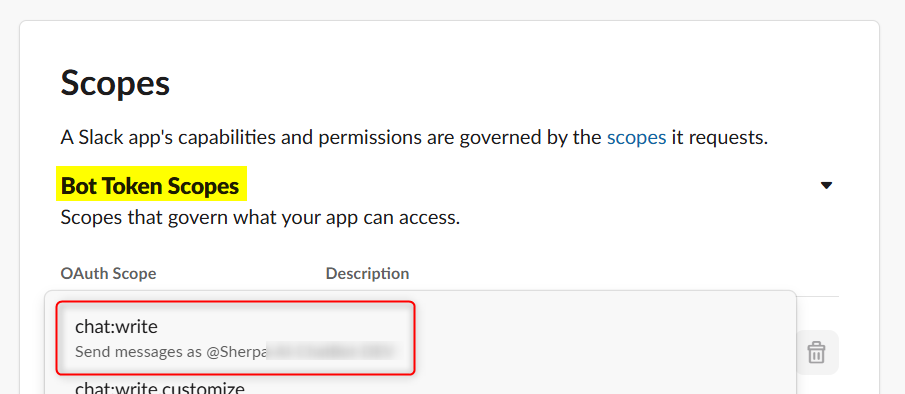
Scopeの設定 -
Events API有効化とイベント購読:
「Event Subscriptions」ページ(https://api.slack.com/apps/APP_ID/event-subscriptions)で Events API を有効化し、「Request URL」に後述の AWS Lambda エンドポイントを設定します。
message.channelsやreaction_addedなど、購読するイベントを追加します。これにより、対象イベント発生時に Slack が指定 URL へ通知を送るようになります。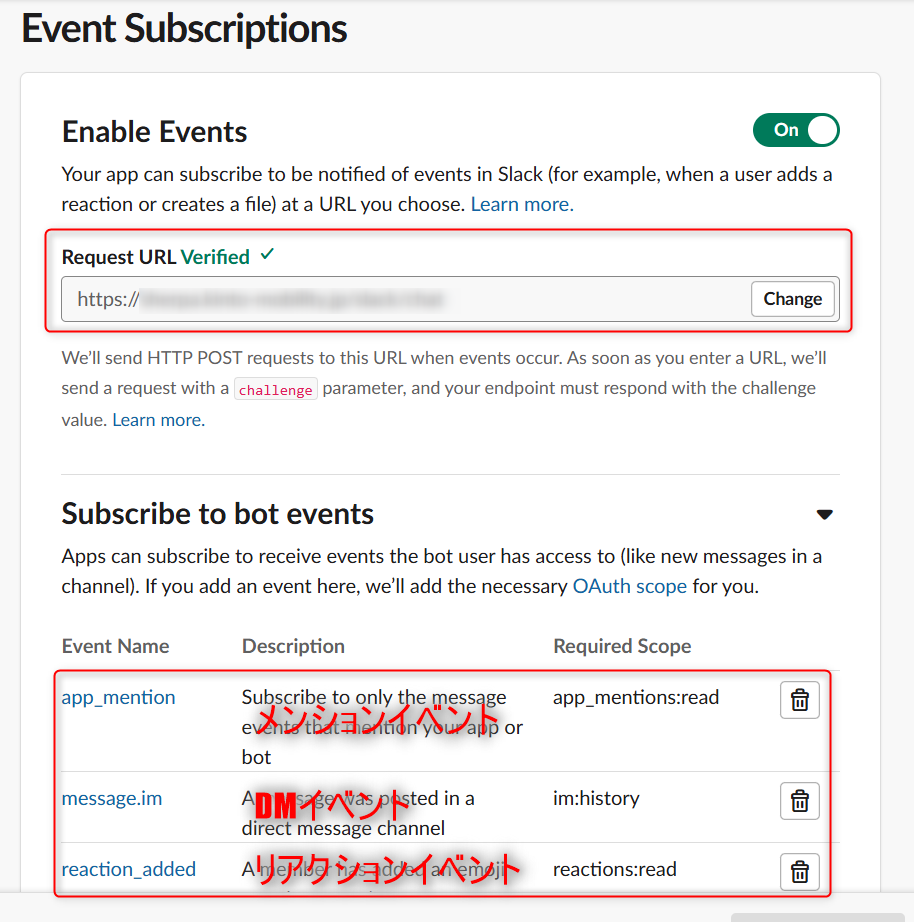
AWS Lambda側でのイベント受信・解析
Slack 側での設定が完了すると、購読対象のイベントが発生するたびに Slack は API Gateway 経由で Lambda へ POST リクエストを送ります。
ステップ1:Slackイベントの解析
slack-go/slackevents パッケージを用いて、受信した JSON を EventsAPIEvent へ変換します。
これにより、URL 検証や CallbackEvent などイベントタイプを判別しやすくなります。
func parseSlackEvent(body string) (*slackevents.EventsAPIEvent, error) {
event, err := slackevents.ParseEvent(json.RawMessage(body), slackevents.OptionNoVerifyToken())
if err != nil {
return nil, fmt.Errorf("Slackイベントの解析に失敗しました: %w", err)
}
return &event, nil
}
ステップ2:URL検証要求対応
初回に Slack は type=url_verification のイベントを送ってきます。この中の challenge をそのまま返すことで Slack は URL 有効性を確認し、その後イベントを通知してくれるようになります。
func handleURLVerification(body string) (events.APIGatewayProxyResponse, error) {
var r struct {
Challenge string `json:"challenge"`
}
if err := json.Unmarshal([]byte(body), &r); err != nil {
return createErrorResponse(400, err)
}
return events.APIGatewayProxyResponse{
StatusCode: 200,
Body: r.Challenge,
}, nil
}
ステップ3:署名検証・再試行リクエスト無視
Slack はリクエスト署名を付与し、正当性を検証できます(実装は省略)。
また、障害時などに再試行リクエストが送られる場合があり、X-Slack-Retry-Num ヘッダで再試行を判定して同じイベントを二重処理しないようにできます。
func verifySlackRequest(body string, headers http.Header) error {
// 署名検証処理(省略)
return nil
}
func isSlackRetry(headers http.Header) bool {
return headers.Get("X-Slack-Retry-Num") != ""
}
func createIgnoredRetryResponse() (events.APIGatewayProxyResponse, error) {
responseBody, _ := json.Marshal(map[string]string{"message": "Slackの再試行を無視します"})
return events.APIGatewayProxyResponse{
StatusCode: 200,
Headers: map[string]string{"Content-Type": "application/json"},
Body: string(responseBody),
}, nil
}
ステップ4:CallbackEvent処理
CallbackEvent は実際のメッセージ投稿やリアクション追加などが含まれます。ここで、:confluence: が含まれるか、ファイルがあるか、翻訳用絵文字が付いているかなどを判定し、5.2 以降で示すテキスト処理や Python Lambda 呼び出しへ進みます。
// handleCallbackEvent は、コールバックイベントを処理します。(5.1での説明対象)
func handleCallbackEvent(ctx context.Context, isOrchestrator bool, event *slackevents.EventsAPIEvent) (events.APIGatewayProxyResponse, error) {
innerEvent := event.InnerEvent
switch innerEvent.Data.(type) {
