Global KINTOにおけるロードバランシング
はじめに
ホアンです。バックエンドエンジニアとして、Global KINTO IDプラットフォーム(GKIDP)チームに所属し、ヨーロッパと南米を担当しています。チームはKINTOテクノロジーズ(KTC)のグローバルグループに属しています。私たちは世界中のユーザーを認証するため、グローバルな課題に取り組んでいます。GKIDPにとって、速くて信頼性が高く、かつ可用性の高いID管理、認証、認可システム(Identity and Access Management (IAM) システム) は必要不可欠です。この記事では、どんな種類のクロスボーダーシステム上でも実行できるロードバランシング/トラフィックルーティングについて、私の考えをシェアします。
HTTP (UDP, DNSも)はステートレス・プロトコルです。つまり、クライアントからサーバーへの各リクエストにおいて、以前のリクエスト情報を一切利用できません。では、なぜステートレスでなければいけないのでしょうか?目的は何なのでしょうか?
これには深い理由があります。ステートレス・プロトコルであれば、どんなリクエストが来ても各リクエストの状態を気にすることなく、任意のウェブサーバーにルーティングすることができます。その結果、スケールアーキテクチャに合わせたロードバランシングが可能になるのです。これにより、ウェブサーバーをグローバルにヨコテンできるようになり、システムレジリエンスの強化とパフォーマンスの向上に繋がります。
この記事では、2種類の主要なロードバランシングについて紹介します。DNSルーティングとハードウェアロードバランサー (別名ロードバランサー)です。これら2つの方法は異なったものですが、組み合わせることで、KINTOの車両サブスクリプションサービスのようなグローバルシステムの強化に利用することができます。
