生成 AI アプリケーション開発に評価の仕組みを導入して精度向上を実現した話:DB 設計レビュー自動化の取り組み

こんにちは。 DBRE チーム所属の @p2sk と @hoshino です。
DBRE(Database Reliability Engineering)チームでは、横断組織としてデータベース(DB)に関する課題解決やプラットフォーム開発に取り組んでいます。
本記事では、AWS の生成 AI サービス Amazon Bedrock を活用し、Serverless アーキテクチャで構築した DB テーブル設計の自動レビュー機能を紹介します。この機能は GitHub Actions と連携し、プルリクエスト(PR)がオープンされると AI が自動でレビューし、修正案をコメントとして提案します。また、生成 AI アプリケーションの評価をどのように設計・実装したかも解説します。LLMOps のライフサイクルにおける 3 つのフェーズ(モデル選定、開発、運用)ごとに採用した評価手法を説明し、特に運用フェーズでは「LLM-as-a-Judge」を活用した生成 AI による自動評価について紹介します。
本記事の目的
本記事では生成 AI アプリケーションの評価を、抽象的な概念から具体的な実装例までわかりやすく情報提供することを目指します。本記事を読んでいただくことで、私たち DBRE チームのように機械学習の専門知識がないエンジニアでも、生成 AI の開発ライフサイクルの理解度が上がることを目指しています。また、生成 AI をサービスで活用する中で直面した課題とその解決策についても具体例を交えて紹介します。加えて、先日開催された AWS AI Day でのセッション「コンテンツ審査を題材とした生成AI機能実装のベストプラクティス」で紹介されている「LLM の実導⼊における考慮点と打ち⼿」に対する実装例の 1 つとしてもお読みいただけるかと思います。
少しでも皆さまの参考になれば幸いです。
目次
この記事の構成は以下のとおりです。長文のため「どんな仕組みか」にだけ興味がある方は「完成した仕組み」まで、生成 AI アプリケーション開発に関心がある方はそれ以降も読んでいただければと思います。
背景
DB のテーブル設計の重要性
一般的に DB のテーブルは、一度作成すると修正が難しいという特性があります。サービス成長に伴いデータ量や参照頻度は増加する傾向にあるため「設計時点で⚪︎⚪︎にしておけばよかった・・・」と後から後悔するような技術的負債を抱え続けることは、できる限り避けたいものです。したがって、統一された基準に基づく「良い設計」でテーブルが作り続けられる仕組みを整えることが重要です。「AWSでデータベースを始めるのに 必要な 10 のこと」においても、クラウドで DB 管理が自動化されてもテーブル設計は依然として価値の高いタスクとされています。
また、生成 AI の普及によりデータ基盤の重要性はさらに高まっています。統一基準で設計されたテーブルは分析がしやすく、分かりやすい命名や適切なコメントは生成 AI に良質なコンテキストを提供できる、というメリットもあります。
こうした背景から、DB テーブル設計の質が組織に与える影響は以前よりも大きくなっています。質を担保する手段として、例えば社内ガイドラインの作成や、それに基づくレビューの実施が考えられます。
レビューに関する弊社の現状
弊社では、テーブル設計レビューは各プロダクトの担当者が行っています。DBRE チームから「設計ガイドライン」を提供していますが、現状のところ拘束力はありません。DBRE が全プロダクトのテーブル設計を横断的にレビューする案も検討しましたが、プロダクトが数十個に及ぶため、DBRE がゲートキーパー的に振る舞うと開発のボトルネックになる懸念があり、断念しました。
以上の背景から、ガードレール的に振る舞う自動レビューの仕組みを DBRE で開発してプロダクトへ提供する、という手段を採用しました。
設計
抽象的なアーキテクチャ図と機能要件
以下は、自動テーブル設計レビュー機能の抽象的なアーキテクチャ図です。
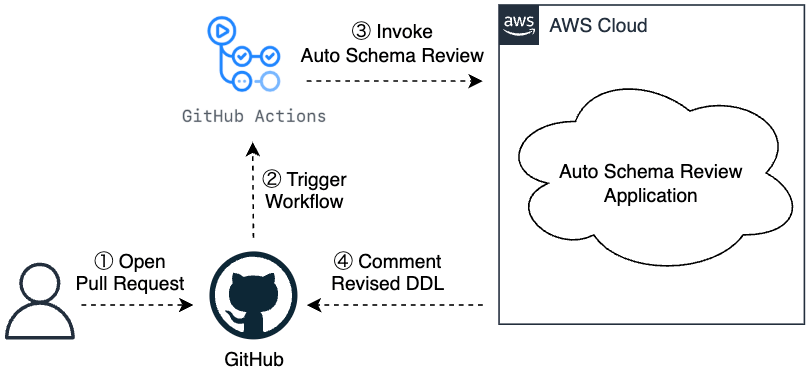