case *slackevents.AppMentionEvent:
// AppMentionEventの場合の処理(5.2で詳細説明)
case *slackevents.MessageEvent:
// MessageEventの場合の処理(5.2で詳細説明)
case *slackevents.ReactionAddedEvent:
// ReactionAddedEventの場合の処理(5.2で詳細説明)
}
return events.APIGatewayProxyResponse{Body: "OK", StatusCode: http.StatusOK}, nil
}
ハンドラ全体のコード例
これらのステップを組み合わせて AWS Lambda ハンドラを定義します。
ハンドラ全体のコード例
func handler(ctx context.Context, request events.APIGatewayProxyRequest) (events.APIGatewayProxyResponse, error) {
event, err := parseSlackEvent(request.Body)
if err != nil {
return createErrorResponse(400, err)
}
if event.Type == slackevents.URLVerification {
return handleURLVerification(request.Body)
}
headers := convertToHTTPHeader(request.Headers)
err = verifySlackRequest(request.Body, headers)
if err != nil {
return createErrorResponse(http.StatusUnauthorized, fmt.Errorf("リクエストの検証に失敗しました: %w", err))
}
if isSlackRetry(headers) {
return createIgnoredRetryResponse()
}
if event.Type == slackevents.CallbackEvent {
return handleCallbackEvent(ctx, event)
}
return events.APIGatewayProxyResponse{Body: "OK", StatusCode: 200}, nil
}
func convertToHTTPHeader(headers map[string]string) http.Header {
httpHeaders := http.Header{}
for key, value := range headers {
httpHeaders.Set(key, value)
}
return httpHeaders
}
func createErrorResponse(statusCode int, err error) (events.APIGatewayProxyResponse, error) {
responseBody, _ := json.Marshal(map[string]string{"error": err.Error()})
return events.APIGatewayProxyResponse{
StatusCode: statusCode,
Headers: map[string]string{"Content-Type": "application/json"},
Body: string(responseBody),
}, err
}
5.1のまとめ
このセクションで、Slack App の App ID や OAuth & Permissions でのスコープ付与方法、Event Subscriptions でのイベント購読設定を説明し、Slack イベントの受信・解析プロセス(URL Verification 対応、署名検証、再試行リクエスト無視、CallbackEvent 処理)を示しました。
次の 5.2 以降では、CallbackEvent 処理の具体例や、Go 側でのテキスト処理、Python Lambda への問い合わせ方法などを紹介します。
5.2 [Go] HTMLテキストのサニタイズ
外部リンク参照内容のサニタイズ
外部リンクから取得した HTML テキストには、script や style など回答に不要なタグが含まれる場合があります。そのまま LLM に渡すと、トークン数が増えてモデルコストが上昇し、回答精度が下がる可能性があります。次のコードでは、bluemonday パッケージを用いて基本的なサニタイズを行ったうえで、table や ol、ul など重要なタグを残しつつ不要なタグを除去し、読みやすい形に整形します。addNewlinesForTags 関数を活用し、特定のタグ後に改行を挿入してテキストを整えることで、モデルへの問い合わせ時に必要な情報のみを最適なフォーマットで渡すことが可能になります。
func sanitizeContent(htmlContent string) string {
// 基本的なサニタイズ
ugcPolicy := bluemonday.UGCPolicy()
sanitized := ugcPolicy.Sanitize(htmlContent)
// カスタムポリシーで特定タグを許可
