Structured Concurrency with Kotlin coroutines

はじめに
こんにちは!KTCでAndroidエンジニアをしている長谷川(@gotlinan)です!
普段はmyrouteというアプリの開発をしています。myrouteのメンバーが書いた他の記事も是非読んで見てください!
本記事ではKotlin coroutinesを使用したStructured Concurrencyを解説します。
Structured Concurrencyは知っているけど、coroutineを使う方法はどんな感じ?って方は、並行処理のための便利関数をご確認ください。
Structured Concurrency?
Structured Concurrencyって何でしょう?日本語にすると「構造化された並行処理」みたいな感じだと思います。イメージとしては、二つ以上の処理を並行しながら、それぞれでキャンセルやエラーが発生した場合も正しく管理されていること、だと思います。本記事を通じて、Structured Concurrencyについて詳しくなりましょう!
今回は二つのよくある例をもとに紹介してみます。
1. エラーを協調したい
まずよくある例として処理1と処理2を実行後、その結果に応じて処理3を実行したい場合です。
図にすると、以下のようになります。
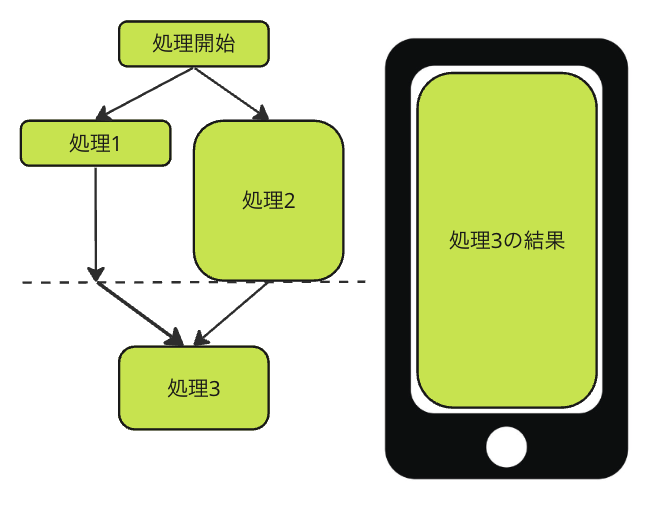
処理1と処理2を実行後、その結果に応じて処理3を実行する
この場合、処理1でエラーが発生した場合、処理2を継続しても無駄ですね。
したがって処理1でエラーが発生した場合、処理2をキャンセルする必要があります。
同様に処理2でエラーが発生した場合も、処理1をキャンセルして、処理3に進む必要はありません。
2. エラーを協調したくない
次によくある例として、画面内に複数のエリアがあり、それぞれ独立して表示する場合です。
図にすると、以下のようになります。
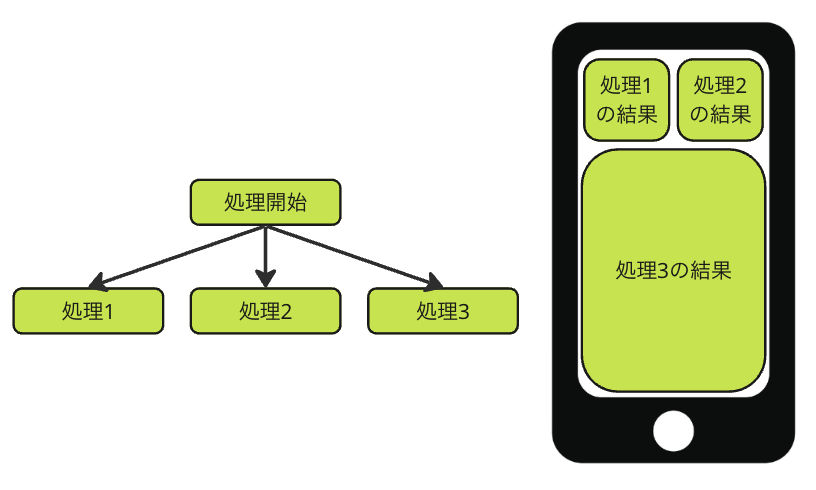
画面内に複数のエリアがあり、それぞれ独立して表示する
この場合、仮に処理1でエラーが発生しても、処理2や処理3の結果は表示したい場合があります。
したがって処理1でエラーが発生した場合でも処理2や処理3はキャンセルせずに継続する必要があります。
二つの例は理解できましたか?coroutineでは上記のような例を、Structured Concurrencyの考えをもとに簡単に実装することができます!
