Railway Oriented Programming Practice Using Rust

This article is the Day 13 entry for the KINTO Technologies Advent Calendar 2025 🎄
Introduction
I'm yuki.n (@yukidotnbysh) from the Master Maintenance Tool Development Team in the KINTO Backend Development Group, KINTO Development Division, based in the Osaka Tech Lab.
Our team develops management systems that integrate with various services. These systems serve not only as administrative tools but also as solutions to business issues.
To address these challenges, our management systems cannot be simple CRUD applications. Each system and its business requirements bring various complexities. I believed Railway Oriented Programming would be effective for handling these complexities in our business logic, so I introduced it in a project. Based on this case study, I would like to share the benefits we gained and the issues we faced.
What is Railway Oriented Programming?
Railway Oriented Programming is an error handling approach in functional programming proposed by Scott Wlaschin, who runs F# for Fun and Profit and authored Domain Modeling Made Functional. Looking at the article with the same title posted on F# for Fun and Profit, it seemingly have been published at least as early as 2013.
In Railway Oriented Programming, functions are compared to railways, with success and failure handling represented as two separate tracks.
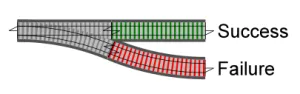
The following diagram shows multiple of these railways connected together.

Each processing step functions as a switch: if successful, processing continues on the success track; if it fails, it switches to the failure track. Once on the failure track, subsequent processing never succeeds, and the error flows through to the end.
Specifically, this involves chaining functions that return Result types through a pipeline.
Why Did We Adopt Railway Oriented Programming?
Our team already had experience developing with Rust, and we adopted it as the backend server development language for this project as well.
We designed the project architecture, according to the Clean Architecture diagram—for convenience, simply hereinafter referred to as Clean Architecture.
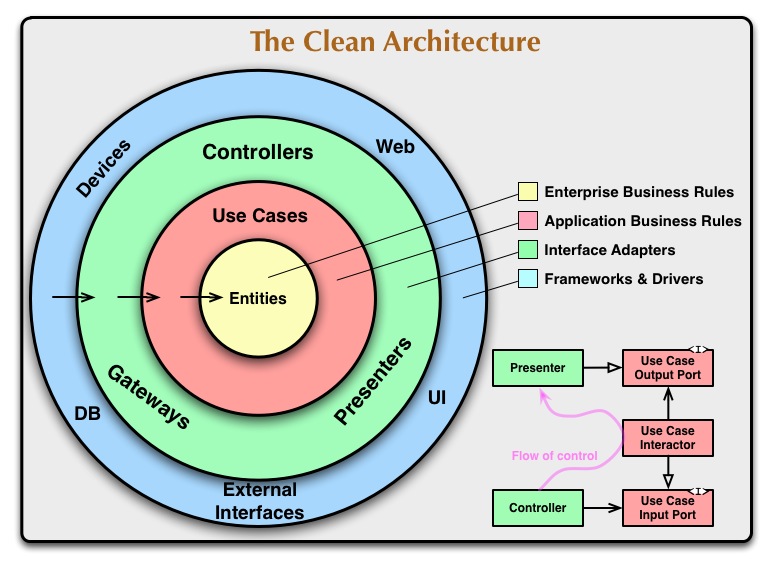
When we introduced Clean Architecture in past projects, we found that the processing in the Use Cases layer (as depicted in the circle diagram above) often results in an unnecessarily complex and clunky structure design. Even when we carved some processing as domain services to combine them into the Entities layer, the readability of the Use Cases layer still suffered.
In this situation, I learned about Railway Oriented Programming, which led to its adoption.
Railway Oriented Programming with Rust
Overall Structure
The Use Cases layer we implemented has roughly the following structure.
