1時間30分かかっていたデータ取り込み処理をたった5分で終わらせる技術〜ISUCONは役にたつ〜

はじめに
こんにちは、KINTOテクノロジーズのFACTORY EC開発グループでバックエンドエンジニアをやっている、うえはら(@penpen_77777)です。
今回はWebサービスを決められたレギュレーションの中で限界まで高速化を図るチューニングバトル「ISUCON」で得た知識を活用して、FACTORYでマスタデータ反映に1時間30分かかっていた処理をたった5分で終わらせるようにした方法についてご紹介します。
「ISUCON」は、LINEヤフー株式会社の商標または登録商標です。
ISUCON is a trademark or registered trademark of LY Corporation.
今回の課題
FACTORYでは商品や車種などのマスタデータをExcelファイルに取りまとめ、
そのExcelファイルをもとに本番環境のDBにデータを反映しています(=マスタ反映)。
このマスタ反映に90分かかっており、マスタ運用作業のボトルネックになっていました。
例えば本番環境への反映の前に検証環境でマスタデータに問題ないかを確認しているのですが、
データの誤りに気づいて修正してもマスタ反映に90分かかるため、データが正しく直せたかどうかすぐに確認できない状況でした。
そこで、マスタ反映を高速化することで運用作業の効率化を図ることにしました。
マスタデータ反映
マスタ反映は、Excelで管理されているマスタデータを元に、最終的にマスタ反映コンテナがDBに書き込むという流れになっています。
上記の流れを図に示します。

図中では以下のような流れでマスタ反映が進みます。
- マスタ運営担当者が、原本となるExcelファイルに車種や商品情報を入力する
- 出来上がったExcelファイルをマスタ管理ツールにアップロードする
- マスタ管理ツールがバリデーションをかけ、問題があれば担当者に通知する
- Excelがアップロードされると裏でLambda関数が実行され、ExcelファイルからCSVファイルに変換される
- DBに反映したい段階で、マスタデータをFACTORY本体に連携するため、CSVをレプリケーションバケットに保存する
- レプリケーションバケットにファイルが保存されるとFACTORY本体でステートマシンが起動し、マスタ反映コンテナを起動する
- マスタ反映コンテナがCSVを読み取ってSQLを組み立て、DBの各テーブルにレコードを読み書きする
今回高速化の対象としたのは、7のマスタ反映コンテナの処理です。
パフォーマンスチューニングをどのように進めたか追体験する
今回のマスタ反映に関するパフォーマンス問題についてどのように解決したかサンプルコードで見ていきましょう。
実際のマスタ反映処理はKotlinで記述されていますが、サンプルコードの方では筆者が慣れているGoを使います。
また、使用するマスタデータはFACTORYの実際に使われているデータではありません。
ですが、似た構造のマスタデータを使うので、実際に筆者が行ったパフォーマンスチューニングと同じ方法で高速化できます。
もしよろしければ皆さんも手を動かしながら試してみてください。

入力
ECサイトで管理している商品データを反映したいと考えてみましょう。
表では省略していますが、全部で50万件程度のデータとなります
| product_code 商品を一意に識別するコード |
product_name 商品の表示名 |
category_code 商品が属するカテゴリのコード |
supplier_code 仕入先コード |
status_code 商品の販売状態 |
unit_price 単価(円) |
|---|---|---|---|---|---|
| P1001 | ボールペン 黒 | CAT01 | SUP01 | active | 150 |
| P1002 | ボールペン 赤 | CAT01 | SUP01 | active | 150 |
| P1003 | シャープペンシル | CAT01 | SUP02 | discontinued | 300 |
| P2001 | A4コピー用紙 500枚 | CAT02 | SUP03 | active | 450 |
| P2002 | A3コピー用紙 500枚 | CAT02 | SUP03 | active | 780 |
人間にとって分かりやすいように表で示しましたが、システムにはcsvの形で入力されます。
product_code,product_name,category_code,supplier_code,status_code,unit_price
P1001,ボールペン 黒,CAT01,SUP01,active,150
P1002,ボールペン 赤,CAT01,SUP01,active,150
P1003,シャープペンシル,CAT01,SUP02,discontinued,300
P2001,A4コピー用紙 500枚,CAT02,SUP03,active,450
P2002,A3コピー用紙 500枚,CAT02,SUP03,active,780
出力
入力されたデータを以下のようにproductテーブルに入れることにします。
category_codeやsupplier_codeやstatus_codeは外部テーブルで保持される値となるため、idに変換した上で保存されます。
外部テーブルにはすでにレコードが反映されているとします。
| product_id | product_code | product_name | category_id | supplier_id | status_id | unit_price |
|---|---|---|---|---|---|---|
| 1 | P1001 | ボールペン 黒 | 1 | 1 | 1 | 150 |
| 2 | P1002 | ボールペン 赤 | 1 | 1 | 1 | 150 |
| 3 | P1003 | シャープペンシル | 1 | 2 | 2 | 300 |
| 4 | P2001 | A4コピー用紙 500枚 | 2 | 3 | 1 | 450 |
| 5 | P2002 | A3コピー用紙 500枚 | 2 | 3 | 1 | 780 |
改善前のコード
サンプルコードの全体構成を以下の図に示します。
ハンズオンをサクッとできるようにテストデータの準備等の必要な作業を行ったのち、本題のマスタ反映が実行されるようになっています。testcontainersでMySQLコンテナを起動しテスト用のCSVを生成した後、main.goがそのCSVを読み取ってDBにマスタ反映を行います。

今回使用するサンプルコードを以下に示します。以下の4つのコードを同じディレクトリに配置してください。
main.go (改善対象のコード)
package main
import (
"context"
"fmt"
"log"
"os"
"time"
_ "github.com/go-sql-driver/mysql"
"github.com/gocarina/gocsv"
"github.com/jmoiron/sqlx"
)
func main() {
ctx := context.Background()
// MySQLコンテナを起動
connStr, cleanup, err := startMySQLContainer(ctx)
if err != nil {
log.Fatal(err)
}
defer cleanup()
db, err := sqlx.Open("mysql", connStr)
if err != nil {
log.Fatal(err)
}
defer db.Close()
// テーブル・マスターデータを作成
if err := setupTables(db); err != nil {
log.Fatal(err)
}
// サンプルCSVを生成(50万行)
csvFilename := "data.csv"
if err := generateSampleCSV(csvFilename, 500000); err != nil {
log.Fatal(err)
}
// 1. CSVを読み取る
file, err := os.Open(csvFilename)
if err != nil {
log.Fatal(err)
}
defer file.Close()