ただし理解するためにはcoroutineの基礎を理解する必要があります。次のセクションからは実際にcoroutineを学びましょう!
基礎は知っているよっていう方は、並行処理のための便利関数までスキップしてください。
coroutineの基礎
詳しい解説の前にcoroutineの基礎的な話をしましょう。
coroutineではCoroutineScopeからlaunch関数を呼ぶことで非同期の処理を開始できます。具体的には以下のような形です。
CoroutineScope.launch {
// 実行したいコード
}
ところでなぜCoroutineScopeを使用する必要があるのでしょうか?それは非同期処理では、「どのスレッドで実行するか」、「キャンセルやエラーが発生した時にどう振る舞うか」がとても重要だからです。CoroutineScopeはCoroutineContextを持ちます。あるCoroutineScopeで実行されるcoroutineはCoroutineContextをもとに制御されます。
具体的にはCoroutineContextは以下の要素などから構成されます。
Dispatcher: どのスレッドで動くかJob: キャンセルの実行、キャンセルやエラーの伝搬CoroutineExceptionHandler: エラーハンドリング
CoroutineScopeを作成する際は、それぞれの要素を+演算子で渡すことが可能です。
そしてCoroutineContextはcoroutineの親子間で継承されます。例えば以下のようなコードがあったとします。
val handler = CoroutineExceptionHandler { _, _ -> }
val scope = CoroutineScope(Dispatchers.Default + Job() + handler)
scope.launch { // 親処理
launch { // 子処理1
launch {} // 子処理1-1
launch {}// 子処理1-2
}
launch {} // 子処理2
}
この場合はCoroutineContextが以下のように継承されます。
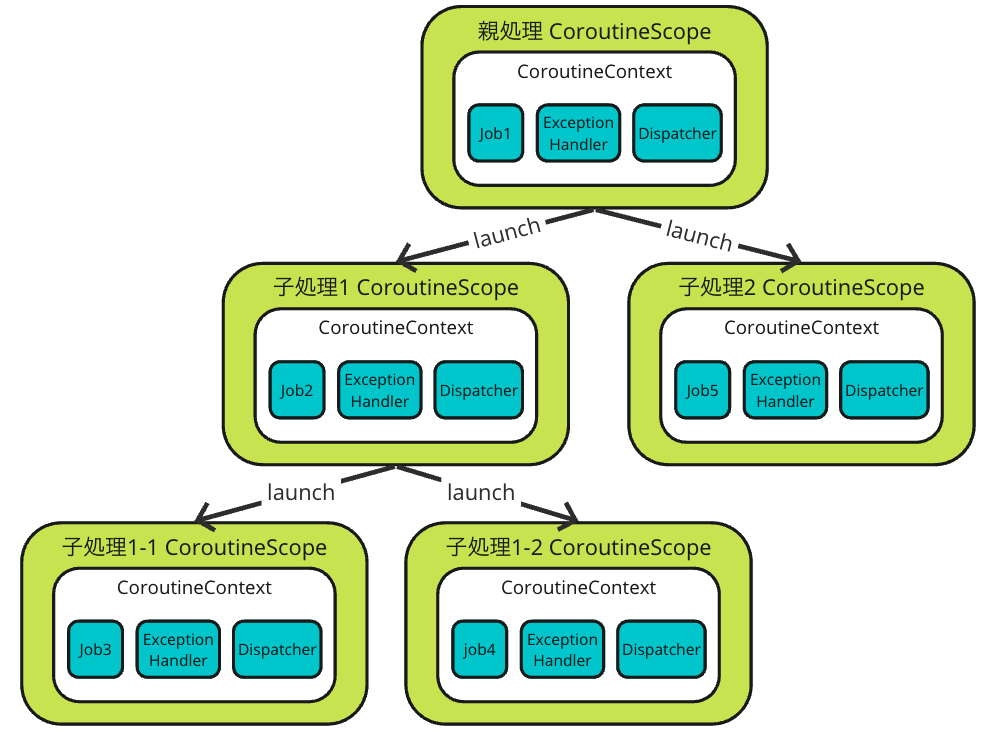
CoroutineContextの継承
おや、画像を見るとJobは継承されずに新しく作成されているようですね?
