Developing a System to Investigate Lock Contention (Blocking) Causes in Aurora MySQL

Hello. I am @p2sk from the DBRE team.
In the DBRE (Database Reliability Engineering) team, our cross-functional efforts are dedicated to addressing challenges such as resolving database-related issues and developing platforms that effectively balance governance with agility within our organization. DBRE is a relatively new concept, so very few companies have dedicated organizations to address it. Even among those that do, there is often a focus on different aspects and varied approaches. This makes DBRE an exceptionally captivating field, constantly evolving and developing.
For more information on the background of the DBRE team and its role at KINTO Technologies, please see our Tech Blog article, The need for DBRE in KTC.
Having been unable to identify the root cause of a timeout error resulting from lock contention (blocking) on Aurora MySQL, this article provides an example of how we developed a mechanism to consistently collect the necessary information to follow up on causes. In addition, this concept can be applied not only to RDS for MySQL but also to MySQL PaaS for cloud services other than AWS, as well as MySQL in its standalone form, so I hope you find this article useful.
Background: Timeout occurred due to blocking
A product developer contacted us to investigate a query timeout issue that occurred in an application. The error code was SQL Error: 1205, which suggests a timeout due to exceeding the waiting time for lock acquisition.
We use Performance Insights for Aurora MySQL monitoring. Upon reviewing the DB load during the relevant time period, there was indeed an increase in the "synch/cond/innodb/row_lock_wait_cond" wait event, which occurs when waiting to acquire row locks.
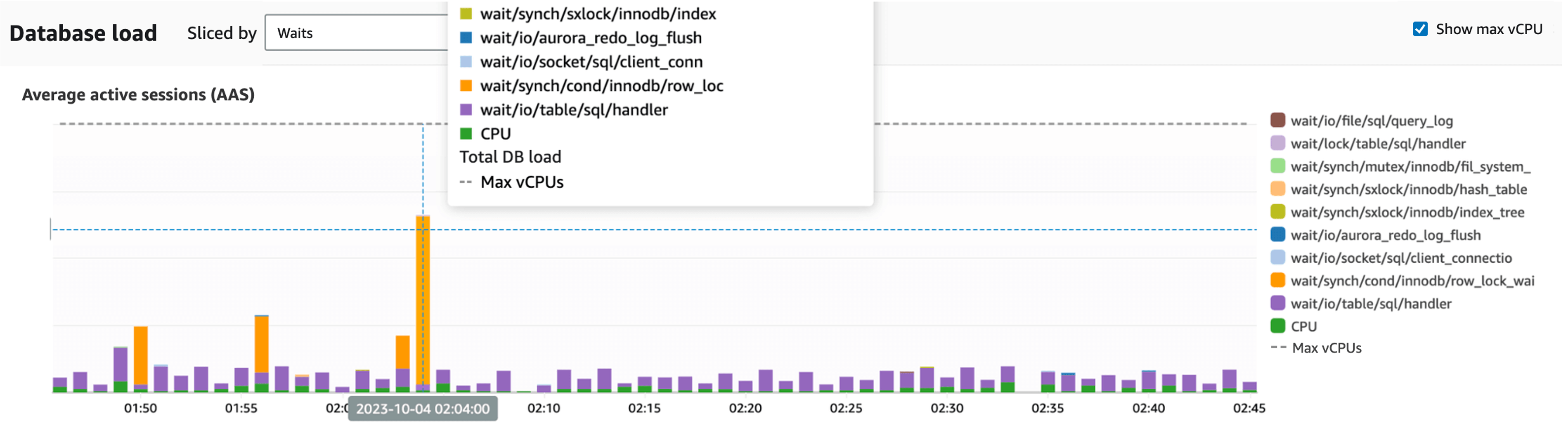 Performance Insights Dashboard: Lock waits (depicted in orange) are increasing
Performance Insights Dashboard: Lock waits (depicted in orange) are increasing
Performance Insights has a tab called "Top SQL" that displays SQL queries that were executed in descending order of their contribution to DB load at any given time. When I checked this, the UPDATE SQL was displayed as shown in the figure below, but only the SQL that timed out, the blocked SQL was being displayed.
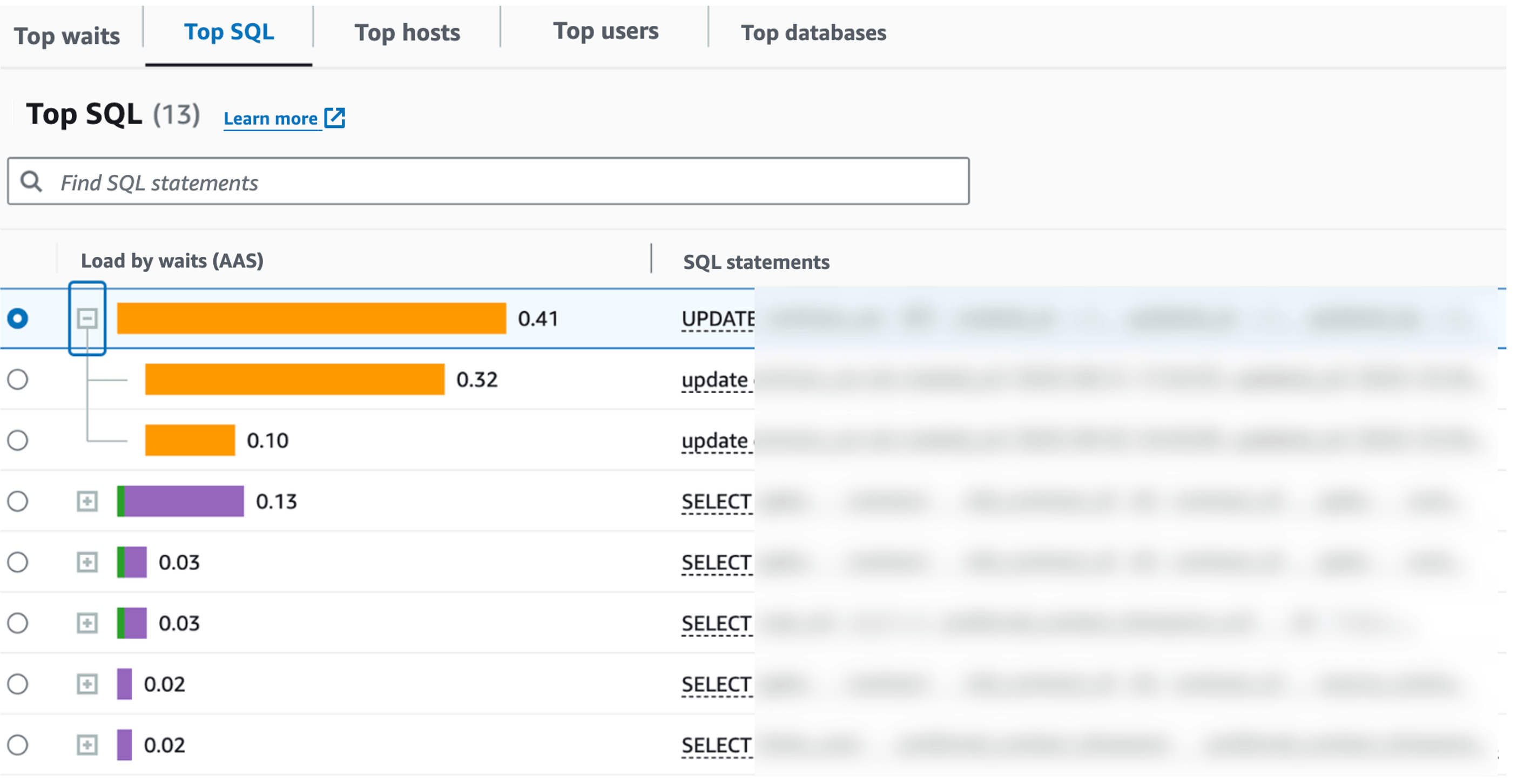 Top SQL tab: The update statement displayed is the one on the blocked side
Top SQL tab: The update statement displayed is the one on the blocked side
"Top SQL" is very useful to identify SQL queries, so for example, it has a high contribution rate during periods of high CPU load. On the other hand, in some cases, such as this one, it is not useful to identify the root cause of blocking. This is because the root cause of SQL (blocker) that is causing the blocking may not by itself contribute to the database load.