customPolicy := bluemonday.NewPolicy()
customPolicy.AllowLists()
customPolicy.AllowTables()
customPolicy.AllowAttrs("href").OnElements("a")
// タグごとに改行を追加して可読性向上
formattedContent := addNewlinesForTags(sanitized, "p")
// カスタムポリシー適用後の最終サニタイズ
finalContent := customPolicy.Sanitize(formattedContent)
return finalContent
}
func addNewlinesForTags(htmlStr string, tags ...string) string {
for _, tag := range tags {
closeTag := fmt.Sprintf("</%s>", tag)
htmlStr = strings.ReplaceAll(htmlStr, closeTag, closeTag+"\n")
}
return htmlStr
}
この処理により、モデルへの入力は不要なタグが取り除かれたテキストのみとなり、回答精度とコスト効率が向上します。必要な構造(テーブルや箇条書き)は保持しつつ、特定タグの終了後に改行を挿入することで、モデルが情報を理解しやすい形でコンテキストを提供できます。
5.3 [Python] LLM問い合わせの具体例
以下は、Python で LLM(たとえば Azure OpenAI)へ問い合わせる処理の例です。OpenAIClientFactory を用いてモデルやエンドポイントを動的に切り替えられるため、複数の Lambda ハンドラ間で共通のクライアント生成処理を再利用できます。
クライアント生成処理
OpenAIClientFactory は api_type や model に応じて Azure OpenAI または OpenAI 用のクライアントを動的に生成します。
環境変数や秘密情報により API キー、エンドポイントを取得するため、モデル変更や設定変更時もコード修正が最小限で済みます。
import openai
from shared.secrets import get_secret
class OpenAIClientFactory:
@staticmethod
def create_client(region="eastus2", model="gpt-4o") -> openai.OpenAI:
secret = get_secret()
api_type = secret.get("openai_api_type", "azure")
if api_type == "azure":
return openai.AzureOpenAI(
api_key=secret.get(f"azure_openai_api_key_{region}"),
azure_endpoint=secret.get(f"azure_openai_endpoint_{region}"),
api_version=secret.get(
f"azure_openai_api_version_{region}", "2024-07-01-preview"
),
)
elif api_type == "openai":
return openai.OpenAI(api_key=secret.get("openai_api_key"))
raise ValueError(f"Invalid api_type: {api_type}")
LLM問い合わせ処理
chatCompletionHandler 関数では、HTTP リクエストとして受け取った JSON から messages や model、temperature などを取得し、OpenAIClientFactory で生成したクライアントを用いて LLM に問い合わせます。
レスポンスは JSON 形式で返し、エラー発生時は共通のエラーレスポンス生成関数によって整形されたレスポンスを返します。
import json
from typing import Any, Dict, List
import openai
from openai.types.chat import ChatCompletionMessageParam
from shared.openai_client import OpenAIClientFactory
def chatCompletionHandler(event: Dict[str, Any], context: Any) -> Dict[str, Any]:
request_body = json.loads(event["body"])
messages: List[ChatCompletionMessageParam] = request_body.get("messages", [])
model = request_body.get("model", "gpt-4o")
client = OpenAIClientFactory.create_client(model=model)
temperature = request_body.get("temperature", 0.7)
