Efforts to Implement the DBRE Guardrail Concept
Hello, this is Awache (@_awache), a Database Reliability Engineer (DBRE) at KINTO Technologies (KTC).
In this blog post, I would like to talk about the Database guardrail concept that I want to implement at KTC.
What are guardrails?
"Guardrails" is a term that is often used in Cloud Center of Excellence (CCoE) activities.
In a nutshell, guardrails are "solutions for restricting or detecting only realms that are off-limits, while ensuring as much user freedom as possible."
Based on the characteristics of the role of dealing with the realms of a database, where governance must be emphasized, DB engineers sometimes act as "gatekeepers" which hinders the agility of corporate activities.
Therefore, I am thinking about incorporating this "guardrail" concept into DBRE's activities to achieve both agility and governance controls.
Types of guardrails
Guardrails can be categorized into the three types below.
| Category | Role | Overview |
|---|---|---|
| Preventive Guardrails | Restrictive | Applies controls that render the operations in question impossible |
| Detective Guardrails | Detective | Mechanisms that discover and detect when an unwanted operation is carried out |
| Corrective Guardrails | Corrective | A mechanism that automatically makes corrections when unwanted settings are configured |
-
Preventive guardrails
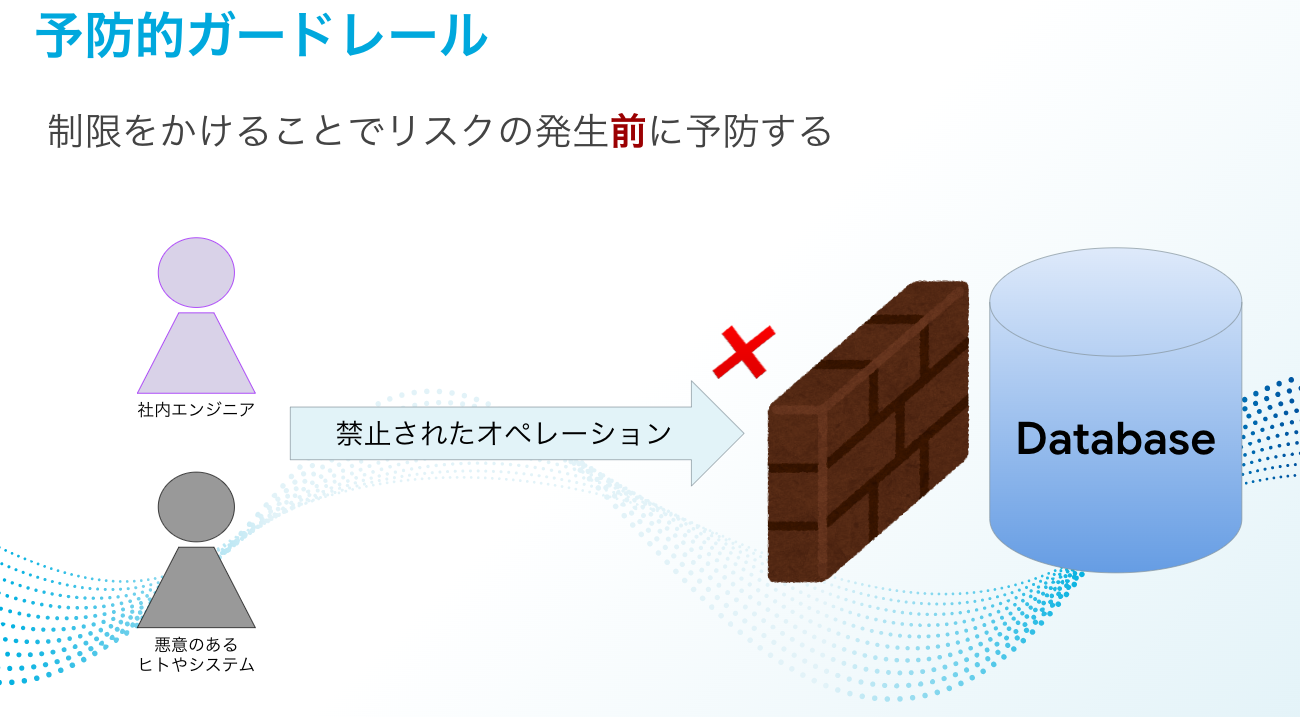
-
Detective guardrails
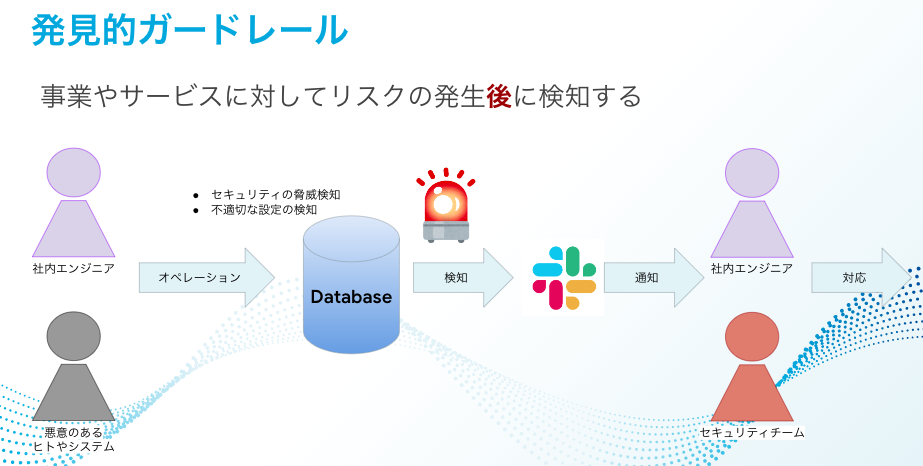
-
Corrective guardrails
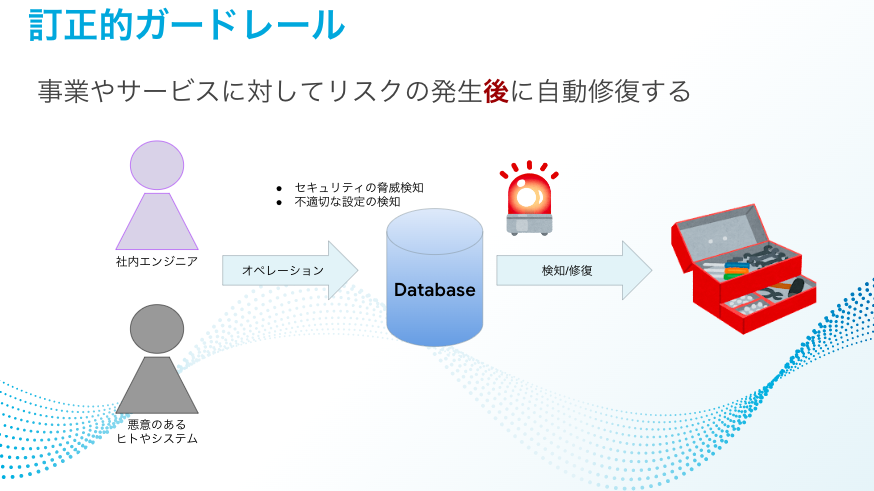
The guardrail concept
Applying strong restrictions using preventive guardrails starting from the initial introductory stages may lead to opposition and fatigue among on-site engineers because they will be unable to do what they have previously been able to do, as well as what they want to do.