DNSルーティング
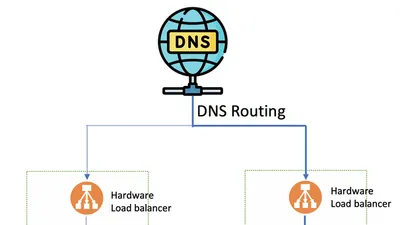
ユーザーがブラウザにURLを入力すると、ブラウザはDNSサーバーにDNSクエリを送信して、Webサイトのホスト名に対応するIPアドレスを取得します。ブラウザは、Webサイトのドメインではなく、そのIPアドレスを使用してサーバーにアクセスします。以下がシンプルなフローです。
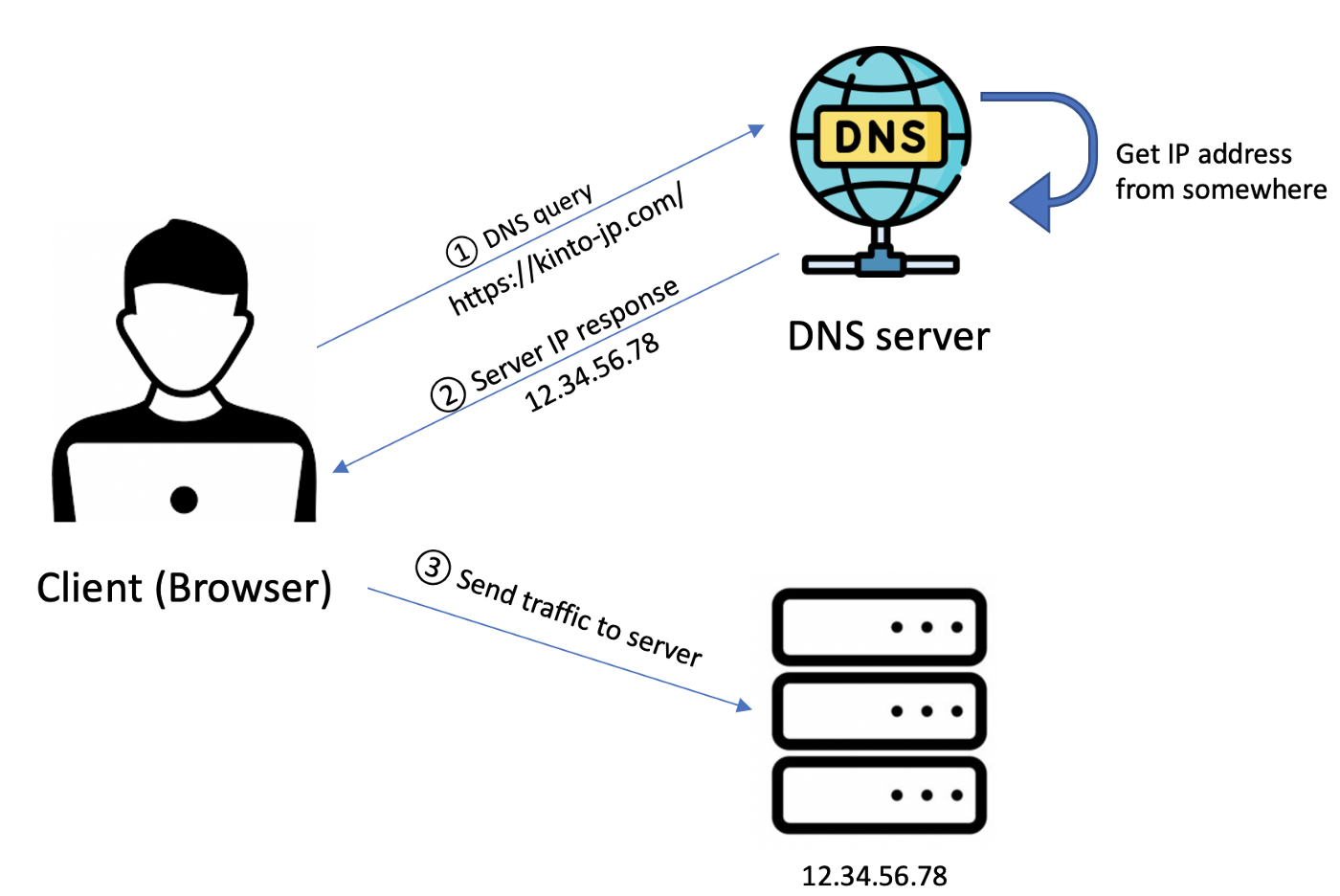 図2.DNSルーティング
図2.DNSルーティング
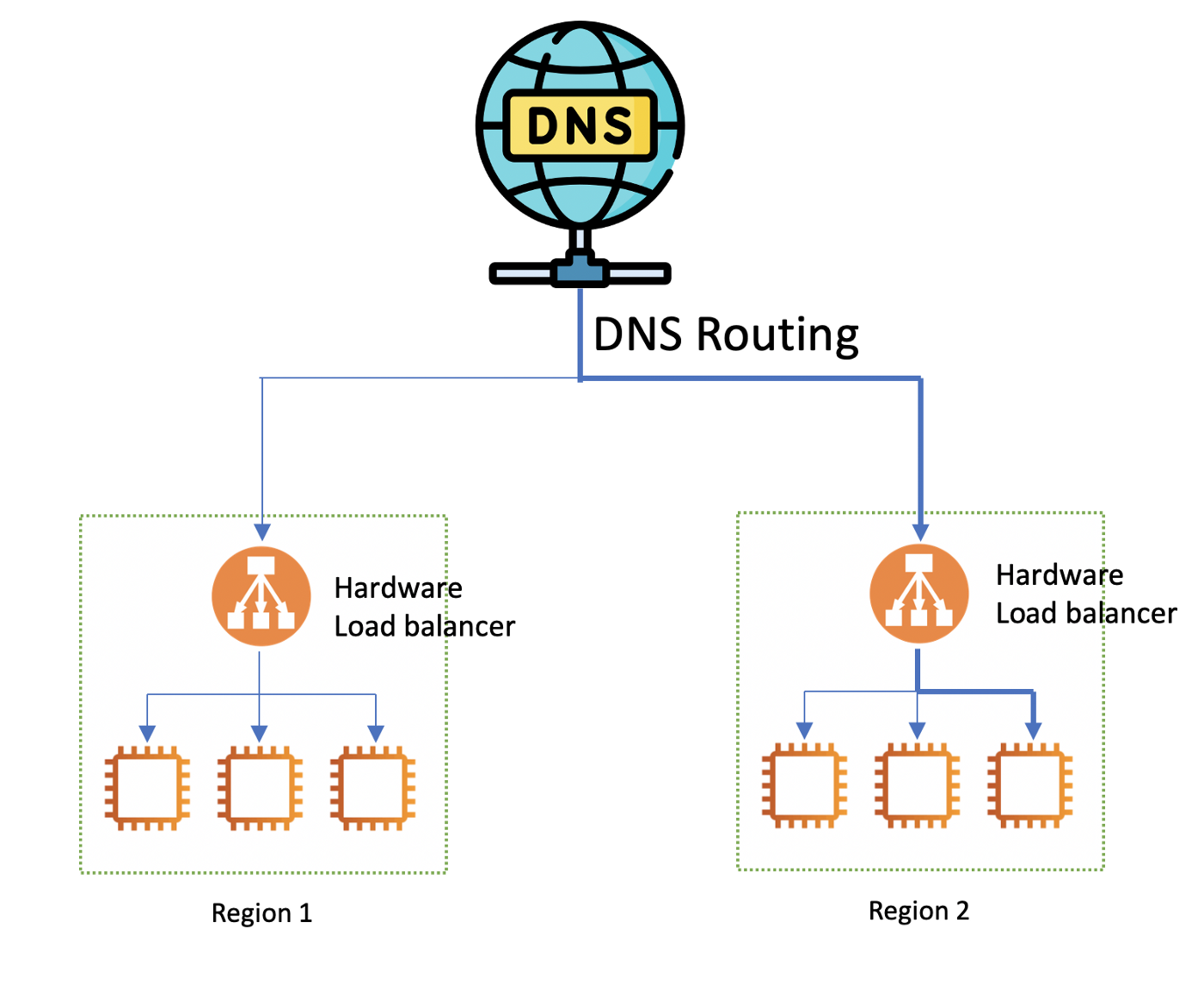
システムのサーバーが複数の地域に分散しているこのようなケースでは、DNSサーバーは、クライアントを最も適切なサーバーにルーティングし、パフォーマンスと可用性を改善します。DNSがリクエストの転送先を決定する方法を DNSルーティングと呼びます。
DNSルーティングは、ユーザーのリクエストにタッチしないため、簡単な構成でありながらスケーラビリティの高い方法です。多くの場合、データセンターや地域間でユーザーをルーティングするために使用されます。一般的なDNSルーティング方法には、単純なラウンドロビン方式や、位置情報ベース、レイテンシーベース、ヘルスベースのようなダイナミック方式があります。
DNSルーティングには、古いDNSキャッシュの問題といった欠点もあります。DNSは、サーバーがダウンしている場合でも、TTL(生存期間)経過前であれば、あるドメインに対して常に同じIPアドレスを返します。