これは間違いではないです。「CoroutineContextはcoroutineの親子間で継承されます」と述べましたが、厳密には「Job以外のCoroutineContextはcoroutineの親子間で継承される」の方が正しいです。それならJobはどうなるんだ?と思いますよね。
次のセクションではJobについて理解を深めてみましょう!
Jobとは
coroutineにおけるJobとは何でしょうか?それは短くまとめるのであれば、「coroutineの実行を制御する」ものだと思います。
Jobにはcancelメソッドがあり、開発者は開始されたcoroutineをいつでもキャンセルすることが可能です。
val job = scope.launch {
println("start")
delay(10000) // Long Process
println("end")
}
job.cancel()
// start (printed out)
// end (not printed out)
Androidエンジニアがよく利用するであろうviewModelScopeやlifecycleScopeに紐づくJobはそれぞれのライフサイクルの終わりの時にキャンセルされています。これによりユーザーが画面外にでた場合に継続中の処理があっても、開発者が意識せずに正しくキャンセルされます。
そんな超重要なJobですが、coroutineの親子間でのキャンセルやエラーの伝搬の役割も持ちます。前のセクションではJobは継承されない話をしましたが、その例を使うと、以下の画像のようにJobは階層関係を持ちます。
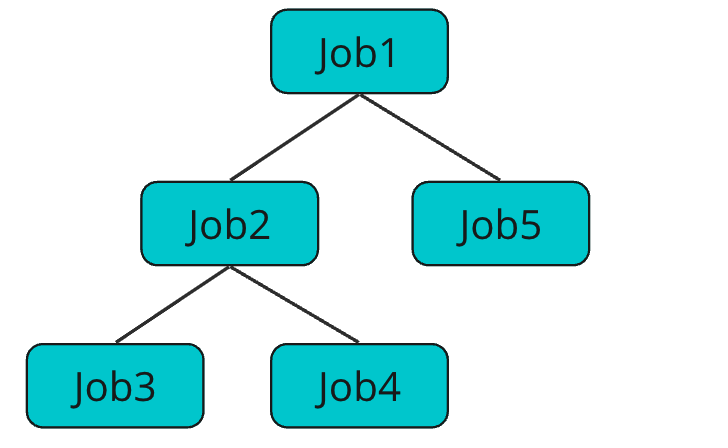
Jobの階層関係
実際にJobの定義を一部抜粋すると、以下のようになっています。
public interface Job : CoroutineContext.Element {
public val parent: Job?
public val children: Sequence<Job>
}
親子関係を保持できるになっており、キャンセルやエラーが発生したときに親や子のJobを操作できそうですね。
次の章からはJobの階層関係を通じて、どのようにcoroutineがキャンセルやエラーを伝搬しているか確認してみましょう!
