ついに(一部で)EKSを入れたお話 - OpenSearchのEOLに伴うリプレイスを添えて -

こんにちは。プラットフォームGでPlatformEngineeringの考え方をベースにツール周りの開発・運用・展開の役割(とエンジニアリングマネージャーと本格的にアプリケーション開発もやり始めて、よくわからなくなった)島村です。
この記事は KINTOテクノロジーズアドベントカレンダー2025 の14日目の記事です🎅🎄
社内モニタリング基盤をリプレイスするにあたって、ECSやManagedServiceではなく、EKS上に構築した話についてお話しをします。
背景
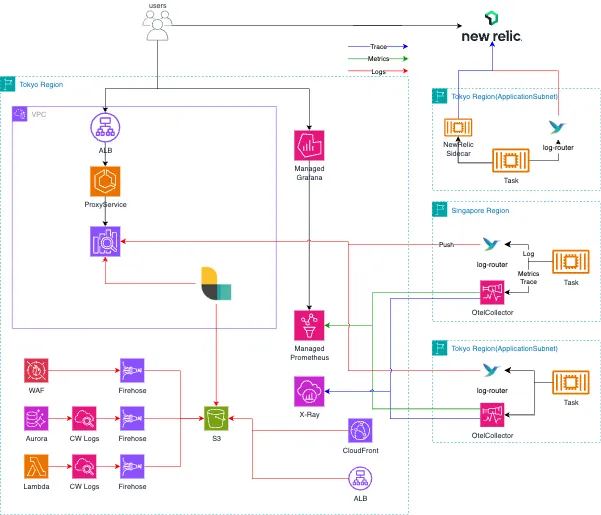
弊社では元々、
- 社内モニタリング基盤
- OpenSearch (Log + Alert + Visualization)
- Managed Prometheus (Metrics)
- Managed Grafana (Alert + Visualization)
- X-Ray (Trace + Visualization)
- SaaS
- NewRelic (ALL)
となっていました。基本、そんなに監視運用レベルが求められないものはモニタリング基盤、ガッツリ色々見たい+関連サービスがあるものはNewRelicというような感じです。
OpenSearchについては、本当はバージョン追従をするべきなんですが、古いままで運用し、2025/11についにEOLになりました。
コストや運用の手間を減らす目的と、AIのベクトルストアで使えるか確認のため、Serverlessの検証なども行ったんですが、「確認の際に横断的に見えないというのは課題だ」、ということで、全体的な刷新を行うことにしました。
合わせて、RCA(RootCauseAnalysis)の情報取得元としても使いやすくしようということで、関連プロジェクトとしてプロジェクト化しました。
(RCAの概要はこちらのイベントのLT参照)
まずはStackを決める
まず、弊社のワークロードの基本構成はECS+Fargateです。AWS上に環境を作る場合、PackModuleと呼ばれているTerraformのモジュール群があります。→過去参考動画
なので、ECSをベースに考えたのですが、制限事項も多いことから、まずは求められること(要件)を整理しました。
したいこと
- 横断的にLog/Metrics/Traceが可視化できること
- (リソース、ライセンス的に)安価であること
- 切り替えが容易であること
- Fluentbitでログを、AdotCollectorでMetrics/Traceを転送している部分を大きく変更しない。
- 永続ログはS3に保存できること
- モニタリング基盤から保存ではなく、途中でAWSコンポーネントからの転送でもOK
- NewRelicより可能なら長く検索できる期間があること
特に、2番目については、NewRelicというSaaSツールも既にありますから、使用するアプリケーションユーザ側の予算的に今までより高価になると意味がありませんでした。
しないこと
こちらも重要だと思います。最低限必要なものを整理して、あれもこれも…とやると時間と手間が増えます。
- AWSのアカウントは既存と同じにする
- 運用アカウント分割を過去は検討したが、現状ではやらない
- CloudInfraチームやSCoEなど、アカウント増やすなら関係各所が増えるのと、アカウント自体のセキュリティールールの運用のため
- Profile可視化(Pyroscope)
- アプリケーション担当者へのトランスファーや運用手順が増える
- S3にある永続ログを検索できるように戻したりとかはしない