自動レビューを継続的に実行するには、開発フローへの統合が重要です。そのため、PR をトリガとして AWS 上でアプリケーションを自動実行し、PR 内にテーブル定義(DDL)の修正案をコメントでフィードバックする仕組みを採用しました。アプリケーションの要件は以下の通りです。
- 弊社独自のレビュー観点を設定できること
- 人間のレビューを補完する目的で、100%でなくとも可能な限り高精度であること
レビュー機能の実現方針
テーブル設計レビューの自動化には「① 構文解析によるレビュー」と「② 生成 AI によるレビュー」の 2 種類の方針が考えられます。それぞれの特徴を以下にまとめます。
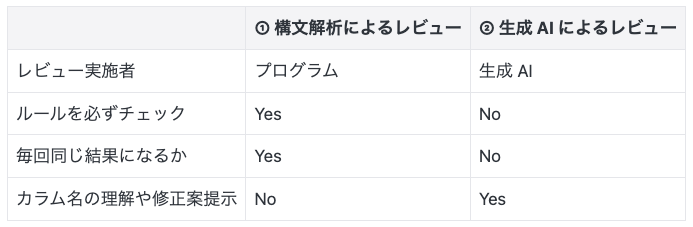
構文解析で対応可能なレビュー観点は①、それ以外は②を適用するのが理想です。たとえば「オブジェクト名は Lower Snake Case で定義する」という命名規則の確認は①で対応できます。一方で「格納されているデータを推測できるオブジェクト名をつける」などの主観的な観点は②が適しています。
このように、レビュー観点に応じて両者を使い分けるのが理想ですが、今回は以下の理由から「②生成 AI によるレビュー」のみで実装する方針としました。
- ①は実現可能性が見えているが、②はやってみないと分からず、先に挑戦する価値があると判断
- ①で対応可能な項目も②で実装することで、両者の精度や実装コストの比較に関する知見を得たい
レビュー対象のガイドライン
提供までの時間を短縮するため、レビュー項目を以下の 6 つに絞りました。
- インデックスが DBRE 指定の命名規則に準拠
- オブジェクト名は Lower snake case で定義
- オブジェクト名は英数字とアンダースコアのみで構成
- オブジェクト名にローマ字を使わない
- 格納されているデータを推測できるオブジェクト名をつける
- 真偽値を格納するカラムは「flag」を使わずに命名
上の 3 つは構文解析で対応可能ですが、下の 3 つは修正案の提示も考慮すると生成 AI の方が適切だと考えられます。
なぜ専用の仕組みを作るのか
「生成 AI によるレビューの仕組み」は既に複数存在しますが、今回の要件を満たせないと判断し、専用の仕組みを作ることにしました。例えば、 PR-Agent や CodeRabbit は有名な生成 AI レビューサービスで、弊社でも PR-Agent を導入し、コードやテックブログのレビューに活用しています。また、GitHub Copilot の自動レビュー機能は現在 Public Preview として提供中で、今後 GA される可能性があります。この機能ではコードを Push する前に Visual Studio Code 上でレビューを受けることも可能で、「生成 AI によるレビューの仕組み」は今後さらに開発フローに自然に統合されていくと想定されます。さらに、GitHub の管理画面で独自のコーディング規約を定義し、それをもとに Copilot にレビューさせることも可能です。
それでも自前で仕組みを構築する理由は以下の通りです。
- 多数のガイドラインを生成 AI で高精度にチェックするのは難しく、外部サービスでの対応は現状困難と判断
- フィードバックの方法を柔軟に調整したい
- 例:意味が曖昧な「data1」のようなカラムは、修正案の提示が難しいためコメントのみに留めたい
- 将来的に構文解析とのハイブリッド構成で精度向上を目指す
次に、完成した仕組みを紹介します。
完成した仕組み
デモ動画
PR 作成後に GitHub Actions が実行され、生成 AI がレビュー結果を PR のコメントとしてフィードバックします。実際の処理時間は約 1 分40 秒ですが、動画では待ち時間を省略しています。なお、生成 AI のコストは Claude 3.5 Sonnet を用いた場合、 DDL を 1 つレビューするために約 0.1 USD 必要という試算になりました。
アーキテクチャ
最終的なアーキテクチャは下図の通りです。なお、使用するプロンプトをチューニングするための評価アプリケーションは別途構築しており、詳細は後述します。
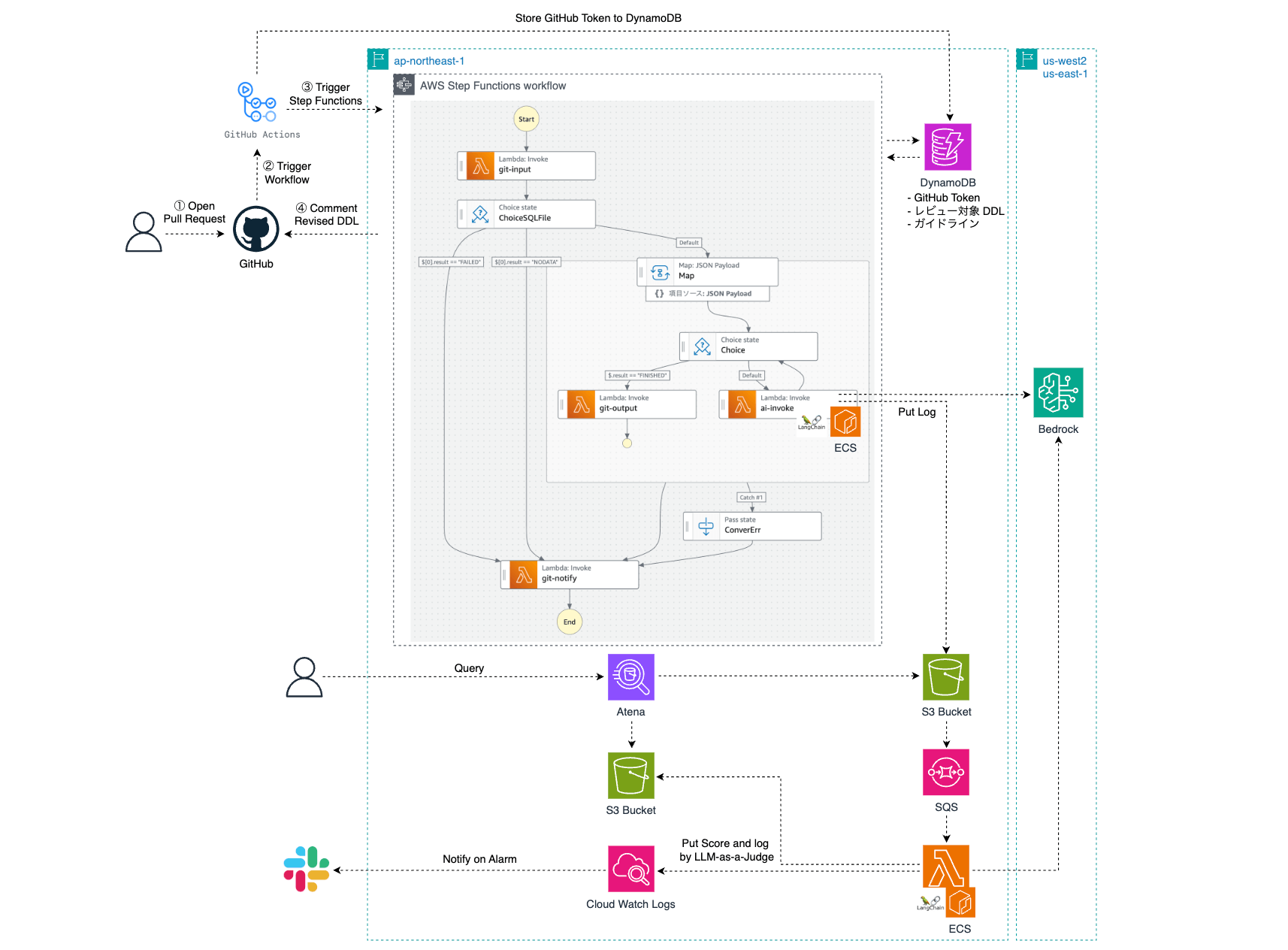
処理の流れ