混乱するかもしれないのでここで説明しておきます。DNSはトラフィックをルーティングしません。DNSクエリに対して、IPアドレスを返すだけです。このIPアドレスでユーザーがトラフィックを送るべき場所が分かります。図2における、ステップ3以降を説明します。サーバーのIPアドレスを取得後、クライアントは実際にトラフィック(HTTPリクエスト等)をターゲットサーバーに送信します。そうするとハードウェアロードバランサーがその背後にある複数のバックエンドサーバーにトラフィックを分散してくれます。ハードウェアロードバランサーについては次のパートで詳しく説明します。
ハードウェアロードバランサー
ドメインに対応する変換後のIPアドレスを受信した後、クライアントはトラフィックをターゲットサーバーに送信します。ここで、複数あるバックエンドサーバーの前に設置されたハードウェアロードバランサーが起動し、これらのウェブサーバーにトラフィックを分散させます。実は、ハードウェアロードバランサーはリバースプロキシ、つまりシステムのコーディネーターとしての役割を果たす物理的なデバイスにすぎません。
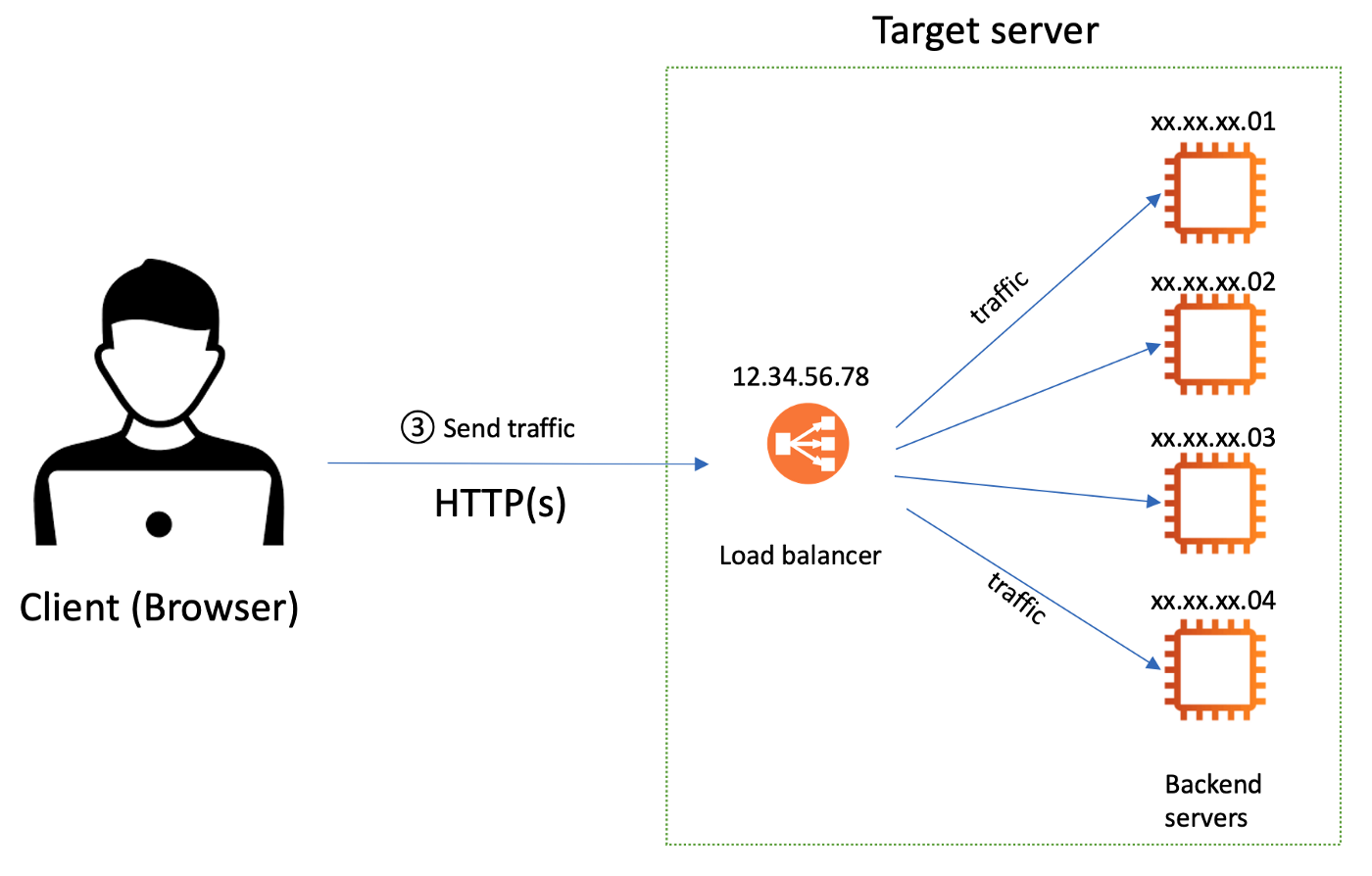
図3.リバースプロキシとしてのロードバランサー
ハードウェアロードバランシングには、レイヤー4ロードバランシングとレイヤー7ロードバランシングの2種類があり、それぞれOSIモデルで言うところのトランスポートレイヤーとアプリケーションレイヤーで動作します。OSIモデルを簡単に説明すると、リクエストはマトリョーシカのように7つのレイヤーに集約されます。より深いレイヤー (レイヤー1からレイヤー7まで)のデータであるほど、より多くの情報を得ることができます。つまり、レイヤー7ロードバランサーは、レイヤー4ロードバランサーと比較して、受信リクエストに関し、より多くの情報を持っているということです。
OSIモデル各レイヤーのデータは以下のようになっています。