max_tokens = request_body.get("max_tokens", 4000)
response_format = request_body.get("response_format", None)
completion = client.chat.completions.create(
model=model,
stream=False,
messages=messages,
max_tokens=max_tokens,
frequency_penalty=0,
presence_penalty=0,
temperature=temperature,
response_format=response_format,
)
return {
"statusCode": 200,
"body": json.dumps(completion.to_dict()),
"headers": {
"Content-Type": "application/json",
"Access-Control-Allow-Origin": "*",
"Access-Control-Allow-Methods": "OPTIONS,POST",
"Access-Control-Allow-Headers": "Content-Type,X-Amz-Date,Authorization,X-Api-Key,X-Amz-Security-Token",
},
}
この仕組みにより、異なる Lambda ハンドラでも同様の手順で LLM 問い合わせが可能となり、モデルやエンドポイント変更にも柔軟に対応できる構成となっています。
5.4 [Python] RAG検索呼び出し例
このセクションでは、Python で RAG(Retrieval Augmented Generation)検索を行うための手順を示します。
Confluence ドキュメントなど社内のナレッジをベクトル化し、FAISS インデックスを用いて類似文書検索を行うことで、LLM 回答に特化した情報を組み込むことが可能です。
ここで注目すべき点は faiss ライブラリの取り扱いです。faiss は非常にサイズが大きく、Lambda Layer の容量制限を超える可能性があるため、通常は EFS を利用するか、Lambda をコンテナ化する必要があります。
今回はその手間を省くため、setup_faiss 関数により S3 から faiss 関連パッケージをダウンロード・展開し、sys.path に動的に追加することで faiss を利用可能にしています。
FAISS とは
FAISS(Facebook AI Similarity Search)は、Meta(Facebook)製の近似最近傍探索ライブラリであり、類似の画像やテキストを検索するためのインデックスを作成するツールです。
setup_faiss 関数によるFAISSセットアップ
FAISS パッケージを Lambda 環境で利用するために、setup_faiss 関数では次の手順を行います。
-
ローカル/CI環境でfaissパッケージをビルド・アーカイブ
開発者が GitHub Actions などの CI 環境でfaiss-cpuパッケージをインストールし、必要なバイナリをtar.gz形式でまとめます。 -
S3へアップロード
CI でビルド・アーカイブしたfaiss_package.tar.gzを S3 にアップロードします。
本番やステージング環境に合わせて、適切なバケットやパスへ格納することで、Lambda 実行時に S3 から動的に取得可能です。 -
Lambda実行時に
setup_faissで動的ロード
Lambda 実行環境上では、setup_faiss関数が起動時に S3 からfaiss_package.tar.gzをダウンロード・展開し、sys.pathに追加します。
これにより、Lambda コード内でimport faissが可能となり、Embedding 処理で作成したベクトルを高速に検索できます。
GitHub Actions でfaissパッケージをS3へアップロードする例
以下は、faiss-cpu をインストールし、Lambda で利用できるようにパッケージ化した上で、S3 にアップロードする GitHub Actions の例です。
ここでは、GitHub Actions の Secret や Environment Variables 機能を利用することで、AWS 認証情報や S3 バケット名などをハードコーディングせずに管理しています。
name: Build and Upload FAISS
on:
workflow_dispatch:
inputs:
environment:
description: デプロイ環境
type: environment
default: dev
jobs:
build-and-upload-faiss:
environment: ${{ inputs.environment }}
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- uses: actions/setup-python@v5
with:
python-version: "3.11"
# 必要なパッケージのインストール(faiss-cpu)
- name: Install faiss-cpu
run: |
set -e
echo "Installing faiss-cpu..."
