約9分で読めます
DataAnalytics
KINTOテクノロジーズのMLOpsを定義してみた (1/4)
こんにちは。分析グループ(分析G)でMLOps/データエンジニアしてます伊ヶ崎(@_ikki02)です。
こちらは「KINTOテクノロジーズ株式会社にてどのようにMLOpsを適用していくのか」というテーマでの連載1本目です。後続の記事では、SageMaker Pipelinesを用いたバッチ推論、SageMaker Experimentsを用いた実験管理、そして、他部署も巻き込んで開催した勉強会のお話などをしていければと考えています。
背景(Situation)
KINTOテクノロジーズでは機械学習を用いた様々なプロジェクトに取組んできました。新車の申込台数予測、中古車の残価予測、画像の類似度判定、ランキングアルゴリズムの開発など、様々なドメインや機械学習タスクがあります。また、分析グループにはデータサイエンティストが何名か在籍しており、それぞれの実行環境やお作法が異なったり、実験結果のスムーズな共有が難しかったことがありました。そのため、EDA(探索的データ分析のこと)やモデル開発にあたって、共通のプラットフォームが求められており、MLOpsという言葉も社内で使われるようになってきました。
ところで、MLOpsとは何でしょうか。また、既存のプロジェクトに対して、どのように組み込んでいけばよいのでしょうか。個人的にはMLOpsという言葉は抽象度が高すぎて、できれば避けたい言葉だったりします(正確には、成し遂げたい課題に対して、より適切な要素技術や言葉があるはず、と考えています)。
業務(Task)
そこで、この記事では、いくつかの論文やドキュメントを参考にしながら、MLOpsの全体像を明確にしつつ、KINTOテクノロジーズで特に重要視している要素技術についてご紹介していければと思います。MLOpsの話をする際に親の顔より見た絵としてよく以下の図が紹介されているかと思います(Sculley et al., 2015)。

この図では機械学習に関連するコードはアプリケーション全体のほんの一部であることが示唆されています。実際、機械学習を本番環境のアプリケーションにデプロイする際には、ソフトウェアエンジニアリングやDevOps等の技術に習熟する必要があり、データサイエンスとはまた異なるスキルセットや文化が求められます。一方で、MLOpsはバズワード化することもなく多くの研究者等によってその定義やスコープが明確にされつつあるようにも思えます。Kreuzberger et al. (2022)は様々な分野で活躍する機械学習の専門家に対してインタビューや文献調査を実施し、MLOpsの9つの原則と要素技術の解説をまとめています。また、メルカリ社により公開されているml-system-design-patternでは、機械学習システムを本番稼働させるためのデザインパターンがまとめられており(Shibui et al., 2020)、MLOpsの社内定義に際して、大いに参考にさせていただきました。
これらの情報をKINTOテクノロジーズの内部にてよく使われている用語や技術をベースに再整理し、社内展開できるようにまとめていきました。
やったこと(Action)
目的とスコープ