- 生成AI周りの監視基盤
- 最終的にはLangFuseが生えましたが、最初の時点ではスコープ外
決まったこと
使うOSS
| 名称 | 機能 | 概要 |
|---|---|---|
| Loki | Log保存 | ログ保存。OpenSearchのOSSやElasticも悩みましたが、全体揃ってるので基本GrafanaLabs系で統一 |
| Tempo | Trace保存 | トレース保存 |
| Grafana | 可視化 | 各種可視化とアラート。Grafanaの構築単位は任意のアプリ群にしました |
| Alloy | AWSログ転送 | Lambda/WAF/RDS系のログがKinesisFirehose(HTTP)からAlloyを経由してLokiに転送 |
| Thanos | Metrics保存 | Mimirではなくこちらで。メンバーのナレッジがあったため |
| 自作Logger | AWSログ転送 | ALB/Cloudfrontの、S3にしか出力できないログの転送用。現行はLogStashを使用 |
| ArgoCD | GitOps | GitOpsのためこちらを選択 |
制限事項
- Thanos/MimirともにNFSをサポートしてないので、ECS+Fargateだと厳しい
- CNDW2025でLokiをECS+Fargateで構築した人がいらっしゃったんですけど、コンポーネントとか考慮点が多い
- Grafana系だとLoki以外はDockerでのDeploy手順が公式でサポートされていない
- Prod環境だとHelmかTankaでのデプロイメントが推奨
あ、EKSで動かすしか無いか…
もともと、EKSはアプリケーション要件があれば導入を検討しようという話もありました。そのため、ちょうど良い機会としてEKSを実行サービスとして決めました。ただ、Webアプリケーションを動かしているワークロードについてはECSのままとしています。
PlatformEngineeringTeamとして、CICDのテンプレートやその他ツール群を提供していますが、アプリケーション部門にEKSを提供するメリットがあまり見えなかったことと、提供のための各種修正を考慮した結果です。
構成
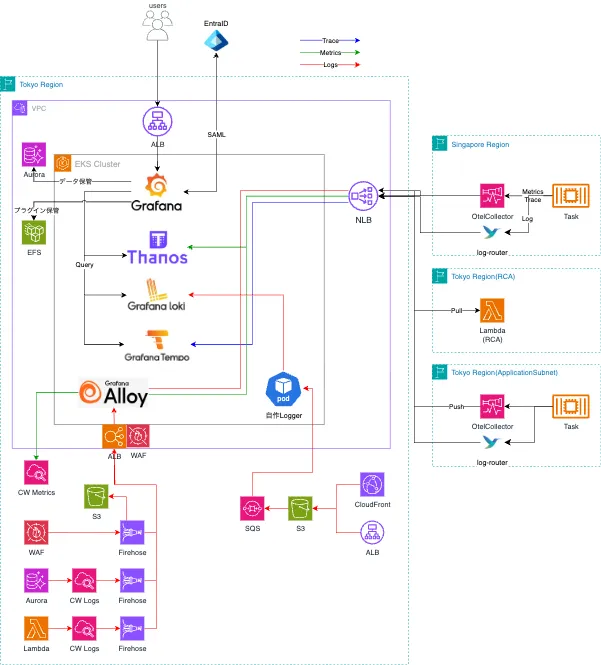
※NewRelic経路は変わらないので割愛
AWSコンポーネント
この時点で、ちょうどEKSにAutoModeが発表されました。制限事項の1つ目のEFSの対応という点では、EKS+Fargateでも対応不可だったので、AutoModeを使ってみようということになりました。
AutoModeでも、ARM64を指定した設定ができ、起動するEC2のインスタンスが安価になるので、構築後にArmアーキテクチャのNodePoolを設定しています。
EKS構築以外の新モニタリング基盤の推進に向けたおしごと
PackModuleの修正
最初の方にあった、Moduleの修正です。
意識しないと移行しない(=Default値が変わらないようにする)形で修正しました。
- KinesisFirehose(HTTPエンドポイント向け)のModule作成
- Backupの取得をALLにしてS3へ保存(要件4に関連する)
- 呼び出す各コンポーネントModuleの修正
- Lambda
- WAF
- RDS
セキュリティー調整
Firehoseですが、VPC内部に作成されないので、Alloyの前段のALBにインターネット経由での通信経路となります。その場合、さすがに認証認可もなしでALBにログを送るのもNGでしたので、Headerでの認証を追加しました。