For example, suppose the following SQL is executed in a session:
-- Query A
start transaction;
update sample_table set c1 = 1 where pk_column = 1;
This query is a single row update query with a primary key, so it completes very quickly. However, if the transaction is left open and the following SQL is executed in another session, it will be waiting for lock acquisition and blocking will occur.
-- Query B
update sample_table set c2 = 2
Query B continues to be blocked, so it will appear in "Top SQL" due to longer wait times. Query A, conversely, completes execution instantly and does not appear in "Top SQL," nor is it recorded in the MySQL slow query log.
This example is extreme, but it illustrates a case in which it is difficult to identify blockers using Performance Insights.
In contrast, there are cases where Performance Insights can identify blockers. For example, the execution of numerous identical UPDATE SQL queries can lead to a "Blocking Query = Blocked Query" scenario. In such case, Performance Insights is sufficient. However, the causes of blocking are diverse, and current Performance Insights has its limitations.
Performance Insights was also unable to identify the blocker in this incident. We looked through various logs to determine the cause. Various logs were reviewed, including Audit Log, Error Log, General Log, and Slow Query Log, but the cause could not be determined.
Through this investigation, we found that, currently, there is insufficient information to identify the cause of blocking. However, even if the same event occurs in the future, the situation in which we have no choice but to answer "Because of the lack of information, the cause is unknown," needs to be improved. Therefore, we decided to conduct a "solution investigation" to identify the root cause of the blocking.
Solution Investigation
We investigated the following to determine potential solutions for this issue:
- Amazon DevOps Guru for RDS
- SaaS monitoring
- DB-related OSS and DB monitoring tools
Each of these is described below.
Amazon DevOps Guru for RDS
Amazon DevOps Guru is a machine learning-powered service to analyze metrics and logs from monitored AWS resources, automatically detects performance and operational issues, and provides recommendations for resolving them. The DevOps Guru for RDS is a feature within DevOps Guru specifically dedicated to detecting DB-related issues. The difference from Performance Insights is that DevOps Guru for RDS automatically analyzes issues and suggests solutions. It conveys the philosophy of AWS to realize a world of "managed solutions to issues in the event of an incident."
When the actual blocking occurred, the following recommendations were displayed:
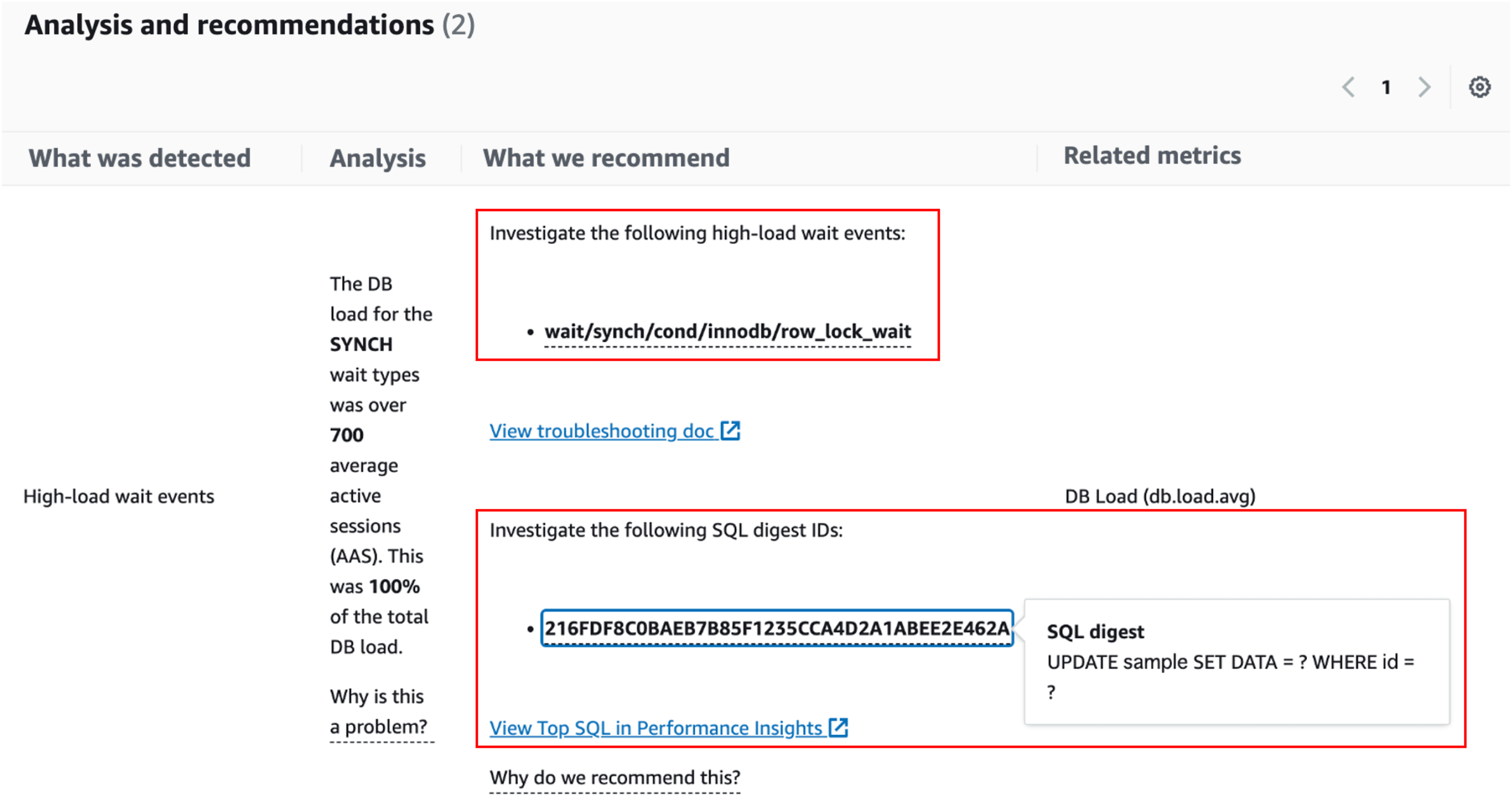
DevOps Guru for RDS Recommendations: Suggested wait events and SQL to investigate
The SQL displayed was the SQL on the blocked side, and it seemed difficult to identify the blocker. Currently, it seems that it only presents link to document that describes how to investigate when a "synch/cond/innodb/row_lock_wait" wait event is contributing to the DB load. Therefore, currently, it is necessary for humans to make final judgments on the proposed causes and recommendations. However, I feel that in the future a more managed incident response experience will be provided.
SaaS monitoring
A solution that can investigate the cause of database blocking at the SQL level is Datadog Database Monitoring feature. However, it currently supports only PostgreSQL and SQL Server, not MySQL. Similarly, in tools like New Relic and Mackerel, it appears that the feature to conduct post-blocking investigations is not available.
DB-related OSS and DB monitoring tools
We also investigated the following other DB-related OSS and DB monitoring tools, but no solutions seemed to be offered.
On the other hand, the SQL Diagnostic Manager for MySQL was the only tool capable of addressing the MySQL blocking investigation. Despite being a DB monitoring tool for MySQL, we opted not to test or adopt it due to its extensive functionalities exceeding our needs, and the price being a limiting factor.
Based on this investigation, we found that there were almost no existing solutions, so we decided to create our own mechanism. Therefore, we first organized the "manual investigation procedure for blocking causes." Since version 2 of Aurora MySQL (MySQL 5.7) is scheduled to reach EOL on October 31 of this year, the target is Aurora 3 (MySQL 8.0). Also, the target storage engine is InnoDB.
Manual investigation procedure for blocking causes
To check the blocking information in MySQL, you need to refer to the following two types of tables. Note that performance_schema must be enabled by setting the MySQL parameter performance_schema to 1.
- performance_schema.metadata_locks
- Contains acquired metadata lock information
- Check for blocked queries with lock_status = 'pending' records
- performance_schema.data_lock_waits
- Contains blocking information at the storage engine level (e.g., rows)
For example, if you select performance_schema.data_lock_waits in a situation where metadata-caused blocking occurs, you will not get any record. Therefore, the information stored in the two types of tables will be used together to conduct the investigation. It is useful to use a View that combines these tables with other tables for easier analysis. The following is an introduction.