cancelの伝搬
coroutineがキャンセルされた場合、以下のような挙動になります。
- 自身の子coroutineを全てキャンセルする
- 自身の親coroutineには影響しない
※ CoroutineContextをNonCancellableに変更することで親coroutineのキャンセルの影響を受けないcoroutineを実行することも可能です。Structured Concurrencyのテーマとは離れるため、今回は割愛します。
つまりキャンセルはJobの階層関係において下方向に影響します。
下記の例だと、Job2がキャンセルされた場合、Job2、Job3、Job4で動いているcoroutineがキャンセルされます。
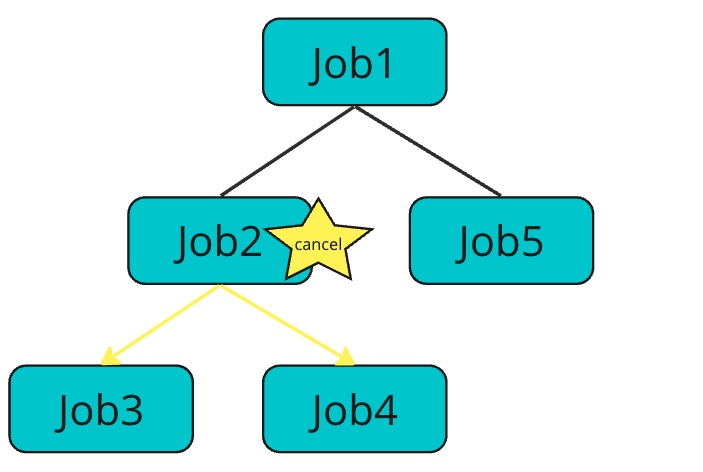
Cancelの伝搬
エラーの伝搬
実はJobには大きく分けて、JobとSupervisorJobがあります。
この種類によって、エラーが発生した場合の挙動が変わります。
自身のJobでエラーが発生したときと、子Jobでエラーが発生したときの挙動を二つの表にまとめました。
Job内でエラーが発生したとき
| 子Jobを | 自身のJobを | 親Jobに | |
|---|---|---|---|
| Job | 全てキャンセルする | エラー終了する | エラーを伝搬する |
| SupervisorJob | 全てキャンセルする | エラー終了する | エラーを伝搬しない |
エラーが子Jobから伝搬してきたとき
| 他の子Jobを | 自身のJobを | 親Jobに | |
|---|---|---|---|
| Job | 全てキャンセルする | エラー終了する | エラーを伝搬する |
| SupervisorJob | 何もしない | 何もしない | エラーを伝搬しない |
二つの表を参考にしてエラー発生時の挙動を表したイメージは、JobとSupervisorJobの場合でそれぞれ以下のようになります。