PR のオープンをトリガに GitHub Actions ワークフローを実行し、AWS Step Functions を起動します。この際、PR の URL とワークフロー内で生成した GITHUB_TOKEN を DynamoDB に保存します。DDL を直接 Step Functions に渡さないのは、入力文字数制限を回避するためです。PR の URL を元に Lambda 側で DDL を抽出します。Step Functions は Map ステート を利用し、各 DDL を並列でレビューします。1 回のレビューでチェックするガイドラインは 1 項目だけです。複数のガイドライン観点でレビューするために、最初のプロンプトで得た「修正後の DDL」を次のプロンプトに渡す処理を繰り返し、最終的な DDL を生成します(理由は後述)。レビュー完了後、PR にコメントとしてフィードバックします。レビュー結果は S3 に保存され、LLM-as-a-Judge を用いて生成 AI がその結果を評価します(詳細は後述)。
結果例を以下に図示します。
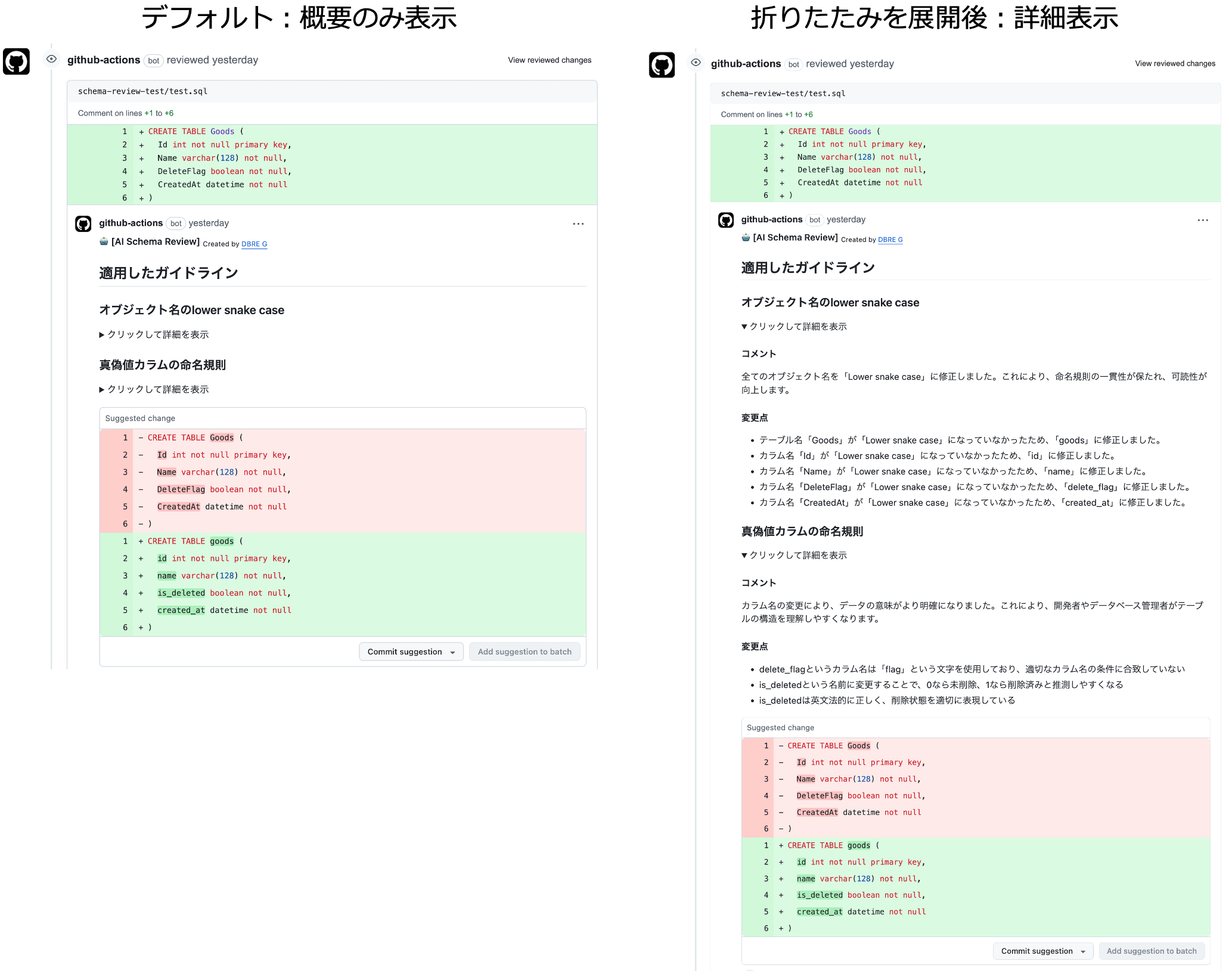
生成 AI からのフィードバックとして「適用したガイドライン」と「修正案」がコメントされます(画像左)。詳細は折りたたまれており、展開すると DDL への具体的な修正内容やコメントが確認できます(画像右)。
導入に必要な手順
以下の 2 ステップでテーブル設計レビュー機能の導入が完了します。数分で設定できるため、簡単に導入して即座に生成 AI によるレビューを開始できます。
- AWS リソースへのアクセスに必要なキーを GitHub Actions Secrets に登録
- 対象の GitHub リポジトリにレビュー機能用の GitHub Actions ワークフローを追加
- DBRE が提供するテンプレートファイルにプロダクト名を追記するだけ
次に、実装で工夫した点を何点か紹介します。
実装時の工夫点
コンテナイメージと Step Functions の活用
当初はシンプルに Lambda のみで実装予定でしたが、以下の課題がありました。
- 使用するライブラリのサイズが大きく、Lambda のデプロイパッケージサイズ制限(250 MB)を超える
- 複数のガイドライン観点を Chain して評価する場合、Lambda の最大実行時間(15分)に達してしまう懸念
- DDL を直列に処理すると、DDL の数が増えるほど実行時間が長くなる
1 を解決するために Lambda にコンテナイメージを採用しました。また、2 と 3 を解決するため Step Functions を導入し、1 回の Lambda 実行で 1 つの DDL を 1 つのガイドライン観点で評価する設計に変更しました。さらに、Map ステートを使い DDL ごとに並列処理を行うことで、全体の処理時間が DDL の数に影響されないようにしました。下図は Map ステートの実装を示しており、ループ部分でプロンプトの Chain を実現しています。
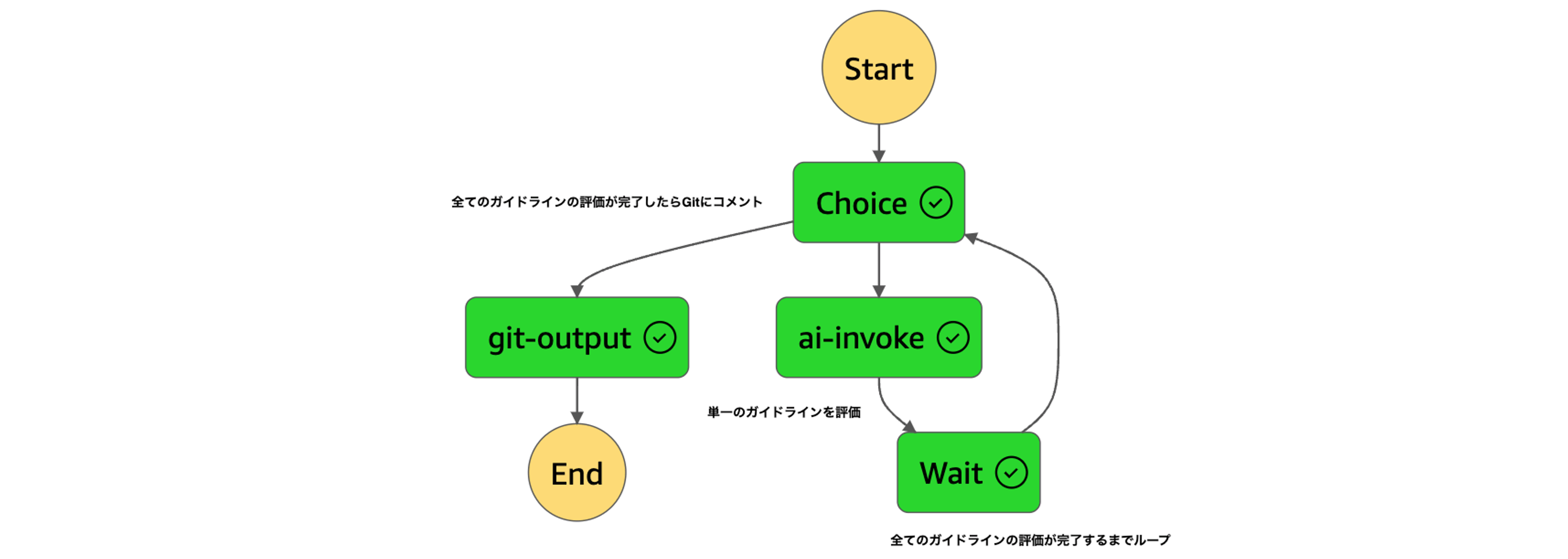
Bedrock API のスロットリング対策
レビュー時に DDL の数 x ガイドラインの数 だけ Bedrock の InvokeModel リクエストが発生し、クォータ制限によるエラーが発生することがありました。AWS のドキュメントによると、この制限は緩和できません。そのため、DDL 単位でリクエストを複数リージョンに分散し、エラー時はさらに別のリージョンでリトライする仕組みを導入しました。これにより、RateLimit に達することがほぼなくなり安定したレビューが可能になりました。
ただし、現在はクロスリージョン推論を利用することで複数リージョン間でトラフィックが動的にルーティングされ、スロットリング対策は AWS 側に任せることが可能なため、今後はこちらに移行予定です。
Lambda から GitHub API を実行するための権限付与方法の整理
Lambda で「対象 PR の変更ファイルの取得」と「対象 PR へのコメント投稿」を実現するため、以下の 3 種類の権限付与方法を比較検討しました。
| トークン種別 | 有効期限 | メリット | デメリット |