Step 1: Make use of sys.schema_table_lock_waits
sys.schema_table_lock_waits is a SQL Wrapper View using the following three tables:
- performance_schema.metadata_locks
- performance_schema.threads
- performance_schema.events_statements_current
Selecting View while a Wait is occurring for acquiring metadata lock on the resource, will return the relevant records.
For example, the following situation.
-- Session 1: Acquire and keep metadata locks on tables with lock tables
lock tables sample_table write;
-- Session 2: Waiting to acquire incompatible shared metadata locks
select * from sample_table;
In this situation, select sys.schema_table_lock_waits to get the following recordset.
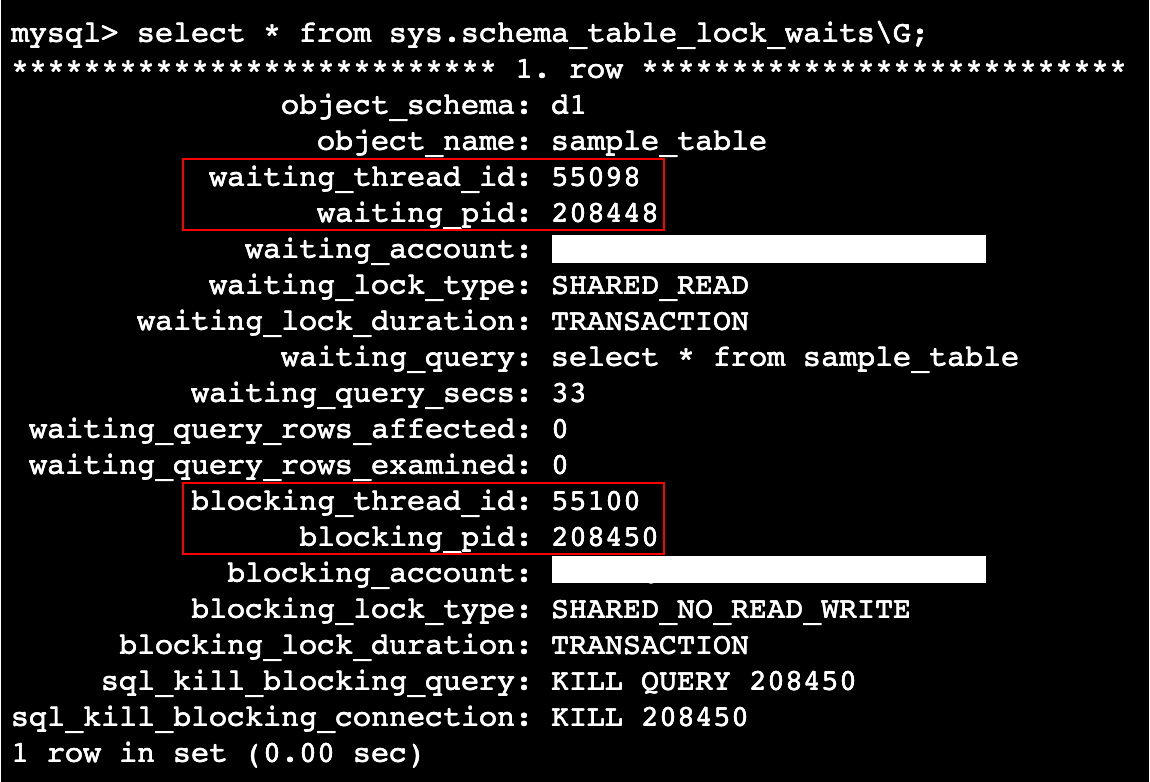
The results of this View do not directly identify the blocker in SQL. The blocked query can be identified in the waiting_query column, but there is no blocking_query column, so I will use blocking_thread_id or blocking_pid to identify it.
How to identify blockers: SQL-based method
When identifying blockers on an SQL basis, use the thread ID of the blocker. The following query using performance_schema.events_statements_current will retrieve the last SQL text executed by the relevant thread.
SELECT THREAD_ID, SQL_TEXT
FROM performance_schema.events_statements_current
WHERE THREAD_ID = 55100\G
The result, for example, should look like this. I found out that it was performing lock tables on sample_table, and I was able to identify the blocker.

This method has its drawbacks. If the blocker executes another additional query after acquiring locks, the SQL will be retrieved and the blocker cannot be identified. For example, the following situation.
-- Session 1: Acquire and keep metadata locks on tables with lock tables
lock tables sample_table write;
-- Session 1: Run another query after lock tables
Select 1;
If you execute a similar query in this state, you will get the following results.

Alternatively, performance_schema.events_statements_history can be used to retrieve the last N SQL texts executed by the relevant thread.
SELECT THREAD_ID, SQL_TEXT
FROM performance_schema.events_statements_history
WHERE THREAD_ID = 55100
ORDER BY EVENT_ID\G;
The result should look like this:
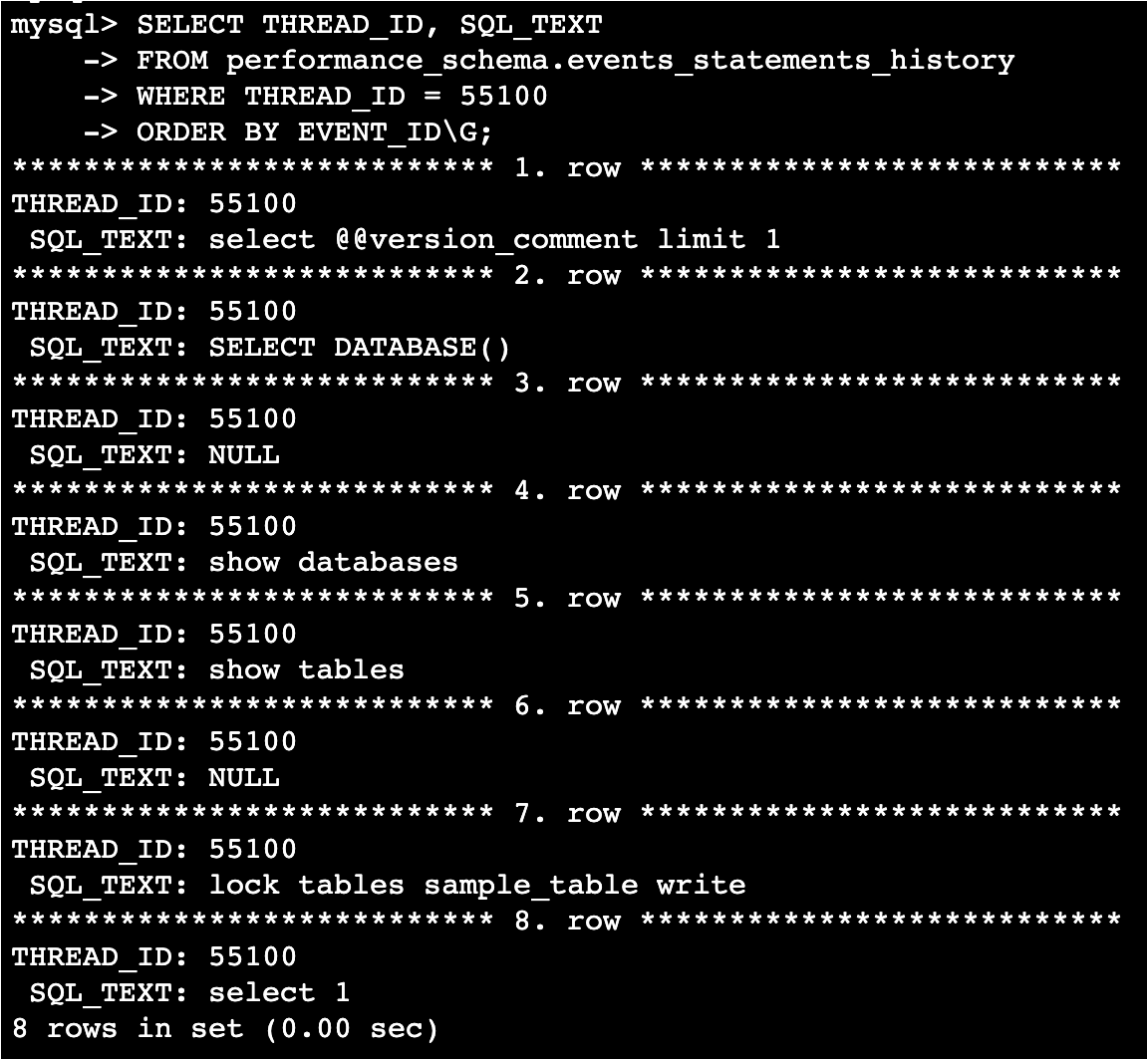
The blocker could also be identified because the history could be retrieved. The parameter performance_schema_events_statements_history_size can be used to change how many SQL history entries are kept per thread (set to 10 during verification). The larger the size, the more likely it is to identify blockers, but this also means using more memory, and there's a limit to how large the size can be, so finding a balance is important. Whether history retrieval is enabled can be checked by selecting performance_schema.setup_consumers. It seems that the performance_schema.events_statements_history retrieval is enabled by default for Aurora MySQL.