pip install faiss-cpu --no-deps
# faiss のバイナリをアーカイブ
- name: Archive faiss binaries
run: |
mkdir -p faiss_package
pip install --target=faiss_package faiss-cpu
tar -czvf faiss_package.tar.gz faiss_package
# AWS認証情報の設定(環境に合わせてSecretsやRoleを指定)
- name: Configure AWS credentials
uses: aws-actions/configure-aws-credentials@v3
with:
aws-access-key-id: ${{ secrets.CICD_AWS_ACCESS_KEY_ID }}
aws-secret-access-key: ${{ secrets.CICD_AWS_SECRET_ACCESS_KEY }}
aws-region: ap-northeast-1
# S3 にアップロード
- name: Upload faiss binaries to S3
run: |
echo "Uploading faiss_package.tar.gz to S3..."
aws s3 cp faiss_package.tar.gz s3://${{ secrets.AWS_S3_BUCKET }}/lambda/faiss_package.tar.gz
echo "Upload complete."
上記の例では、faiss_package.tar.gz が S3 に lambda/faiss_package.tar.gz というキーでアップロードされます。
Lambda側での動的ロード処理 (setup_faiss 関数)
setup_faiss 関数は、Lambda 実行時に S3 から faiss_package.tar.gz をダウンロードし、/tmp ディレクトリに展開、sys.path にパッケージパスを追加します。こうして Lambda 内で import faiss が可能になり、FAISS インデックス検索を実行できるようになります。
# setup_faiss例:S3上のfaissパッケージをダウンロードし、sys.pathに追加
import os
import sys
import tarfile
from shared.logger import getLogger
from shared.s3_client import S3Client
logger = getLogger(__name__)
def setup_faiss(s3_client: S3Client, s3_bucket: str) -> None:
try:
import faiss
logger.info("faiss が既にインポートされています。")
except ImportError:
logger.info("faiss が見つかりません。S3からダウンロードします。")
faiss_package_key = "lambda/faiss_package.tar.gz"
faiss_package_path = "/tmp/faiss_package.tar.gz"
faiss_extract_path = "/tmp/faiss_package"
# S3からパッケージをダウンロードして展開
s3_client.download_file(bucket_name=s3_bucket, key=faiss_package_key, file_path=faiss_package_path)
with tarfile.open(faiss_package_path, "r:gz") as tar:
for member in tar.getmembers():
member.name = os.path.relpath(member.name, start=member.name.split("/")[0])
tar.extract(member, faiss_extract_path)
sys.path.insert(0, faiss_extract_path)
import faiss
logger.info("faiss のインポートに成功しました。")
EmbeddingsとFAISSインデックスを用いたRAG検索
search_data 関数では、S3 から取得した FAISS インデックスをローカルでロードし、クエリに合致する文書を検索します。get_embeddings 関数によって生成される Embeddings クライアント(Azure OpenAI または OpenAI)を用いて文書をベクトル化しており、faiss を活用した高速検索が可能です。
from typing import Any, Dict, List, Optional
from langchain_community.vectorstores import FAISS
from langchain_core.documents.base import Document
from langchain_core.vectorstores.base import VectorStoreRetriever
from shared.secrets import get_secret
from shared.logger import getLogger
from langchain_openai import AzureOpenAIEmbeddings, OpenAIEmbeddings
logger = getLogger(__name__)
def get_embeddings(secrets: Dict[str, str]):
api_type: str = secrets.get("openai_api_type", "azure")
if api_type == "azure":
return AzureOpenAIEmbeddings(
openai_api_key=secrets.get("azure_openai_api_key_eastus2"),
azure_endpoint=secrets.get("azure_openai_endpoint_eastus2"),
model="text-embedding-3-large",
api_version=secrets.get("azure_openai_api_version_eastus2", "2023-07-01-preview"),
)
elif api_type == "openai":
return OpenAIEmbeddings(
openai_api_key=secrets.get("openai_api_key"),
model="text-embedding-3-large",
)
else:
logger.error("無効なAPIタイプが指定されています。")
raise ValueError("Invalid api_type")
def search_data(
query: str,
index_folder_path: str,
search_type: str = "similarity",
score_threshold: Optional[float] = None,