var products []Product
if err := gocsv.UnmarshalFile(file, &products); err != nil {
log.Fatal(err)
}
fmt.Printf("CSV読み込み完了: %d 行\n", len(products))
importStart := time.Now()
for i, product := range products {
// 2. 読んでない行があれば1行読み取る、なければ終了
lineNum := i + 2
// 3. category_codeをcategory_idに変換
var category Category
if err := db.Get(
&category,
`SELECT * FROM categories WHERE code = ?`,
product.CategoryCode,
); err != nil {
log.Fatalf("行 %d: category_code %q の検索に失敗: %v", lineNum, product.CategoryCode, err)
}
// 4. supplier_codeをsupplier_idに変換
var supplier Supplier
if err := db.Get(
&supplier,
`SELECT * FROM suppliers WHERE code = ?`,
product.SupplierCode,
); err != nil {
log.Fatalf("行 %d: supplier_code %q の検索に失敗: %v", lineNum, product.SupplierCode, err)
}
// 5. status_codeをstatus_idに変換
var status Status
if err := db.Get(
&status,
`SELECT * FROM statuses WHERE code = ?`,
product.StatusCode,
); err != nil {
log.Fatalf("行 %d: status_code %q の検索に失敗: %v", lineNum, product.StatusCode, err)
}
// 6. ProductRowに変換
row := ProductRow{
ProductCode: product.ProductCode,
ProductName: product.ProductName,
CategoryID: category.ID,
SupplierID: supplier.ID,
StatusID: status.ID,
UnitPrice: product.UnitPrice,
}
// 7. UPDATE文を実行する
result, err := db.NamedExec(`
UPDATE products
SET product_name = :product_name,
category_id = :category_id,
supplier_id = :supplier_id,
status_id = :status_id,
unit_price = :unit_price
WHERE product_code = :product_code`,
row,
)
if err != nil {
log.Fatalf("行 %d: productsの更新に失敗: %v", lineNum, err)
}
rowsAffected, err := result.RowsAffected()
if err != nil {
log.Fatalf("行 %d: 更新件数の取得に失敗: %v", lineNum, err)
}
// 8. UPDATE対象がなければINSERTする
if rowsAffected == 0 {
_, err = db.NamedExec(`
INSERT INTO products (product_code, product_name, category_id, supplier_id, status_id, unit_price)
VALUES (:product_code, :product_name, :category_id, :supplier_id, :status_id, :unit_price)`,
row,
)
if err != nil {
log.Fatalf("行 %d: productsの登録に失敗: %v", lineNum, err)
}
}
if (lineNum-1)%1000 == 0 {
rate := float64(lineNum-1) / time.Since(importStart).Seconds()
fmt.Printf("進捗: %d / %d 行 (%.0f 行/秒)\n", lineNum-1, len(products), rate)
}
// 9. 2に戻る
}
fmt.Printf("完了: %d 行 (所要時間: %v)\n", len(products), time.Since(importStart))
}
models.go (csv, dbを操作するのに必要な構造体を定義)
package main
type Product struct {
ProductCode string `csv:"product_code"`
ProductName string `csv:"product_name"`
CategoryCode string `csv:"category_code"`
SupplierCode string `csv:"supplier_code"`
StatusCode string `csv:"status_code"`
UnitPrice int `csv:"unit_price"`
}
type Category struct {
ID int `db:"id"`
Code string `db:"code"`
Name string `db:"name"`
}
type Supplier struct {
ID int `db:"id"`
Code string `db:"code"`
Name string `db:"name"`
}
type Status struct {
ID int `db:"id"`
Code string `db:"code"`
Name string `db:"name"`
}
type ProductRow struct {
ProductCode string `db:"product_code"`
ProductName string `db:"product_name"`
CategoryID int `db:"category_id"`
SupplierID int `db:"supplier_id"`
StatusID int `db:"status_id"`
UnitPrice int `db:"unit_price"`
}
setup.go(DB初期化・CSV生成)
package main
import (
"context"
"encoding/csv"
"fmt"
"math/rand"
"os"
"strconv"
"time"
"github.com/jmoiron/sqlx"
"github.com/testcontainers/testcontainers-go"
"github.com/testcontainers/testcontainers-go/modules/mysql"
"github.com/testcontainers/testcontainers-go/wait"
)
func startMySQLContainer(ctx context.Context) (connStr string, cleanup func(), err error) {
mysqlContainer, err := mysql.Run(ctx,
"mysql:8.0",
mysql.WithDatabase("testdb"),
mysql.WithUsername("user"),
mysql.WithPassword("password"),
testcontainers.WithWaitStrategyAndDeadline(3*time.Minute,
wait.ForListeningPort("3306/tcp").