How to identify blockers: Log-based method
When identifying blockers on an log basis, use the General Log and Audit Log. For example, if General Log retrieval is enabled on Aurora MySQL, all SQL history executed by the process can be retrieved using the following query in CloudWatch Logs Insights.
fields @timestamp, @message
| parse @message /(?<timestamp>[^\s]+)\s+(?<process_id>\d+)\s+(?<type>[^\s]+)\s+(?<query>.+)/
| filter process_id = 208450
| sort @timestamp asc
Executing this query results in the following:
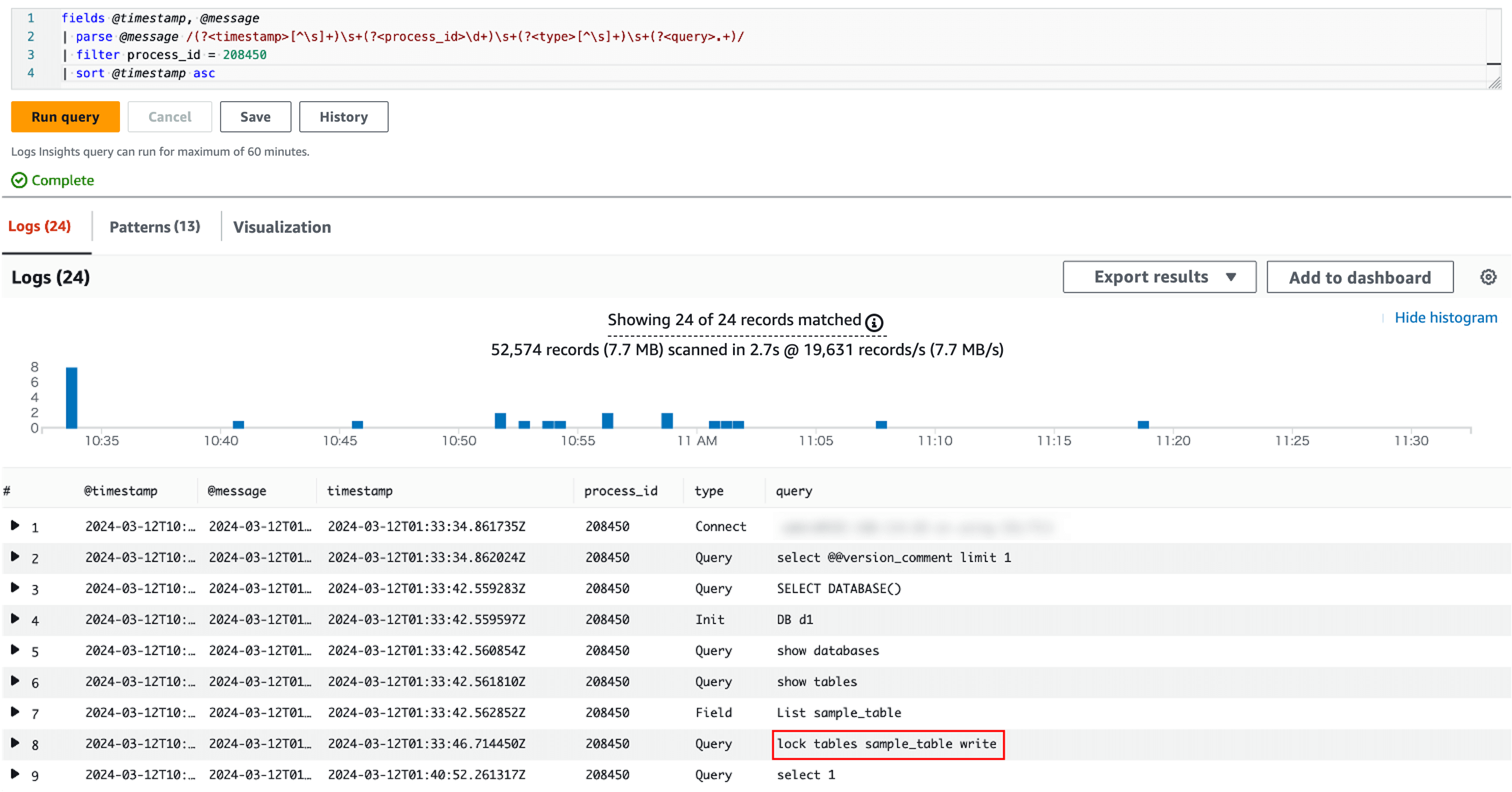 CloudWatch Logs Insights Query Execution Result: SQL blocked by red box is a blocker
CloudWatch Logs Insights Query Execution Result: SQL blocked by red box is a blocker
We basically enable the General Log. There is a concern that SQL-based blockers will be removed from the history table and cannot be identified. Therefore, we decided to use a log-based identification method this time.
Considerations for identifying blockers
Identifying blockers ultimately requires human visual confirmation and judgment. The reason is that the lock acquisition information is directly related to the thread, and the SQL executed by the thread changes from time to time. Therefore, in a situation like the example, "the blocker finished executing the query, but the lock has been acquired," it is necessary to infer the root cause SQL from the history of SQL executed by the blocker process.
However, just knowing the blocker thread ID or process ID can be expected to significantly improve the rate of identifying the root cause.
Step 2: Make use of sys.innodb_lock_waits
This is a SQL Wrapper View using the following three tables:
- performance_schema.data_lock_waits
- information_schema.INNODB_TRX
- performance_schema.data_locks
If you select this View while a Wait is occurring for lock acquisition implemented by the storage engine (InnoDB), the record will be returned.
For example, the following situation.
-- Session 1: Keep the transaction that updated the record open
start transaction;
update sample_table set c2 = 10 where c1 = 1;
-- Session 2: Try to update the same record
delete from sample_table where c1 = 1;
In this situation, select sys.innodb_lock_waits to get the following recordset.