|---|---|---|---|
| Personal Access Token | 設定次第、無期限も可能 | 権限の適用範囲が広い | 個人への依存 |
| GITHUB_TOKEN | ワークフロー実行中のみ | 取得が簡単 | 対象の処理次第で権限不足の懸念 |
| GitHub App(installation access token) | 1 時間 | GITHUB_TOKEN で未対応の権限も付与可能 | プロダクトへ導入する際の手順の複雑化 |
今回は以下の理由から GITHUB_TOKEN を採用しました。
- トークンは短期間(ワークフロー中のみ)有効で、セキュリティリスクが低い
- トークンの発行・管理が自動化され、運用負荷が低い
- 今回の処理に必要な権限を付与可能
トークンは有効期限(TTL)付きで DynamoDB に保存し、必要なときに Lambda から取得して使用します。これにより、トークン受け渡し処理のログへの記録有無を調査する必要がなく、安全にトークンを利用できます。
以降では、生成 AI アプリケーションの評価事例について紹介します。
生成 AI アプリケーションの評価
生成 AI アプリケーションの評価について、Microsoft 社のドキュメントに記載の下図を参考にしました。
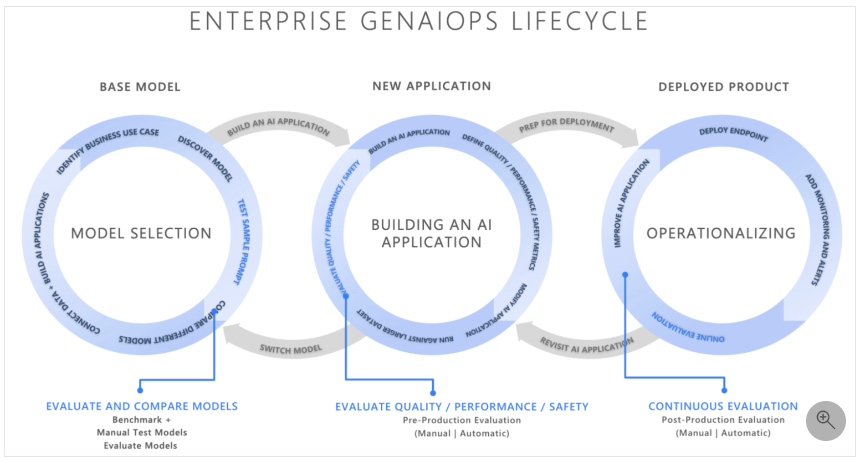
出典: Microsoft 社 - 生成 AI アプリケーションの評価
この図によると、GenAIOps(今回は LLM が対象のため LLMOps)ライフサイクルの中で実施すべき評価は 3 種類です。
- モデル選定フェーズ
- 基盤モデルを評価し、使用するモデルを決定
- アプリケーション開発フェーズ
- アプリケーションの出力(≒ 生成 AI の応答)を、品質・安全などの観点で評価しチューニングを実施
- デプロイ後の運用フェーズ
- Production 環境へデプロイ後も、品質・安全性などについて継続的な評価を実施
以降では、各フェーズにおける評価をどのように実施したか、事例を紹介します。
モデル選定フェーズにおける評価
今回は Amazon Bedrock の基盤モデルから選定を行い、Chatbot Arena のスコアと社内の生成 AI 有識者 のアドバイスをもとに評価し、Anthropic 社の Claude を採用しました。着手時点で最も高性能だった Claude 3.0 Opus を用いて DDL のレビューを実施し、一定の精度を確認しました。モデルごとにベースの性能やレスポンス速度、金銭的コストが異なりますが、今回はレビュー発生頻度は高くなく、かつ「できる限り高速に」といった要件はないため、性能を最も重視したモデル選定を実施しています。あとは Claude のベストプラクティスに基づきプロンプトチューニングを行うことで、さらに高い精度が期待できると判断し、次のフェーズへ進みました。
なお、途中でより高性能・高速な Claude 3.5 Sonnet がリリースされ、推論の精度はさらに向上しました。
アプリケーション開発フェーズにおける評価
生成 AI の評価手法については、こちらの記事に分かりやすくまとめられています。記事内で、
プロンプト、基盤モデル、RAGの有無で、さまざまな評価のパターンが考えられます。
と述べられているように、「何を評価するか」によって評価のパターンが異なります。今回は「単一のプロンプト」の評価に焦点を当て、「DB のテーブル設計を社内独自のガイドラインに従いレビューさせる」という特定のユースケースで、評価の設計と実装の具体例を紹介します。
プロンプトチューニングと評価の流れ
プロンプトチューニングと評価は Claude のドキュメントに記載の下図に沿って実施しました。
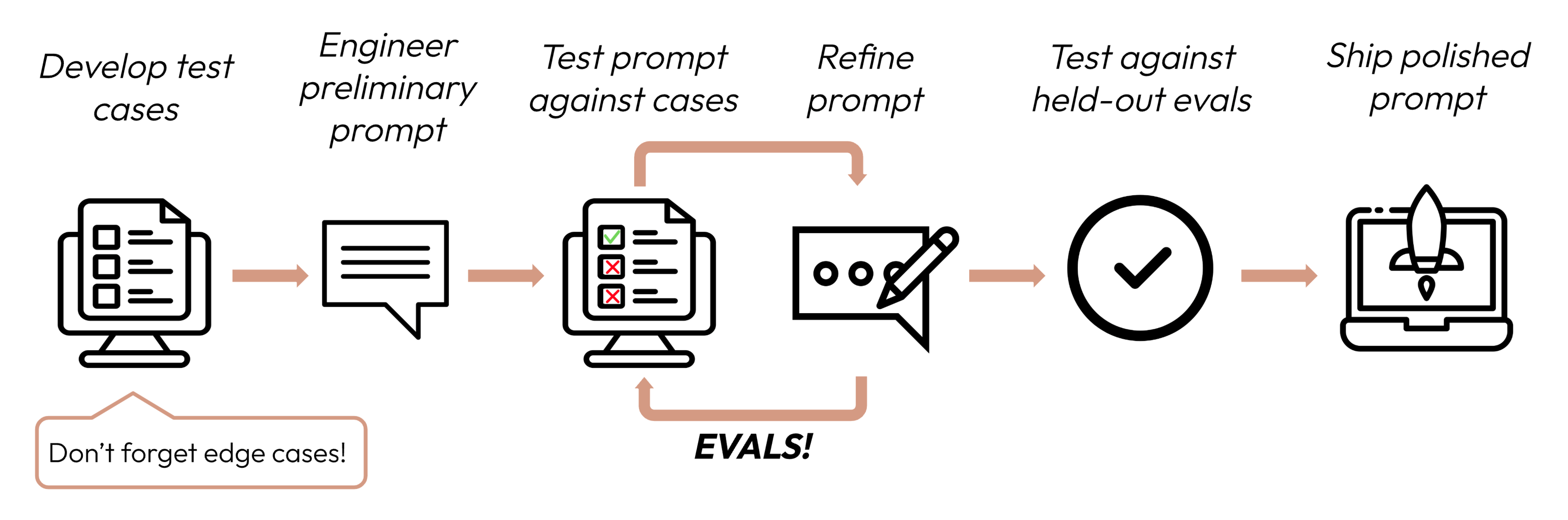
出典: Anthropic 社 - Create strong empirical evaluations
ポイントは、「プロンプトの実行結果が期待にどれだけ近いか」などの評価観点を「何らかの方法で算出したスコア」として定義し、最良のスコアを得たプロンプトを採用する点です。評価の仕組みがない場合、チューニング前後の精度向上を判断する際に主観に頼りがちになり、結果として曖昧さや作業時間の増加を招く恐れがあります。