構築時にSecretManagerにKEYを保存して、Firehoseからはそれを付与して送信。ALBではその値とマッチしているか?と確認しています。
コンテナの脆弱性を検知する仕組みをECR+通知で作っており、DockerHubから直接呼び出さずに、ECRに一時的に保管する運用も行なっています。が、かなり運用負荷が高いので、どうにかしたいのが課題となっています。
移行のお願い
一番泥臭く、CustomerSuccessEngineerチーム(CSE)が各担当にお声がけをしてチケットを切って管理する形で行なっています。一部は開発タスク優先で期限からはみ出ましたが、多くのプロダクトはありがたいことに協力いただき、年内での切り替えを想定しています。
アプリケーションの担当者の変更作業としては
- Fluentbitの使用バージョンの変更(LokiPlugin向け)
- 各種Configの修正
- AdotCollector
- ECS TaskDefinition
こちらは、PlatformGでConfluenceに作業手順を準備して、提供しています。
Firehoseなどの切替は、アプリケーション担当者と日程を調整し、PlatformGとCloudInfraGでTerraformの修正という形で行なっています。
おまけ
アカウント分割の対応
移行中ではあるんですが、社内のAWSアカウントの最適化が進んでおり、そちらの変更反映も実施する予定です。
ただ、EKSの前にはNLB/ALBを挟んでいるため、VPCPeeringかVPCEndpointによる対応で済む見込みです。
(´・ω・) 運用アカウントに分割する日は、何時来るのかな
LLM監視や追加機能のデプロイ
RCAのためのLangFuse、実行時間やメモリなどの関係からCode分析機能がLambdaをやめてEKS上に移行、AWSメトリクス収集のためのYACEのデプロイなど、モニタリング・RCA関連が色々と追加で載るようになりました。
所感
基本、機能要件とか技術制限など、何かしらの理由がない場合は、AWSでコンテナなどを動かすにはECSで十分だと思います。実際、n8nとか他のOSS系はECSで起動するようにしています。
新しくジョインしたメンバーがEKSと各種Grafanaスタックに経験が多かったこともあって、ある程度、スムーズに構築や移行できたこともあります。
ただ、AutoModeの運用経験や、実際に各環境のログなどを投入していくと問題、エラーなどが出てきました。安定運用までに色々と手を打たないといけないと考えています。
やはり、K8s運用は一筋縄ではいかないと実感しました。
さいごに
PlatformEngneeringチームは、社内向けの横断ツールを統制して必要なものを開発しています。
必要なものを新規作成や既存のものをマイグレーションしたり、ツールを使ってもらうためのEnablingの活動や、マーケティング技術を使った内部展開などのチームもあります。
GoldenPathの整理(そもそも業務フローの可視化・改善)も実施していく予定です。
こういった活動に少しでも興味を持ったり話を聞いてみたいと思った方は、お気軽にご連絡いただければと思います。
関連記事 | Related Posts



We are hiring!
【クラウドエンジニア】Cloud Infrastructure G/東京・大阪・福岡
KINTO Tech BlogWantedlyストーリーCloud InfrastructureグループについてAWSを主としたクラウドインフラの設計、構築、運用を主に担当しています。
【クラウドプラットフォームエンジニア】プラットフォームG/東京・大阪・福岡
プラットフォームグループについてAWS を中心とするインフラ上で稼働するアプリケーション運用改善のサポートを担当しています。




