約10分で読めます
DataAnalytics
SageMakerを使った学習&推論のバッチパターン (2/4)
こんにちは。分析グループ(分析G)でMLOps/データエンジニアしてます伊ヶ崎(@_ikki02)です。
こちらは「KINTOテクノロジーズ株式会社にてどのようにMLOpsを適用していくのか」というテーマでの連載2本目です。1本目の記事「KINTOテクノロジーズのMLOpsを定義してみた」はリンクよりご確認ください。後続の記事では、SageMaker Experimentsを用いた実験管理、そして、他部署も巻き込んで開催した勉強会のお話などをしていければと考えています。
背景(Situation)
2本目のこの記事では、SageMaker Pipelinesを用いたバッチパターンの学習および推論の実装に焦点を当てていきたいと思います。バッチパターンとは、メルカリ社が公開しているml-system-design-patternにて「Batch training pattern」および「Batch pattern」として紹介されている内容(2022/8時点)を参考にしています。
実装の詳細に入る前に、当社のKINTO ONEにおける需要予測について、簡単に紹介します。KINTO ONEはトヨタの新車を自動車保険や自動車税なども込みで定額で利用できるサービスです。
マーケティング部門と分析グループにおいて、ユーザーの申込状況や各種主要KPIをダッシュボードで定期的に確認しています。その数値はデータ基盤のETL処理や機械学習のMLパイプラインを通して生成されるため、ダッシュボードの運用管理には、それらシステムの全体をうまくオーケストレーションする必要があります。
")
↑(2022/7時点のKINTO ONEサイトの車種ラインアップページ)
業務(Task)
ダッシュボード上で最新の情報を確認できるように、更新頻度をうまく設定する必要があります。データの更新を常時行えるようにしようとすると、任意のタイミングで更新リクエストを投げられるエンドポイントを起動する必要がありますが、リクエストがないときはインスタンスの起動分無駄なコストがかかり続けます。一方で、更新頻度が少なすぎると、古い情報を参照することになり、意思決定プロセスに影響を与えることが懸念されます。
今回の事例では、ダッシュボードの確認頻度は、基本的に週次の定例か、アナリストの突発的な閃きを随時確認するといったケースがほとんどなため、ダッシュボードの更新頻度は日次で前日分のデータを見ることができれば問題ないという要件でした。そのため、実装すべき更新プロセスはcron形式の日次スケジュールで起動できれば要件を満たせそうです。
なお、このバッチの実装に際しては、KINTO ONEのソフトウェアがAWS上で稼働しているということもあり、データ更新パイプラインもAWSのマネージドサービスを使うことで容易な連携が期待できました。
やったこと(Action)
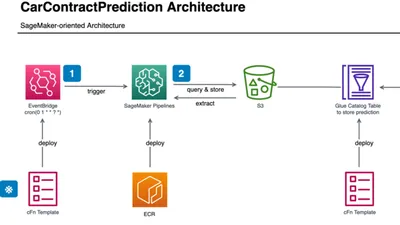
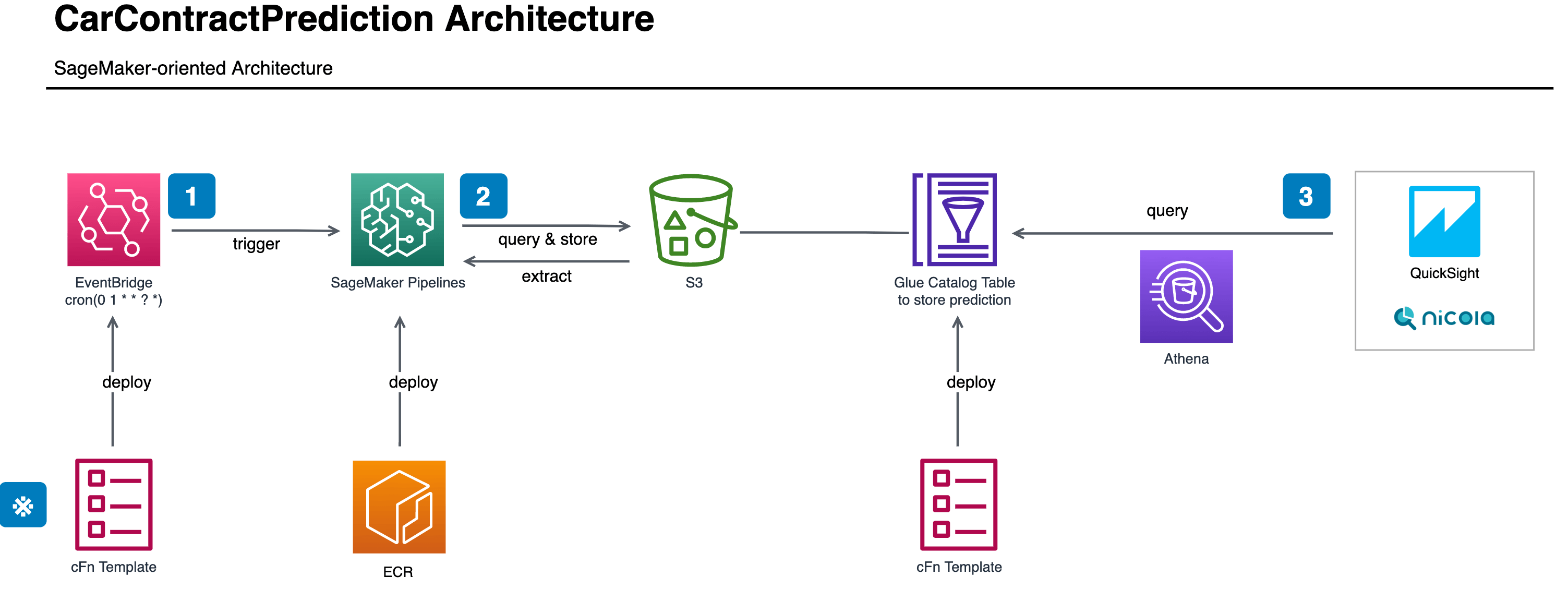
データ更新における、機械学習部分のアーキテクチャは以下の図の通りです。
SageMaker Pipelinesについて
SageMakerはAWSが提供する機械学習のマネージドな統合開発環境で、バッチ処理の実装に際しては、SageMaker Pipelinesという組込み機能を使うと良さそうでした。