以降では、まず生成 AI の評価手法について、その後にプロンプトチューニング事例を紹介します。
「生成 AI の評価」とは
deep checks という生成 AI 評価用プロダクトのページには、評価に関して以下の記載があります。
Evaluation = Quality + Compliance
これは生成 AI アプリケーションの評価を最も端的に表現していると感じました。さらに細分化すると、こちらの記事ではサービス提供者の評価観点として「真実性、安全性、公平性、堅牢性」の 4 つの観点に分類されています。評価の観点とスコア算出方法は、アプリケーションの特性に応じて選ぶ必要があります。たとえば、Amazon Bedrock では、テキスト要約に「BERT スコア」、質問回答には「F1 スコア」など、タスクごとに異なる指標が使われています。
評価スコアの算出方法
anthropic-cookbook では、スコアの算出方法を以下の 3 つに大別しています。

anthropic-cookbook に記載のスコア算出方法まとめ
スコアの計算ロジックは、クラウドサービスや OSS を利用するか、自作するかを選択します。いずれにせよ、評価基準は自分たちで設定する必要があります。例えば LLM の出力が JSON 形式の場合、「文字列の完全一致」より「各要素単位の一致」が適切な場合もあります。
Model-based grading について、anthropic-cookbook に記載のコードをより簡潔に表現すると以下のようになります。
def model_based_grading(answer_by_llm, rubric):
prompt = f"""<answer>タグの回答を、<rubric>タグの観点で評価して。「正しい」または「正しくない」と回答して。
<answer>{answer_by_llm}</answer>
<rubric>{rubric}</rubric>
"""
return llm_invoke(prompt) # 作成したプロンプトをLLMに渡して推論させる
rubric = "正しい回答は、2 種類以上のトレーニングプランを含んでいる必要があります。"
answer_by_llm_1 = "おすすめのトレーニングは、「腕立て伏せ」「スクワット」「腹筋」です。" # 実際はLLMの出力
grade = model_based_grading(answer_by_llm_1, rubric)
print(grade) # 「正しい」と出力されるはず
answer_by_llm_2 = "おすすめのトレーニングは、「腕立て伏せ」です。" # 実際はLLMの出力
grade = model_based_grading(answer_by_llm_2, rubric)
print(grade) # 「正しくない」と出力されるはず
評価についてのまとめ
ここまでの内容をまとめると、評価手法は以下の図で表現できます。
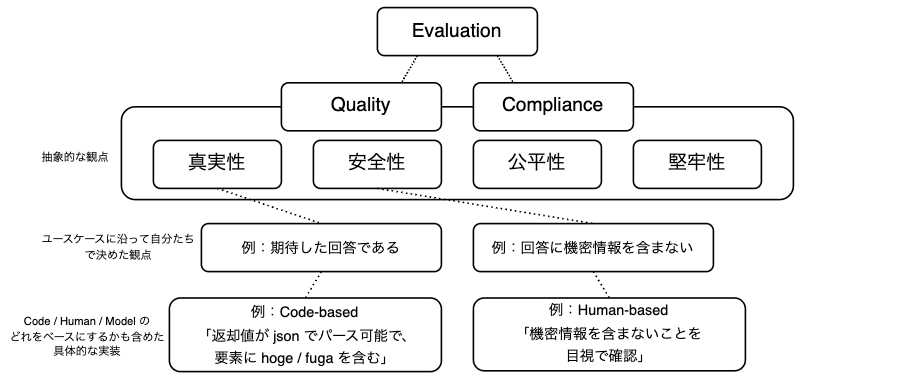
生成 AI の評価は、抽象的には Quality と Compliance に分解されます。これらをさらに細分化し、ユースケースごとに自分たちで具体的な評価観点を設定します。各観点は数値化が必要で、その手段は「Code」「Human」「Model」のいずれかをベースに実現します。
以降では、「DB のテーブル設計レビュー」という観点での具体的な評価方法について説明します。
DB のテーブル設計レビューにおける評価設計
Quality の評価は以下の理由で Code-based アプローチを選択しました。
- Human による評価とチューニングのサイクルは工数増大につながり、得られるメリットに見合わない
- Model-based も検討したが、正解 DDL との完全一致をベストスコアにしたく、Code-based の方が適切と判断