Conversely, I think that if automatic repairs are performed using corrective guardrails, we may lose opportunities to improve engineers' skills in considering what settings were inappropriate and how to fix them.
That is why I believe that we are now in the phase of consolidating the foundations for ensuring as much freedom as possible for users and implementing governance controls. On top of that, I think it is preferable to introduce "detective guardrails."
Currently at KTC, we have introduced a 3-stage DEV/STG/PROD system, so even if the risk detection cycle is shifted to a daily basis using detective guardrails, in many cases they will be recognized before being applied to production. Inappropriate settings are periodically detected by detective guardrails, and the on-site engineers who receive them correct and apply them. If continuously repeating this cycle leads to a rise in service levels, the value of this mechanism will also go up.
Of course, we do not stop at providing detective guardrails; it is also important to keep updating the rules that are detected there according to the situation on the ground. We need to further develop this mechanism itself together with KTC by working with on-site engineers to provide guardrails that match the actual situation at KTC.
Strong backing by executive sponsors
If we do not make headway with the idea of "responding to things detected by guardrails according to the error level," we will only increase the number of false alarms. I also consider it an anti-pattern to allow for this rule to not correspond to the circumstances of individual services.
Therefore, the important thing should be "to incorporate only the rules that should be observed at a minimum as long as we provide services as KTC."
