Structured Concurrency with Kotlin coroutines

Introduction
Hello! This is Hasegawa (@gotlinan), an Android engineer at KINTO Technologies! I usually work on the development of an app called myroute. Check out the other articles written by myroute members!
In this article, I will explain Structured Concurrency using Kotlin coroutines. If you already know about Structured Concurrency, but do not know how to use coroutines, please refer to Convenience Functions for Concurrency.
Structured Concurrency?
So what is Structured Concurrency? In Japanese, I think it is like "structured parallel processing." Imagine having two or more processes running in parallel, each correctly managing cancellations and errors that may occur. Through this article, let’s learn more about Structured Concurrency!
I'll be introducing you two common examples here.
1. Wish to Coordinate Errors
The first example is to execute Task 1 and Task 2, and then execute Task 3 based on the results. In the illustration, it should look like this:
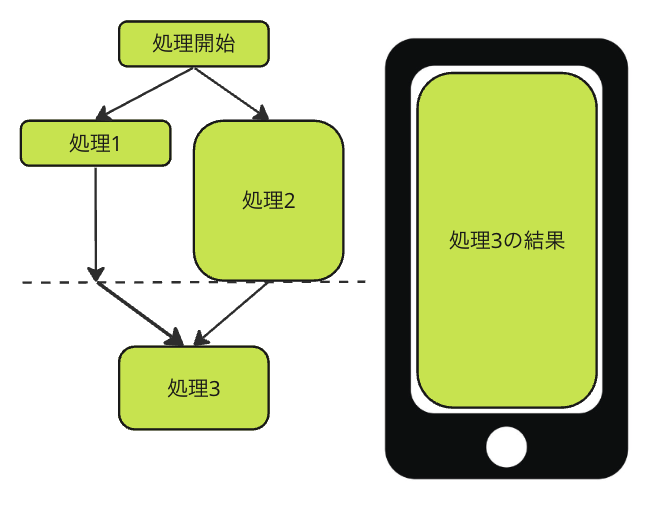
After executing Task 1 and Task 2, execute Task 3 according to the results.
In this case, if an error occurs in Task 1, it is pointless to continue with Task 2. Therefore, if an error occurs in Task 1, Task 2 must be canceled. Similarly, if an error occurs in Task 2, Task 1 should be canceled, eliminating the necessity to proceed to Task 3.
2. Not Wanting to Coordinate Errors
The second common example is when there are multiple areas on the screen, each displayed independently. If we create a diagram, it would look like this:
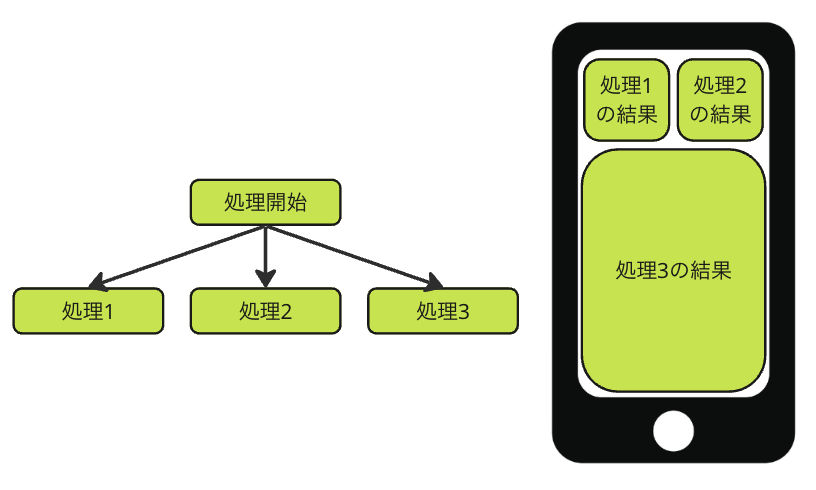
Multiple areas on the screen, each displayed independently.
In this case, even if an error occurs in Task 1, you may want to display the result of Task 2 or Task 3. Therefore, even if an error occurs in Task 1, Task 2 or 3 must be continued without canceling.
I hope these examples were clear to you. With coroutines, the above examples can be easily implemented based on the idea of Structured Concurrency! However, for a deeper understanding is necessary to grasp the basics of coroutines. From the next section we will actually learn about coroutines! If you know the basics, skip to Convenience Functions for Concurrency.