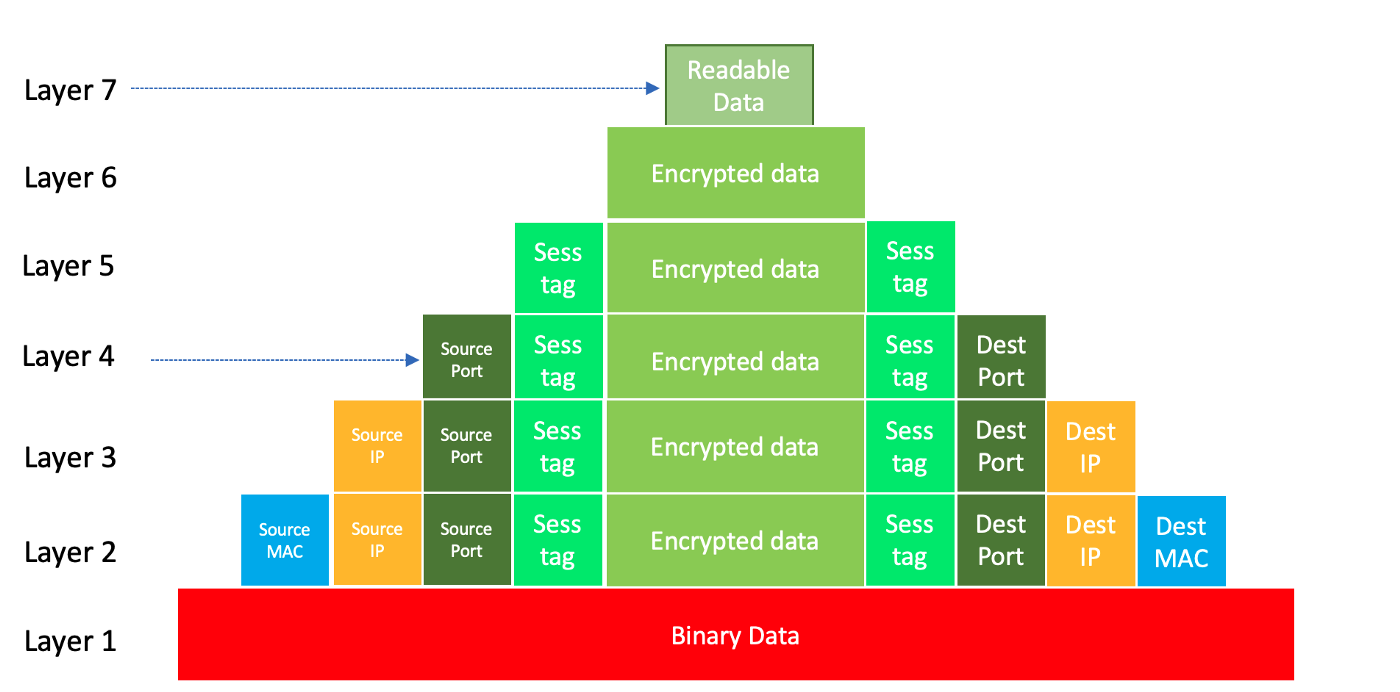 図4.OSIモデル各レイヤーのデータ
図4.OSIモデル各レイヤーのデータ
レイヤー4とレイヤー7のロードバランサーは、受信リクエストへの干渉の程度が異なります。
レイヤー4ロードバランサー
レイヤー4ロードバランサーは受信リクエストに関する情報をほとんど認識せず、クライアントのIPアドレスとポートのみを認識します。データは暗号化されているので、ロードバランサーはリクエストデータの内容について何も理解できません。そのため、レイヤー4ロードバランシングは、レイヤー7ロードバランシングほどスマートではありません。
メリット:
- シンプルなロードバランシング
- データの解読/ルックアップが不要 => 迅速、効率的、安全
デメリット:
- ロードバランシングの方法が少ない (スマートなロードバランシングができない)
- キャッシュなし(データにアクセスできないので)。
レイヤー7ロードバランシング
レイヤー7ロードバランサーは受信リクエストに関する読み取り可能なデータ (HTTPリクエストヘッダー、URL、Cookie等) に実際にアクセスできます。レイヤー7ロードバランサーは、レイヤー4ロードバランサーよりもはるかにスマートにトラフィックを分散できます。たとえば、非常に便利な戦略としてパスベースのルーティングがあります。
メリット:
- スマートなロードバランシング
- キャッシュあり
デメリット:
- 途中でデータを解読する(TLSターミネーション)=> ロードバランサーはデータを確認することになるので、速度が落ち、安全性が低下。
ルーティング/ロードバランシング方法のリスト
ルーティング/ロードバランシング方法は目的に応じて複数あります。
- ラウンドロビンアルゴリズム:実装する最も簡単な方法:サーバーアドレスが、ランダムまたは順番に返されます。