まず、MLOpsの目的を明文化します。目的については、KINTOテクノロジーズ独自の要素を織り交ぜるわけではなく、ある程度一般性を持たせた形にしています。すなわち、
機械学習のPoCを「効率よく」本番環境へ 「信頼性高く」デプロイし運用する
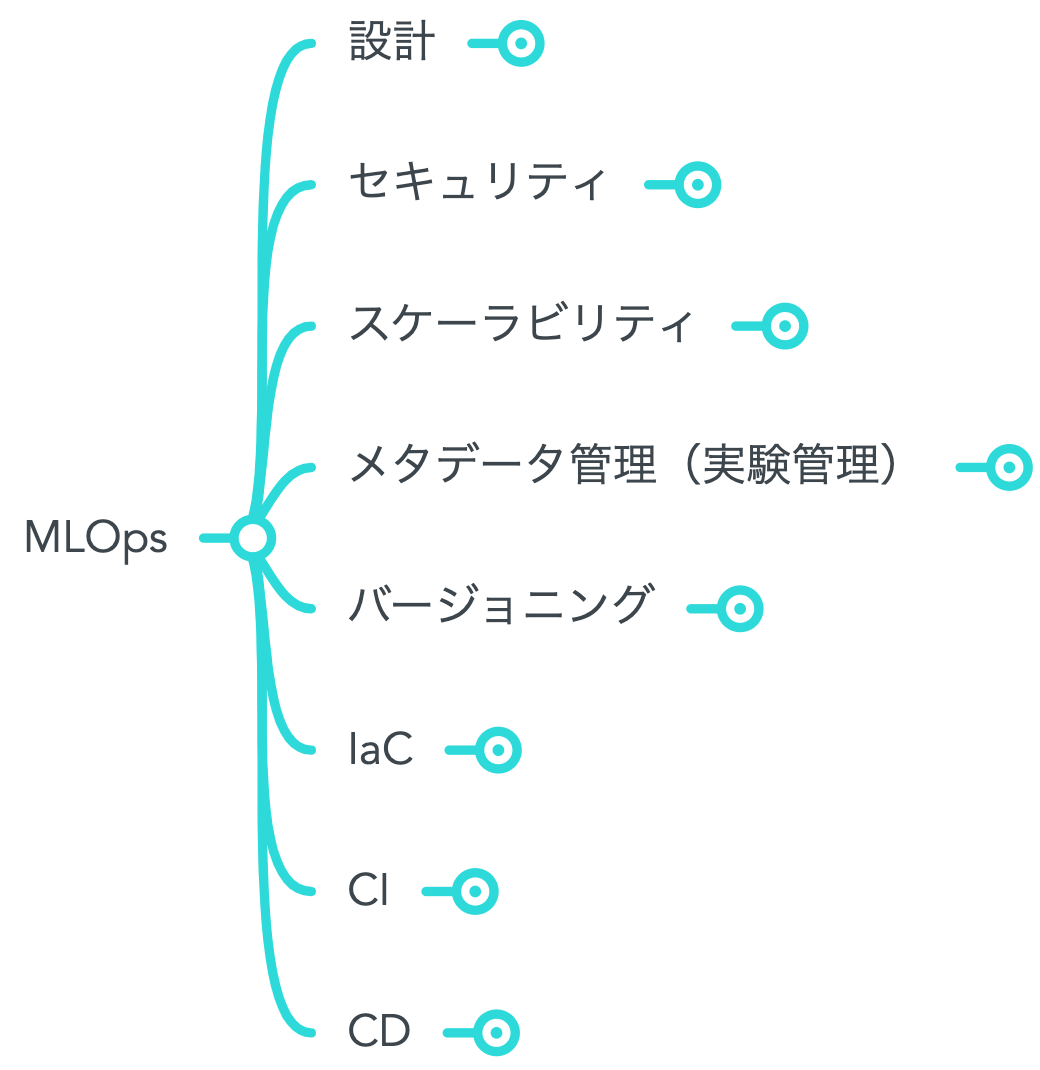
その上で、MindMeisterというマインドマップツールを用いて、要素技術を樹形図状に可視化してみました。

MindMeisterは樹形図の項目を表示したり隠したりできるので、MLOpsという広範な概念をまとめる際に重宝しました。すべての項目を表示すると、見通しが悪くなるので、上記の図では「スケーラビリティ」の一部の項目を中心に展開しています。
また、この樹形図と上述の目的を照らし合わせ、以下の形式でスコープを整理しました。

目的の「効率よく」という文言に図中の「(A) PJ管理・高速化」、「信頼性高く」という文言に「(B) 信頼性を高めるシステム連携」という戦略を割当て、優先度に応じて各項目を手段(戦術)として検討できるようにしています。
いずれの戦略も重要ですが、KINTOテクノロジーズではまず「(A) PJ管理・高速化」に焦点をあて、要素技術の開発ないし普及に努めていこうと考えています。今後投稿予定の連載では、この中の「パイプライン」および「メタデータ管理(実験管理)」について取組みを詳しく紹介していこうと考えており、この記事ではその概要についてご紹介できればと思います。
スケーラビリティ
樹形図の通り、KINTOテクノロジーズでは「スケーラビリティ」という大項目の中に「パイプライン」を位置付けています。スケーラビリティとは、コンピューティングリソースや組織の人的資本に関する拡張性のことを指し、スケールアウトやスケールインといった使われ方をします。データサイエンスのプロジェクトにおいて、このスケーラビリティは重要です。データには非決定的な性質があり、予め必要なコンピューティングリソースの見積もりが難しいためです。仮に既存の設定値でうまく動作していたとしても、たとえばCMや新商品の投入といった需要喚起策で急激にスパイクした場合はいかがでしょうか。アプリケーション内で使われているMLのモデルにもよりますが、メモリやCPU(GPU)のリソース不足で障害の原因となることがよくあります。そのため、このようなリソース不足のエラーに対して柔軟にスケールアウトやスケールアップする(不要時にはうまくスケールインまたはスケールダウン)仕組みが重要になってきます。データサイエンティストがモデルを開発する「学習基盤」、モデルをデプロイし推論結果を提供する「推論基盤」、それらの橋渡しとなる「パイプライン」において、このスケーラビリティの確保は重要です。
メタデータ管理(実験管理)
メタデータ管理では、開発したデータサイエンティストや機械学習エンジニア当人のサポート無しに実験結果やモデル開発を再現できるように、その過程のメタデータを記録し管理することが求められます。データサイエンスは組織においてまだまだ新しい領域だとみなされることも多く、特に他の職種の人々にとってその業務内容や関わり方について十分に認識できていることは少ないと考えます。時にはデータサイエンティスト同士でさえ、専門性(e.g. 時系列、画像、言語、テーブルデータ、地理空間、因果推論、ベイズ統計学など)が異なれば、そのデータサイエンスプロジェクトは容易にブラックボックス化してしまうことでしょう。