k: Optional[int] = None,
fetch_k: Optional[int] = None,
lambda_mult: Optional[float] = None,
) -> List[Dict]:
secrets: Dict[str, str] = get_secret()
embeddings = get_embeddings(secrets)
db: FAISS = FAISS.load_local(
folder_path=index_folder_path,
embeddings=embeddings,
allow_dangerous_deserialization=True,
)
search_kwargs = {"k": k}
if search_type == "similarity_score_threshold" and score_threshold is not None:
search_kwargs["score_threshold"] = score_threshold
elif search_type == "mmr":
search_kwargs["fetch_k"] = fetch_k or k * 4
if lambda_mult is not None:
search_kwargs["lambda_mult"] = lambda_mult
retriever: VectorStoreRetriever = db.as_retriever(
search_type=search_type,
search_kwargs=search_kwargs,
)
results: List[Document] = retriever.invoke(input=query)
return [{"content": doc.page_content, "metadata": doc.metadata} for doc in results]
非同期ダウンロードとLambdaハンドラ
async_handler 内で setup_faiss を実行し、download_files で S3 から FAISS インデックスファイルを取得します。その後 search_data で RAG 検索を実行し、結果を JSON で返します。
import asyncio
import json
import os
from shared.s3_client import S3Client
from shared.logger import getLogger
from shared.token_verifier import with_token_verification
logger = getLogger(__name__)
RESULT_NUM = 5
@with_token_verification
async def async_handler(event: Dict[str, Any], context: Any) -> Dict[str, Any]:
env = os.getenv("ENV")
s3_client = S3Client()
s3_bucket = "bucket-name"
setup_faiss(s3_client, s3_bucket)
request_body_str = event.get("body", "{}")
request_body = json.loads(request_body_str)
query = request_body.get("query")
index_path = request_body.get("index_path")
local_index_dir = "/tmp/index_faiss"
await download_files(s3_client, s3_bucket, index_path, local_index_dir)
results = search_data(
query,
local_index_dir,
search_type=request_body.get("search_type", "similarity"),
score_threshold=request_body.get("score_threshold"),
k=request_body.get("k", RESULT_NUM),
fetch_k=request_body.get("fetch_k"),
lambda_mult=request_body.get("lambda_mult"),
)
return create_response(200, results)
def retrieverHandler(event: Dict[str, Any], context: Any) -> Dict[str, Any]:
return asyncio.run(async_handler(event, context))
def create_response(status_code: int, body: Any) -> Dict[str, Any]:
return {
"statusCode": status_code,
"body": json.dumps(body, ensure_ascii=False),
"headers": {
"Content-Type": "application/json",
},
}
async def download_files(s3_client: S3Client, bucket: str, key: str, file_path: str) -> None:
loop = asyncio.get_running_loop()
await loop.run_in_executor(None, download_files_from_s3, s3_client, bucket, key, file_path)
def download_files_from_s3(s3_client: S3Client, s3_bucket: str, prefix: str, local_dir: str) -> None:
keys = s3_client.list_objects(bucket_name=s3_bucket, prefix=prefix)
if not keys:
logger.info(f"'{prefix}'内にファイルが存在しません。")
return
for key in keys:
relative_path = os.path.relpath(key, prefix)
local_file_path = os.path.join(local_dir, relative_path)
os.makedirs(os.path.dirname(local_file_path), exist_ok=True)
s3_client.download_file(bucket_name=s3_bucket, key=key, file_path=local_file_path)
5.4のまとめ
setup_faissによるfaiss動的ロードで Lambda レイヤー容量問題を回避- 非同期 I/O と S3 利用により、コンテナ化や EFS 接続なしで FAISS インデックスをロード
search_dataで Embedding 済みインデックスを検索し、RAG が迅速な類似文書提供を実現