正解データとの「DDL における類似度」を新たに実装するのは難しいため、テキスト間の距離を計測する手法の 1 つであるレーベンシュタイン距離(Levenshtein Distance)をスコアの算出方法に採用しました。この手法では、完全一致時の距離は 0 となり、値が大きいほど類似度が低くなります。ただし、「DDL における類似度」を完全に表す指標ではないため、基本的には全データセットで 0 スコアを目指し、非 0 スコアのデータセットに対してプロンプトチューニングを行う方針としました。アルゴリズムは LangChain の String Evaluators(String Distance)でも提供されており、こちらを使用しています。
一方、Compliance の観点については社内向けアプリケーションであることや、プロンプトに埋め込むユーザー入力を DDL に限定する実装になっていることから、今回は不要と判断しました。
評価の実装
実装した評価の流れは以下のとおりです。
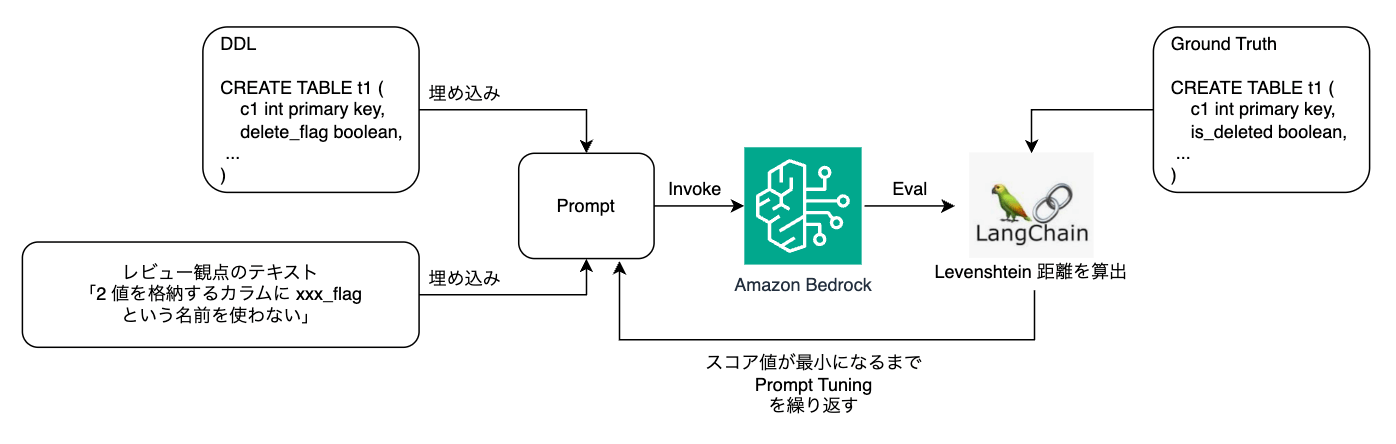
各レビュー観点ごとに、入力用 DDL と正解 DDL を組み合わせた 10 パターンのデータセットを作成しました。効率的にプロンプトチューニングと評価を繰り返すため、Python と Streamlit で専用アプリケーションを開発しました。データセットは jsonl 形式で保存し、ファイルを指定すると自動で評価を実行して結果が表示されます。以下のように各 json は「評価対象のガイドライン」「LLM を Invoke する際のパラメータ」「入力 DDL」「正解 DDL」が含まれています。
{
"guidline_ids": [1,2],
"top_p": 0,
"temperature": 0,
"max_tokens": 10000,
"input_ddl": "CREATE TABLE sample_table (...);",
"ground_truth": "CREATE TABLE sample_table (...);"
}
個別の結果表示では、出力 DDL と正解 DDL の diff を表示し、視覚的に差異(=チューニングポイント)が分かるよう工夫しました。
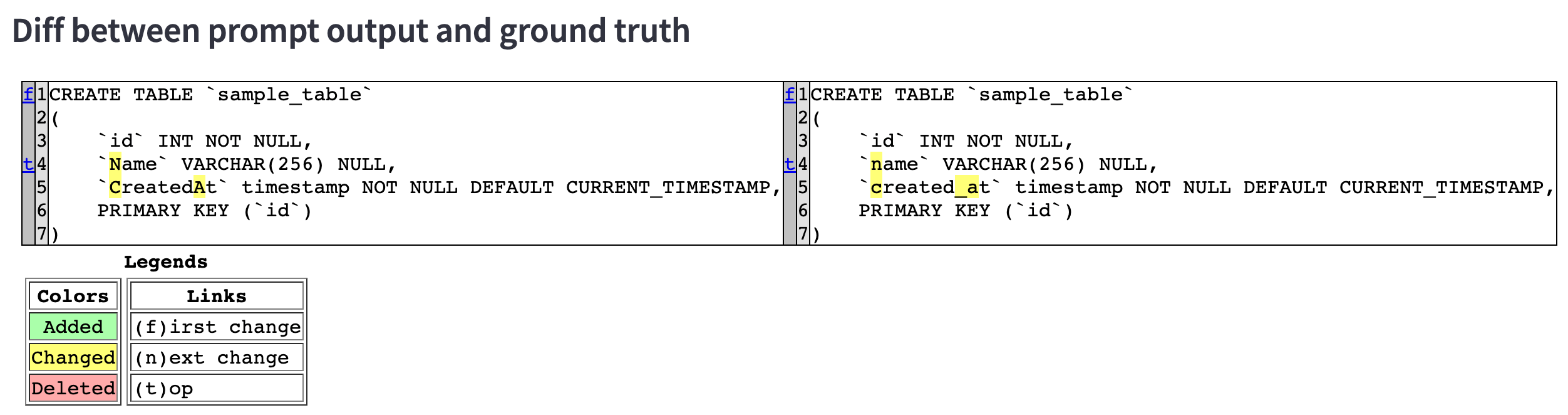
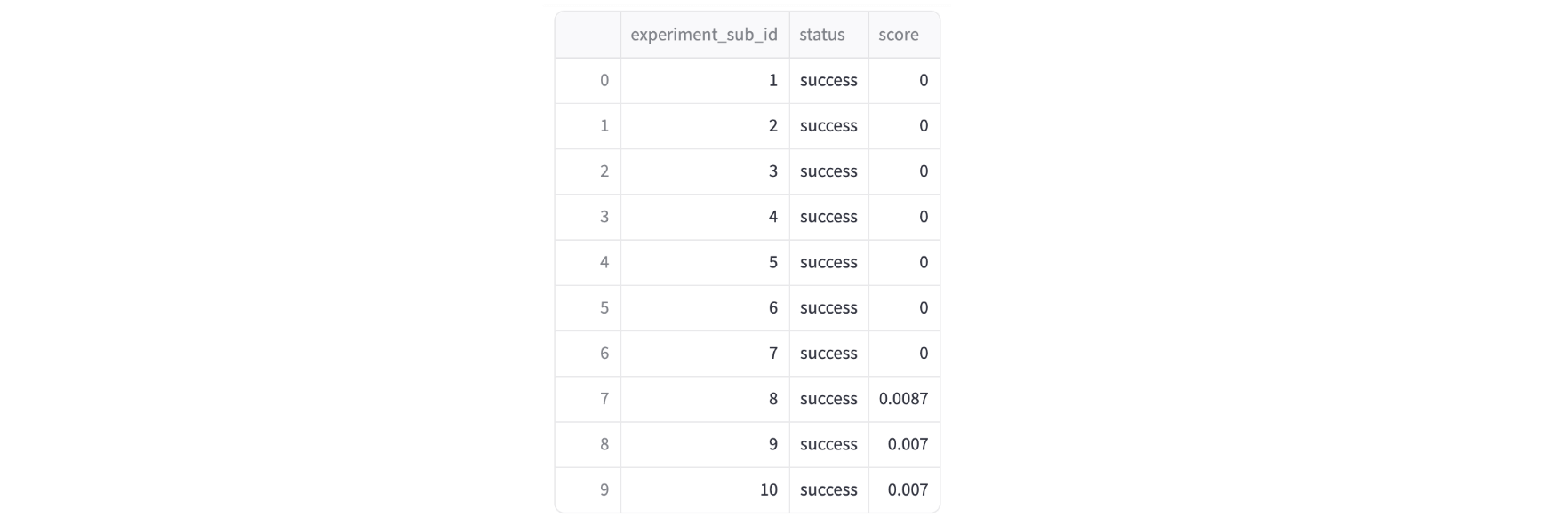
評価が全て終わると、スコアの集計結果も確認できます。
プロンプトチューニング
Claude のドキュメントに基づき、以下のポイントを意識してプロンプトの作成・チューニングを行い、最終的に 60 個のデータセットほぼ全てにおいて、最良(0スコア)の結果を達成しました。
- ロールを設定
- XML タグを活用
- Claude に思考させる(思考過程の出力を指示することで、期待外れの回答時にデバッグを容易に)
- Few-Shot Prompting(出力例を提示)
- 参照データを冒頭に、指示を末尾に配置
- 明確かつ具体的な指示を与える
- プロンプトを Chain させる
有名な手法も多く詳細は省略しますが、最後の 2 点について補足します。
「明確で具体的な指示を与える」
当初は社内のテーブル設計ガイドラインの文章をそのままプロンプトに埋め込んでいました。しかし、ガイドラインには「あるべき姿」のみ記載され、「具体的な修正手順」が含まれていませんでした。そこで、Step-by-step 形式の「具体的な修正指示」に書き換えました。例えば「真偽値を格納するカラム名に xxx_flag を使用しない」というガイドラインについては、以下のように修正しました。
以下の手順に従い、真偽値が格納されているカラム名を抽出し、必要に応じて適切なカラム名に変更してください。
1. 真偽値が格納されているカラム名を抽出します。判断基準は、boolean型が使われているか「flag」文字が入っているかです。
2. 真偽値カラムの名前を1つずつチェックし、カラムの意味をまずは理解します。
3. 真偽値カラムの名前を1つずつチェックし、より適切な名前があると判断した場合は、カラム名を修正します。
4. 適切なカラム名の条件は<appropriate_column_name></appropriate_column_name>タグの中を参照してください。
<appropriate_column_name>
「flag」という文字を使わず...