このような状況では、データサイエンスプロジェクトの管理は属人的になり、作った当人がいない状況では誰もその業務を引継ぐことはできません。また、仮に他のデータサイエンティストがプロジェクトで使われている技術に習熟していたとしても、結果を再現するには具体的にどのようなデータがいつ使われ、ハイパーパラメータの正確な値は何であるのか、なぜそう設定したのかなど、膨大かつ厳密な情報が必要になります。そのため、良き機械学習基盤には、実行環境やデータ、利用するMLアルゴリズム、ハイパーパラメータ、評価指標、解釈などの自由記述文といったメタデータを容易に記録し保存できる機能が求められます。必要な情報がうまく管理されているメタデータレポジトリがあれば、それは実験結果やモデル開発を再現するための青写真となり、また情報を思い出すための試行錯誤も減らせるため、結果として実験サイクルを回すのにかかる時間を短縮し、プロジェクトの高速化が期待できます。そのため、メタデータ管理はMLOpsの目的に沿った戦略と考えます。
結果(Result)
MLOpsの全体像を可視化することで、図中の項目や要件を指しながら、必要な範囲の業務スコープを洗い出したり、他の部署のメンバーと共通認識が持ちやすくなったと思います。ただし、この全体像はまだバージョン1なので、業務で活用していく中で継続的な改善をしていきたいです。理想としては、AWSのWell-Architectedのように、機械学習プロジェクト立上げ期に真っ先に参照されるようなフレームワークへ成長させ、定着させていけたらいいなと考えています。
いかがでしたでしょうか。次回の連載では、本記事(のスケーラビリティの項)で軽く触れたパイプラインについて、SageMaker Pipelinesを用いたバッチパターンの推論基盤についてご紹介しています(Part2はこちらよりご確認ください)。引続きご覧いただけると嬉しいです。
Reference
Kreuzberger, D., Kühl, N., & Hirschl, S. (2022). Machine Learning Operations (MLOps): Overview, Definition, and Architecture. ArXiv, abs/2205.02302.
Sculley, D., Holt, G., Golovin, D., Davydov, E., Phillips, T., Ebner, D., Chaudhary, V., Young, M., Crespo, J.-F., & Dennison, D. (2015). Hidden Technical Debt in Machine Learning Systems.. In C. Cortes, N. D. Lawrence, D. D. Lee, M. Sugiyama & R. Garnett (eds.), NIPS (p./pp. 2503-2511), .
Shibui, Y., Byeon, S., Seo, J., & Jin, D. (2020). ml-system-design-pattern[GitHub Pages]. Retrieved from https://mercari.github.io/ml-system-design-pattern/