Jobの場合
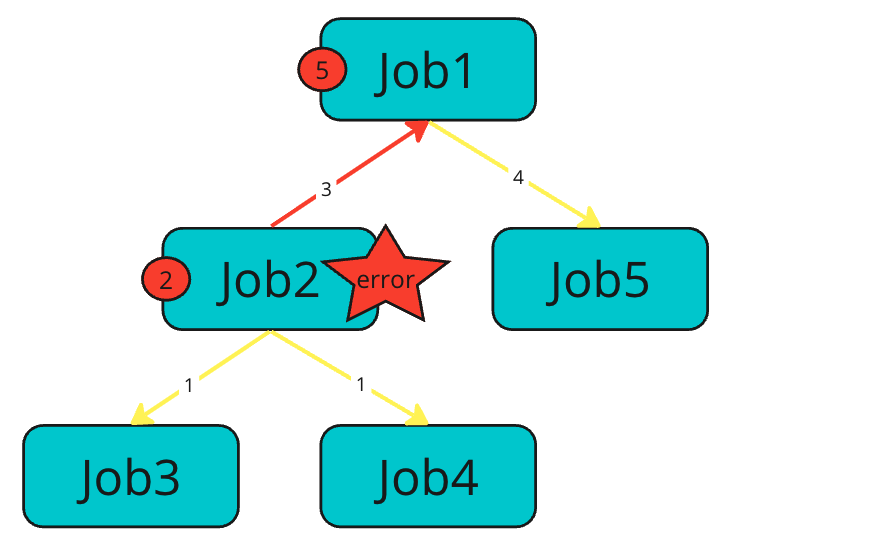
通常のJobのJob2でエラーが発生した場合
- 子Jobである
Job3、Job4はキャンセルされる - 自身のJobである
Job2はエラー終了する - エラーを親Jobである
Job1に伝搬する Job1の他の子JobであるJob5をキャンセルするJob1がエラー終了する
SupervisorJobの場合
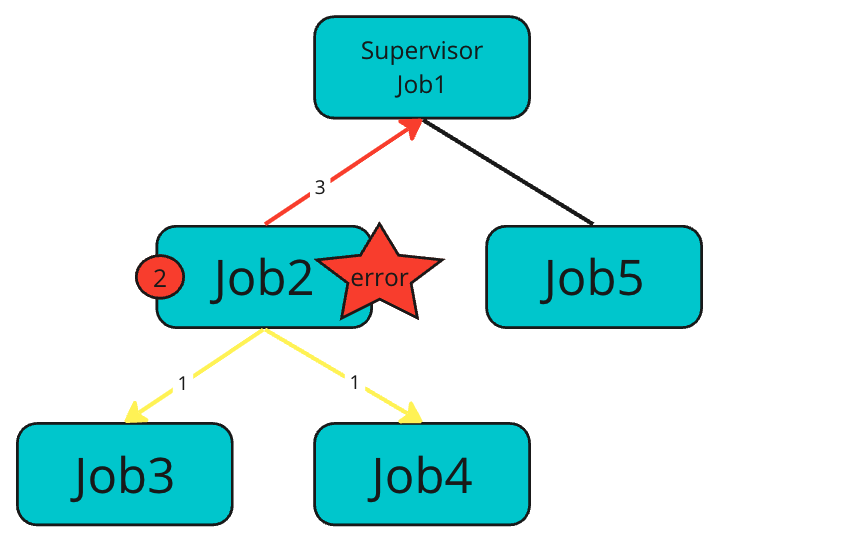
通常のJobのJob2でエラーが発生した場合
- 子Jobである
Job3、Job4はキャンセルされる - 自身のJobである
Job2はエラー終了する - エラーを親SupervisorJobである
Job1に伝搬する
意識してもらいたい点として、エラーが伝搬されたSupervisorJob1は、他の子Job(Job5)をキャンセルせず、自身も通常終了します。
ちなみにJobが、通常終了したのか、エラーにより終了したか、キャンセルにより終了したのかを確認する方法として、invokeOnCompletionを使用することができます。
val job = scope.launch {} // Some work
job.invokeOnCompletion { cause ->
when (cause) {
is CancellationException -> {} // cancellation
is Throwable -> {} // other exceptions
null -> {} // normal completions
}
}
catchされなかった例外
ところでcoroutineで捕捉されなかった例外はどうなるのでしょうか?
例えば
- TopLevelの
Jobでエラーが発生したり、伝搬してきた場合はどうなるの? SupervisorJobでエラーが発生したり、伝搬してきた場合どうなるの?