#[derive(Debug, thiserror::Error)]
pub enum CreateUserUseCaseError {
// Error type definitions
}
pub trait UsesCreateUserUseCase {
/// Workflow
fn handle(
&self,
input: CreateUserInputData,
) -> impl Future<
Output = Result<CreateUserOutputData, CreateUserUseCaseError>,
> + Send;
}
pub trait CreateUserUseCase:
// Dependencies
ProvidesUserFactory
+ ProvidesUserRepository
{
}
impl<T: CreateUserUseCase + Sync> UsesCreateUserUseCase for T {
async fn handle(
&self,
input: CreateUserInputData,
) -> Result<CreateUserOutputData, CreateUserUseCaseError> {
// Chain of functions defined in the railway module
}
}
mod railway {
type RailwayResult<T> = Result<T, super::CreateUserUseCaseError>;
pub(super) fn validate_input(/* ... */) -> RailwayResult<(Email, UserName)> { /* ... */ }
pub(super) async fn check_email_not_exists(/* ... */) -> RailwayResult<(Email, UserName)> { /* ... */ }
pub(super) fn build_user(/* ... */) -> RailwayResult<User> { /* ... */ }
pub(super) async fn save_user(/* ... */) -> RailwayResult<User> { /* ... */ }
pub(super) fn end(/* ... */) -> CreateUserOutputData { /* ... */ }
}
We use the Cake Pattern introduced in Thinking About DI in Rust — Part 2: Organizing DI Approaches Using Rust (only in Japanese) (I will omit the details as this diverges from the main topic of this blog).
We define functions in the railway module and combine them within the handle method of UsesCreateUserUseCase.
(Note: In Domain Modeling Made Functional, the part corresponding to the handle method is called workflow, and the arguments are called commands. This article follows that convention.)
Let's break down each of these elements.
Error Type Definition
#[derive(Debug, thiserror::Error)]
pub enum CreateUserUseCaseError {
// Error type definitions
#[error("Email address already exists.")]
AlreadyExistsEmail,
#[error("Invalid email address.")]
InvalidEmail,
#[error("Invalid username.")]
InvalidUserName,
#[error("UserFactoryError")]
UserFactoryError(#[from] UserFactoryError),
#[error("UserRepositoryError")]
UserRepositoryError(#[from] UserRepositoryError),
}
We always define one error type for each Use Case.
In Rust, error types can be defined as Enums. While the standard approach requires implementing the std::error::Error trait, using the thiserror crate simplifies error type definitions.
Additionally, when defining with the thiserror crate, setting the #[from] attribute implements the From trait, allowing automatic conversion to the target error type without explicit conversion when the corresponding error occurs.
RailwayResult Type
mod railway {
// Result type specific to this use case
type RailwayResult<T> = Result<T, CreateUserUseCaseError>;
}
Since defining Use Case-specific errors for all functions would be cumbersome, we define a RailwayResult type alias so we only need to specify the return value.
railway Module
mod railway {
/// Validates input values and converts them to value objects.
pub(super) fn validate_input(
input: CreateUserInputData,
) -> RailwayResult<(Email, UserName)> {
let email = Email::try_from(input.email)
.map_err(|_| CreateUserUseCaseError::InvalidEmail)?;
let name = UserName::try_from(input.name)
.map_err(|_| CreateUserUseCaseError::InvalidUserName)?;
Ok((email, name))
}
/// Confirms that the email address does not already exist.
pub(super) async fn check_email_not_exists(
(email, name): (Email, UserName),
impl_repository: &impl UsesUserRepository,
) -> RailwayResult<(Email, UserName)> {
impl_repository
.find_by_email(&email)
.await
.map_err(CreateUserUseCaseError::UserRepositoryError)?
.map_or(Ok((email, name)), |_| Err(CreateUserUseCaseError::AlreadyExistsEmail))
}
/// Creates a new user.
pub(super) fn build_user(
(email, name): (Email, UserName),
impl_factory: &impl UsesUserFactory,
) -> RailwayResult<User> {
impl_factory
.build(UserFactoryParams { email, name })
.map_err(CreateUserUseCaseError::UserFactoryError)
}
/// Saves the user.
pub(super) async fn save_user(
output: User,
impl_repository: &impl UsesUserRepository,
) -> RailwayResult<User> {
impl_repository
.save(output)
.await
.map_err(CreateUserUseCaseError::UserRepositoryError)
}
/// Returns the result and terminates processing.
pub(super) fn end(
output: User,
) -> CreateUserOutputData {
CreateUserOutputData {
user: output.into(),
}
}
}
We create a module called railway and define the functions that form the tracks within it.
This is not a Railway Oriented Programming convention but simply a guide we use for easier identification.
In the code for this blog, we assume the following process flows:
- Validate input values (email address and username)
- Check email address existence
- Create
Userentity - Save
Userentity - Convert the saved
Userentity to a DTO for passing to the upper layer, and end the process
Since the return value of the previous function is set as the input value for the next function, the first argument is named output.
However, when output is a tuple, we destructure it from the start. This is because handling tuples as-is causes issues with variable ownership.