WithStartupTimeout(3*time.Minute),
),
)
if err != nil {
return "", nil, err
}
connStr, err = mysqlContainer.ConnectionString(ctx)
if err != nil {
_ = mysqlContainer.Terminate(ctx)
return "", nil, err
}
cleanup = func() {
_ = mysqlContainer.Terminate(ctx)
}
return connStr, cleanup, nil
}
func generateSampleCSV(filename string, rows int) error {
file, err := os.Create(filename)
if err != nil {
return err
}
defer file.Close()
writer := csv.NewWriter(file)
defer writer.Flush()
if err := writer.Write([]string{"product_code", "product_name", "category_code", "supplier_code", "status_code", "unit_price"}); err != nil {
return err
}
categoryCodes := []string{"CAT01", "CAT02", "CAT03"}
supplierCodes := []string{"SUP01", "SUP02", "SUP03"}
statusCodes := []string{"active", "discontinued", "pending"}
for i := 0; i < rows; i++ {
record := []string{
fmt.Sprintf("P%d", 1000+i+1),
fmt.Sprintf("商品_%d", i+1),
categoryCodes[rand.Intn(len(categoryCodes))],
supplierCodes[rand.Intn(len(supplierCodes))],
statusCodes[rand.Intn(len(statusCodes))],
strconv.Itoa(rand.Intn(10000) + 100),
}
if err := writer.Write(record); err != nil {
return err
}
}
return nil
}
func setupTables(db *sqlx.DB) error {
tables := []string{
`CREATE TABLE IF NOT EXISTS categories (
id INT AUTO_INCREMENT PRIMARY KEY,
code VARCHAR(10) UNIQUE NOT NULL,
name VARCHAR(100) NOT NULL
)`,
`CREATE TABLE IF NOT EXISTS suppliers (
id INT AUTO_INCREMENT PRIMARY KEY,
code VARCHAR(10) UNIQUE NOT NULL,
name VARCHAR(100) NOT NULL
)`,
`CREATE TABLE IF NOT EXISTS statuses (
id INT AUTO_INCREMENT PRIMARY KEY,
code VARCHAR(20) UNIQUE NOT NULL,
name VARCHAR(100) NOT NULL
)`,
`CREATE TABLE IF NOT EXISTS products (
id INT AUTO_INCREMENT PRIMARY KEY,
product_code VARCHAR(50) UNIQUE NOT NULL,
product_name VARCHAR(255) NOT NULL,
category_id INT NOT NULL,
supplier_id INT NOT NULL,
status_id INT NOT NULL,
unit_price INT NOT NULL,
FOREIGN KEY (category_id) REFERENCES categories(id),
FOREIGN KEY (supplier_id) REFERENCES suppliers(id),
FOREIGN KEY (status_id) REFERENCES statuses(id)
)`,
}
for _, table := range tables {
if _, err := db.Exec(table); err != nil {
return err
}
}
masterData := []string{
`INSERT IGNORE INTO categories (code, name) VALUES
('CAT01', '文房具'), ('CAT02', '食品'), ('CAT03', '電化製品')`,
`INSERT IGNORE INTO suppliers (code, name) VALUES
('SUP01', '株式会社A商事'), ('SUP02', '株式会社B産業'), ('SUP03', '株式会社C物産')`,
`INSERT IGNORE INTO statuses (code, name) VALUES
('active', '販売中'), ('discontinued', '販売終了'), ('pending', '販売準備中')`,
}
for _, data := range masterData {
if _, err := db.Exec(data); err != nil {
return err
}
}
return nil
}
go.mod
module csv-import-example
go 1.24.5
require (
github.com/go-sql-driver/mysql v1.9.3
github.com/gocarina/gocsv v0.0.0-20240520201108-78e41c74b4b1
github.com/jmoiron/sqlx v1.4.0
github.com/testcontainers/testcontainers-go v0.40.0
github.com/testcontainers/testcontainers-go/modules/mysql v0.40.0
)
require (
dario.cat/mergo v1.0.2 // indirect
filippo.io/edwards25519 v1.1.0 // indirect
github.com/Azure/go-ansiterm v0.0.0-20210617225240-d185dfc1b5a1 // indirect
github.com/Microsoft/go-winio v0.6.2 // indirect
github.com/cenkalti/backoff/v4 v4.3.0 // indirect
github.com/containerd/errdefs v1.0.0 // indirect
github.com/containerd/errdefs/pkg v0.3.0 // indirect
github.com/containerd/log v0.1.0 // indirect
github.com/containerd/platforms v0.2.1 // indirect
github.com/cpuguy83/dockercfg v0.3.2 // indirect
github.com/davecgh/go-spew v1.1.1 // indirect
github.com/distribution/reference v0.6.0 // indirect