This mechanism is pointless if we cannot spread the word and get all of KTC's engineers to collectively understand this single point: if an alert is raised by a guardrail, we will respond according to the error level without defining overly detailed rules.
Therefore, the person pushing this forward for us is our executive sponsor, who is supporting our activities. It is desirable that the executive sponsor be someone with a role that sets the direction of the company, such as someone at the management level or a CXO.
At first, no matter how careful we were, the essential point of enforcing rules on on-site engineers would not change. So the fact that company management has committed to this activity via the executive sponsor should act as one of the reasons and motivations for them to cooperate.
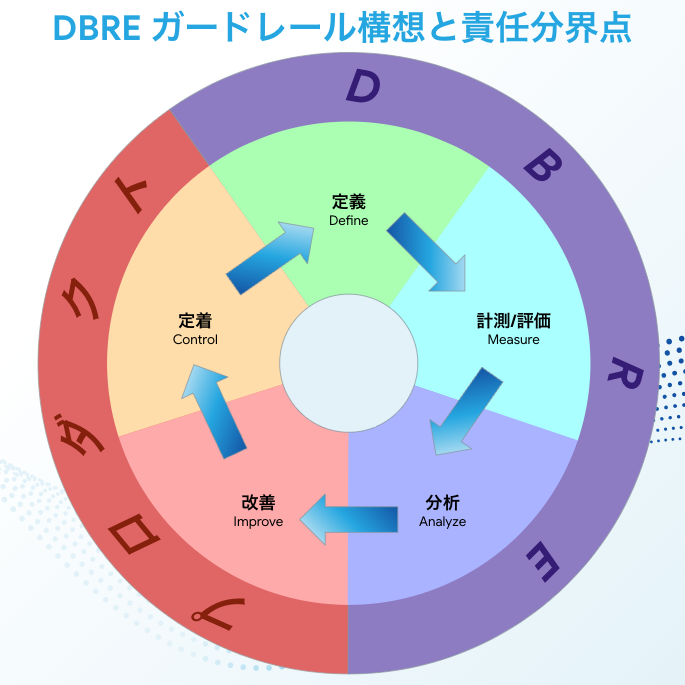
Demarcation points for responsibilities
As a cross-organizational organization, KTC's DBRE does not operate the service directly. Therefore, it is necessary to clarify where the DBRE's responsibilities begin and end and where the on-site engineers' responsibilities begin and end.
I have thought about using a framework called DMAIC for this. Regarding DMAIC, I think that it is laid out in a very easy-to-understand way in this video—"What is DMAIC: Define, Measure, Analyze, Improve, Control. Winning patterns for business flow improvement projects (Lean Six Sigma)"—so please take a look.
Below is a rough description of who is responsible for what and what should be done, in terms of this 5-step procedure.
| Definition | Description | Operation | Final Responsibility |
|---|---|---|---|
| Define | Define the scope and content of what to measure/evaluate | Documentation Scripting |
DBRE |
| Measure | Performing measurements/evaluations and collecting the results | Running scripts | DBRE |
| Analyze | Analyzing/reporting results | Increasing visibility of the entire organization | DBRE |
| Improve | Improving flaws/drafting improvement plans | Implementing smooth solutions to problems | Product |
| Control | Checking outcomes and aiming to control them | Maintaining a healthy state as a service | Product |
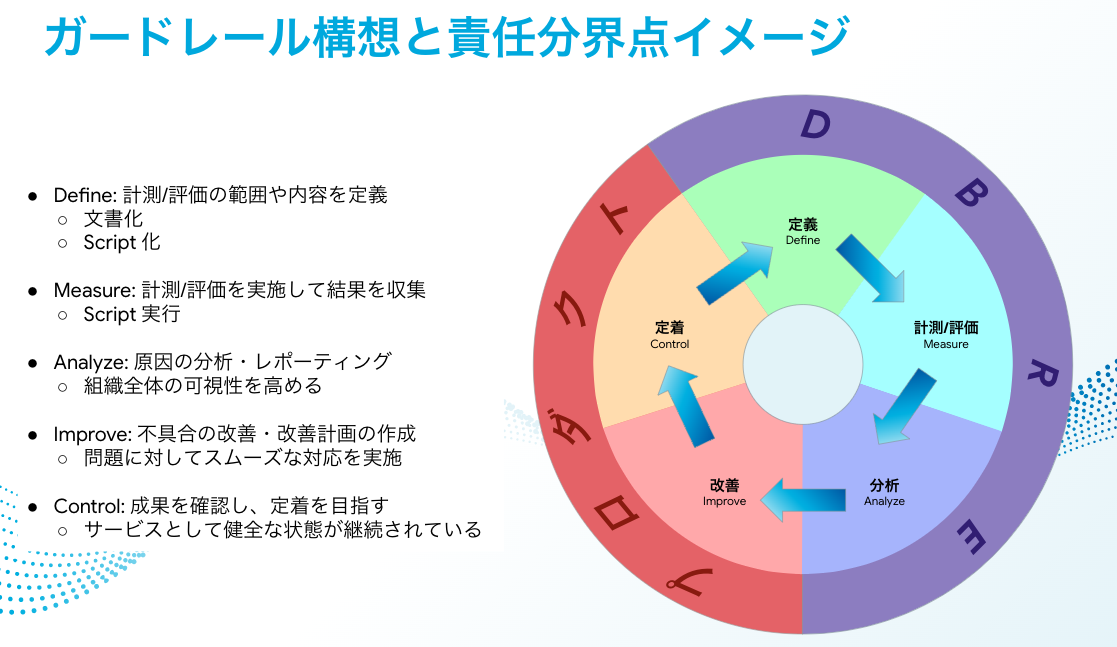
While this diagram clarifies each role, it also shows who holds final responsibility while people work with each other in consultations and improvements in all of these steps. For example, I would like to add that this does not mean that DBRE does not in any way support efforts geared toward on-site improvements and controls.