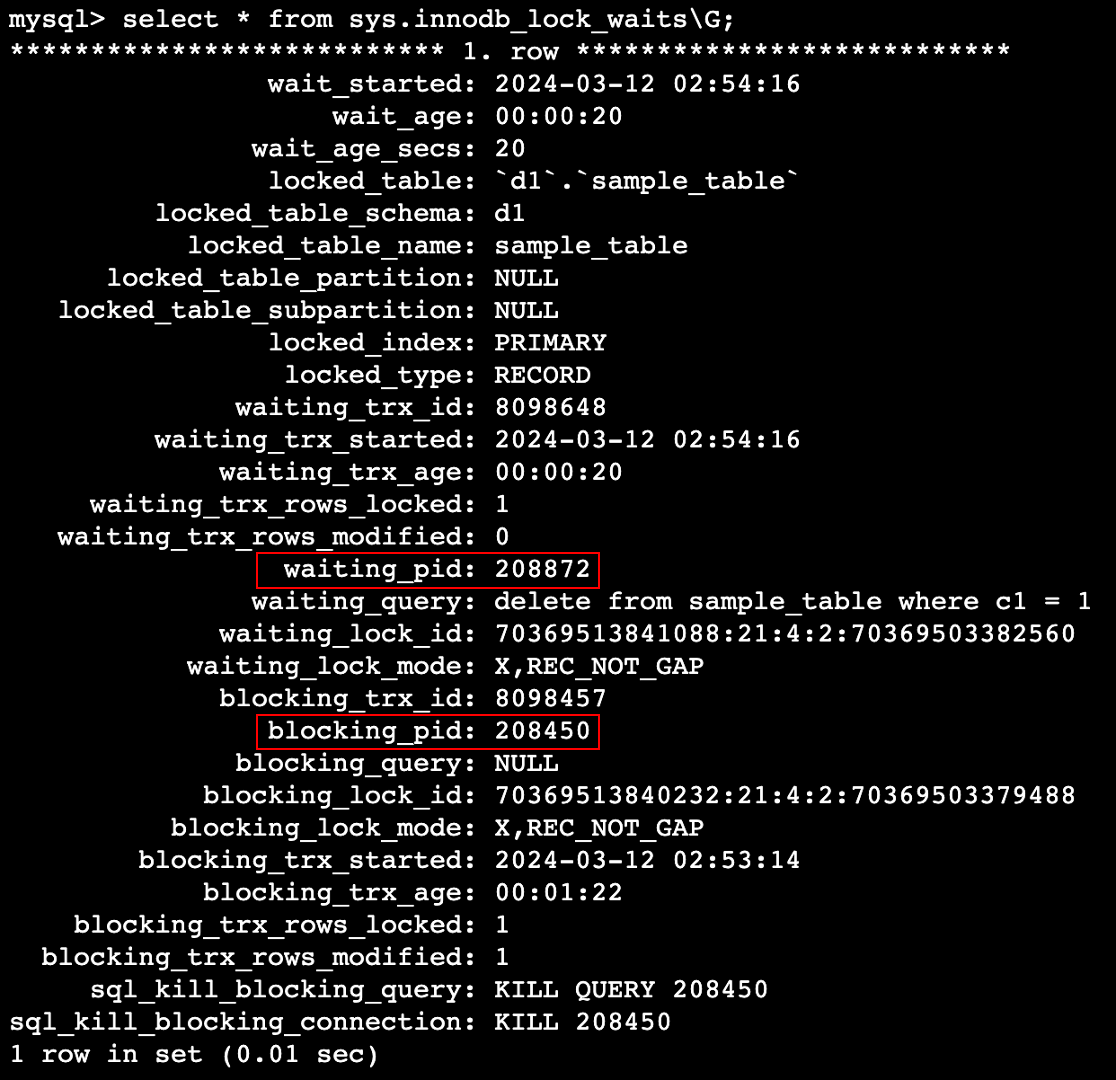
From this result, as with sys.schema_table_lock_waits, it is not possible to directly identify the blocker. Therefore, blocking_pid is used to identify the blocker using the log-based method described above.
fields @timestamp, @message
| parse @message /(?<timestamp>[^\s]+)\s+(?<process_id>\d+)\s+(?<type>[^\s]+)\s+(?<query>.+)/
| filter process_id = 208450
| sort @timestamp asc
Executing this query results in the following:
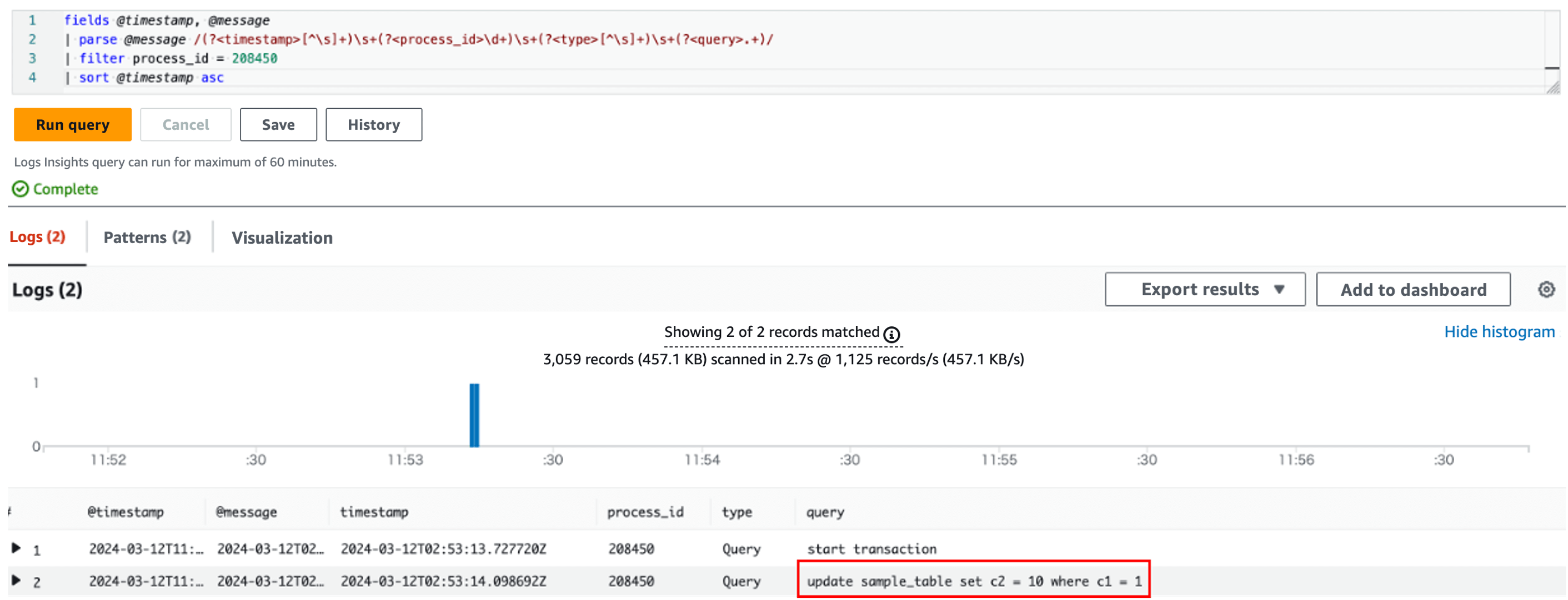 CloudWatch Logs Insights Query Execution Result: SQL blocked by red box is a blocker
CloudWatch Logs Insights Query Execution Result: SQL blocked by red box is a blocker
Summary of the above
As a first step for post-investigation of root cause of Aurora MySQL blocking, I have outlined how to investigate the root cause when blocking occurs. The investigation procedure is as follows:
- Identify blocker process ID using two types of Views:
sys.schema_table_lock_waitsandsys.innodb_lock_waits - Use CloudWatch Logs Insights to retrieve the SQL execution history of the process ID from the General Log
- Identify (estimate) the root cause SQL while visually checking
Step 1 must be in a "blocking condition" to get results. Therefore, periodically collecting and storing two types of View equivalent information at N-second intervals enables post-investigation. In addition, it is necessary to select N such that the relationship of N seconds < Application timeout period is valid.
Additional information about blocking
Here are two additional points about blocking. Firstly, I will outline the difference between deadlocks and blocking, followed by an explanation of the blocking tree.
Differences from deadlocks
It is rare but blocking is sometimes confused with deadlock, so let's summarize the differences. A deadlock is also a form of blocking, but it is determined that the event will not be resolved unless one of the processes is forced to roll back. Therefore, when InnoDB detects a deadlock, automatic resolution occurs relatively quickly. On the other hand, in the case of normal blocking, there is no intervention by InnoDB because it is resolved when the blocker query is completed. A comparison between the two is summarized in the table below.
| Blocking | Deadlock | |
|---|---|---|
| Automatic resolution by InnoDB | Not supported | Supported |
| Query completion | Both the blocker and the blocked side will eventually complete execution unless terminated midway due to a KILL or timeout error. | One transaction is forced to terminate by InnoDB. |
| General solution | It can be resolved spontaneously by the completion of the blocker query or resolved with a timeout error after the application-set query timeout period elapses. | After InnoDB detects a deadlock, it can be resolved by forcing one of the transactions to roll back. |
Blocking tree
It is not an official term of MySQL, but I will describe the blocking tree. This refers to a situation where "a query that is a blocker is also blocked by another blocker."
For example, the following situation.