github.com/docker/docker v28.5.1+incompatible // indirect
github.com/docker/go-connections v0.6.0 // indirect
github.com/docker/go-units v0.5.0 // indirect
github.com/ebitengine/purego v0.8.4 // indirect
github.com/felixge/httpsnoop v1.0.4 // indirect
github.com/go-logr/logr v1.4.3 // indirect
github.com/go-logr/stdr v1.2.2 // indirect
github.com/go-ole/go-ole v1.2.6 // indirect
github.com/google/uuid v1.6.0 // indirect
github.com/grpc-ecosystem/grpc-gateway/v2 v2.27.7 // indirect
github.com/klauspost/compress v1.18.0 // indirect
github.com/lufia/plan9stats v0.0.0-20211012122336-39d0f177ccd0 // indirect
github.com/magiconair/properties v1.8.10 // indirect
github.com/moby/docker-image-spec v1.3.1 // indirect
github.com/moby/go-archive v0.1.0 // indirect
github.com/moby/patternmatcher v0.6.0 // indirect
github.com/moby/sys/sequential v0.6.0 // indirect
github.com/moby/sys/user v0.4.0 // indirect
github.com/moby/sys/userns v0.1.0 // indirect
github.com/moby/term v0.5.0 // indirect
github.com/morikuni/aec v1.0.0 // indirect
github.com/opencontainers/go-digest v1.0.0 // indirect
github.com/opencontainers/image-spec v1.1.1 // indirect
github.com/pkg/errors v0.9.1 // indirect
github.com/pmezard/go-difflib v1.0.0 // indirect
github.com/power-devops/perfstat v0.0.0-20210106213030-5aafc221ea8c // indirect
github.com/shirou/gopsutil/v4 v4.25.6 // indirect
github.com/sirupsen/logrus v1.9.3 // indirect
github.com/stretchr/testify v1.11.1 // indirect
github.com/tklauser/go-sysconf v0.3.12 // indirect
github.com/tklauser/numcpus v0.6.1 // indirect
github.com/yusufpapurcu/wmi v1.2.4 // indirect
go.opentelemetry.io/auto/sdk v1.2.1 // indirect
go.opentelemetry.io/contrib/instrumentation/net/http/otelhttp v0.49.0 // indirect
go.opentelemetry.io/otel v1.38.0 // indirect
go.opentelemetry.io/otel/metric v1.38.0 // indirect
go.opentelemetry.io/otel/sdk v1.38.0 // indirect
go.opentelemetry.io/otel/trace v1.38.0 // indirect
golang.org/x/crypto v0.43.0 // indirect
golang.org/x/sys v0.38.0 // indirect
google.golang.org/grpc v1.78.0 // indirect
google.golang.org/protobuf v1.36.11 // indirect
gopkg.in/yaml.v3 v3.0.1 // indirect
)
高速化するためにmain.goを改善していきます。
main.goの処理の流れをまとめると以下の通りです。
- csvを読み取る
product_code,product_name,category_code,supplier_code,status_code,unit_price P1001,ボールペン 黒,CAT01,SUP01,active,150 P1002,ボールペン 赤,CAT01,SUP01,active,150 ... - 読んでない行があれば1行読み取る、なければ終了
P1001,ボールペン 黒,CAT01,SUP01,active,150 - category_codeをcategory_idに変換
SELECT * FROM categories WHERE code = 'CAT01' -- => id=1, code='CAT01', name='文房具' - supplier_codeをsupplier_idに変換
SELECT * FROM suppliers WHERE code = 'SUP01' -- => id=1, code='SUP01', name='株式会社A商事' - status_codeをstatus_idに変換
SELECT * FROM statuses WHERE code = 'active' -- => id=1, code='active', name='販売中' - ProductRowに変換
- UPDATE文を実行する
UPDATE products SET product_name = 'ボールペン 黒', category_id = 1, supplier_id = 1, status_id = 1, unit_price = 150 WHERE product_code = 'P1001' - UPDATE対象がなければINSERTする
INSERT INTO products (product_code, product_name, category_id, supplier_id, status_id, unit_price) VALUES ('P1001', 'ボールペン 黒', 1, 1, 1, 150) - 2に戻る
実行してみる
まずは現状を把握するため反映にどれくらい時間がかかるかみてみましょう。
testcontainersでMySQLコンテナを起動するため、事前にDocker Desktopを起動しておいてください。
また、依存パッケージを取得するためにgo mod tidyを実行してからgo run .を実行します。
go mod tidy
go run .
このコードを実行してみると以下のような実行結果が得られます。
なんとDBへの反映に47分かかってしまいました。
$ go run .
CSV読み込み完了: 500000 行
進捗: 1000 / 500000 行 (338 行/秒)
進捗: 2000 / 500000 行 (329 行/秒)
進捗: 3000 / 500000 行 (320 行/秒)
進捗: 4000 / 500000 行 (326 行/秒)
進捗: 5000 / 500000 行 (328 行/秒)