How to construct guardrails
So far, I have described the concept at length up to the construction of guardrails, but from here on I will illustrate specific efforts.
[Define] Defining error levels
Defining the error level first is the most important thing.
The error level is the value that this guardrail provides to KTC. No matter how much the DBRE thinks something "must" be done, if it does not meet the defined error level, it will be relegated to a Notice or be out of scope. I can be accountable to the on-site engineers by personally ensuring that the rules that have been set are checked against their definitions, and I can control my desire to "mark everything as critical."
I have set the specific definitions as follows.
| Level | Definition | Response speed |
|---|---|---|
| Critical | Things that may directly lead to security incidents Critical anomalies that go unnoticed |
Immediate response |
| Error | Incidents related to service reliability or security may occur Problems in the database design that may have negative impacts within about 1 year |
Response implemented within 2 to 3 business days |
| Warning | Issues that, by themselves, do not directly lead to service reliability or security incidents Issues that include security risks but have limited impact Problems in the database design that may have negative impacts within about 2 years |
Implement planned response |
| Notice | Things that operate normally but are important to take note of | Respond as needed |
[Define] Specific content arrangement
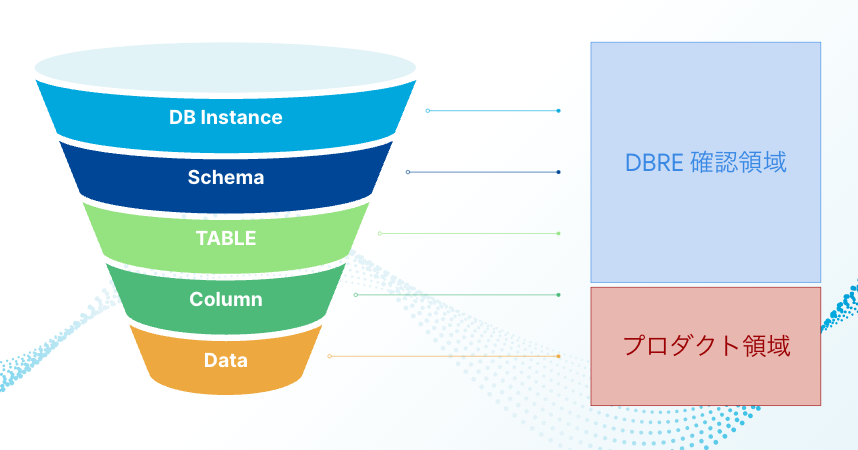
Next, we will consider creating guidelines among the defined rules, but if we try to look at the entire database from the outset, we will fail. Therefore, in the first step, I have set the scope of the guardrail as "the extent to which that one can generally handle things on one's own." "The extent to which that one can generally handle things on one's own" means the extent to which things can be done without deep domain knowledge of the service currently running, such as setting up a database cluster (KTC uses Amazon Aurora MySQL for the main DB), configuring DB connection users, and setting schema, table, and column definitions. On the other hand, the areas without intervention by guardrails at this stage are schema design, data structure, and Queries, etc.
