約13分で読めます
DBRE
DBRE ガードレール構想の実現に向けた取り組みについて
こんにちは、KINTO テクノロジーズ (以下 KTC) で DBRE をやっていますあわっち(@_awache) です。
今回は僕が KTC で実現したい Database のガードレール構想についてお話ししたいと思います。
ガードレールとは
ガードレールとは Cloud Center of Excellence (CCoE) の活動の中でよく表現される言葉です。
一言でガードレールを表現すると「可能な限り利用者の自由を確保しつつ、望ましくない領域のみ制限、または発見するためのソリューション」です。
ガバナンスを重視することを求められる Database 領域を取り扱うという役割の特性上、DB エンジニアは時に「ゲートキーパー」として作用してしまい、企業活動のアジリティを損なってしまうこともあります。
そこで DBRE の活動にこの「ガードレール」の考え方を取り入れてアジリティとガバナンスコントロールを両立させようと考えています。
ガードレールの種類
ガードレールは下記の 3種類に分類できます。
| 種類 | 役割 | 概要 |
|---|---|---|
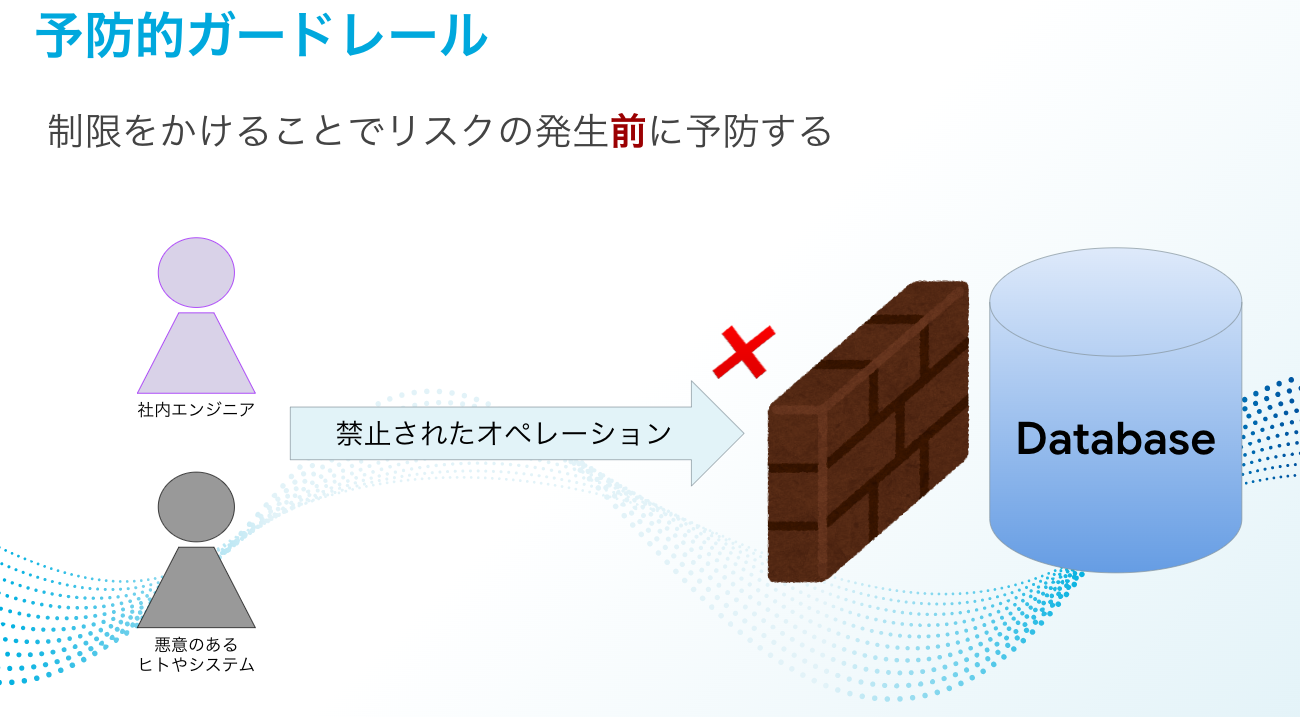
| 予防的ガードレール | 制限 | 対象の操作を出来ないような制限の適用 |
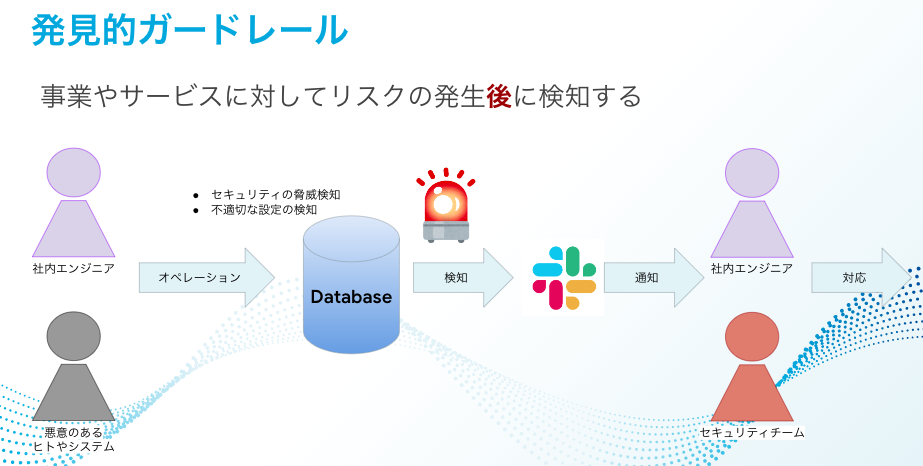
| 発見的ガードレール | 検知 | 望ましくない操作を行った、された場合、それを発見、検知する仕組み |
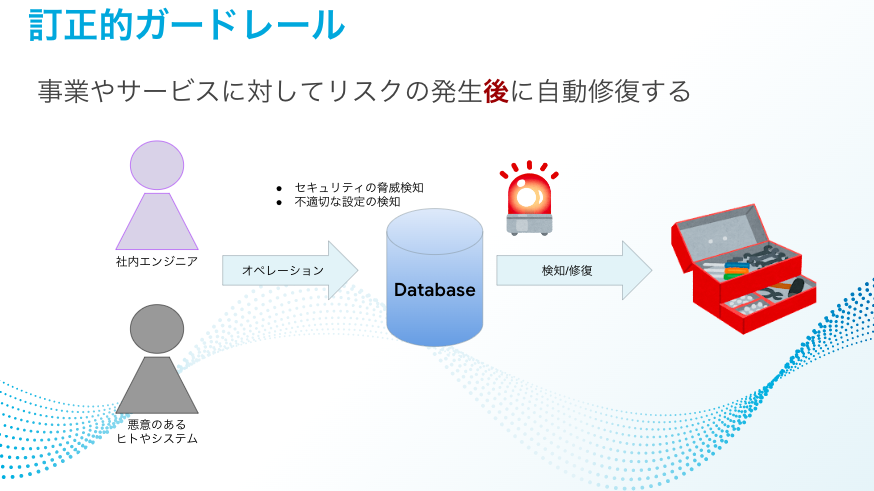
| 訂正的ガードレール | 修正 | 望ましくない設定がなされた場合に自動で修正する仕組み |
-
予防的ガードレール
-
発見的ガードレール
-
訂正的ガードレール
ガードレール構想
導入当初の段階から予防的ガードレールによって強い制限を適用してしまうとこれまでできていたことや、やりたいことができなくなることで現場のエンジニアの反発や疲弊に繋がる可能性があります。
逆に訂正的ガードレールによって自動修復を行ってしまうと何が不適切だったのか、不適切な設定をどのように直していくのかを考えるというエンジニアのスキル向上の機会を失わせてしまうこともあるかと思います。
だからこそ現在は可能な限り利用者の自由を確保し、ガバナンスコントロールを実現するための地盤固めのフェーズだと思っています。その上で「発見的ガードレール」を取り入れることが望ましいと考えています。