- 加重ベースアルゴリズム:各サーバーに送信されるリクエストの割合を制御します。たとえば、少人数のユーザーを対象にカナリアリリースを導入する場合、ユーザーからのフィードバックを得るためにカナリアリリース用に小規模なサーバーを1台設置し、ユーザーの内5%だけをそのサーバーにルーティングします。そして、残りの95%のユーザーには、今までと同じアプリケーションのバージョンを使用してもらいます。
- レイテンシールーティングポリシー (通常はDNSルーティング):クライアントに近く、レイテンシーが最も低いサーバーにルーティングします。低レイテンシーを優先する場合には、このポリシーが適しています。
- 最小コネクション数 (通常はロードバランサー):トラフィックが最も少ないサーバーにトラフィックが送られます。このアルゴリズムは、大きなリクエストが特定のサーバーに集中するのを防ぐことで、ピーク時のパフォーマンス向上に役立ちます。
- ヘルスチェック (ハートビート): フェイルオーバー。ライブセッションを行い、各サーバーの状態を監視します。ロードバランサーは、登録されている各サーバーのハートビートをチェックし、あるサーバーの状態が良くない場合はリクエストのルーティングを停止し、別の正常なサーバーに転送します。
- IPハッシュ(通常はロードバランサー):最適なパフォーマンス (キャッシュ等) が得られるように、クライアントのIPアドレスを固定サーバーに割り当てる
- 位置情報ルーティング (通常はDNSルーティング):大陸、国といったユーザーの各場所に基づいて、適切なサーバーへ案内します。
- マルチバリュー (DNSルーティングのみ):1つではなく複数のIPアドレスを返します。
