TanStack Queryのキャッシュ周辺の挙動を理解してみた

この記事は KINTO テクノロジーズ Advent Calendar 2025 の 16 日目の記事です 🎅🎄
はじめに
こんにちは!
KINTO 開発部 KINTO バックエンド開発 G マスターメンテナンスツール開発チーム、技術広報 G 兼務、Osaka Tech Lab 所属の high-g(@high_g_engineer)です。フロントエンドエンジニアをやっています。
現在、筆者はプロジェクトで TanStack Query を利用しています。
TanStack Query は、 useQuery や useMutation のおかげで、 React Hooks を扱う感覚でデータの取得・更新が可能で非常に便利なライブラリです。
しかし、キャッシュの扱いで少し癖があり、理解が浅いと、以下の様な挙動に振り回されてしまいます。
- データをキャッシュで賄えるはずの場面で無駄にフェッチしてしまっている
- サーバーのデータを更新したはずなのに、古い情報が画面に表示されてしまっている
- 闇雲にキャッシュ削除を連発してしまっている
本記事は、こういった挙動に振り回されないように、TanStack Query の公式ドキュメントを読んで、 筆者自身がキャッシュ周辺の挙動を理解するため の内容となっております。
本記事の構成
- TanStack Query とは?
- TanStack Query のキャッシュの基本である
staleとgcを理解する - TanStack Query のキャッシュの挙動を理解する
- クエリの無効化
- ミューテーション時のクエリの無効化
- プロジェクト内でよく利用している
QueryClientのメソッドの紹介
TanStack Query とは?
本記事では、TanStack Query v5 の利用を前提にしています。
TanStack Query(旧 React Query)は、フロントエンドアプリケーションにおけるサーバー状態管理のためのライブラリです。
サーバー状態とは、API から取得するデータのように、アプリの外部に存在し、非同期で取得・更新が必要なデータのことです。
以下を非常にシンプルなコードで実現してくれます。
- データ取得&データ更新のシンプル化
- キャッシュ管理
- バックグラウンド更新
- ローディング・エラー状態の管理
TanStack Query のキャッシュの基本である stale と gc を理解する
まず、TanStack Query のキャッシュの挙動を理解するために、stale(古いデータ) と gc(ガベージコレクション) について理解する必要があります。
以下の記事が TanStack Query のキャッシュを理解するうえで一番最初の入口として読むべきドキュメントです。
stale について
staleとは、「古くなった」または「更新が必要な可能性がある」状態のデータを指しますuseQueryまたは、useInfiniteQueryのようなデータ取得系のフックは、デフォルトでクエリ(※)のデータをstaleとして扱いますstaleは、staleTimeを設定することで再フェッチの頻度を制御できますstaleTimeのデフォルトは 0 なので、データ取得直後にstaleとなりますstaleなデータは、新しいクエリのマウント、ウィンドウの再フォーカス、ネットワーク再接続時に自動で再フェッチされます
※ クエリとは、取得データ、状態、メタ情報、キー、データ取得関数をひとまとめにした管理単位のことです。
gc について
- 使用しなくなったキャッシュを削除する機能のことです
useQuery,useInfiniteQueryはアクティブなインスタンスがなくなった場合、「非アクティブ」というラベル付けが行われ、再使用される場合に備えてキャッシュに残ります- 「非アクティブ」の場合、デフォルトだと、5 分後に
gcされます gcTimeを設定することで、gcが発生するまでの時間を変更できます
stale と gc について、 staleTime と gcTime(v4 より以前は cacheTime という名称) をもとに考えると分かりやすいです。
staleTime → クエリを再取得するまでの時間
gcTime → gc するまでの時間(キャッシュにメモリを保持する時間)
staleTime が過ぎても、クエリはキャッシュに残っていますが、gcTime が過ぎると、クエリがキャッシュから消えるということになります。