現在 KTC では DEV/STG/PROD の 3ステージ制を導入しているため発見的ガードレールによってリスクを検知の周期を Daily で回したとしても、多くの場合本番に適用される前に気付ける状態にあります。発見的ガードレールで不適切な設定を定期的に検知し、それを受け取った現場のエンジニアが修正して適用する、というサイクルを継続的に回すことでサービスレベルの底上げに繋げられればこの仕組みの価値も上がっていきます。
もちろん発見的ガードレールは提供して終わりではなく、そこで検知されるルールを現場の状況に合わせてアップデートし続けることも大切です。現場のエンジニアと伴走し KTC の実態にあったガードレールを提供することで、この仕組み自体も KTC と一緒に成長していく必要があります。
Executive Sponsor の強力な後ろ盾
「ガードレールで検知されたものはエラーレベルに応じて対応する」ということが浸透しなければ狼アラートを増やすだけです。また個別のサービスの事情に応じてこのルールは対応しない、ということを許容してしまうこともアンチパターンだと考えます。
そこで大切にするべきことは「KTC としてサービスを提供する以上最低限守るべきルールだけを盛り込むこと」です。
細か過ぎるルールは定義せず、ガードレールでアラートが上がったらエラーレベルに応じて対応をする、の一点を KTC 内の全てのエンジニアに対して共通認識化、浸透させることができなければこの仕組みの価値がありません。
そこで最後の後押しをしてくれるのは、活動を後押ししてくれる Executive Sponsor です。Executive Sponsor は経営層、CxO など、企業としての方向性を示してくれる役割の方が望ましいです。
最初はどれだけ気を遣ったとしても現場のエンジニアにルールを強制する、という本質的なことは変わらないので、この活動が Executive Sponsor を通じて経営でコミットされているということは彼らが協力的に動く一つの理由やモチベーションとして作用するはずです。
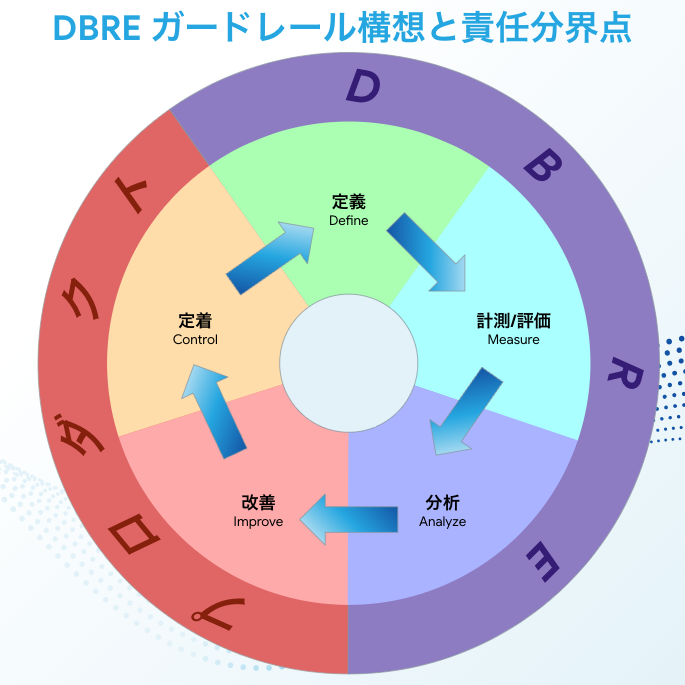
責任分界点
KTC の DBRE は横断組織でありサービスを直接運用しているわけではありません。そのためどこからどこまでが DBRE の責任でどこからどこまでは現場のエンジニアの責任なのか、を明確にする必要があります。