Ideally, only the previous value should be set as the input for the next function, but we determined that the drawbacks outweighed the benefits—such as needing to pass unnecessary values as if through a bucket brigade. That is the reason we adopted a rule allowing new input values to be passed to each function.
Overall Workflow
The original programming convention uses F#, but Railway Oriented Programming is applicable in any language (or with libraries that supplement it) that has the concept of Result or Either types and the ability to compose functions.
Fortunately, Rust comes standard with the following features essential for implementing Railway Oriented Programming, in addition to the Result type:
?operator: Expresses stopping processing when an error occursmapandand_thenfunctions: Function composition
By combining these, you can build a pipeline as follows:
impl<T: CreateUserUseCase + Sync> UsesCreateUserUseCase for T {
async fn handle(
&self,
input: CreateUserInputData,
) -> Result<CreateUserOutputData, CreateUserUseCaseError> {
railway::validate_input(input)
.map(|output| {
railway::check_email_not_exists(output, self.user_repository())
})?
.await
.and_then(|output| railway::build_user(output, self.user_factory()))
.map(|output| railway::save_user(output, self.user_repository()))?
.await
.map(railway::end)
}
}
Benefits I Experienced in Practice
The following are the benefits I experienced from practicing Railway Oriented Programming.
Processing Flow Became Clear, Making Feature Addition Easier
Since the workflow contents are connected through a pipeline, you can understand at a glance what processing is being performed.
Of course, complex specifications inevitably lead to longer workflows, but even so, tracking the function flow helps us to roughly identify where and what is happening.
With each process in the workflow extracted into functions, the scope of each process and its variables also became clear.
This helped us add features simply by inserting new functions and modify them by changing the relevant function, which enhanced the system maintainability.
Processing Input/Output Can Now Be Expressed Through Types
I don't think this is a direct effect of Railway Oriented Programming, but we can now check by type level what data each function's arguments and return values represent.
As compile errors can prevent type mistakes, we are able to avoid problems where incorrect values are passed during processing.
Simplified Unit Test Scenarios
Since implementing all success and failure tests for workflows was extremely labor-intensive and time-consuming, we adopted an approach of thoroughly testing individual railway functions, then only testing the happy path for the workflows.
There may be controversies about whether tests for private functions are necessary, but I personally felt it was helpful to test each function in the railway module. So far, I haven't experienced any major problems with this approach.
Additionally, as a secondary effect, when features are added, we can confirm there are no issues by adding tests for those functions and ensuring existing tests pass, which I think was beneficial.
Issues I Experienced in Practice
While gaining benefits from practice, we also faced some issues.
Railway Oriented Programming Takes Some Getting Used To
For those already familiar with functional languages, this approach probably doesn't feel unusual, but of course there are team members, including myself, who are not. The approach implementation is difficult until you get used to the style of writing. In fact, I struggled quite a bit when examining whether Railway Oriented Programming could be implemented using Rust.
Currently, AI has significantly lowered the technical barriers for the implementation, but we humans still need to understand Railway Oriented Programming at some level to determine whether the outcomes are appropriately generated. That’s where supporting team members come in.
In practice, the process of reviewing outcomes placed a significant burden on us in the early development phase of this project. Depending on the project's situation and conditions—such as development scale and deadlines—we suggest that you seek another solution instead of Railway Oriented Programming.
We May Face fatal runtime error: stack overflow
Depending on what kind of process is executed, Stack Overflow errors may occur at runtime.
It is particularly troublesome because the error is not detected as a compile error, and you cannot determine which specific location contains issues just by searching around the source code.
To find the error cause, you can use rust-lldb to check the stack trace and identify the code where the Stack Overflow error occurred.
# Start binary with LLDB
rust-lldb target/debug/your-bin
# Execute
run
# Check backtrace when Stack Overflow occurs
thread backtrace all
When we address issues that are difficult to solve using a method chaining with map and and_then, we take an alternative solution to stop the method and write the processing line by line instead. This is the safest and easiest way to overcome tough issues.
async fn handle(&self, input: InputData) -> Result<OutputData, UseCaseError> {
railway::begin(self.uow()).await?;
let output = railway::validate_email(&input.email)?;
let output = railway::authenticate(output, input.password, self.authenticator()).await?;
let output = railway::update_last_access(output, self.user_repository()).await?;
let output = railway::commit(output, self.uow()).await?;
railway::end(output)
}
The above solution isn't bad in itself, but it eliminates the pipeline through method chaining, creating the risk that we can write codes on a no-holds-barred basis. So, I think it's safest to only switch to this format when we hardly solve issues.