-- Session 1
begin;
update sample_table set c1 = 2 where pk_column = 1;
-- Session 2
begin;
update other_table set c1 = 3 where pk_column = 1;
update sample_table set c1 = 4 where pk_column = 1;
-- Session 3
update other_table set c1 = 5 where pk_column = 1;
In this situation, when you select sys.innodb_lock_waits, you will get two records: "Session 1 is blocking Session 2" and "Session 2 is blocking Session 3." In this case, the blocker from the perspective of Session 3 is Session 2, but the root cause of the problem (Root Blocker) is Session 1. Thus, blocking occurrences can sometimes be tree-like, making log-based investigations in such cases even more difficult. The importance of collecting information on blocking beforehand lies in the difficulty of investigating such blocking-related causes.
In the following, I will introduce the design and implementation of the blocking information collection mechanism.
Architectural Design
We have multiple regions and multiple Aurora MySQL clusters running within a region. Therefore, the configuration needed to minimize the deployment and operational load across regions and clusters.
Other requirements include:
Functional requirements
- Can execute any SQL periodically against Aurora MySQL
- Can collect Aurora MySQL information from any region
- Can manage the DB to be executed
- Can store Query execution results in external storage
- Can stored SQL data be queried
- Privileges can be managed to restrict access to the collected data in the source database, allowing only those authorized to view it.
Non-functional requirements
- Minimal overhead on the DB to be collected
- Data freshness during analysis can be limited to a time lag of about five minutes
- Notification will alert us if the system becomes inoperable
- Response in seconds during SQL-based analysis
- Collected logs can be aggregated into some kind of storage in a single location
- Can minimize the financial costs of operations
In addition, the tables to be collected were organized as follows.
Table to be Collected
Even though you have the option to periodically gather specific results from sys.schema_table_lock_waits and sys.innodb_lock_waits, the system load will increase due to the complexity of these Views when compared to directly selecting data from the original tables. Therefore, to meet the non-functional requirement of 'Minimal overhead on the DB to be collected,' we opted to select the following six tables, which serve as the source for the Views. These views were then constructed on the query engine side, enabling the query load to be shifted away from the database side.
- Original tables of sys.schema_table_lock_waits
- performance_schema.metadata_locks
- performance_schema.threads
- performance_schema.events_statements_current
- Original tables of sys.innodb_lock_waits
- performance_schema.data_lock_waits
- information_schema.INNODB_TRX
- performance_schema.data_locks
The easiest way would be to use MySQL Event, MySQL's task scheduling feature, to execute SELECT queries on these tables every N seconds and store the results in a dedicated table. However, this method is not suitable for the requirements because it generates a high write load to the target DB and requires individual login to the DB to check the results. Therefore, other methods were considered.
Architecture Patterns
First, an abstract architecture diagram was created as follows:
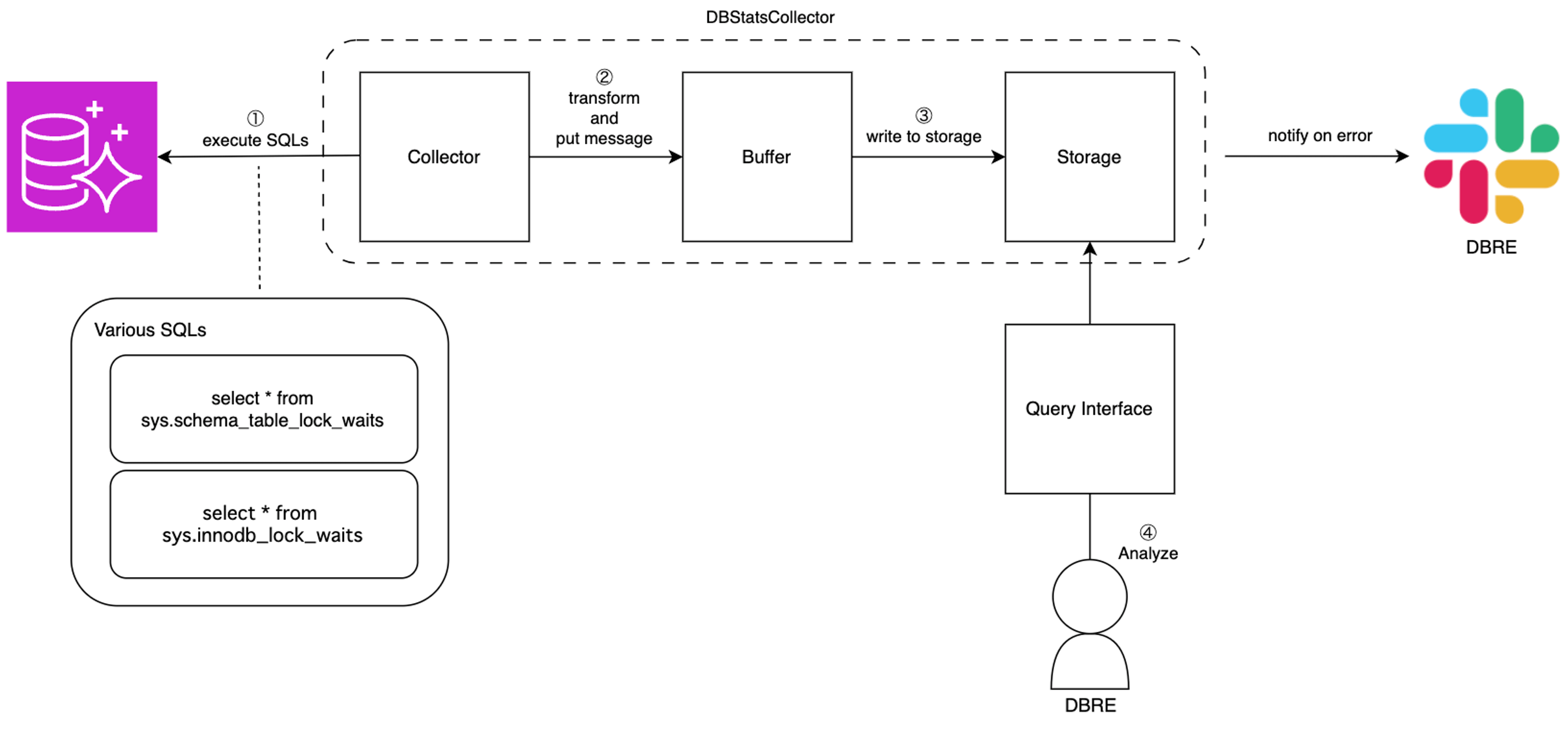
For this architecture diagram, the AWS services to be used at each layer were selected based on the requirements.
Collector service selection
After evaluating the following services based on our past experiences, we decided to proceed with the design mainly using Lambda.
- EC2
- It is assumed that this workload does not require as much processing power as running EC2 all the time, and is considered excessive from both an administrative and cost perspective
- The mechanism depends on the deployment to EC2 and execution environment on EC2
- ECS on EC2
- It is assumed that this workload does not require as much processing power as running EC2 all the time, and is considered excessive from both an administrative and cost perspective
- Depends on Container Repository such as ECR
- ECS on Fargate
- Serverless like Lambda, but depends on Container Repository such as ECR
- Lambda
- It is more independent than other compute layer services, and is considered best suited for performing the lightweight processing envisioned at this time
Storage / Query Interface service selection
Storage / Query Interface was configured with S3 + Athena. The reasons are as follows.
- Want to run SQL with JOIN
- CloudWatch Logs was also considered for storage, but rejected due to this requirement
- Fast response times and transaction processing are not required
- No advantage of using DB services such as RDS, DynamoDB, or Redshift
Buffer service selection
We have adopted Amazon Data Firehose as the buffer layer between the collector and storage. We also considered Kafka, SQS, Kinesis Data Streams, etc., but we chose Firehose for the following reasons.
- Put to Firehose and data will be automatically stored in S3 (no additional coding required)
- Can reduce the number of files in S3 by buffering them based on time or data size, enabling bulk storage in S3
- Automatic compression reduces file size in S3
- Dynamic partitioning feature allows dynamic determination of S3 file paths
Based on the services selected above, five architecture patterns were created. For simplicity, the figure below illustrates one region.