僕はこれをDMAIC というフレームワークを用いて考えました。DMAIC については 「【DMAICとは:定義、測定、分析、改善、定着】業務フロー改善プロジェクトの必勝パターン(リーンシックスシグマ)」に非常に分かりやすくまとまっていると思いますのでこちらをご覧ください。
この5段階の手順にざっくりと誰が責任を持つのか、そしてそこでやるべきこと、を当てはめると下記のようになります。
| 定義 | 内容 | 作業 | 最終責任 |
|---|---|---|---|
| Define | 計測/評価の範囲や内容の定義 | 文書化 Script 化 |
DBRE |
| Measure | 計測/評価を実施して結果を収集 | Script の実行 | DBRE |
| Analyze | 原因の分析/レポーティング | 組織全体の可視性を高める | DBRE |
| Improve | 不具合の改善/改善計画の作成 | 問題に対してスムーズな対応を実施 | プロダクト |
| Control | 成果を確認し、定着を目指す | サービスとして健全な状態が継続されている | プロダクト |
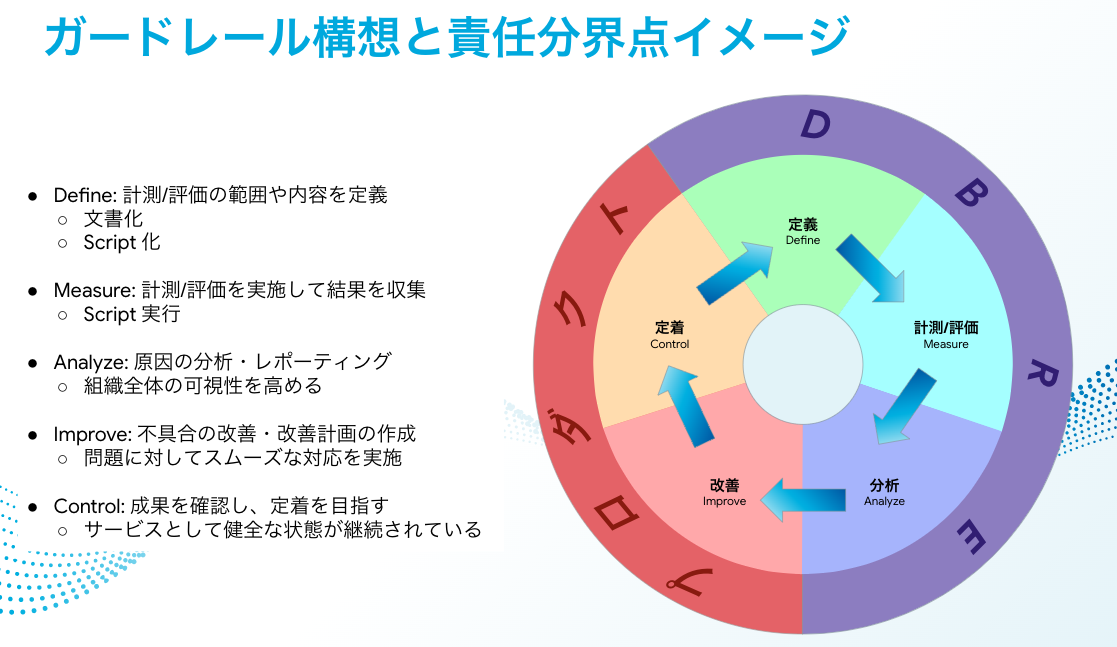
この図はそれぞれ役割を明確にしつつも、 全てのステップでお互いに相談や改善、など連携しながら最終的な責任をどこが持つのか、ということを表しています。例えば DBRE は現場の改善や定着に向けた動きを一切手助けしないということではない、ということを補足させていただきます。
どのようにガードレールを構築するのか
ここまで長々とガードレールを構築するまでの考え方を記載させていただきましたがここから具体的な取り組みについて説明させていただきます。
[Define] エラーレベルの定義
最初にエラーレベルを定義することは最も重要です。
エラーレベルとはこのガードレールが KTC に提供する価値そのものです。DBRE としてどれだけ Must でやるべきことと考えたとしても定義されたエラーレベルに合ってなければ Notice もしくは対象外になります。設定したルールを定義に照らし合わせることを僕自身も徹底することで現場のエンジニアに対する説明責任を果たすことや、「何でも Critical」としたい欲求などをコントロールすることができます。
具体的な定義は下記の通り設定しました。
| Level | 定義 | 対応速度 |
|---|---|---|
| Critical | セキュリティ事故に直結する可能性があるもの クリティカルな異常に気付けない状態になっているもの |