SageMaker Pipelinesは、SageMaker ProcessingというETL処理に特化した別の組込み機能を機械学習パイプラインのステップとして実装することができ、そのステップをDAG(有向非巡回グラフ)として繋ぎ合わせることで機械学習パイプラインを実装することができます。DAGはもちろん可視化することもでき、以下のように表示できます。

実装は自由に作り込めますが、上図では各ステップを次のような責務で実装しています。
| ステップ名 | 簡単な説明 |
|---|---|
| Extract | AWS Athenaを用いてデータを抽出するステップ |
| PreProc | 時系列データ用の加工をする前処理ステップ |
| Train | SageMaker SDKを用いて、学習し、モデルを構築する学習ステップ |
| TrainEvaluation | 学習済みモデルの目的変数が基準を満たしているか評価する評価ステップ |
| Predict | 学習済みモデルと推論用データを用いて推論を行う推論ステップ |
| PostProc | 推論したデータをデータ基盤に連携できるよう加工する後処理ステップ |
このパイプラインをバッチとして実行するには、SageMaker Pipelinesとネイティブに組込みされているEventBridgeを活用することができます。EventBridgeはAWSの各リソースが生成するイベントに基づいてターゲットを起動するイベント駆動型のトリガーか、cron形式で定義されたスケジュールに基づいてターゲットを実行する方法から選択することができ、今回は日次のスケジュールを指定しています。以下の図のように起動が確認できます。

また、EventBridgeは監視の目的でも利用しています。「SageMaker Pipelinesの実行ステータス(成功、失敗、など)」および「SageMaker Pipelinesを構成する各ステップの実行ステータス」をイベントとして検知することができ、そのイベントをSNSトピックに飛ばすことで機械学習パイプラインの実行ステータスをリアルタイムで確認しています。ダッシュボードが最新の状態に保たれているかどうかはこの監視機構を通じてslackチャンネルに通知しており、もし何らかの理由で失敗すればすぐにパイプラインの実行ログを確認して対応できるようにしています。
QuickSightについて
上述のパイプラインの最後のステップではデータ基盤への連携を行っています。具体的には、推論結果のデータをGlueのカタログテーブルとして読み込めるようにテーブルスキーマを整え、Athenaで推論結果をクエリできるようにしています。パイプラインは日次で実行されるので、Glueのカタログテーブルのパーティションに日付単位で追加されるようにしています。このようにすることで、パイプラインを実行日指定で冪等に実装でき、パイプラインが失敗してもその日の推論結果について再実行すれば直るようにしています(同じ実行日については繰り返し実行しても結果が上書き更新されるだけで処理自体は変化しません)。
また、クエリを書くアナリスト視点では、必要な実行日分の推論結果にのみクエリすることで、クエリ処理時間および費用の削減に繋げています。
このようにAthena経由で推論結果を取得できるので、ダッシュボードとしてはQuickSightを使って更新しています。QuickSightはAWSが提供するマネージドなBIダッシュボードで、QuickSightが読み込むデータセットを"Athena"に指定することでSPICEというインメモリの集計エンジンに日次でデータを取込むことができます。ただし、このQuickSightの日次取込みは、上述の機械学習パイプラインとは別のスケジュールで起動するため、2つのスケジュールをうまく合わせる必要があります。