As another option, you can expand the stack area by adding a value to the RUST_MIN_STACK variables. However, this merely postpones the issue and may cause the recurrence of the Stack Overflow errors. Therefore, I don’t recommend this solution.
In my case, the error occurred in debug builds in the meantime when I executed asynchronous processing within functions defined in the railway module.
async/await is syntactic sugar for the Future type, but, according to rust-lang/rust#132050, the state held by the Future type is expanded to the stack area at runtime, which causes Stack Overflow errors at the execution of many async functions.
In this case, I was able to avoid the error by storing the Future type data I wanted to simultaneously process into the Vec type data (because Vec type values are stored in the heap).
Increase in Codes in Return for Clarified Processing Flow
When introducing Railway Oriented Programming in Rust, you end up connecting each function with map and and_then. Additionally, you need to define each of those functions, so the overall code volume increases compared to the one when you usually write codes.
For example, if Railway Oriented Programming were not applied, the handle method would look like as follows:
impl<T: CreateUserUseCase + Sync> UsesCreateUserUseCase for T {
async fn handle(
&self,
input: CreateUserInputData,
) -> Result<CreateUserOutputData, CreateUserUseCaseError> {
// Input validation
let email = Email::try_from(input.email)
.map_err(|_| CreateUserUseCaseError::InvalidEmail)?;
let name = UserName::try_from(input.name)
.map_err(|_| CreateUserUseCaseError::InvalidUserName)?;
// Email duplication check
let existing_user = self
.user_repository()
.find_by_email(&email)
.await
.map_err(CreateUserUseCaseError::UserRepositoryError)?;
if existing_user.is_some() {
return Err(CreateUserUseCaseError::AlreadyExistsEmail);
}
// User creation
let user = self
.user_factory()
.build(UserFactoryParams { email, name })
.map_err(CreateUserUseCaseError::UserFactoryError)?;
// Saving user
let saved_user = self
.user_repository()
.save(user)
.await
.map_err(CreateUserUseCaseError::UserRepositoryError)?;
// Result conversion
Ok(CreateUserOutputData {
user: saved_user.into(),
})
}
}
Without functions, the implementation would be within the handle method (or with some functions partially extracted). Therefore, depending on the case, this approach might be simpler.
So for applications with simple processing and mostly branching, it may be safer to unnecessarily adopt Railway Oriented Programming.
P.S.: Where’s the Repository Pattern?
While not directly related to the main topic of this blog, Domain Modeling Made Functional addresses the repository pattern in a section named “Where’s the Repository Pattern?” The book states the pattern in the functional approach as follows:
“...when we model everything as functions and push persistence to the edges, then the Repository pattern is no longer needed.”
However, since I couldn't fully grasp the intent and method behind this, we adopted the repository pattern for the code and our project described in this blog.
Conclusion
This concludes my explanation about practicing Railway Oriented Programming in Rust.
Rust is an extremely expressive language with various features, and I feel that adopting Railway Oriented Programming can enhance it further.
If you consider adopting Railway Oriented Programming in Rust, I hope this article can serve you as a helpful reference.
関連記事 | Related Posts
Railway Oriented Programming Practice Using Rust
![Cover Image for [Server side Kotlin] エラーハンドリングにKotlin公式のResult型を使う](/assets/common/thumbnail_default_×2.png)
[Server side Kotlin] エラーハンドリングにKotlin公式のResult型を使う

KINTO FACTORY ローンチ半年記念:挑戦と学びの軌跡

Orval × Feature-Sliced Design で実現するルールベースなスキーマ駆動開発

入社1年未満メンバーだけのチームによる新システム開発をリモートモブプログラミングで成功させた話
[Server-side Kotlin] Using Kotlin’s Built-in Result Type for Error Management
We are hiring!
PjM(新規システムの構想検討とプロジェクト推進)/ プロジェクト推進G/東京・名古屋
業務内容トヨタグループ内でデジタル領域における業務改善やシステム化を推進していただくポジションです。現場に深く入り込み、実務と企画の両面から支援を行います。
【PdM】契約管理システム開発G/東京
契約管理システム開発グループについて契約管理システム開発グループは、クルマのサブスクリプションサービス『KINTO』(新車・中古車)を中心とした国内向けサービスにおいて、申込から契約満了(中途解約を含む)までの社内業務プロセスのシステム化と、契約状態の管理を担っています。