即時対応を実施 |
| Error | サービスの信頼性やセキュリティに関係する事故が発生する可能性があるもの Database 設計上の問題でおよそ 1年以内に悪影響を及ぼす可能性のあるもの |
2 ~ 3営業日対応を実施 |
| Warning | それだけではサービスの信頼性やセキュリティ事故に直結しないもの セキュリティリスクを含むが影響が限定的なもの Database 設計上の問題でおよそ 2年以内に悪影響を及ぼす可能性があるもの |
計画的対応を実施 |
| Notice | 正常に動作しているが記録しておきたい重要なもの | 必要に応じて対応 |
[Define] 具体的な内容整理
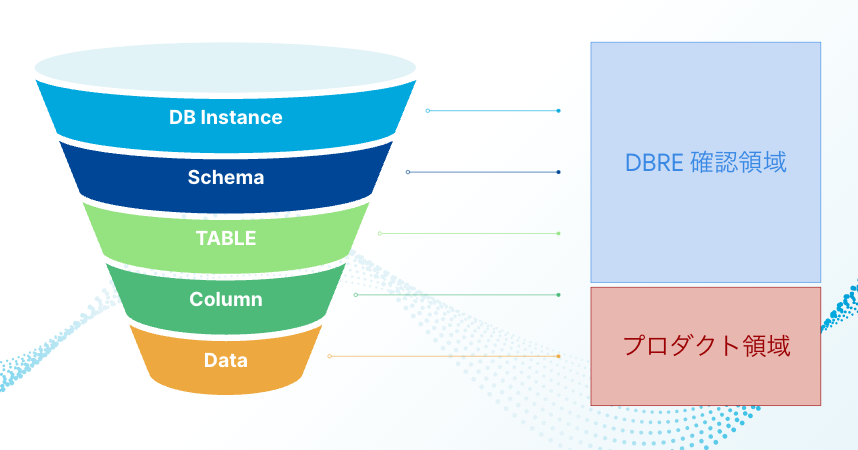
続いて定義したルールの中でガイドライン作成を検討することになるのですが、最初から Database 全体を見ようと思うと失敗してしまいます。そのため僕は最初のステップではガードレールの範囲を「おおよそ自力でできる範囲」と置いています。おおよそ自力でできる範囲、とは今動いているサービスに対する深いドメイン知識がなくてもできる範囲、例えば Database クラスター(KTC ではメインの DB は Amazon Aurora MySQL を使用しています) の設定や、DB 接続ユーザーの作成、Schema、Table、Column の定義、がそこにあたります。逆に現段階でガードレールで手を出さないところはスキーマ設計やデータ構造、Query などになります。
特にここでのポイントは 「Slow Query が発生した場合の対処」をガードレールに設定していないこと、です。Slow Query は非常に重要な指標になりうるものですが、サービス単位の深いドメイン知識がなければ対応は困難です。もし現段階で大量に出ていたとしたらどこから手をつけたらいいのか、そしてそれをエラーレベルに応じた期限通りに確実に対処し続けることも難しい状態です。
Slow Query に関してはまずはガードレールではなく、Slow Query を可視化し誰でも状況が確認できるようにする、そしてそれを対処することを SLO として定義し、 DBRE から個別に提案してみる、という動きをもって段階を踏んで考えていきたいと思っています。
- ガードレールで確認する領域イメージ
[Define] ガイドラインの設定/スクリプト化の実施
定義したエラーレベルや、手を出す範囲を決めた上でガイドラインに落とし込みます。そこで合意を得たものに関して自動的に検出できるようにします。