進捗: 6000 / 500000 行 (328 行/秒)
進捗: 7000 / 500000 行 (329 行/秒)
進捗: 8000 / 500000 行 (328 行/秒)
進捗: 9000 / 500000 行 (319 行/秒)
...
進捗: 500000 / 500000 行 (176 行/秒)
完了: 成功 500000 行, エラー 0 行 (所要時間: 47m23.503716s)
実際のFACTORYのマスタ反映の負荷状況
実際のFACTORYでの本番環境への反映では90分もの時間がかかっていました。
FACTORY本番のRDSでの負荷を計測するため、以下にDatabase Insightsの結果を示します。
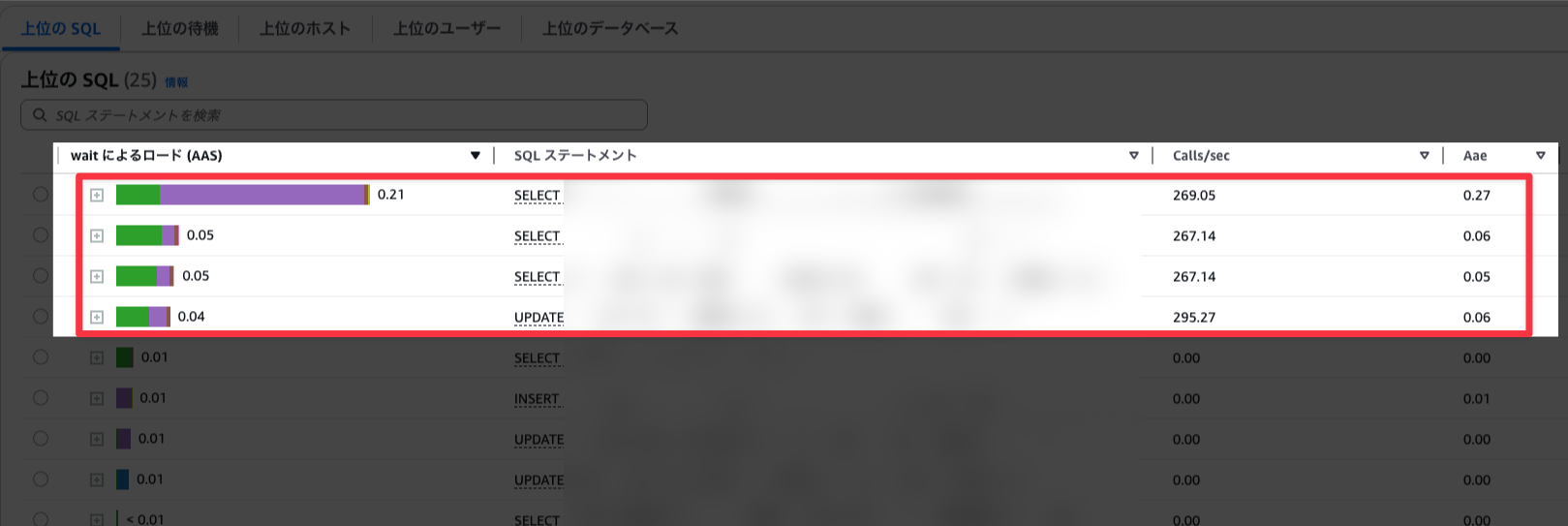
図ではクエリ別にAAS(平均アクティブセッション)が示され、AASが高い順に並んでいます。
AASが高いほどDBに負荷がかかっており、低いほどDBに負荷がかかっていないというように解釈すればokです。
赤枠がマスタ反映時に実行されているSQLになりますが、
- 特定のテーブルに対するSELECTの実行回数が多い(1秒あたりに200回程度実行されている)
- SELECTよりも負荷は小さいものの、UPDATEも同程度の頻度で実行されている
このように計測の結果、マスタ反映時に叩かれるSQL、特にSELECTが原因だなというように見当をつけ、改善を進めていきました。
原因を探る
これだけの時間がかかる原因を探ってみましょう。
ここではコード中で実行されるクエリに着目してみます。
実行されているクエリは以下の通りです。
| # | クエリ | ループ中(回) | 合計(回) |
|---|---|---|---|
| 1 | SELECT * FROM categories WHERE code = ? |
1 × 50万ループ = 50万 | 50万 |
| 2 | SELECT * FROM suppliers WHERE code = ? |
1 × 50万ループ = 50万 | 50万 |
| 3 | SELECT * FROM statuses WHERE code = ? |
1 × 50万ループ = 50万 | 50万 |
| 4 | UPDATE products SET ... WHERE product_code = ? |
1 × 50万ループ = 50万 | 50万 |
| 5 | INSERT INTO products (...) VALUES (...) |
最大1 × 50万ループ = 最大50万 | 最大50万 |
| 合計 | 最大250万 | 最大250万 |
1ループあたりの実行回数は少ないですが、今回はCSVが50万行あることから50万ループ実行され、最大で合計250万クエリ実行されることになります。
実行されるクエリが多いと、インデックスを貼って単体のクエリが高速にしたとしても、ちりつもで遅くなってしまいます。
特にDBは別サーバに分離されることが多く、ネットワークの通信帯域の影響も受けてしまいます。
なので高速化の方針としては実行されるクエリをいかに削減するかということを考えれば良さそうです。
実行されるクエリを削減するためには?
SELECT編
実行されるクエリを削減するにはいくつかの手段がありますが、まずはオンメモリキャッシュを取り上げてみたいと思います。
オンメモリキャッシュは、時間のかかる処理の実行結果をあらかじめメモリ上に乗っけてしまい、結果が欲しい時にはメモリ上のデータから引っ張り出すことで高速化する手法です。ISUCONでは常套手段といっても良いほど典型的なパターンです。
今回でいくと時間のかかる処理とはDBへの問い合わせにあたります。

オンメモリでキャッシュするには、キャッシュ対象のデータが、キャッシュ中に書き換えられないほうが実装しやすいです。
キャッシュ中に実データに書き込みがある場合、キャッシュを書き込みに追随させるためデータの更新が必要になります。排他制御を考慮する必要があり、実装が困難になります。
productsテーブルを更新する際にはcategories, suppliers, statusesテーブルはすでに更新が完了しており、書き込みはありません。なのでproductsテーブルを更新する前にキャッシュしておけば問題なさそうです。
ということで先ほどのコードにキャッシュ処理を加えます。
CSV読み取り直後にSELECTを行い全件をメモリ上に載せます。
code→IDへ高速にデータを引きたいので、スライスではなくここではmap[string]intに載せてあげます。map型はキーにひもづくデータの取得で
fmt.Printf("CSV読み込み完了: %d 行\n", len(products))
+ // マスターデータをmapに読み込み(code → id)
+ var categories []Category
+ if err := db.Select(&categories, "SELECT * FROM categories"); err != nil {
+ log.Fatal(err)
+ }
+ categoryMap := make(map[string]int, len(categories))
+ for _, c := range categories {
+ categoryMap[c.Code] = c.ID
+ }
code→IDが欲しいタイミングで、先ほど定義したmap型の変数を使うように書き換えます
// 3. category_codeをcategory_idに変換
- var category Category
- if err := db.Get(&category, "SELECT * FROM categories WHERE code = ?", product.CategoryCode); err !=
nil {
- log.Printf("行 %d: category変換エラー: %v", i+2, err)
+ categoryID, ok := categoryMap[product.CategoryCode]
+ if !ok {
+ log.Printf("行 %d: category変換エラー: code %q が見つかりません", i+2, product.CategoryCode)
errorCount++
continue
}
他の修正も加えると以下のような差分になります。
オンメモリキャッシュ化の全体差分
diff --git a/main.go b/main.go
index c3705d8..c3c16cf 100644
--- a/main.go
+++ b/main.go
@@ -52,6 +52,34 @@ func main() {
}
fmt.Printf("CSV読み込み完了: %d 行\n", len(products))
+ // マスターデータをmapに読み込み(code → id)
+ var categories []Category
+ if err := db.Select(&categories, "SELECT * FROM categories"); err != nil {
+ log.Fatal(err)
+ }
+ categoryMap := make(map[string]int, len(categories))
+ for _, c := range categories {
+ categoryMap[c.Code] = c.ID
+ }
+
+ var suppliers []Supplier
+ if err := db.Select(&suppliers, "SELECT * FROM suppliers"); err != nil {
+ log.Fatal(err)
+ }
+ supplierMap := make(map[string]int, len(suppliers))
+ for _, s := range suppliers {
+ supplierMap[s.Code] = s.ID
+ }
+