Coroutines Basics
Let's talk about the basics of coroutines before explaining it in detail.
In coroutines, asynchronous processing can be initiated by calling the launch function from CoroutineScope. Specifically, it looks like this:
CoroutineScope.launch {
// Code to be executed
}
So, why do we need to use CoroutineScope? We need to because in asynchronous processing, "which thread to execute" and "how to behave in case of cancellation or error" are very important. CoroutineScope has a CoroutineContext. A coroutine run on a given CoroutineScope is controlled based on CoroutineContext.
Specifically, CoroutineContext consists of the following elements:
Dispatcher: Which thread to run onJob: Execution of cancellations, propagation of cancellations and errorsCoroutineExceptionHandler: Error handling
When creating a CoroutineScope, each element can be passed with the + operator. And a CoroutineContext is inherited between parent-child coroutines. For example, suppose you have the following code:
val handler = CoroutineExceptionHandler { _, _ -> }
val scope = CoroutineScope(Dispatchers.Default + Job() + handler)
scope.launch { // Parent
launch { // Child 1
launch {} // Child 1-1
launch {}// Child1-2
}
launch {} // Child 2
}
In this case, CoroutineContext is inherited as follows.
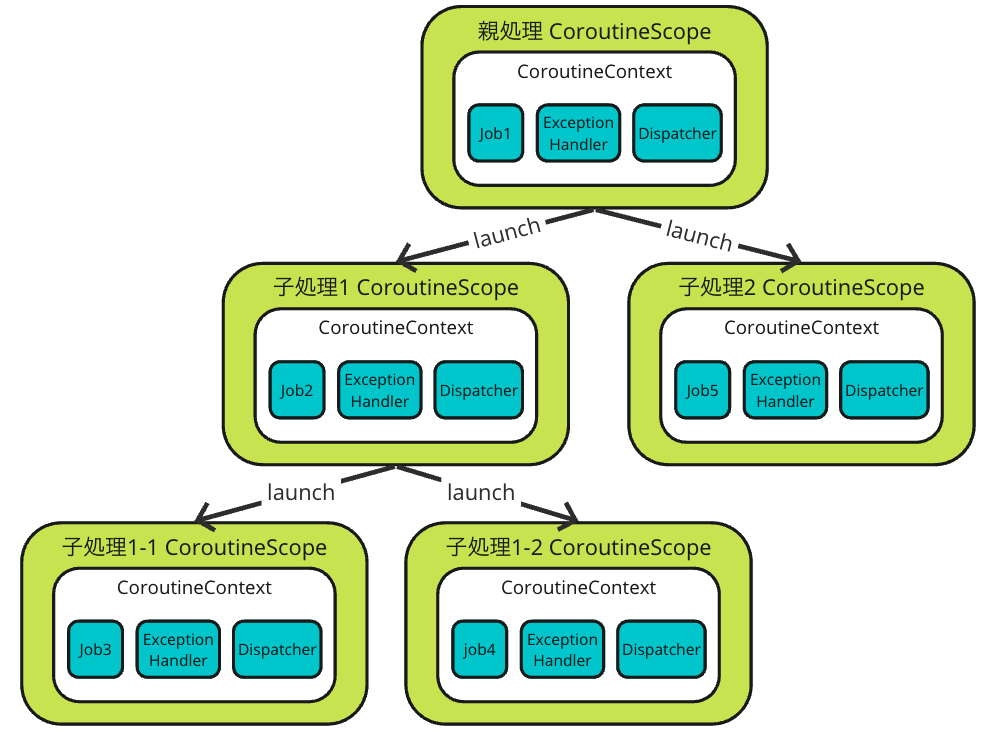
Inheritance of CoroutineContext
Well, if you look at the image, it looks like Job has been newly created instead of inheriting it, doesn't it? This is not a mistake. Although I stated that the "CoroutineContext is inherited between parent-child coroutines," strictly speaking, it is more correct to say that a"CoroutineContext is inherited between parent-child coroutines except for Job. Then, what about Job?
Let's learn more about it in the next section!
What is a Job?