こうして作成したガイドラインを一部紹介します。
| チェック項目 | Error Level | 理由 |
|---|---|---|
| Database に対する Backup 設定が有効である | Backup が設定されてなかった場合には Error となります | Backup は自然災害、システム障害、または外部からの攻撃などによるデータ消失のリスクに対する有効な対策です |
| バックアップ保持期間が十分な期間である | Backup 保持期間が 7 未満の場合には Notice となります。 | 重大な損失から復旧するためには一定の期間を必要とします。 どの程度あれば十分なのか、一概な定義はありません。そのため AWS の自動スナップショット機能のデフォルトを設定しています。 |
| Audit Log の出力が有効である | Audit Log の設定がされていなかった場合には Critical となります | Database に対して、いつ、誰が、何をおこなったのかをログとして残すことでデータ消失やデータ漏洩のリスクに正しく対応することができます |
| Slow Query Log の出力が有効である | Slow Query の設定がされていなかった場合には Critical となります | Slow Query の設定が有効でなかった場合、サービス障害の起因となる Query を特定できない可能性があります |
| Schema、Table、Column の文字コードに utf8(utf8mb3) で構成されたオブジェクトが存在しない | Schema、Table、Column の文字コードに utf8(utf8mb3) で構成されたオブジェクトが存在した場合、Warning となります | utf8(utf8mb3) では格納できない文字列が存在してしまいます また近いうちに MySQL のサポートからも対象外となることが明記されています |
| 全てのテーブルに Primary Key が存在している | 主キーのないテーブルを利活用していた場合、Warning となります | そのスキーマの主体は何か、機械的にレコードを一意に特定するためには主キーが必要になります |
| Schema、Table、Column の名前に予約語となる文字列だけで構成されたものがない | 予約語だけで構成された名前が存在した場合、Warning となります | 予約語だけで構成された名前は将来的に使えなくなる、もしくは必ずバッククオート(`)で囲う必要があることが予定されています。 予約語一覧は 9.3 キーワードと予約語 を確認しましょう |