+ var statuses []Status
+ if err := db.Select(&statuses, "SELECT * FROM statuses"); err != nil {
+ log.Fatal(err)
+ }
+ statusMap := make(map[string]int, len(statuses))
+ for _, s := range statuses {
+ statusMap[s.Code] = s.ID
+ }
+
importStart := time.Now()
for i, product := range products {
@@ -59,41 +87,29 @@ func main() {
lineNum := i + 2
// 3. category_codeをcategory_idに変換
- var category Category
- if err := db.Get(
- &category,
- `SELECT * FROM categories WHERE code = ?`,
- product.CategoryCode,
- ); err != nil {
- log.Fatalf("行 %d: category_code %q の検索に失敗: %v", lineNum, product.CategoryCode, err)
+ categoryID, ok := categoryMap[product.CategoryCode]
+ if !ok {
+ log.Fatalf("行 %d: category_code %q の検索に失敗", lineNum, product.CategoryCode)
}
// 4. supplier_codeをsupplier_idに変換
- var supplier Supplier
- if err := db.Get(
- &supplier,
- `SELECT * FROM suppliers WHERE code = ?`,
- product.SupplierCode,
- ); err != nil {
- log.Fatalf("行 %d: supplier_code %q の検索に失敗: %v", lineNum, product.SupplierCode, err)
+ supplierID, ok := supplierMap[product.SupplierCode]
+ if !ok {
+ log.Fatalf("行 %d: supplier_code %q の検索に失敗", lineNum, product.SupplierCode)
}
// 5. status_codeをstatus_idに変換
- var status Status
- if err := db.Get(
- &status,
- `SELECT * FROM statuses WHERE code = ?`,
- product.StatusCode,
- ); err != nil {
- log.Fatalf("行 %d: status_code %q の検索に失敗: %v", lineNum, product.StatusCode, err)
+ statusID, ok := statusMap[product.StatusCode]
+ if !ok {
+ log.Fatalf("行 %d: status_code %q の検索に失敗", lineNum, product.StatusCode)
}
row := ProductRow{
ProductCode: product.ProductCode,
ProductName: product.ProductName,
- CategoryID: category.ID,
- SupplierID: supplier.ID,
- StatusID: status.ID,
+ CategoryID: categoryID,
+ SupplierID: supplierID,
+ StatusID: statusID,
UnitPrice: product.UnitPrice,
}
DBに問い合わせる代わりにメモリ上のキャッシュにデータを問い合わせるため、
SELECTの150万回分がなくなり、残りのUPDATE/INSERTの最大100万回にまで削減できました。
| # | クエリ | ループ前(回) | ループ中(回) | 合計(回) |
|---|---|---|---|---|
| 1 | SELECT * FROM categories |
1 | 0 | 1 |
| 2 | SELECT * FROM suppliers |
1 | 0 | 1 |
| 3 | SELECT * FROM statuses |
1 | 0 | 1 |
| 4 | UPDATE products SET ... WHERE product_code = ? |
0 | 1 × 50万ループ = 50万 | 50万 |
| 5 | INSERT INTO products (...) VALUES (...) |
0 | 最大1 × 50万ループ = 最大50万 | 最大50万 |
| 合計 | 3 | 最大100万 | 最大100万3 |
これでどれくらい高速化できたか見てみましょう。
CSV読み込み完了: 500000 行
進捗: 1000 / 500000 行 (282 行/秒)
進捗: 2000 / 500000 行 (302 行/秒)
進捗: 3000 / 500000 行 (330 行/秒)
進捗: 4000 / 500000 行 (360 行/秒)
進捗: 5000 / 500000 行 (378 行/秒)
(略)
進捗: 496000 / 500000 行 (409 行/秒)
進捗: 497000 / 500000 行 (409 行/秒)
進捗: 498000 / 500000 行 (409 行/秒)
進捗: 499000 / 500000 行 (407 行/秒)
進捗: 500000 / 500000 行 (405 行/秒)
完了: 成功 500000 行, エラー 0 行 (所要時間: 20m35.34731075s)
以上のように時間を半減させることができました。
INSERT/UPDATE編
SELECTの実行回数は削減できましたが、まだ100万回ものSQLが実行されています。
残りのINSERT/UPDATEの高速化にチャレンジしてみます。
INSERT/UPDATEの実行回数を削減する手段としてはupsertに変更することが挙げられます。
UPSERTとは
UPSERTとはINSERTとUPDATEを組み合わせた単語で、INSERT時に対象レコードが存在しない場合はINSERTと、すでに存在する場合はUPDATEをかける処理です。
MySQLではINSERT ON DUPLICATE KEY UPDATEとREPLACE構文が使えますが、今回は前者の構文を使ってみます。
今回でいくと以下のUPDATE文を実行し、
UPDATE products
SET product_name = ?,
category_id = ?,
supplier_id = ?,
status_id = ?,
unit_price = ?
WHERE product_code = ?
UPDATE対象が存在しなければINSERTを行っています。
INSERT INTO products (
product_code,
product_name,
category_id,
supplier_id,
status_id,
unit_price
)
VALUES (?, ?, ?, ?, ?, ?)
INSERT ON DUPLICATE KEY UPDATEを使用すると2つのクエリを1つにまとめることができます。
INSERT INTO products (
product_code,
product_name,
category_id,
supplier_id,
status_id,
unit_price
)
VALUES (?, ?, ?, ?, ?, ?)