...
</appropriate_column_name>
「プロンプトを Chain させる」
チェックするガイドラインが増えるほど、1 回で全てを確認しようとするとプロンプトが複雑化し、チェック漏れや精度低下の懸念が高まります。そのため、1 回のプロンプト実行で AI にチェックさせる項目を 1 つに限定しました。最初のプロンプトで得た「修正後の DDL」を次のプロンプトの入力として渡し(Chain)、繰り返し処理することで最終的な DDL を得る仕組みにして、アーキテクチャにも反映しました。プロンプトの Chain で、以下のメリットも得られました。
- プロンプトが短く、タスクが 1 つに絞られるため精度が向上
- ガイドライン追加時は新規プロンプトを作成するだけでよく、既存プロンプトへの精度影響がない
一方で、LLM の Invoke 回数が増えるため、時間と金銭的コストは増加します。
デプロイ後の運用フェーズにおける評価
プロンプト作成段階では、手動で作成した正解データを用いて Quality を評価しました。しかし、Production 環境では正解データが存在しないため、別の評価手法が必要です。そこで「LLM の応答を LLM に評価させる」手法である LLM-as-a-Judge を採用しました。Confident AI のドキュメント によると、この手法には 3 種類の方法があるとされています。
- Single Output Scoring (正解データなし)
- 「LLM の出力」と「評価基準(Criteria)」を与え、基準に基づき LLM にスコアを付けさせる
- Single Output Scoring (正解データあり)
- 上記に加え「正解データ」も提供。より高精度な評価が期待できる
- Pairwise Comparison
- 2 つの出力を比較し、どちらが優れているかを判定。「優れた」の Criteria は自分で定義する
今回は Single Output Scoring (正解データなし) を採用しました。この手法も LangChain でサポートされており、提供されている関数を使用しました。なお、現在は LangSmith による実装が推奨されています。
評価基準(Criteria)は以下の 2 つを定義し、それぞれ 10 点満点で採点させています。
- Appropriateness
- LLM の出力がガイドラインに沿って適切に修正されているか
- Formatting Consistency
- 不要な改行や空白などが付与されておらず、フォーマットの一貫性が保たれているか
コードとプロンプトのイメージは以下の通りです。
input_prompt ="""
<input_sql_ddl>CREATE TABLE ...</input_sql_ddl>
<table_check_rule>曖昧なオブジェクト名は...</table_check_rule>
指示書:table_check_ruleを元に、input_sql_ddlを適切なDDLに修正してください。
"""
output_ddl = "CREATE TABLE ..." # 実際はLLMが生成したDDLをセット
appropriateness_criteria = {
"appropriateness": """
Score 1: ...
...
Score 7: 入力の指示に概ね従った応答が生成されており、不適切な修正が2箇所以下である。
Score 10: 入力の指示に完全に従った応答が生成されている。
"""
}
evaluator = langchain.evaluation.load_evaluator(
"score_string", llm=model, criteria=appropriateness_criteria
)
result = evaluator.evaluate_strings(
prediction=output_ddl, input=input_prompt
)
print(result)
この実装で以下のような出力が得られます。(省略箇所あり)
この回答は、与えられた指示に完全に従っています。以下に評価の理由を説明します:
1. カラム名の抽出と評価:
回答者は全てのカラム名を抽出し、それぞれのカラム名がデータの中身を推測できるかどうかを適切に判断しています。
2. 曖昧なカラム名の特定:
提供されたDDL内のカラム名は全て、その目的や格納されるデータの種類を明確に示しています。例えば、...
...
この回答は、与えられた指示を完全に理解し、適切に実行しています。
Rating: [[10]]
この仕組みは、アーキテクチャ図における下図赤枠部分に相当します。
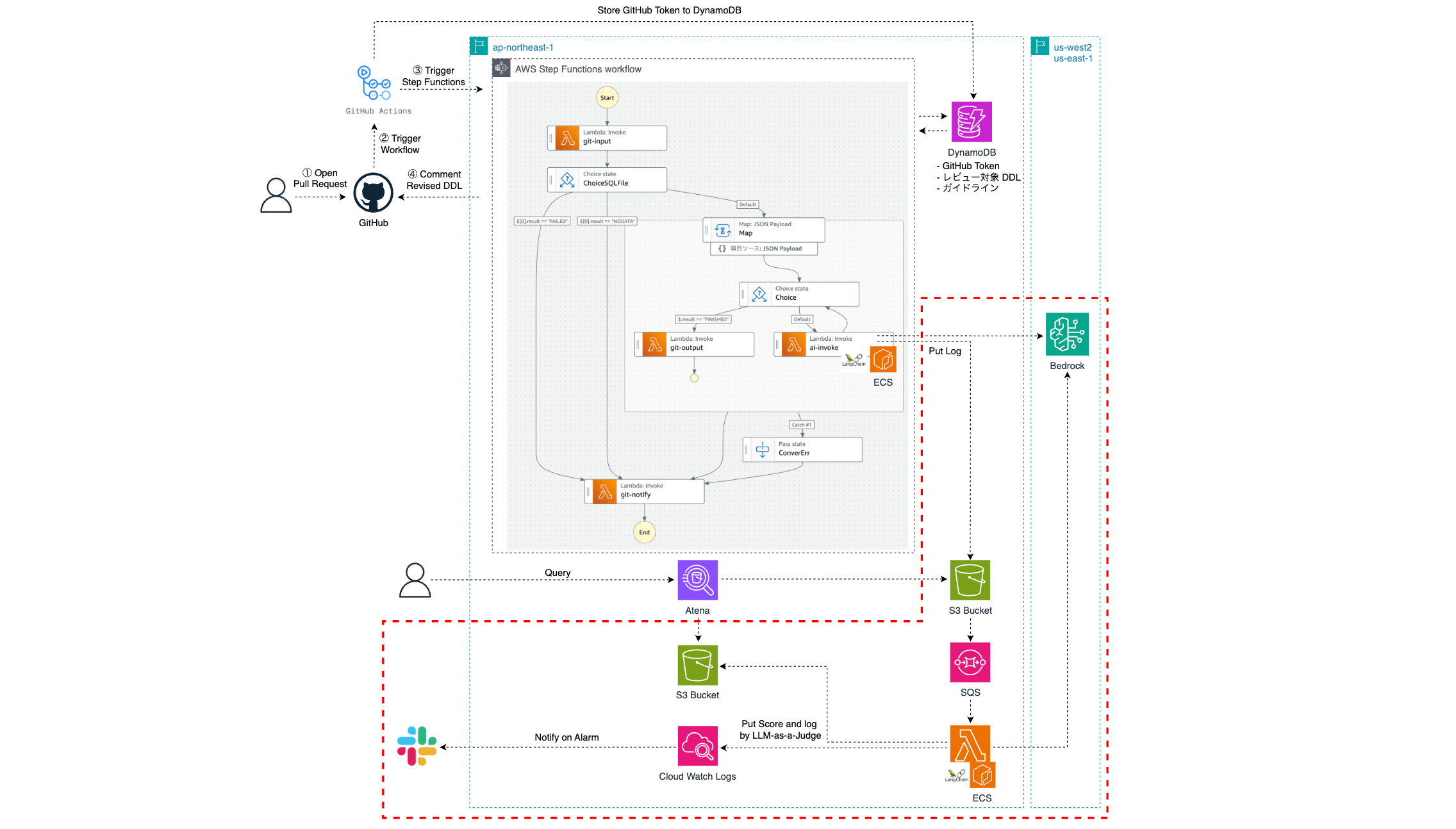
LLM のレビュー結果が S3 に保存されると、SQS を介して非同期で LLM-as-a-Judge 用の Lambda が起動します。この Lambda が評価を実行し、結果はログとして S3 に保存され、スコアは CloudWatch のカスタムメトリクスとして送信されます。また、CloudWatch Alarm により閾値を下回る場合は Slack に通知されます。
このスコアは完全に信頼できるものではありませんが、対象が社内向けシステムであるため、ユーザーからのフィードバックを得やすい環境です。そのため、定量的なスコアで継続的にモニタリングしつつ、定期的にユーザーフィードバックを収集する体制をとりました。
得られた学びと今後の展望
最後に、生成 AI アプリケーション開発に挑戦して得た学びと、今後の方向性についてまとめます。
評価が非常に重要かつ難しい
プロンプトの結果を同じ観点で評価することで、主観を排除しつつ高速にチューニングと評価を繰り返すことができました。この経験から、評価設計の重要性を強く感じました。ただし、GenAIOps における3つの評価(モデル選定時、開発時、運用時)はユースケースごとに判断が必要で「自分たちの評価設計の妥当性判断」は難しいと感じました。また、評価の観点が不足していると、コンプライアンス面で問題を抱えたアプリケーションを提供するリスクもあります。今後、より体系的でマネージドな評価方法や仕組みが提供されれば、GenAIOps が実現しやすくなっていくと考えます。
生成 AI のユースケースの想像の幅が広がった