これらは AWS の API や Information Schema (一部 mysql Schema や Performance Schema) だけの情報から取得可能な範囲にしています。
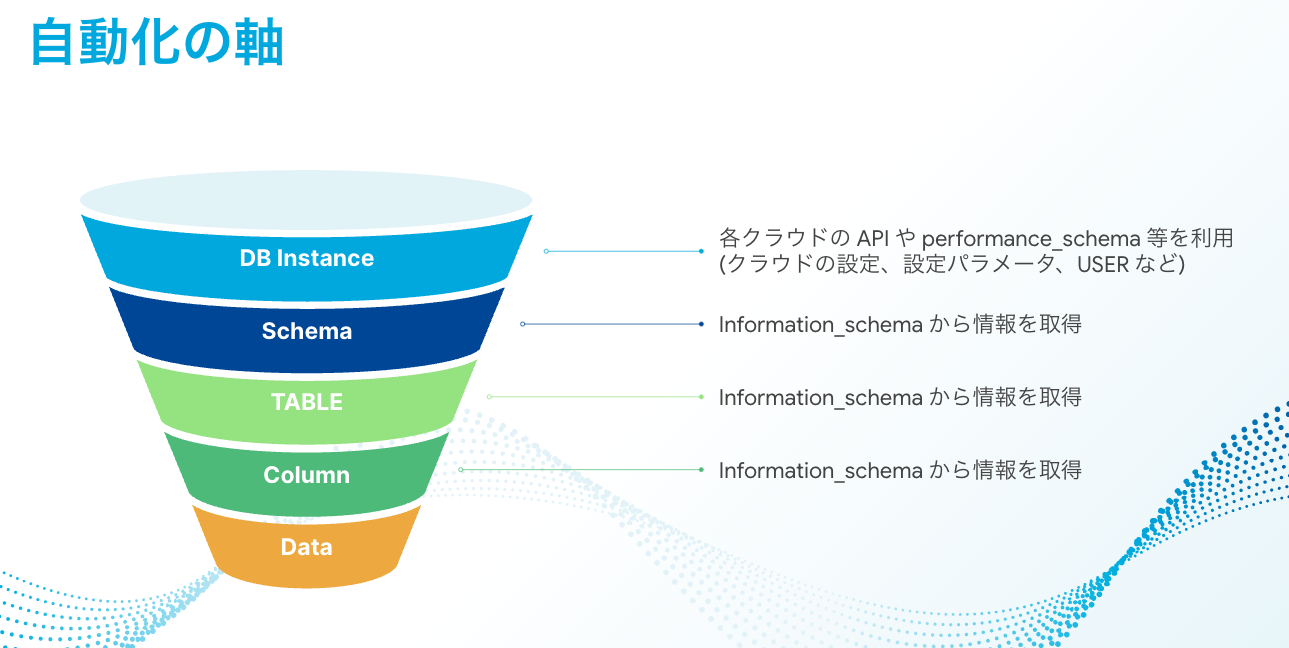
これらの情報を取得した上でスクリプト化します。例えば 「Schema、Table、Column の文字コードに utf8(utf8mb3) で構成されたオブジェクトが存在しない」を調べたければ下記のクエリを実行することで取得できます。
SELECT
SCHEMA_NAME,
CONCAT('schema''s default character set: ', DEFAULT_CHARACTER_SET_NAME)
FROM
information_schema.SCHEMATA
WHERE
SCHEMA_NAME NOT IN ('information_schema', 'mysql', 'performance_schema', 'sys', 'tmp') AND
DEFAULT_CHARACTER_SET_NAME in ('utf8', 'utf8mb3')
UNION
SELECT
CONCAT(TABLE_SCHEMA, ".", TABLE_NAME, ".", COLUMN_NAME),
CONCAT('column''s default character set: ', CHARACTER_SET_NAME) as WARNING
FROM
information_schema.COLUMNS
WHERE
TABLE_SCHEMA NOT IN ('information_schema', 'mysql', 'performance_schema', 'sys', 'tmp') AND
CHARACTER_SET_NAME in ('utf8', 'utf8mb3')
;
その他のステップ(Measure/Analyze/Improve/Control)
上記のようなクエリなどガイドラインを満たすための情報取得をスクリプト化したものを定期的に実行し、その結果が適切でないと判断された場合にはアラートを送る、それをガードレールとして機能させる Platform を構築します。そして取得した結果の可視性を高めるための Dashboard を用意し現場のエンジニアに対応してもらう、このサイクルを回すことが当面の僕の DBRE としての活動軸になると考えています。