SageMaker Pipelinesを使って想定外だったのが、SageMaker Pipelinesの各ステップのインスタンス起動に都度5~10分ほどかかるため、上述のパイプラインのように、ステップが5つ同期的に繋がったパイプラインでは、インスタンスの起動と終了だけで1時間弱の実行時間を予め見積もっておく必要があります(上図のElapsed timeが該当します)。今回の要件としては、日次で実行できればよく、実行スケジュールに余裕があったため、特に問題にはなりませんでしたが、要件次第ではSageMaker Pipelinesのクセとして気を付ける必要がありそうです。
結果(Result)
SageMaker PipelinesとQuickSightを組み合わせたダッシュボード更新ロジックは、全体として一つのバッチとして見なすことができ、学習および推論のバッチパターンとしてみなすことができると考えています。バッチパターン採用の大きなメリットの一つは、管理を容易にできることです(前回の記事にて、MLOpsの目的のひとつは「PJ管理・高速化」だと紹介しました)。例えば、バッチではなくリアルタイム推論が可能な推論エンドポイントを用意する場合、新しいバージョンをデプロイし直す際には、ダウンタイムが発生しない、またはなるべくダウンタイムを短くするための別の仕組み(kubernetesのDeploymentなど)が必要になってきます。一方で、バッチの場合、冪等でさえあれば、デプロイに失敗したり動作がおかしくても、動作確認済みのバッチを再実行するだけで対処することができます。
バッチパターンはコスト削減も期待できます。常時稼働する推論エンドポイントに比べると、バッチパターンの実装は処理にかかった時間単位の課金で済むからです(サーバーレス)。
また、今回の実装においては、職掌別の責務に応じて運用を切分けできるメリットもあります。具体的には、推論データの更新を担う機械学習パイプラインの運用は機械学習エンジニアが担当し、QuickSightのダッシュボードの運用はBIエンジニアが担当するという棲分けができています。BIエンジニアは常にダッシュボードを管理しているので、推論データに異常があった際はすぐに気づくことができますが、大元の機械学習パイプラインの修正が難しかったりします。しかし、棲分けができているということは、例えば当日の更新処理が失敗していても、BIエンジニア自身が過去の推論結果を参照させることで暫定対応をすることができたり(機械学習エンジニアが機械学習パイプラインの修正をするまでの時間を稼ぐことができる)、ダッシュボード自体の公開を控えたりといった対応が可能になっています。
いかがでしたでしょうか。この記事では、SageMaker Pipelinesを用いた学習&推論システムのバッチパターンを紹介してきました。しかし、上述はあくまで定期実行部分のお話にすぎず、MLOpsとしてはまだまだ説明することがあります。次回の連載では、このパイプラインの定期実行の管理を含め、メタデータ管理(実験管理)についてご紹介していきたいと思います。引続きご覧いただける際は「SageMakerExperimentsを用いた実験管理 (3/4)」よりご覧ください。また、最新記事やその他情報発信については、本ページ最下部のTech Blogのツイッターをフォローいただけると嬉しいです。
Reference
Shibui, Y., Byeon, S., Seo, J., & Jin, D. (2020). ml-system-design-pattern[GitHub Pages]. Retrieved from https://mercari.github.io/ml-system-design-pattern/