それ以外の細かいオプションなども書かれてはいますが、 TanStack Query のキャッシュの基本を理解するために、まずは stale と gc が理解できていれば問題ないと思います。
TanStack Query のキャッシュの挙動を理解する
以下のドキュメントでは、TanStack Query の useQuery がクエリのデータをキャッシュ、キャッシュしたデータの利用、そして gc するまでの流れが解説されています。
useQuery は、 useQuery({ queryKey: ["todos"], queryFn: fetchTodos }); といった記述が基本になりますが、こちらがどのように動作するかを順番に解説します。
本題の前に useQuery の基本コードを簡単に紹介
キャッシュの挙動理解の本題に入るまでに、useQuery を利用した簡単なサンプルを紹介します。
useQuery が利用される場合、以下のようなコードが記述されることが一般的です。
// データ取得関数
const fetchTodos = async () => {
const response = await fetch("/api/todos");
return response.json();
};
// コンポーネント内で使用
const TodoList = () => {
// useQuery の記述
const { data, isPending, error } = useQuery({
queryKey: ["todos"],
queryFn: fetchTodos,
});
if (isPending) return <p>読み込み中...</p>;
if (error) return <p>エラーが発生しました</p>;
return (
<ul>
{data.map((todo) => (
<li key={todo.id}>{todo.title}</li>
))}
</ul>
);
}
useQuery の引数として与えられているオブジェクトには、 queryKey と queryFn というプロパティがありますが、それぞれについては以下の意味があります。
queryKey → キャッシュを識別するためのキー。配列で指定。同じキーを持つクエリはキャッシュを共有
queryFn → データをフェッチするクエリ関数
TanStack Query のキャッシュの一連のライフサイクルを理解する
ここまで出た queryKey, stale, gc を元に useQuery のキャッシュ周辺の流れを整理すると、以下のようになります。
1. 初回の useQuery({ queryKey: ['todos'], queryFn: fetchTodos }) を実行
まだ、queryKey: ['todos'] に紐づけられたクエリのデータが存在しないため、データを取得する為に queryFn で指定された fetchTodos を実行します。
クエリ関数の実行が完了すると、レスポンスは、 ['todos'] キーのもとにキャッシュされます。
staleTime はデフォルトで 0 なので、この時のデータは即座に stale になります。
2. 再度、 useQuery({ queryKey: ['todos'], queryFn: fetchTodos }) を実行
この時、['todos'] キーのもとにキャッシュされたデータが stale として存在するため、stale なデータがレンダリングに利用されます。
それと同時に queryFn で指定された fetchTodos がバックグラウンド実行されます。
クエリ関数の実行が完了した時点で、キャッシュが新しいデータで更新されます。(初回と同じく、staleTime が 0 なので、即座に stale になります)
そして、この時点で更新されたデータを元にまたレンダリングが更新されます。
3. useQuery({ queryKey: ['todos'], queryFn: fetchTodos }) がマウント解除され、使用されなくなる
この時、アクティブなインスタンスがなくなったため、クエリは「非アクティブ」のラベルが付与され、gcTime を利用して、gc を実行するための時間設定を行います。
gcTime のデフォルトは 5 分なので、何もなければ、5 分後に ['todos'] キーに紐づいたキャッシュデータは gc されますが、5 分以内に再度useQuery({ queryKey: ['todos'], queryFn: fetchTodos }) が実行されるようなことがあれば、gc のタイマーはリセットされ、同じ様な流れでキャッシュの更新が行われます。