これにより、RAG 検索を用いた高速なナレッジ検索が可能となり、LLM 回答に特化した情報提供が実現できます。
5.5 [Python] EmbeddingとFAISSインデックス化
このセクションでは、Confluence ドキュメントなどの社内ドキュメントを Embedding し、FAISS インデックスを作成・更新する定期バッチ処理の例を示します。
RAG パイプラインで参照するインデックスは、生成 AI が社内特有の知識を回答に反映するための重要な鍵です。そのため、定期的なドキュメント更新時には Embedding と FAISS インデックスを再構築し、最新情報を常に参照できるようにします。
処理の概要
- S3 から JSON フォーマットのドキュメントを取得
- 取得したドキュメントを Embedding(OpenAI や Azure OpenAI の Embeddings API を利用)
- Embedding 済みのテキスト群を FAISS インデックス化
- 作成した FAISS インデックスを S3 へアップロード
これらの手順を Lambda バッチ処理や Step Functions ワークフローで定期的に実行することで、問い合わせ時には常に最新インデックスを用いた RAG 検索が行えます。
ステップ1:JSONドキュメントの読み込み
S3 上の JSON ファイル(Confluence ページ等を要約済みのもの)をダウンロード・パースし、Document オブジェクトのリストに変換します。
import json
from typing import Any, Dict, List
from langchain_core.documents.base import Document
from shared.logger import getLogger
logger = getLogger(__name__)
def load_json(file_path: str) -> List[Document]:
"""
JSONファイルを読み込み、Documentオブジェクトのリストを返します。
JSONは [{"title": "...", "content": "...", "id": "...", "url": "..."}] のような形式を想定。
"""
with open(file_path, "r", encoding="utf-8") as f:
data = json.load(f)
if not isinstance(data, list):
raise ValueError("JSONトップレベルがリストではありません。")
documents = []
for record in data:
if not isinstance(record, dict):
logger.warning(f"スキップされたレコード(辞書でない): {record}")
continue
title = record.get("title", "")
content = record.get("content", "")
metadata = {
"id": record.get("id"),
"title": title,
"url": record.get("url"),
}
# タイトルとコンテンツをまとめたテキストとしてDocument化
doc = Document(page_content=f"Title: {title}\nContent: {content}", metadata=metadata)
documents.append(doc)
logger.info(f"{len(documents)} 件のドキュメントをロードしました。")
return documents
ステップ2:EmbeddingとFAISSインデックス化
vectorize_and_save 関数では、get_embeddings で取得した Embeddings クライアントでドキュメントを Embedding し、FAISS インデックスを作成します。その後、ローカルにインデックスを保存します。
import os
from langchain_community.vectorstores import FAISS
from langchain_core.text_splitter import RecursiveCharacterTextSplitter
from shared.logger import getLogger
logger = getLogger(__name__)
def vectorize_and_save(documents: List[Document], output_dir: str, embeddings) -> None:
"""
ドキュメントをEmbeddingし、FAISSインデックスを作成してローカルに保存します。
"""
# テキスト分割器を使用してドキュメントを小さなチャンクに分割
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1024, chunk_overlap=128)
split_docs = text_splitter.split_documents(documents)
logger.info(f"{len(split_docs)} 件の分割済みドキュメント")
# Embeddingsでベクトル化し、FAISSインデックス構築
db: FAISS = FAISS.from_documents(split_docs, embeddings)
logger.info("ベクトルDBの構築が完了しました。")
os.makedirs(output_dir, exist_ok=True)
db.save_local(output_dir)
logger.info(f"ベクトルDBを {output_dir} に保存しました。")
ステップ3:インデックスをS3へアップロード
ローカルで作成した FAISS インデックスを S3 にアップロードすることで、RAG 検索用 Lambda から容易に取得可能になります。
from shared.s3_client import S3Client
from shared.logger import getLogger
logger = getLogger(__name__)
def upload_faiss_to_s3(s3_client: S3Client, s3_bucket: str, local_index_dir: str, index_s3_path: str) -> None:
"""
FAISSインデックスをS3にアップロードします。
"""
index_files = ["index.faiss", "index.pkl"]
for file_name in index_files:
local_file_path = os.path.join(local_index_dir, file_name)
s3_index_key = os.path.join(index_s3_path, file_name)
s3_client.upload_file(local_file_path, s3_bucket, s3_index_key)
logger.info(f"FAISSインデックスファイルを s3://{s3_bucket}/{s3_index_key} にアップロードしました。")