In particular, the point here is that "workarounds when a Slow Query occurs" is not set as a guardrail. Slow Query can be a very important metric, but it is difficult to address without deep service-level domain knowledge. If a large number of them occur at this stage, it is difficult to know where to start and how to continue to address them reliably and in a timely fashion according to the error level.
Regarding Slow Queries, I would like to think step by step, by visualizing Slow Queries so as to enable anyone to check the situation, then defining the SLO as the one to address them, and try out individual proposals from the DBRE.
- Image of realms checked using guardrails
[Define] Setting guidelines/implementing scripting
After deciding upon the defined error levels and the range of interventions, I will apply them to the guidelines. Thus, I can automatically detect what has been agreed upon. Here are some of the guidelines I created.
| Item to check | Error Level | Reason |
|---|---|---|
| Setting database backups is effective | If backups are not set, it will result in an Error | Backups are an effective measure against the risk of data loss due to natural disasters, system failures, or external attacks |
| The backup retention period is long enough | If the backup retention period is less than 7, it will result in a Notice. | A certain period of time is needed to recover from a serious loss. There is no general definition of how much time is enough. Therefore, I have set the defaults for AWS's automatic snapshot feature. |
| Audit Log output is valid | If the Audit Log settings have not been configured, it will result in Critical status | Leaving a log in the Database of who did something, what was done, and when it was done will enable a proper response to data losses and data leaks |
| Slow Query Log output is valid | If Slow Query settings are not configured, it will result in Critical status | If the Slow Query settings are not valid, it may not be possible to identify Queries that cause service disruptions |
| There is no object that uses utf8(utf8mb3) as the character set for Schema, Table and Column content | If there is no object that uses utf8(utf8mb3) as the character set for Schema, Table and Column content, it will result in a Warning | There will be strings that cannot be stored in utf8(utf8mb3) It is also mentioned that they will be excluded from MySQL support in the near future. |
| There are Primary Keys in all tables | If tables without Primary Keys are used, it will result in a Warning | Primary Keys are necessary for uniquely identifying what the main body of that scheme is for and structurally identifying the records |
| There are no Schema, Table or Column names consisting only of strings that are reserved words. | If there is a name composed only of reserved words, it will result in a Warning | We are planning to render names consisting only of reserved words as unusable in the future or to require that they must always be enclosed in backquotes (`). See 9.3 Keywords and Reserved Words for a list of reserved words |
These are within the range that can be acquired from information from AWS's API and Information Schema (some mysql Schema and Performance Schema).
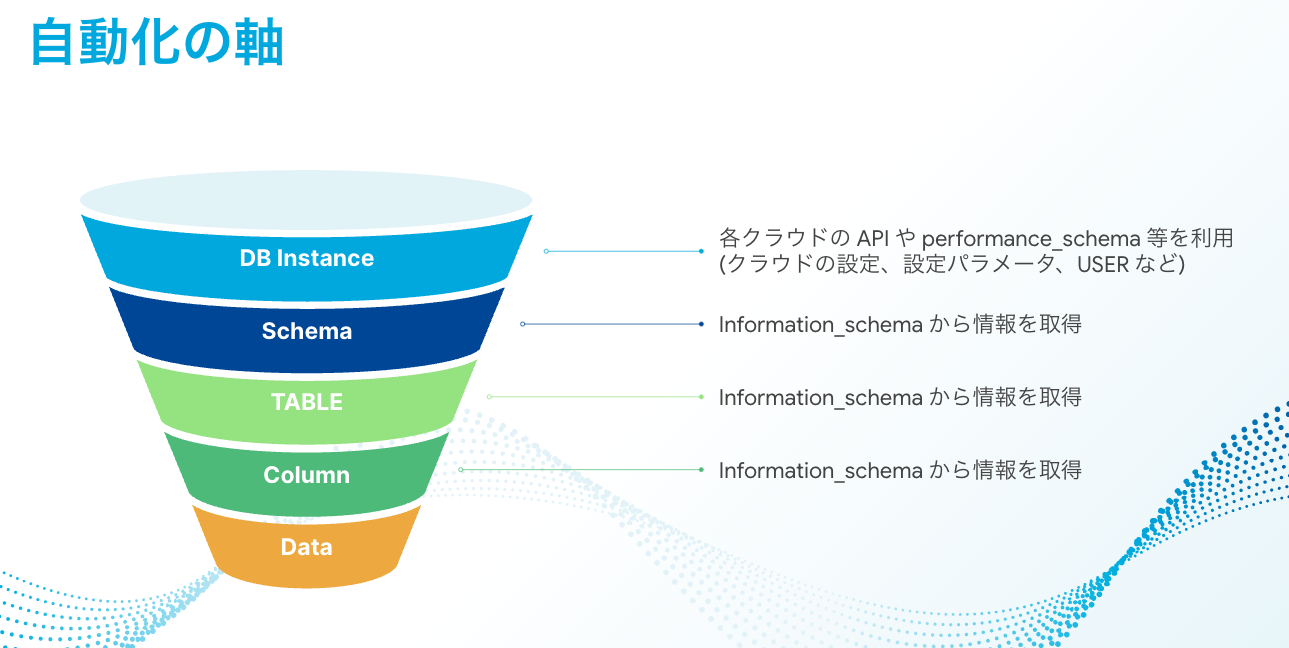
Script this information after acquiring it. For example, if you want to check if "there is no object that uses utf8(utf8mb3) as the character set for Schema, Table and Column content," you can obtain that information by executing the following query.