ON DUPLICATE KEY UPDATE
product_name = VALUES(product_name),
category_id = VALUES(category_id),
supplier_id = VALUES(supplier_id),
status_id = VALUES(status_id),
unit_price = VALUES(unit_price)
これだけで100万回→50万回までクエリの実行回数を削減できます。
| # | クエリ | ループ前(回) | ループ中(回) | 合計(回) |
|---|---|---|---|---|
| 1 | SELECT * FROM categories |
1 | 0 | 1 |
| 2 | SELECT * FROM suppliers |
1 | 0 | 1 |
| 3 | SELECT * FROM statuses |
1 | 0 | 1 |
| 4 | INSERT INTO products (...) ON DUPLICATE KEY UPDATE ... |
0 | 1 × 50万ループ = 50万 | 50万 |
| 合計 | 3 | 50万 | 50万3 |
コードでは以下のように修正しています
UPSERT化の差分
diff --git a/main.go b/main.go
index c3c16cf..0da4db0 100644
--- a/main.go
+++ b/main.go
@@ -113,36 +113,23 @@ func main() {
UnitPrice: product.UnitPrice,
}
- // 7. UPDATE文を実行する
- result, err := db.NamedExec(`
- UPDATE products
- SET product_name = :product_name,
- category_id = :category_id,
- supplier_id = :supplier_id,
- status_id = :status_id,
- unit_price = :unit_price
- WHERE product_code = :product_code`,
+ // 7. UPSERT(INSERT or UPDATE)を実行する
+ _, err := db.NamedExec(`
+ INSERT INTO products (
+ product_code, product_name, category_id, supplier_id, status_id, unit_price
+ ) VALUES (
+ :product_code, :product_name, :category_id, :supplier_id, :status_id, :unit_price
+ )
+ ON DUPLICATE KEY UPDATE
+ product_name = VALUES(product_name),
+ category_id = VALUES(category_id),
+ supplier_id = VALUES(supplier_id),
+ status_id = VALUES(status_id),
+ unit_price = VALUES(unit_price)`,
row,
)
if err != nil {
- log.Fatalf("行 %d: productsの更新に失敗: %v", lineNum, err)
- }
-
- rowsAffected, err := result.RowsAffected()
- if err != nil {
- log.Fatalf("行 %d: 更新件数の取得に失敗: %v", lineNum, err)
- }
-
- // 8. UPDATE対象がなければINSERTする
- if rowsAffected == 0 {
- _, err = db.NamedExec(`
- INSERT INTO products (product_code, product_name, category_id, supplier_id, status_id, unit_price)
- VALUES (:product_code, :product_name, :category_id, :supplier_id, :status_id, :unit_price)`,
- row,
- )
- if err != nil {
- log.Fatalf("行 %d: productsの登録に失敗: %v", lineNum, err)
- }
+ log.Fatalf("行 %d: productsのUPSERTに失敗: %v", lineNum, err)
}
if (lineNum-1)%1000 == 0 {
実行してみましょう。
CSV読み込み完了: 500000 行
進捗: 1000 / 500000 行 (636 行/秒)
進捗: 2000 / 500000 行 (642 行/秒)
進捗: 3000 / 500000 行 (658 行/秒)
進捗: 4000 / 500000 行 (661 行/秒)
進捗: 5000 / 500000 行 (652 行/秒)
(略)
進捗: 497000 / 500000 行 (650 行/秒)
進捗: 498000 / 500000 行 (650 行/秒)
進捗: 499000 / 500000 行 (650 行/秒)
進捗: 500000 / 500000 行 (650 行/秒)
完了: 成功 500000 行, エラー 0 行 (所要時間: 12m48.924974166s)
この修正だけで10分程度まで早くすることができました。
bulk化する
upsertに変更して50万回までSQLの実行回数を削減できました。
さらにSQLの実行回数を削減するためにSQLをbulk化してみます。
bulk化とはDBに対して複数のレコードに対する操作を1つのSQLにまとめて実行することを言います。
以下のUPSERT化したSQLはいまだ50万回叩かれています。
INSERT INTO products (
product_code,
product_name,
category_id,
supplier_id,
status_id,
unit_price
)
VALUES (?, ?, ?, ?, ?, ?)
ON DUPLICATE KEY UPDATE
product_name = VALUES(product_name),
category_id = VALUES(category_id),
supplier_id = VALUES(supplier_id),
status_id = VALUES(status_id),
unit_price = VALUES(unit_price)
このSQLを1行ずつ入れていくのではなく、ある程度のレコード数で固めてから送ることで
SQLの実行回数を減らせるわけです。
今回は1000レコード分ずつSQLをまとめて送ることにしてみましょう。
すると500000/1000=500回までSQLの実行回数を削減できます。
| # | クエリ | ループ前(回) | ループ中(回) | 合計(回) |
|---|---|---|---|---|
| 1 | SELECT * FROM categories |
1 | 0 | 1 |
| 2 | SELECT * FROM suppliers |
1 | 0 | 1 |
| 3 | SELECT * FROM statuses |
1 | 0 | 1 |
| 4 | INSERT INTO products (...) VALUES (...), (...), ... ON DUPLICATE KEY UPDATE ... |
0 | 50万ループ / 1000 = 500 | 500 |
| 合計 | 3 | 500 | 503 |
どれくらい固めるかを表す数値をバッチサイズと呼びますが、この場合バッチサイズは1000となります。
バルクUPSERT化の差分
diff --git a/main.go b/main.go
index 0da4db0..daf2689 100644
--- a/main.go
+++ b/main.go
@@ -80,8 +80,8 @@ func main() {
statusMap[s.Code] = s.ID
}
- importStart := time.Now()
-
+ // code → id 変換してProductRowスライスを構築
+ var rows []ProductRow
for i, product := range products {
// 2. 読んでない行があれば1行読み取る、なければ終了
lineNum := i + 2
@@ -104,16 +104,29 @@ func main() {
log.Fatalf("行 %d: status_code %q の検索に失敗", lineNum, product.StatusCode)
}
- row := ProductRow{
+ // 6. ProductRowに変換
+ rows = append(rows, ProductRow{
ProductCode: product.ProductCode,
ProductName: product.ProductName,
CategoryID: categoryID,
SupplierID: supplierID,
StatusID: statusID,
UnitPrice: product.UnitPrice,
+ })
+ }
+ fmt.Printf("変換完了: %d 行\n", len(rows))
+
+ // バルクUPSERT(1000行ずつ)
+ const batchSize = 1000
+ importStart := time.Now()
+
+ for i := 0; i < len(rows); i += batchSize {
+ end := i + batchSize
+ if end > len(rows) {
+ end = len(rows)
}
+ batch := rows[i:end]
- // 6. UPSERT(INSERT or UPDATE)を実行する
_, err := db.NamedExec(`
INSERT INTO products (
product_code, product_name, category_id, supplier_id, status_id, unit_price
@@ -126,17 +139,16 @@ func main() {
supplier_id = VALUES(supplier_id),
status_id = VALUES(status_id),
unit_price = VALUES(unit_price)`,
- row,
+ batch,
)
if err != nil {
- log.Fatalf("行 %d: productsのUPSERTに失敗: %v", lineNum, err)
+ log.Fatalf("バッチ %d-%d: UPSERTに失敗: %v", i+1, end, err)
}
- if (lineNum-1)%1000 == 0 {
- rate := float64(lineNum-1) / time.Since(importStart).Seconds()
- fmt.Printf("進捗: %d / %d 行 (%.0f 行/秒)\n", lineNum-1, len(products), rate)
+ if end%10000 == 0 || end == len(rows) {
+ rate := float64(end) / time.Since(importStart).Seconds()
+ fmt.Printf("進捗: %d / %d 行 (%.0f 行/秒)\n", end, len(rows), rate)
}
- // 8. 2に戻る
}
fmt.Printf("完了: %d 行 (所要時間: %v)\n", len(products), time.Since(importStart))
では実行してみましょう。
CSV読み込み完了: 500000 行
変換完了: 500000 行 (エラー 0 行)
進捗: 10000 / 500000 行 (56843 行/秒)
進捗: 20000 / 500000 行 (72234 行/秒)
進捗: 30000 / 500000 行 (78721 行/秒)
進捗: 40000 / 500000 行 (73047 行/秒)
進捗: 50000 / 500000 行 (76230 行/秒)
進捗: 60000 / 500000 行 (78932 行/秒)
進捗: 70000 / 500000 行 (81193 行/秒)
(略)
進捗: 460000 / 500000 行 (83997 行/秒)
進捗: 470000 / 500000 行 (83998 行/秒)
進捗: 480000 / 500000 行 (84197 行/秒)
進捗: 490000 / 500000 行 (83433 行/秒)
進捗: 500000 / 500000 行 (83642 行/秒)
完了: 成功 500000 行, エラー 0 行 (所要時間: 5.977838667s)
わずか6秒程度で完了するようになりました!
