6 min read
DataAnalytics
How We Define MLOps in KTC (1/4)
By Ikki Ikazaki, MLOps/Data Engineer at Analysis Group
This is the first part of a multi-part series on how KINTO Technologies Corporation (KTC) developed a system and culture of Machine Learning Operations (MLOps). Subsequent posts will cover batch patterns as the prediction serving pattern using SageMaker Pipelines, SageMaker Experiments to track the experiments conducted by data scientists, and "Benkyo-kai", a series of internal study sessions, to form the common knowledge about SageMaker and MLOps with other departments.
Situation
We have been working on various projects using ML techniques such as demand forecast, present and residual value prediction of the used car, image classification task, and some ranking algorithms, etc. Also, there are a few data scientists in Analysis Group and it comes to the conclusion that we need to build a common platform on which we can develop, manage, and develop machine learning models using MLOps technique. However, the question is what is MLOps and how we can integrate it with the ongoing relevant projects. Actually, the term MLOps is ambiguous and some people say "it is a kind of a buzzword." — and agreed to some extent.
Task
Considering the above, this blog post tries to define the scope of KTC MLOps by referring to some papers and documents the predecessor had published before. When talking about MLOps, the below image (Sculley et al., 2015) is often cited in Japan as a good illustration that shows ML code is actually a fraction of the whole system.

To deploy and operate at a production environment, you need to be familiar with the skills and culture of software engineering and DevOps practices, which is different from the ones of data scientists. However, there are much efforts done these days by ML experts to define the scope of MLOps and now fortunately we could refer to. In 2020, ml-system-design-pattern is published by Shibui et al at Mercari, inc., at that time, and our basic concept of MLOps is greatly influenced by such design patterns. Kreuzberger et al. (2022) also conducted some interview and literature review to try to summarize the latest basic principles and technologies usually required by MLOps. Now it is time to promote those ideas and develop them in depth within our teams.
Action
Goal
First of all, we set the goal of our MLOps. It is not much different from the one defined by the others:
to bring ML proofs of concept into production "efficiently" and "reliably".
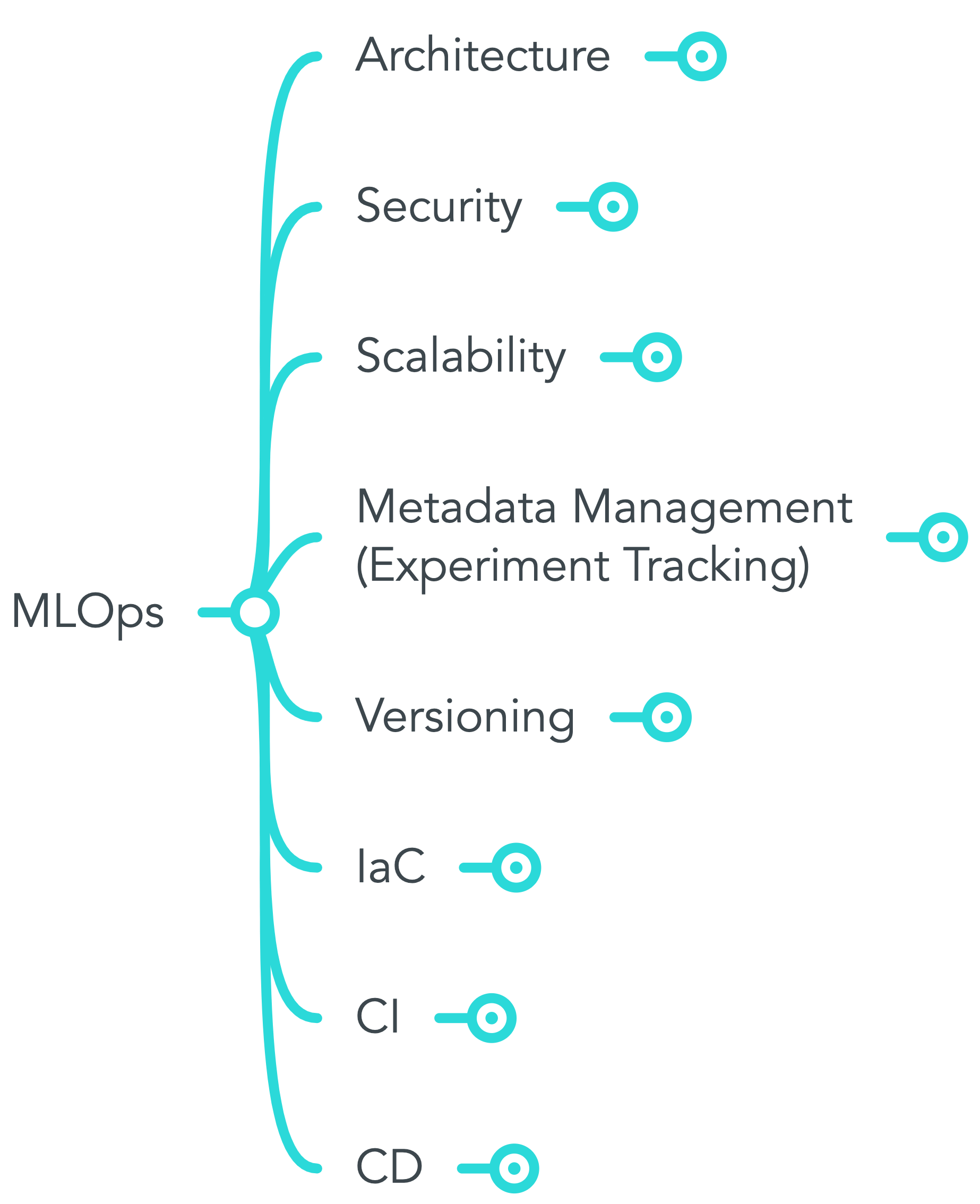
Also, the key concepts of MLOps is depicted in the decision-tree-like-format using MindMeister, a useful mind map tool, so that it can be easily referenced by the colleagues. The below is the artifact.