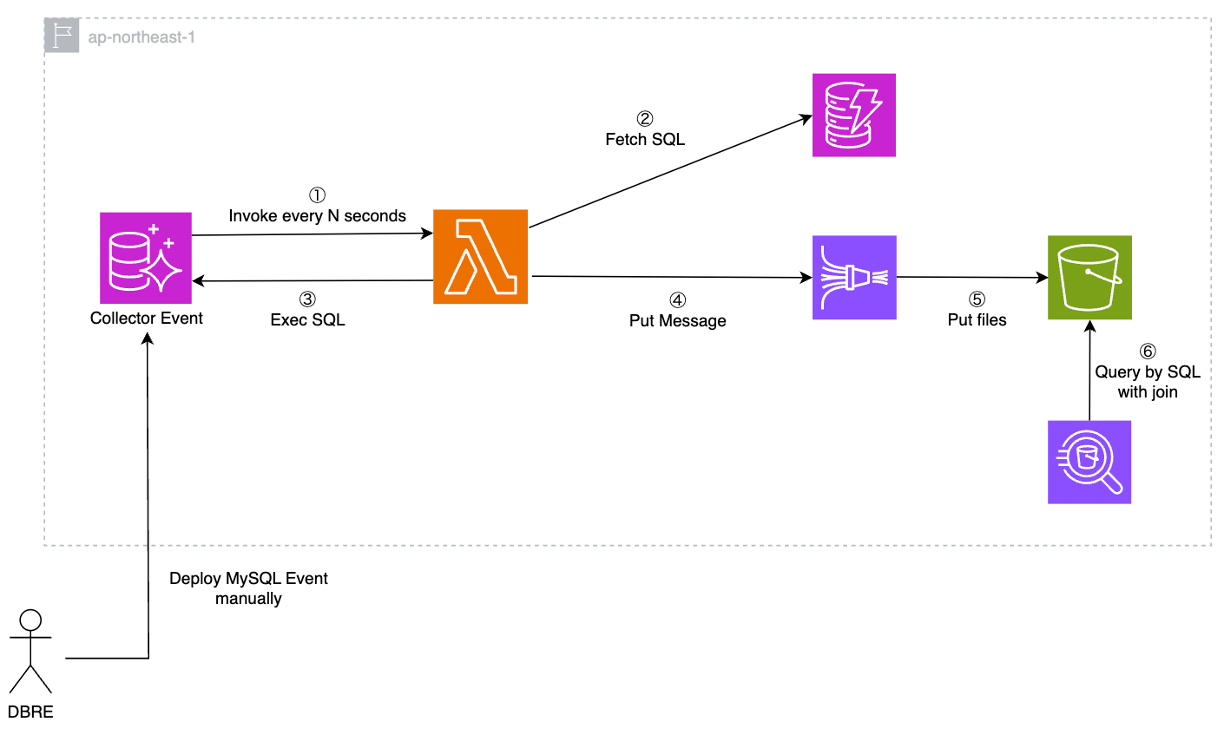
Option 1: Execute Lambda in MySQL Event
Aurora MySQL is integrated with Lambda. This pattern is used to periodically invoke Lambda using MySQL Event. The architecture is as follows:
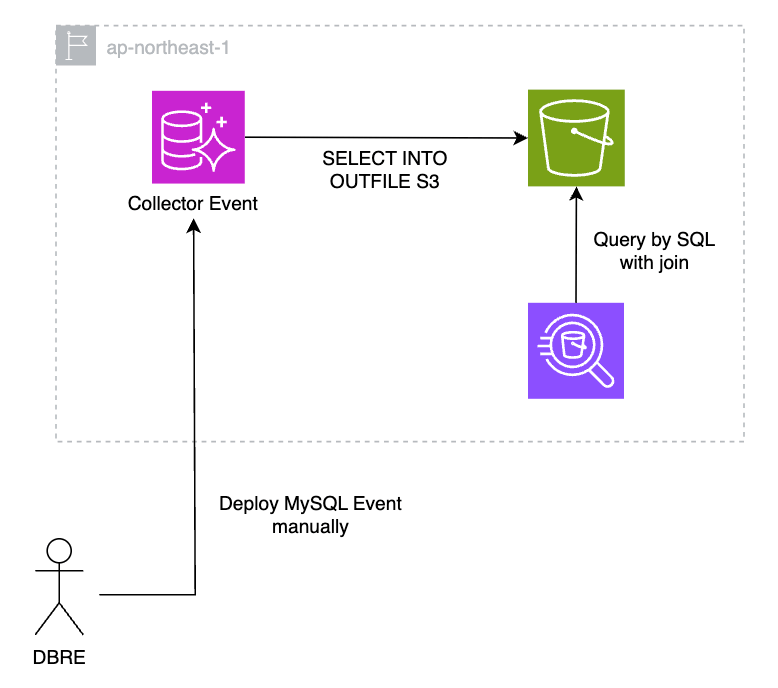
Option 2: Save data directly from Aurora into S3
Aurora MySQL is also integrated with S3 and can store data directly in S3. The architecture is very simple, as shown in the figure below. On the other hand, as in option 1 also requires deployment of MySQL Events, it will be necessary to deploy across multiple DB clusters when creating or modifying new Events. It must be handled manually and individually, or a mechanism must be in place to deploy to all target clusters.
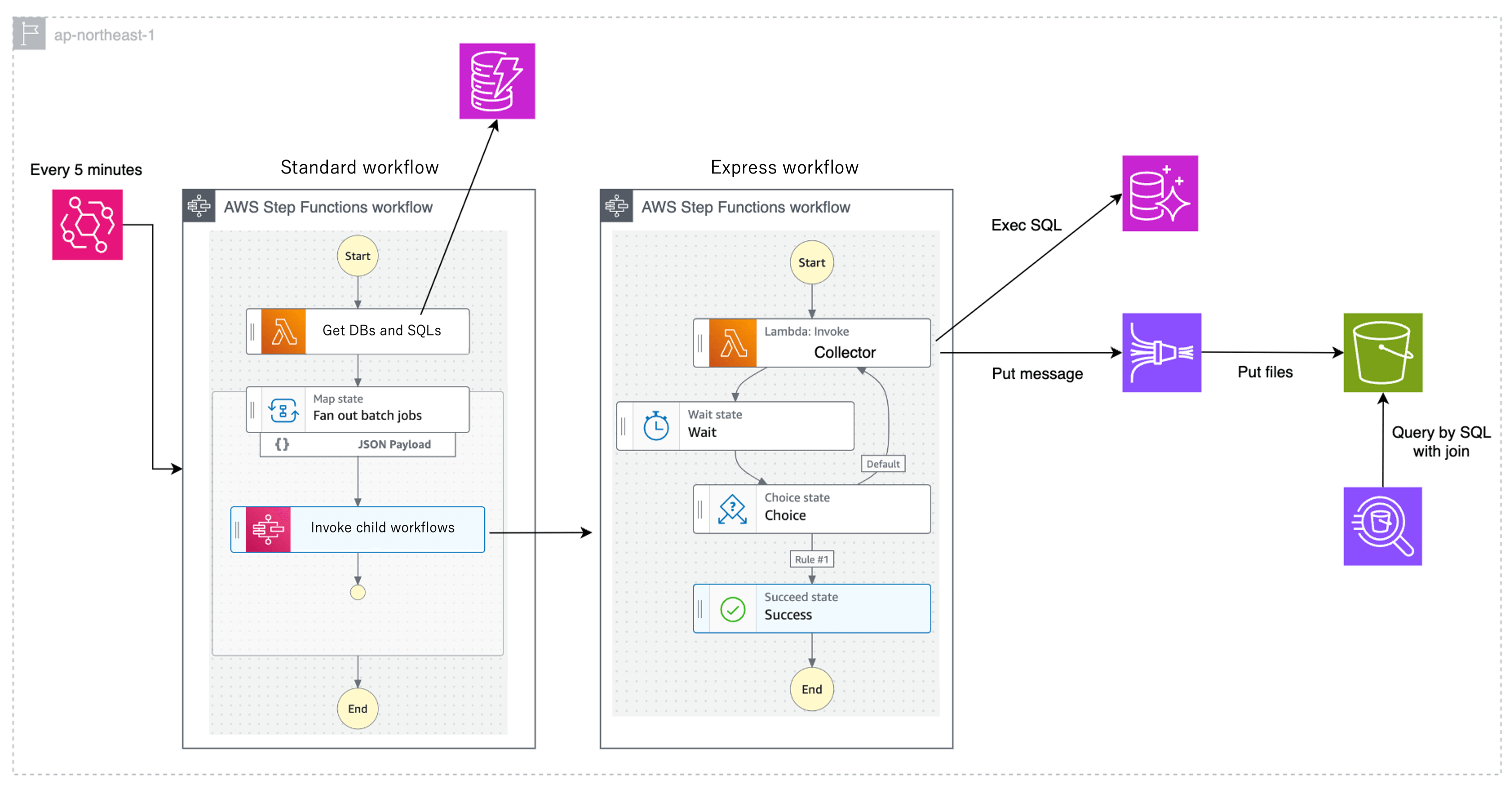
Option 3: Step Functions Pattern A
This pattern combines Step Functions and Lambda. By using the Map state, child workflows corresponding to the collector can be executed in parallel for each target cluster. The process of "executing SQL at N-second intervals" is implemented using a combination of Lambda and Wait state. This implementation results in a very large number of state transitions. For AWS Step Functions Standard Workflows, pricing is based on the number of state transitions, while for Express Workflows, there is a maximum execution time of five minutes per execution, but no charge is incurred based on the number of state transitions. Therefore, Express Workflows are implemented where the number of state transitions is large. This AWS Blog was used as a reference.