一連のライフサイクルを図示すると以下のようになります。
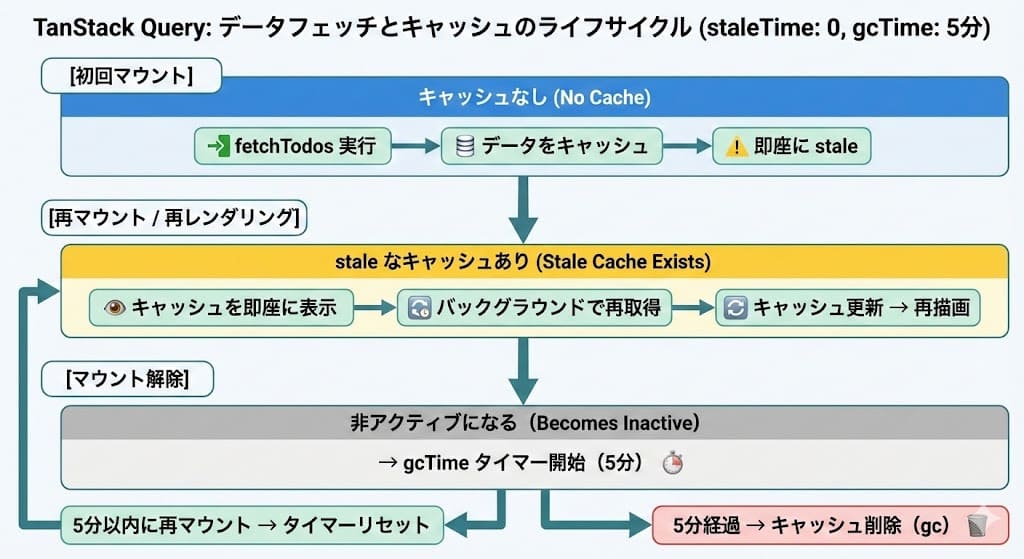
queryKey によるキャッシュ管理について
少しだけ脱線しますが、queryKey については、以下のドキュメントで詳しく解説されています。
TanStack Query は、queryKey に基づいて、キャッシュを管理します。
queryKey の型は unknown[] なので、シンプルな文字列のみで構成された配列から文字列とオブジェクトのネストなどの複雑な配列まで対応しています。
大切なことは、TanStack Query は queryKey を一意のキーとして、キャッシュを管理するため、キャッシュしたクエリのデータを再利用したい場合は、正しく配列を指定する必要があります。
例えば、以下のように、queryFn に対して同じクエリ関数を指定しているが、異なった queryKey を指定している場合、キャッシュは全く別のもとして扱われます。
useQuery({ queryKey: ['todos'], queryFn: fetchTodos })useQuery({ queryKey: ['todos1'], queryFn: fetchTodos })
また、逆に queryFn は異なったクエリ関数を指定しているが、同じ queryKey を指定している場合、同一のキャッシュが扱われます。
useQuery({ queryKey: ['todos'], queryFn: fetchTodos1 })useQuery({ queryKey: ['todos'], queryFn: fetchTodos2 })
queryKey の指定が正しくないだけで、そもそもキャッシュが正しく効かない状態になるので、注意が必要です。
ただし、以下のように、queryKey にオブジェクトが扱われている場合、オブジェクトの中身(キーと値)が同じであれば、オブジェクト内のキーの順序に関係なく、同じキャッシュとして扱われます。
useQuery({ queryKey: ['todos', { status: 'done', page: 1 }], queryFn: fetchTodos })useQuery({ queryKey: ['todos', { page: 1, status: 'done' }], queryFn: fetchTodos })
ここまでの内容が理解できれば、TanStack Query のキャッシュの基本はかなり押さえられたと思います。
クエリの無効化
staleTime に基づいた自動的なキャッシュ更新のみだと、必ずしも効果的でない場面は存在します。
例えば、ユーザーの何らかの操作によって、キャッシュが古くなっていることが確実な時や、意図的にキャッシュを更新したい時などです。
そういった場面に利用できるのが、QueryClient に存在する invalidateQueries メソッドです。
これを利用することで、クエリのデータを強制的に stale にします。そのクエリが現在レンダリング中(アクティブ)であれば、即座にバックグラウンドで再取得されます。
import { useQuery, useQueryClient } from "@tanstack/react-query";
// QueryClient からコンテキスト取得
const queryClient = useQueryClient();
// キャッシュ内のすべてのクエリを無効化
queryClient.invalidateQueries();
// todos キーを持つ全てのクエリを無効化
queryClient.invalidateQueries({ queryKey: ["todos"] });
注意点として、invalidateQueries() はクエリのデータを stale にするだけであり、キャッシュを削除したり、gc したりするわけではありません。
キャッシュを削除する場合、removeQueries() を利用する必要があります。
ミューテーション時のクエリの無効化
TanStack Query を扱う上で最も挙動に振り回されるタイミングがミューテーション(更新、削除などの操作)後のレンダリングだと筆者は思います。
正直なところ、ここまでの説明は、この項目を説明するための長い前置きでした。
(本当に長くてすみません・・・。)
ドキュメントとしては、以下を読んで終わりなのですが...