MindMeister was really useful when illustrate a vague concept like MLOps because of its feature to display or clear the child topics in the tree diagram. We just display the topic of scalability above not to bother you by showing the whole and mess tree of MLOps. Then, we associate the key concepts with our goal and organized like below.

Note that the term "Efficiently" in our goal is rephrased as "PJ Management With Speed" in the above picture and "Reliably" is expressed as "Reliable System Integration". Both strategies are important, of course, but we prioritize "PJ Management With Speed" first.
The next coming posts of multi-part series will get into the details about "Pipeline" which I think requires and thus belongs to "Scalability" subtopic and "Metadata Management" often called "Experiment Tracking" by data scientists. In this section, I just introduce those concepts in a general way.
Scalability
Scalability is the term to refer to the flexibility of computing resources or human workload in an organization. There are some technical terms in computer science using this keyword such as scale out, scale in, scale up, and scale down. For data scientists, scalability is crucial at the step of the model building because it is difficult to estimate the computational capacity required to run data processing and train the machine learning algorithms in advance. Could you guess how much data and what kind of format is available in KTC for demand forecast? If you could, what happens if our business suddenly expands which leads to a rapid increase in data? It may cause system resource error and require either proper scale out in the cluster or scale up per instance. In a sense, data itself stands for uncertainty and thus we need a scalable platform on which we can process data to train and host ML models by mitigating the risk.
Metadata Management (Experiment tracking)
The aim of metadata management is to manage the experiments for model development by tracking its metadata and reproduce its result without the help of by data scientists or developers who conducted the experiment. It is often said that because data science is a relatively new discipline and its technique is too technical for other roles to understand — sometimes even among data scientists — , it often becomes a black box. In this situation, nobody can reproduce the model building process except for the one who created it, which leads to the risk in management once he or she is on leave. Even if other data scientists are familiar with the techniques used, without the exact information - i.e. data extracted and hyper parameters - the model building process cannot be reproduced. Thus, the ML platform needs to have the ability to easily track the metadata on the processing environment, data, models, hyper parameters, objective metrics, and any comments, etc. The well-structured metadata repository not only brings the team the blueprint of data science but also accelerates the experiment cycle for data scientists. It is well suited as one of MLOps goals.
Result
By clarifying the entire scope of MLOps, it becomes easier to form a common knowledge among team members by pointing out the term or requirement in the scope. This entire map is just version one in KTC and expects continuous improvement. Like AWS Well-Architected tools, it will be great if it becomes a primary source in the project initiation which needs ML integration.
Sounds interesting? Next time we'll deep dive into the process of how to bring the DataScience project into production using MLOps techniques: batch pattern as the prediction serving pattern using SageMaker Pipelines. Part 2 is available from here. For more info, don't forget to follow the KTC Tech Blog to stay up to date.
Reference
Kreuzberger, D., Kühl, N., & Hirschl, S. (2022). Machine Learning Operations (MLOps): Overview, Definition, and Architecture. ArXiv, abs/2205.02302.
Sculley, D., Holt, G., Golovin, D., Davydov, E., Phillips, T., Ebner, D., Chaudhary, V., Young, M., Crespo, J.-F., & Dennison, D. (2015). Hidden Technical Debt in Machine Learning Systems.. In C. Cortes, N. D. Lawrence, D. D. Lee, M. Sugiyama & R. Garnett (eds.), NIPS (p./pp. 2503-2511), .
Shibui, Y., Byeon, S., Seo, J., & Jin, D. (2020). ml-system-design-pattern[GitHub Pages]. Retrieved from https://mercari.github.io/ml-system-design-pattern/