実際に自分たちで生成 AI アプリケーションに関して調査・実装したことで解像度が上がり、ユースケースの想像の幅が広がりました。例えば、エージェントとロック競合の情報を収集する仕組みなどを組み合わせて、よりマネージドかつ高速にインシデント調査ができる仕組みなどを想像できるようになりました。
プログラマブルなタスクの代替としての 生成 AI 活用
生成 AI をアプリケーション開発に活用する方法は、大きく次の 2 つに分けられます。
- タスクそのものを 生成 AI に実施させる
- プログラム開発の生産性を 生成 AI で向上させる
今回は、 生成 AI に推論させるべきタスクだけでなく、本来はプログラムで処理すべきタスクも生成 AI を使って実装しました。当初は「プロンプトを工夫すれば迅速に高精度の結果が得られるかもしれない」と期待していましたが、実際にはプロンプトチューニングに多くの時間が必要であると痛感しました。一方、Claude の複数モデルで同じタスクを解かせた結果、モデルの精度が高いほど明確に結果が改善されることを確認しました。さらに、精度が高いモデルでは予測不能な挙動が減り、プロンプトチューニングに要する時間も短縮できることが分かりました。
これらの経験を踏まえると、今後モデル精度がさらに向上した場合、要件次第では「タスクを実施するプログラムを書く」代わりに「タスクそのものを 生成 AI に実施させる」という手段を選択するケースが増えるかもしれません。
今後の展望
今後は以下のようなことに取り組んでいきたいと考えています。
- 対応ガイドラインの拡充
- 導入プロダクトの拡大
- プログラムによる構文解析とのハイブリッド構成にする
- レビュー結果をユーザーへフィードバックする際の「分かりやすさ」の改善
- 現状の簡易的な LLMOps を、モニタリングだけでなくログを活用したプロンプト・モデル改善にまで拡張
- 参考: @hiro_gamo 氏の Post
まとめ
本記事では、Amazon Bedrock を活用し、Serverless アーキテクチャで実装した DB テーブル設計の自動レビュー機能を紹介しました。また、生成 AI アプリケーションの評価方法についても解説しました。先日開催された AWS AI Day でのセッション「コンテンツ審査を題材とした生成AI機能実装のベストプラクティス」で紹介されている「LLM の実導⼊における考慮点と打ち⼿」の各項目にマッピングする形で、今回の取り組みを以下にまとめます。
| 項目 | 内容 |
|---|---|
| 他の手段との棲み分け | ● DBRE チームで LLM による自動化に挑戦 ● 将来的にはルールベースとの併用を目指す |
| 精度 | ● 「テーブル設計レビュー」というユースケースに沿った評価観点を設計 ● プロンプトチューニングと評価を高速に繰り返すために、専用のアプリケーションを開発 ● 選定したモデル(Claude)のベストプラクティスに従ってプロンプトチューニングを実施 ● 1 回のプロンプト実行で AI にチェックさせる項目を 1 つに限定 & プロンプトの Chain で精度向上 |
| コスト | ● DDL の文字数にもよるが、1 DDL あたり約 0.1 USD ● レビュー発生頻度は低いため、コストより精度を重視したモデル選定(Claude 3.5 sonnet) ● プロンプトの Chain も同様に、コストは増えるが精度向上のメリットが大きいと判断 |
| 可用性・スループット | ● クォータを意識してリージョン間のリクエスト分散やリトライ処理を実装 ● よりマネージドなクロスリージョン推論へと移行予定 |
| レスポンス速度 | ● 「できる限り高速に」といった要件はないため、速度よりも精度を優先したモデル選定 ● 各 DDL を並列でレビューすることで速度向上 ● 数 10 個 の DDL に対して 2-5 分程度で レスポンスを返却 |
| LLMOps | ● LLM-as-a-Judge を用いて継続的に精度をモニタリング |
| セキュリティ | ● GitHub との連携には、GHA ワークフロー実行中だけ有効な GITHUB_TOKEN を採用 ● 社内アプリ & 入力が DDL に限定されるため、LLM の応答への Compliance 観点評価は未実施 |
本プロダクトは現在複数のプロダクトへの導入が進行中で、今後もユーザーフィードバックを基に改善を進める予定です。生成 AI アプリケーションは Amazon Bedrock Prompt フロー など開発用のサービスも進化を続けており、今後もより便利になっていくと思います。今後も積極的に生成 AI 領域にも挑戦していきたいです。
KINTO テクノロジーズ DBRE チームでは一緒に働いてくれる仲間を絶賛募集中です!カジュアルな面談も歓迎ですので、 少しでも興味を持っていただけた方はお気軽に X の DM 等でご連絡ください。併せて、弊社の採用 X アカウント もよろしければフォローお願いします!
関連記事 | Related Posts
生成 AI アプリケーション開発に評価の仕組みを導入して精度向上を実現した話:DB 設計レビュー自動化の取り組み

Event Report: DBRE Summit 2023

A system for efficiently reviewing code and blogs: Introducing PR-Agent (Amazon Bedrock Claude3)
Streamlining SQL Creation Using GitHub Copilot Agent!

The Secret to Achieving 99% Accuracy in Generative AI: Hands-On with AWS Automated Reasoning
Efforts to Implement the DBRE Guardrail Concept
We are hiring!
【SRE】DBRE G/東京・大阪・名古屋・福岡
DBREグループについてKINTO テクノロジーズにおける DBRE は横断組織です。自分たちのアウトプットがビジネスに反映されることによって価値提供されます。
シニア/フルスタックエンジニア(JavaScript・Python・SQL)/契約管理システム開発G/東京
契約管理システム開発グループについて◉KINTO開発部 :66名・契約管理開発G :9名★←こちらの配属になります・KINTO中古車開発G:9名・KINTOプロダクトマネジメントG:3名・KINTOバックエンド開発G:16名・KINTO開発推進G:8名・KINTOフロントエンド...