ドキュメントで扱われているサンプルコードを記載します。
import { useMutation, useQueryClient } from "@tanstack/react-query";
const queryClient = useQueryClient();
const mutation = useMutation({
mutationFn: addTodo,
onSuccess: async () => {
// パターン1: 単一のクエリのデータを無効化する場合
await queryClient.invalidateQueries({ queryKey: ["todos"] });
// パターン2: 複数のクエリのデータを無効化する場合
// ※ 実際はパターン1かパターン2のどちらかを使用します
await Promise.all([
queryClient.invalidateQueries({ queryKey: ["todos"] }),
queryClient.invalidateQueries({ queryKey: ["reminders"] }),
]);
},
});
ミューテーション後にqueryClient.invalidateQueries({ queryKey: ["todos"] }) を実行することで、キャッシュに保持しているクエリのデータを手動で無効化し、バックグラウンドで再取得が行われます。これにより、キャッシュのデータを最新の状態に更新できます。
この記述がない場合、キャッシュの更新が staleTime に依存するため、タイミングによってはミューテーションでデータを更新したにもかかわらず、画面の表示が古いままになることがあります。
ここまでで紹介したドキュメントに目を通した方なら、なぜ onSuccess のタイミングで、 queryClient.invalidateQueries({ queryKey: ['todos'] }) を実行しているのか?を正しく理解できると思います。
ただ、このドキュメントを読むだけだと正しい理解ができず、更にこのドキュメントでもそこまで触れられていない為、useMutation を利用した後は、対応する queryKey を invalidateQueries() に記述するだけで終わってしまうのではないかと思います。
実際、筆者はそうでしたし、未だにプロジェクト内にはそういったコードが散在しています。
プロジェクト内でよく利用しているQueryClient のメソッドの紹介
最後に、プロジェクト内でよく利用している QueryClient のメソッドを紹介します。
invalidateQueries
queryClient.invalidateQueries({ queryKey: ["todos"] });
指定したクエリキーのクエリを無効化し、キャッシュを stale にマークします。
- キャッシュは即座に削除されません
- そのクエリを使用しているコンポーネントがアクティブな場合、バックグラウンドで再フェッチが自動的に実行されます
- 用途: データ更新後に関連するクエリを再取得させたいとき
refetchQueries
await queryClient.refetchQueries({ queryKey: ["todos"] });
指定したクエリキーのクエリを即座に再フェッチします。
invalidateQueriesとは異なり、アクティブなコンポーネントの有無に関係なく強制的に再取得awaitで完了を待つことが必要- 用途: 更新後に最新データが確実に取得されていることを保証したいとき
removeQueries
queryClient.removeQueries({ queryKey: ["todos"] });
指定したクエリキーのキャッシュを完全に削除します。
- キャッシュからデータが消えるため、次回アクセス時は新規フェッチが必要
- 用途: エンティティが削除された後など、キャッシュに残っていると問題になるケース
setQueryData
queryClient.setQueryData([`/v1/versions/${variables.id}`], data);
指定したクエリキーのキャッシュデータを直接書き換えます。
- サーバーへのリクエストなしでキャッシュを更新
- 用途:
Mutationの結果をそのままキャッシュに反映したいとき(楽観的更新など)
まとめ
TanStack Query というライブラリは処理を非常にシンプルに記述でき、ドキュメントをそこまで読まなくても利用できてしまうほど便利なライブラリです。
ただ、キャッシュ周辺に関しては、ある程度ドキュメントを読み込んで理解しておかないと、挙動に振り回されて、書かなくても良いようなコードを書いて、場当たり的な対応をしてしまうことになります。
この記事が TanStack Query のキャッシュ周辺で悩んでいる方の助けに少しでもなれば幸いです。
最後まで読んでいただきありがとうございました。
参考記事
関連記事 | Related Posts





We are hiring!
シニア/フロントエンドエンジニア(React/Typescript)/KINTO中古車開発G/東京・大阪・福岡
KINTO開発部KINTO中古車開発グループについて◉KINTO開発部 :66名 KINTO中古車開発G:9名★ KINTOプロダクトマネジメントG:3名 KINTOバックエンド開発G:16名 契約管理開発G :9名 KINTO開発推進G:8名 KINTOフロントエンド開発G...
【クラウドエンジニア(クラウド活用の推進)】Cloud Infrastructure G/東京・名古屋・大阪・福岡
KINTO Tech BlogCloud InfrastructureグループについてAWSを主としたクラウドインフラの設計、構築、運用を主に担当しています。