ステップ4:全体フローをLambdaで実行
index_to_s3 関数は全体フローをまとめています。S3 から JSON をダウンロード、Embedding と FAISS インデックス作成、そしてインデックスを S3 へアップロードします。この処理を Step Functions などのワークフローで定期的に実行し、常に最新のインデックスを用意します。
import os
from shared.faiss import setup_faiss
from shared.logger import getLogger
from shared.s3_client import S3Client
from shared.secrets import get_secret
logger = getLogger(__name__)
def index_to_s3(json_s3_key: str, index_s3_path: str) -> Dict[str, Any]:
"""
S3からJSONファイルをダウンロードし、EmbeddingとFAISSインデックス作成を行い、インデックスをS3に保存します。
"""
env = os.getenv("ENV")
if env is None:
error_msg = "ENV 環境変数が設定されていません。"
logger.error(error_msg)
return {"status": "error", "message": error_msg}
try:
s3_client = S3Client()
s3_bucket = "bucket-name"
local_json_path = "/tmp/json_file.json"
local_index_dir = "/tmp/index"
# 必要なら faiss のセットアップ(S3からダウンロード)
setup_faiss(s3_client, s3_bucket)
# JSONファイルをS3からダウンロード
s3_client.download_file(s3_bucket, json_s3_key, local_json_path)
documents = load_json(local_json_path)
# Embeddingsクライアント取得
secrets = get_secret()
embeddings = get_embeddings(secrets)
# ベクトル化とFAISSインデックス作成
vectorize_and_save(documents, local_index_dir, embeddings)
# インデックスファイルをS3へアップロード
upload_faiss_to_s3(s3_client, s3_bucket, local_index_dir, index_s3_path)
return {
"status": "success",
"message": "FAISSインデックスを作成し、S3にアップロードしました。",
"output": {
"bucket": s3_bucket,
"index_key": index_s3_path,
},
}
except Exception as e:
logger.error(f"インデックス作成処理中にエラー発生: {e}")
return {"status": "error", "message": str(e)}
5.5のまとめ
load_jsonで JSON ファイルを読み込み、vectorize_and_saveで Embedding と FAISS インデックス作成upload_faiss_to_s3でローカルインデックスを S3 へアップロードindex_to_s3で全体フローをまとめ、定期バッチ処理で最新インデックスを作成・更新
これにより、社内ドキュメントを Embedding し、RAG 検索用の FAISS インデックスを作成・更新するバッチ処理を実現できます。
6. まとめ
本記事では、Slack 上で LLM を活用する社内チャットボットしぇるぱの開発背景や技術的実装ポイント、RAG パイプラインの導入手順、Confluence ドキュメントのサニタイズや Embedding/FAISS インデックスによる検索基盤の整備、さらには翻訳・要約などの機能拡張について紹介しました。
こうした仕組みにより、Slack 内で自然な操作で生成 AI を利用でき、社員は新たなツールやコマンドを学ぶことなく高度な情報活用が可能になります。
7. 今後の展望
私たちはしぇるぱをさらに進化させるため次の改善・拡張に積極的に取り組みます。
-
Azure 環境での構築強化
Azure Functions や Azure CosmosDB などの Azure サービスとの連携を本格化し RAG パイプラインのパフォーマンスや拡張性を抜本的に向上させます。- Azure Cosmos DBベクトル検索の導入
Azure Cosmos DB for NoSQL 上でベクトル検索機能を実用化しより高度な検索を提供します。 - AI Document Intelligenceの活用
AI Document Intelligence を積極的に取り込み RAG のナレッジ範囲を拡大させより多彩な情報活用を実現します。
- Azure Cosmos DBベクトル検索の導入
-
モデルの多様化・高度化
GPT-4o のみならず GPT-o1 や Google Gemini など最新で多様なモデルへの対応を推進し常に最先端のモデルを統合します。 -
Web UIの実装
Slack 依存の表現上の制約を解消するため Web UI を構築し多彩なインタラクションや新機能を柔軟に展開します。 -
プロンプト管理の拡充
既存のプロンプトをテンプレート化し用途別に容易な再利用を実現します。またプロンプト共有機能を充実させ社内全体での生成 AI 活用を一層促進します。 -
マルチエージェント化の実現
要約や翻訳、 RAG 検索など特定機能に特化した専門エージェントを配置し、エージェントビルダー機能で自由に組み合わせることでより柔軟で高度な情報活用を可能にします。 -
RAG精度の評価・改善
テストセットを構築し回答の自動評価を実施して精度を定量的に把握し継続的な品質向上につなげます。 -
ユーザーフィードバックを起点とした改善
利用実態やフィードバックを反映し対話フローの最適化やプロンプトチューニング外部サービス連携強化など実運用を通じて常にしぇるぱの利便性と有用性を高めていきます。
私たちはこれらの取り組みによってしぇるぱを持続的に進化させ、より多様なニーズに応えられる力強い社内支援ツールへ成長させます。
関連記事 | Related Posts



We are hiring!
生成AIエンジニア/AIファーストG/東京・名古屋・大阪・福岡
AIファーストGについて生成AIの活用を通じて、KINTO及びKINTOテクノロジーズへ事業貢献することをミッションに2024年1月に新設されたプロジェクトチームです。生成AI技術は生まれて日が浅く、その技術を業務活用する仕事には定説がありません。
【クラウドエンジニア】Cloud Infrastructure G/東京・大阪・福岡
KINTO Tech BlogWantedlyストーリーCloud InfrastructureグループについてAWSを主としたクラウドインフラの設計、構築、運用を主に担当しています。
イベント情報