元々50分かかっていた処理だと考えると、かなり高速化されたのではないかと思います。
改善後の実際のFACTORYでのDBの負荷状況
改善の結果を先述のDatabase InsightsのAASで確認してみましょう。
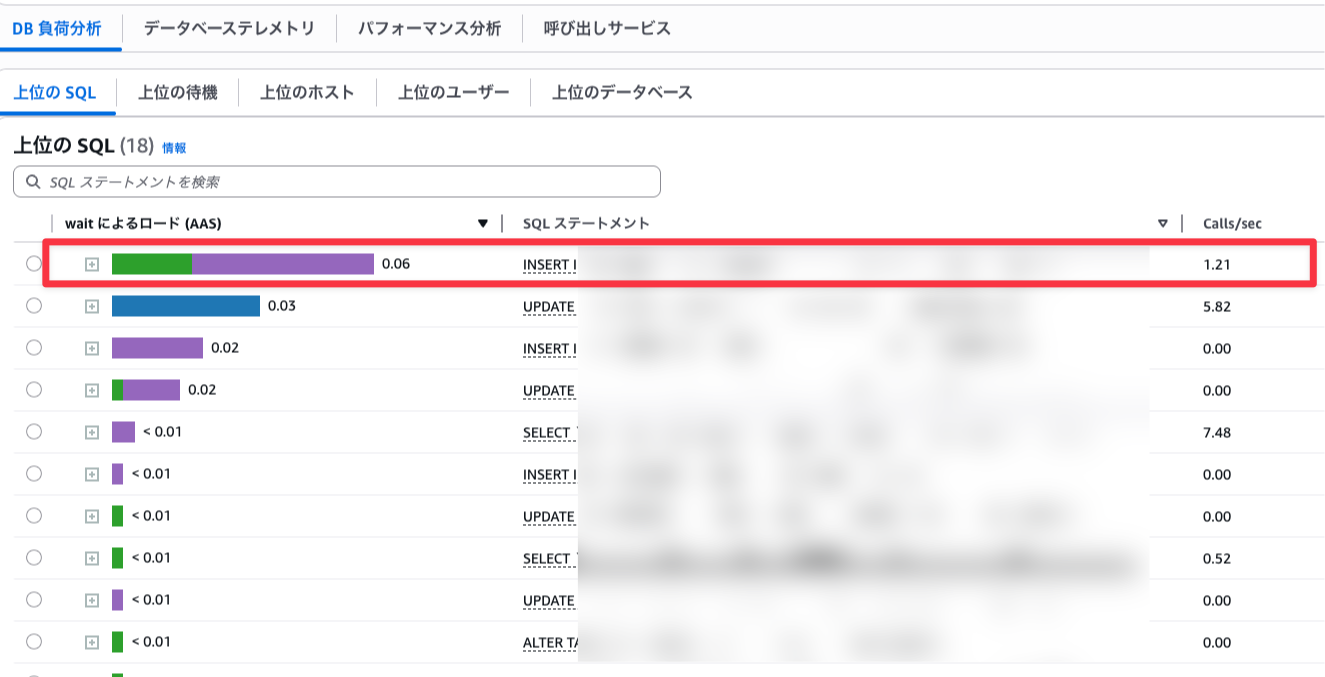
赤枠がマスタ反映時に実行されているSQLになりますが、
- 改善前に負荷がかかっているSQLとして挙げられていたSELECTがなくなって、ボトルネックを解消した
- INSERTはまだいるが実行回数が減り、AASも減った
このように実際のFACTORYのDBの計測からも負荷が減ったことがわかります。
この改善の結果、5分程度で反映が終わるようになりました!
改善前は90分かかっていたと考えるとめちゃくちゃ高速化できました!
まとめ
今回の改善の変遷をまとめると以下の通りです。
| ステップ | 施策 | 所要時間 | SQL実行回数(最大) |
|---|---|---|---|
| 改善前 | - | 47分 | 250万回 |
| 1. オンメモリキャッシュ | SELECTをメモリ参照に置換 | 20分 | 100万回 |
| 2. UPSERT化 | UPDATE+INSERTを1クエリに統合 | 13分 | 50万回 |
| 3. バルクUPSERT化 | 1000行ずつまとめて実行 | 6秒 | 500回 |
パフォーマンスチューニングでとった方法はどれもISUCONではよく出てくる典型的な対応策です。
まさかISUCONで培った知識を使って業務でこれほどまでの結果を出せるとは思いもしませんでした。
ISUCONは業務でも役に立ちます。
これからもISUCONで腕を磨きつつ、業務でのボトルネックを改善していきたいと考えています。