What is a Job in Kotlin coroutines? In short, it would be something that "controls the execution of the coroutine" Job has a cancel method, which allows developers to cancel started coroutines at any time.
val job = scope.launch {
println("start")
delay(10000) // Long Process
println("end")
}
job.cancel()
// start (printed out)
// end (not printed out)
The Job associated with viewModelScope and lifecycleScope, which Android engineers often use, are canceled at the end of their respective lifecycles. This allows the developer to correctly cancel any ongoing processes without requiring users to be mindful of switching screens.
Such is the high importance of a Job, which also plays the role to propagate cancellations and errors between parent and child coroutines. In the previous section, I talked about how Job is not inherited, but using that example, Job can have a hierarchical relationship as shown in the image below.
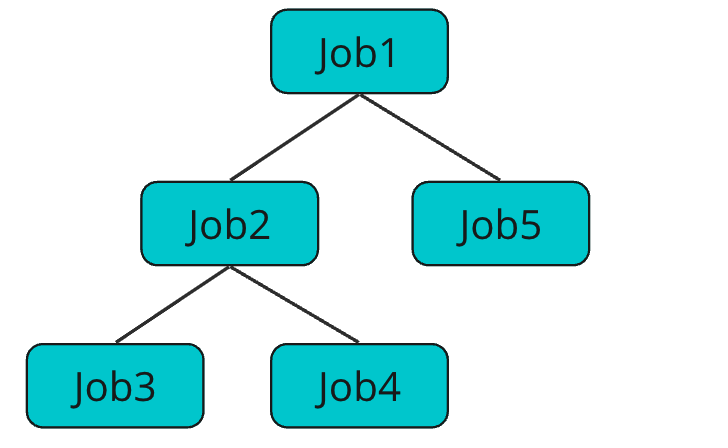
Hierarchical Relationship of Job
A partial definition of Job looks like this:
public interface Job : CoroutineContext.Element {
public val parent: Job?
public val children: Sequence<Job>
}
It allows parent-child relationships to be maintained, and it seems that parent and child Job can be managed when cancellations or errors occur. From the next chapter, let's see how the coroutine propagates cancellations and errors through the hierarchical relationships of Jobs!
Propagation of cancellations
If the coroutine is canceled, the behavior is as follows.
- Cancels all of its child coroutines
- Does not affect its own parent coroutine
*It is also possible to execute a coroutine that is not affected by the cancellation of the parent coroutine by changing CoroutineContext to NonCancellable. I will not talk about this part in this article since it deviates from the theme of Structured Concurrency.
cancellation affects downward in the Job hierarchy. In the example below, if Job2 is canceled, the coroutine running on Job2, Job3, and Job4 will be canceled.
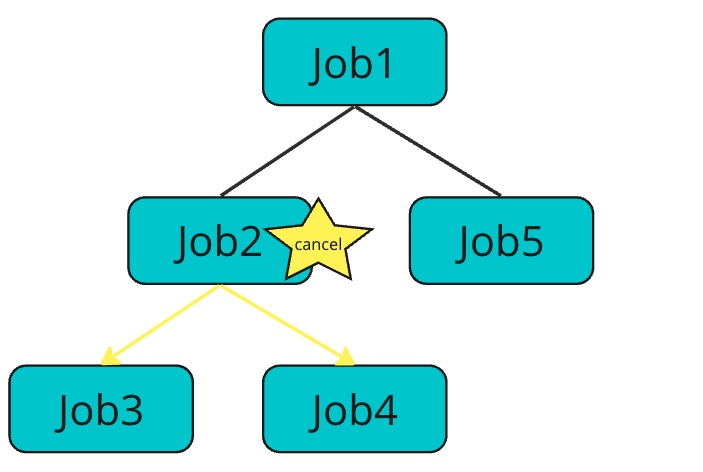
Propagation of cancellations
Propagation of Errors
Actually, Job can be broadly divided into Job and SupervisorJob. Depending on each, the behavior when an error occurs will vary. I have summarized the behavior in the two tables below: one for when an error occurs in its own Job, and the other for when an error occurs in a child Job.
When an error occurs in Job
| Child Job | its own Job | to Parent Job | |
|---|---|---|---|
| Job | Cancel all | Complete with errors | Propagate error |
| SupervisorJob | Cancel all | Complete with errors | No propagate error |
When an error propagates from Child Job
| other child jobs | its own Job | to Parent Job | |
|---|---|---|---|
| Job | Cancel all | Complete with errors | Propagate error |
| SupervisorJob | No action | No action | No propagate error |
The images representing the behavior when an error occurs with reference to the two tables are as follows for Job and SupervisorJob respectively.