SELECT
SCHEMA_NAME,
CONCAT('schema''s default character set: ', DEFAULT_CHARACTER_SET_NAME)
FROM
information_schema.SCHEMATA
WHERE
SCHEMA_NAME NOT IN ('information_schema', 'mysql', 'performance_schema', 'sys', 'tmp') AND
DEFAULT_CHARACTER_SET_NAME in ('utf8', 'utf8mb3')
UNION
SELECT
CONCAT(TABLE_SCHEMA, ".", TABLE_NAME, ".", COLUMN_NAME),
CONCAT('column''s default character set: ', CHARACTER_SET_NAME) as WARNING
FROM
information_schema.COLUMNS
WHERE
TABLE_SCHEMA NOT IN ('information_schema', 'mysql', 'performance_schema', 'sys', 'tmp') AND
CHARACTER_SET_NAME in ('utf8', 'utf8mb3')
;
Other steps (Measure/Analyze/Improve/Control)
I will build a platform that periodically executes a scripted information acquisition query to meet the guidelines, such as the above query, and sends an alert if the result is determined to be inappropriate, which functions as a guardrail. Then I think that, for the time being, my activities as DBRE will be centered on returning to this cycle of preparing a dashboard to increase the visibility of the obtained results and having engineers on site respond.
The good thing about this guardrail mechanism is, for example, when it becomes necessary within KTC to set a rule that "among the Slow Queries that take 1 second or more, the percentage of queries from the front-end will go from 99 percent per month to 0 percent," if that rule is added, it alone can be applied to all services managed by KTC. Conversely, it is also possible to remove unnecessary rules all at once.
This is my concept of scalable database guardrails.
Summary
What do you think? In this blog post, I introduced the DBRE guardrails, which I consider as one axis around which we can perform scaling as KTC's DBRE and create a continuous value provision.
Although it is still in the construction stage, it does not use database technology as has been done up to now, and we are on the verge of creating a DBRE organization that takes into consideration how to apply this technology effectively at KTC and even how to link it to our business values. In that sense, we are now in a challenging time, and we are expending into a wide range of things, from application engineering to cloud engineering.
We want to build up these things step by step and continue to output them to everyone, so please continue to support us!
Also, if you are interested in this activity or would like to hear more about it, please feel free to contact me via Twitter DM.
関連記事 | Related Posts



We are hiring!
【SRE】xRE G/東京・大阪・名古屋・福岡
xREグループについてxREグループは、SRE / DBRE の専門性を活かしながら、プロダクト横断で信頼性・運用品質・開発生産性の向上を支える組織です。私たちは、単一プロダクトの信頼性改善にとどまらず、その知見を抽象化し、トヨタグループ全体に展開することで「信頼性の標準」を定義することを目指しています。
ビジネスデベロップメントスペシャリスト(シニア) / ビジネスディベロップメントG/東京
ビジネスディベロップメントGについてビジネスディベロップメントGは、トヨタグループが世界で展開するモビリティサービスを“仕組み”と“テクノロジー”の力で成長させていくチームです。モビリティサービスの中核を担う車のFull Service Leaseや、それ以外のサービスにおけるグローバルプロジェクトに関わります。