- パスベースのルーティング (レイヤー7ロードバランサーのみ): リクエストのパスに応じて、処理を担当するサーバーを決定します。例:/processingの場合、リクエストは処理サーバーへ、/imageの場合、イメージサーバーへ転送されます。
最後に
ハードウェアロードバランサーとDNSルーティングは混同されがちです。これらは互いに代替手段というわけではなく、通常は組み合わせて使われています。重要なのは、データセンター間や地域間などの広い地域にまたがる場合にはDNSルーティングが使用されているということです。ハードウェアロードバランサーよりもはるかに安価で高速であるためです。その後の段階で使用されるのがハードウェアロードバランサーで、多くの場合データセンターや地域内においてトラフィックを分散させます。DNSルーティングはDNSクエリを、ハードウェアロードバランサーはトラフィックをそれぞれ処理します。
これら2つの定義の理解は、高いパフォーマンスと可用性を持ったグローバルシステムの構築に不可欠なものです。
参考
関連記事 | Related Posts



We are hiring!
Cloud Engineer(トヨタグループ内製化支援)/Cloud Infrastructure G/東京・名古屋・大阪・福岡
トヨタグループのクラウド活用を、最前線で支える。1社にとどまらないスケールで、移行・生成AI・内製化まで幅広く挑戦できるポジションです。
【クラウドセキュリティエンジニア】クラウドセキュリティG/東京・名古屋・大阪・福岡
ミッションクラウドセキュリティの専門組織として、KINTO テクノロジーズのマルチクラウド環境のセキュリティガバナンスに責任を持ちます。 セキュリティリスクを発生させない セキュリティリスクを常に監視・分析する セキュリティリスクが発生したときに速やかに対応する 業務内容ミッションを達成するために様々な業務を実施します。