For Job
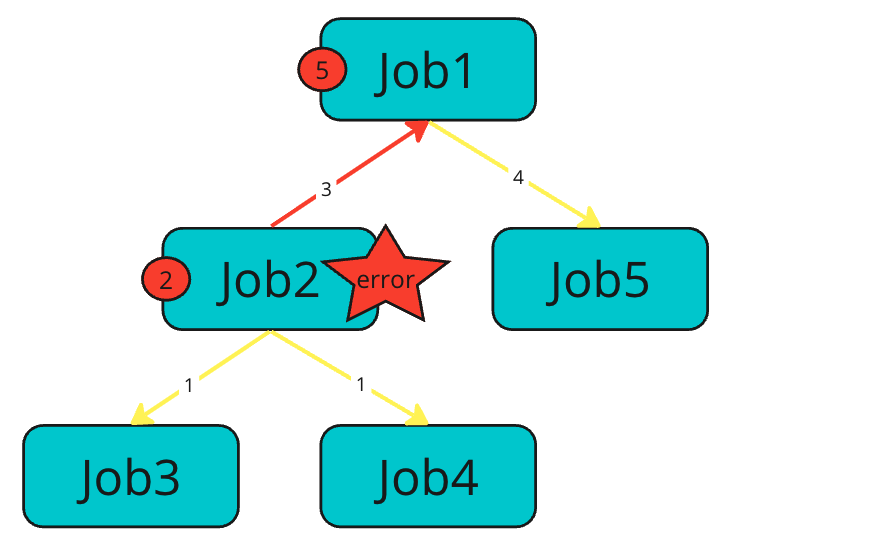
If an error occurs in Job2 of a normal Job
- The Child Job,
Job3andJob4will be canceled - Its own Job,
Job2completes with errors - Propagates the error to the Parent Job
Job1 - Cancels
Job1's other Child Job,Job5. Job1completes with errors
For SupervisorJob
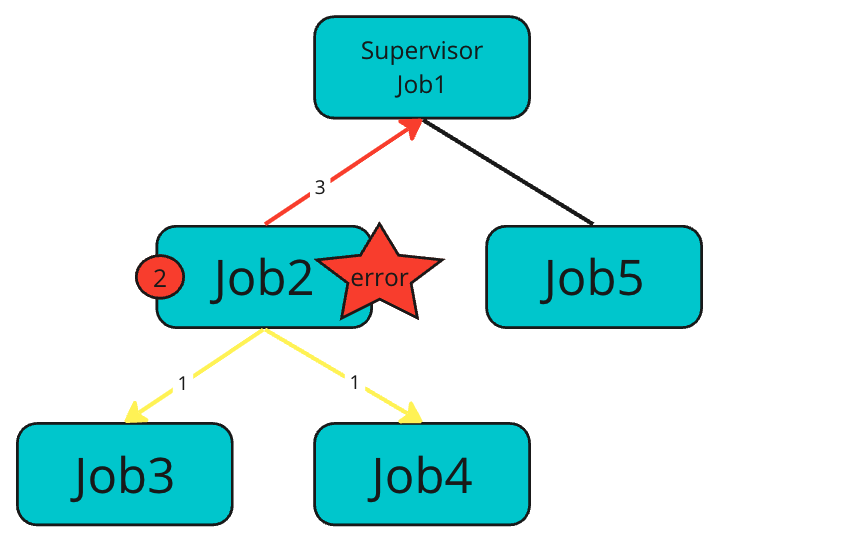
If an error occurs in Job2 of a normal Job
- The Child Job,
Job3andJob4will be canceled - Its own Job,
Job2completes with errors - Propagates the error to the Parent SupervisorJob,
Job1
As a reminder, the SupervisorJob1 with the error propagated does not cancel the other Child Job (Job5), and normally completed itself.
Moreover, you can use invokeOnCompletion to check whether Job was completed normally, by error, or by cancellation.
val job = scope.launch {} // Some work
job.invokeOnCompletion { cause ->
when (cause) {
is CancellationException -> {} // cancellation
is Throwable -> {} // other exceptions
null -> {} // normal completions
}
}
Exceptions Not Caught
By the way, how about exceptions not caught by coroutine? For example,
- what happens if an error occurs or propagates in
Jobat TopLevel? - what happens if an error occurs or propagates in
SupervisorJob?