などの疑問があると思います。
答えは
CoroutineExceptionHandlerが指定されていれば、呼ばれるCoroutineExceptionHandlerが指定されていなければ、スレッドのデフォルトのUncaughtExceptionHandlerが呼ばれる
となります。
coroutineの基礎で前述のように、CoroutineExceptionHandlerもCoroutineContextの仲間です。以下のように渡すことができます。
val handler = CoroutineExceptionHandler { coroutineContext, throwable ->
// Handle Exception
}
val scope = CoroutineScope(Dispatchers.Default + handler)
もしCoroutineExceptionHandlerが指定されていない場合、スレッドのデフォルトのUncaughtExceptionHandlerが呼ばれます。
開発者が指定したい場合は以下のように記述します。
Thread.setDefaultUncaughtExceptionHandler { thread, exception ->
// Handle Uncaught Exception
}
自分が本記事執筆まで誤解していたこととして、SupervisorJobを使用すれば、エラーが伝搬しないのでアプリケーションは終了しないという認識がありました。
しかしSupervisorJobはあくまでcoroutineのJobの階層関係上でエラーを伝搬しないだけです。従って上記の二種類のHandlerのどちらかを適宜定義しておかないと、意図した通りに動かない可能性があります。
例えばAndroidアプリではスレッドのデフォルトのUncaughtExceptionHandlerは、開発者が指定しない限りアプリケーションが終了(クラッシュ)するようになっています。一方で通常のKotlinコードを実行すると、ただエラーログを表示するだけとなります。
また、少し話は逸れますが、try-catchとCoroutineExceptionHandlerのどちらを使用すればいいのか、という疑問があるかもしれません。CoroutineExceptionHandlerでエラーを捕捉したとき、coroutineのJobは既に終了しており、復帰することはできません。基本的に復帰可能なエラーはtry-catchを使用して、Structured Concurrencyの考えをもとに実装する際や、ログを出しておきたいときなどは、CoroutineExceptionHandlerを設定する方針が良さそうです。
並行処理のための便利関数
ここまでの説明が少し長くなってしまいましたが、coroutineではStructured Concurrencyを達成するために、coroutineScope()やsupervisorScope()のような関数があります。
coroutineScope()
1. エラーを協調したいを覚えていますか?このような例ではcoroutineScope()を使用することができます。coroutineScope()は起動した子coroutineが全て終了するまで待ちます。また子coroutineでエラーが発生した場合、他の子coroutineはキャンセルします。
以下のようにコードを記述すると、
- 子処理1と子処理2は並行で実行
- 子処理3は子処理1と子処理2が終わった後に実行
- どの子処理でエラーが発生しても、他の子処理はキャンセルされる
などを達成することができます。
scope.launch {
coroutineScope {
launch {
// 子処理1
}
launch {
// 子処理2
}
}
// 子処理3
}
supervisorScope()
2. エラーを協調したくないを覚えていますか?このような例ではsupervisorScope()を使用することができます。supervisorScope()も起動した子coroutineが全て終了するまで待ちます。また子coroutineでエラーが発生した場合でも、他の子coroutineはキャンセルしません。
以下のように記述すると、
- 子処理1と子処理2と子処理3は並行で実行
- どの子処理でエラーが発生しても、他の子処理に影響しない
などを達成することができます。
scope.launch {
supervisorScope {
launch {
// 子処理1
}
launch {
// 子処理2
}
launch {
// 子処理3
}
}
}
まとめ
Structured Concurrencyは理解できましたか?
説明のための基礎的な内容が多かったかもしれませんが、基礎的な内容を理解しておくと、いざ複雑な実装に取り組む際の助けとなります。
そしてStructured Concurrencyをうまく記述できるようになると、比較的簡単にサービスの局所的なパフォーマンスの改善に繋げることができます。もし無駄に直列で実行しているようなボトルネックがあれば、Structured Concurrencyを考慮してみてはどうでしょうか?
以上です〜
関連記事 | Related Posts
Structured Concurrency with Kotlin coroutines
Here's What I Learned from Udemy's Coroutines and Flow Course
UdemyでCoroutinesとFlowの講座を受けました

A to Z of Testing in Kotlin Multiplatform (KMP)

Android開発をする時に知っておかないとバグを引き起こしそうな「地域別の設定」について

Kotlin Multiplatform Hybrid Mode: Compose Multiplatform Meets SwiftUI and Jetpack Compose
We are hiring!
【クラウドエンジニア(クラウド活用の推進)】Cloud Infrastructure G/東京・名古屋・大阪・福岡
KINTO Tech BlogCloud InfrastructureグループについてAWSを主としたクラウドインフラの設計、構築、運用を主に担当しています。
プロジェクトマネージャー(PjM)/KINTO開発推進G/東京
KINTO開発推進グループについて◉KINTO開発部 :67名 KINTO開発推進G:8名 KINTOプロダクトマネジメントG:5名 KINTOバックエンド開発G:17名 KINTOフロントエンド開発G:21名 業務管理システム開発G :9名 KINTO中古車開発G:10名 ...