このガードレールの仕組みの良い点は、例えば 「1秒以上 Slow Query のうち、フロントエンドからの Query が 1ヶ月の 99パーセンタイルで 0 になること」が KTC 内で必要とされるようになった場合には、そのルールを加えればそれだけで KTC で管理している全てのサービスに適用できることです。逆に不要になったルールを外すことも一括で可能となります。
これが僕の考えるスケールする Database ガードレールの構想です。
まとめ
いかがでしたでしょうか?今回は僕が KTC の DBRE としてスケールし、継続的な価値提供を生み出していくための一つの軸として考えている DBRE ガードレールについて紹介させていただきました。
まだまだ構築段階ですがこれまでのように Database 技術 を用いているわけではなく、その技術をどのように効果的に KTC に適用するのか、そしてビジネス価値に繋げるところまで考えた DBRE 組織を作っているところです。そう言った意味でも今はチャレンジの時期でアプリケーションエンジニアリングからクラウドエンジニアリングまで幅広く行なっています。
こういったことを一歩一歩積み重ねて継続して皆さんにアウトプットしていこうと思っていますので引き続きよろしくお願いします!
またこの活動に少しでも興味を持ったり話を聞いてみたい、と思った方はお気軽に Twitter DM 等でご連絡いただければと思います。
関連記事 | Related Posts



We are hiring!
【クラウドセキュリティエンジニア】クラウドセキュリティG/東京・名古屋・大阪・福岡
ミッションクラウドセキュリティの専門組織として、KINTO テクノロジーズのマルチクラウド環境のセキュリティガバナンスに責任を持ちます。 セキュリティリスクを発生させない セキュリティリスクを常に監視・分析する セキュリティリスクが発生したときに速やかに対応する 業務内容ミッションを達成するために様々な業務を実施します。
セキュリティエンジニア/サイバーセキュリティ G/東京・名古屋・大阪・福岡
募集ポジションについて本ポジションでは、セキュリティ・プライバシー部/サイバーセキュリティ グループに所属し、当社サービスおよび社内システムのサイバー防御強化に携わっていただきます。SOC運用や脆弱性管理を通じて、企業全体のセキュリティレベルを向上させる重要な役割を担うポジションです。