And so on.
The answers are:
CoroutineExceptionHandleris called if specified.- If
CoroutineExceptionHandleris not specified, the thread's defaultUncaughtExceptionHandleris called.
As mentioned earlier in Coroutines Basics, CoroutineExceptionHandler is also a companion to CoroutineContext. It can be passed as follows:
val handler = CoroutineExceptionHandler { coroutineContext, throwable ->
// Handle Exception
}
val scope = CoroutineScope(Dispatchers.Default + handler)
If CoroutineExceptionHandler is not specified, the thread's default UncaughtExceptionHandler is called. If the developer wishes to specify, write as follows:
Thread.setDefaultUncaughtExceptionHandler { thread, exception ->
// Handle Uncaught Exception
}
I had misunderstood until writing this article that if I used SupervisorJob, the application would not complete because the error would not propagate. However, SupervisorJob only does not propagate errors on the coroutine's Job hierarchy. Therefore, if either of the above two types of handlers are not defined accordingly, it may not work as intended. For example, in an Android app, the default thread UncaughtExceptionHandler causes the app to complete (crash) unless specified by the developer. On the other hand, executing normal Kotlin code will just display an error log.
Also, slightly off topic, you may be wondering whether try-catch or CoroutineExceptionHandler should be used. When an error is caught by CoroutineExceptionHandler, the coroutine Job has already completed and cannot be returned. Basically, you can use try-catch for recoverable error. When implementing based on the idea of Structured Concurrency, or when you want to log errors, setting up a CoroutineExceptionHandler seems like a good approach.
Convenience Functions For Concurrency
The explanation was a little long, but in coroutines, functions such as coroutineScope() and supervisorScope() are used to achieve Structured Concurrency.
coroutineScope()
1. Remember Wish to Coordinate Errors? You can use coroutineScope() in such an example. coroutineScope() waits until all started child coroutines are completed. If an error occurs in a child coroutine, the other child coroutines will be canceled.
The code would be as follows:
- Child coroutine 1 and Child coroutine 2 are executed concurrently
- Child coroutine 3 is executed after Child coroutine 1 and Child coroutine 2 are finished
- Regardless of which Child coroutine encounters an error, the others will be canceled.
scope.launch {
coroutineScope {
launch {
// Child 1
}
launch {
// Child 2
}
}
// Child 3
}
supervisorScope()
2. Remember Wish Not to Coordinate Errors? You can use supervisorScope() in such an example. supervisorScope() also waits until all started child coroutines are completed. Also, if an error occurs in a child coroutine, the other child coroutines will not be canceled.
The code would be as follows:
- Child coroutine 1, Child coroutine 2 and Child coroutine 3 are executed concurrently
- Errors in any child coroutine do not affect other child coroutine
scope.launch {
supervisorScope {
launch {
// Child 1
}
launch {
// Child 2
}
launch {
// Child 3
}
}
}
Summary
How was it? I hope you now have a better understanding of Structured Concurrency. While there may have been several basics to cover, understanding these basics will help you when navigating more complex implementations.
And once you can write structured concurrency well, enhancing the local performance of the service will become relatively easy. Why not consider Structured Concurrency if there are any bottlenecks needlessly running in series?
That's it for now!
関連記事 | Related Posts


We are hiring!
【クラウドセキュリティエンジニア】クラウドセキュリティG/東京・名古屋・大阪・福岡
ミッションクラウドセキュリティの専門組織として、KINTO テクノロジーズのマルチクラウド環境のセキュリティガバナンスに責任を持ちます。 セキュリティリスクを発生させない セキュリティリスクを常に監視・分析する セキュリティリスクが発生したときに速やかに対応する 業務内容ミッションを達成するために様々な業務を実施します。
【オープンポジション】「気になる!」方はまずはこちらからご応募ください。/東京・名古屋・大阪・福岡
業務内容国内外のKINTOサービスや、トヨタグループの金融、モビリティサービスの内製開発組織である同社にて、ご経験・ご志向性に応じて配属を決定し、ご活躍いただきます。