Option 4: Step Functions Pattern B
Like option 3, this pattern combines Step Functions and Lambda. The difference from option 3 is that the process "Execute SQLat N-second intervals" is implemented in Lambda, and "Execute SQL -> N-second Sleep" is repeated for 10 minutes. Since Lambda execution is limited to a maximum of 15 minutes, Step Functions is invoked in EventBridge every 10 minutes. Because the number of state transitions is very small, the financial cost of Step Functions can be reduced. On the other hand, since Lambda will continue to run even during Sleep, the Lambda billing amount is expected to be higher than in option 3.
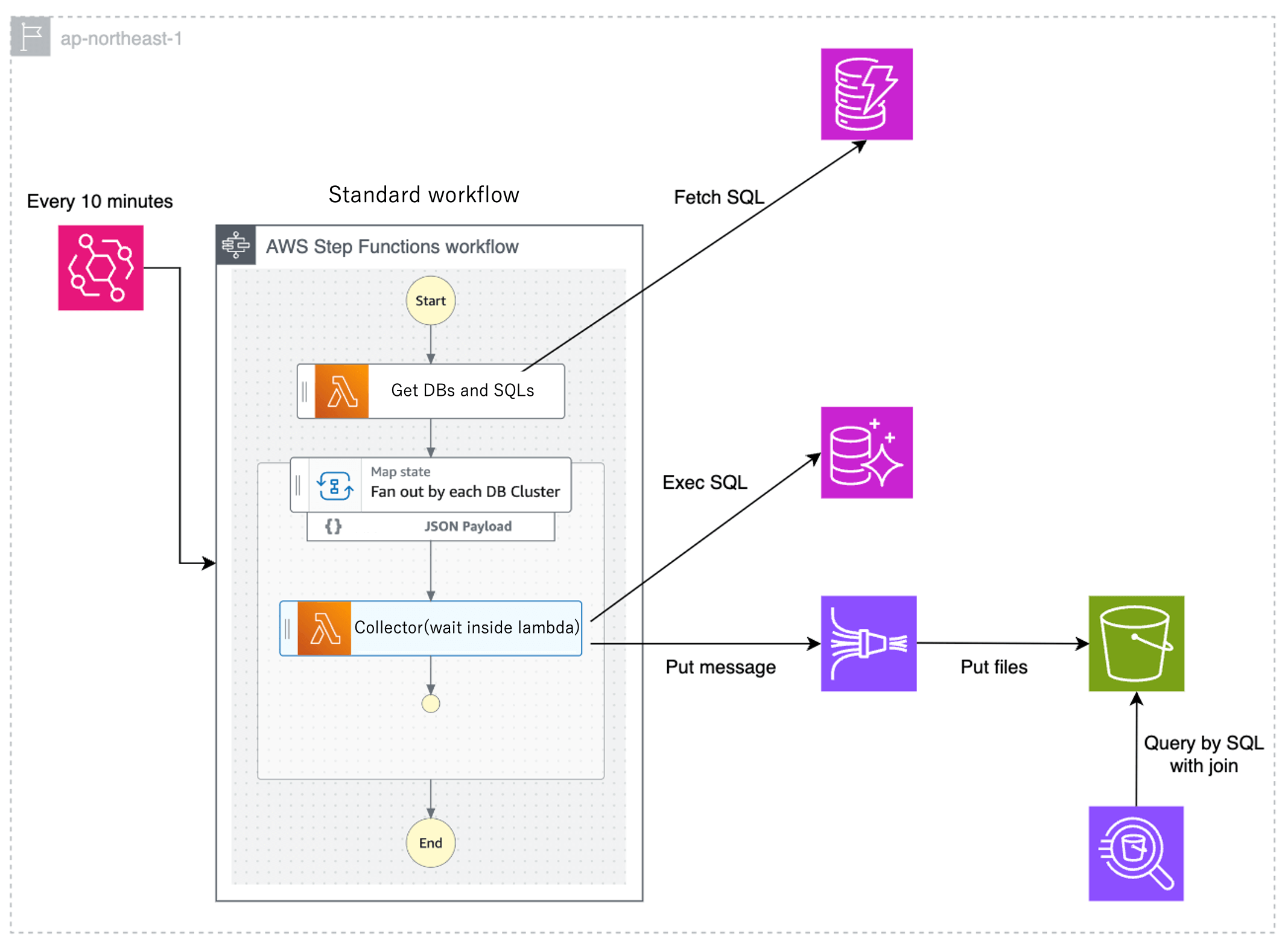
Option 5: Sidecar Pattern
We primarily use ECS as our container orchestration service, assuming that there is at least one ECS cluster accessible to each Aurora MySQL. Placing a newly implemented Collector as a Sidecar in a task has the advantage of not incurring additional computing resource costs, such as Lambda. However, if it does not fit within the resources of Fargate, it needs to be expanded.
Architecture Comparison
The results of comparing each option are summarized in the table below.
| Option 1 | Option 2 | Option 3 | Option 4 | Option 5 | |
|---|---|---|---|---|---|
| Developer and operator | DBRE | DBRE | DBRE | DBRE | Since the container area falls outside our scope, it is necessary to request other teams |
| Financial costs | ☀ | ☀ | ☀ | ☁ | ☀ |
| Implementation costs | ☁ | ☀ | ☁ | ☀ | ☀ |
| Development Agility | ☀ (DBRE) | ☀ (DBRE) | ☀ (DBRE) | ☀ (DBRE) | ☁ (must be coordinated across teams) |
| Deployability | ☁ (Event deployment either requires manual intervention or a dedicated mechanism) | ☁ (Event deployment either requires manual intervention or a dedicated mechanism) | ☀ (IaC can be managed with existing development flow) | ☀ (IaC can be managed with existing development flow) | ☁ (must be coordinated across teams) |
| Scalability | ☀ | ☀ | ☀ | ☀ | ☁ (must be coordinated with Fargate team) |
| Specific considerations | Permissions must be configured for IAM and DB users to enable the launching of Lambda functions from Aurora | No buffering, so writes to S3 occur synchronously and API executions are frequent | Implementing Express Workflows requires careful consideration of the at-least-once execution model. | The highest financial cost because Lambda runs longer than necessary | The number of Sidecar containers can be the same as the number of tasks, resulting in duplicated processing |
Based on the above comparison, we adopted option 3, which uses Step Functions with both Standard and Express Workflows. The reasons are as follows.
- It is expected that the types of collected data will expand, and those who can control development and operations within their own team (DBRE) can respond swiftly.
- The option to use MySQL Event is simple configuration, yet there are numerous considerations, such as modifying cross-sectional IAM permissions and adding permissions for DB users, and the human cost is high whether automated or covered manually.
- Even though it costs a little more to implement, the additional benefits offered make option 3 the most balanced choice.
In the following sections, I will introduce the aspects devised in the process of implementing the chosen option and the final architecture.
Implementation
Our DBRE team develops in Monorepo and uses Nx as a management tool. Infrastructure management is handled using Terraform, while Lambda implementation is performed in Go. For more information on the DBRE team's development flow using Nx, please see our Tech Blog article "AWS Serverless Architecture with Monorepo Tools - Nx and Terraform! (Japanese)"
Final Architecture Diagram
Taking into account multi-region support and other considerations, the final architecture is shown in the figure below. 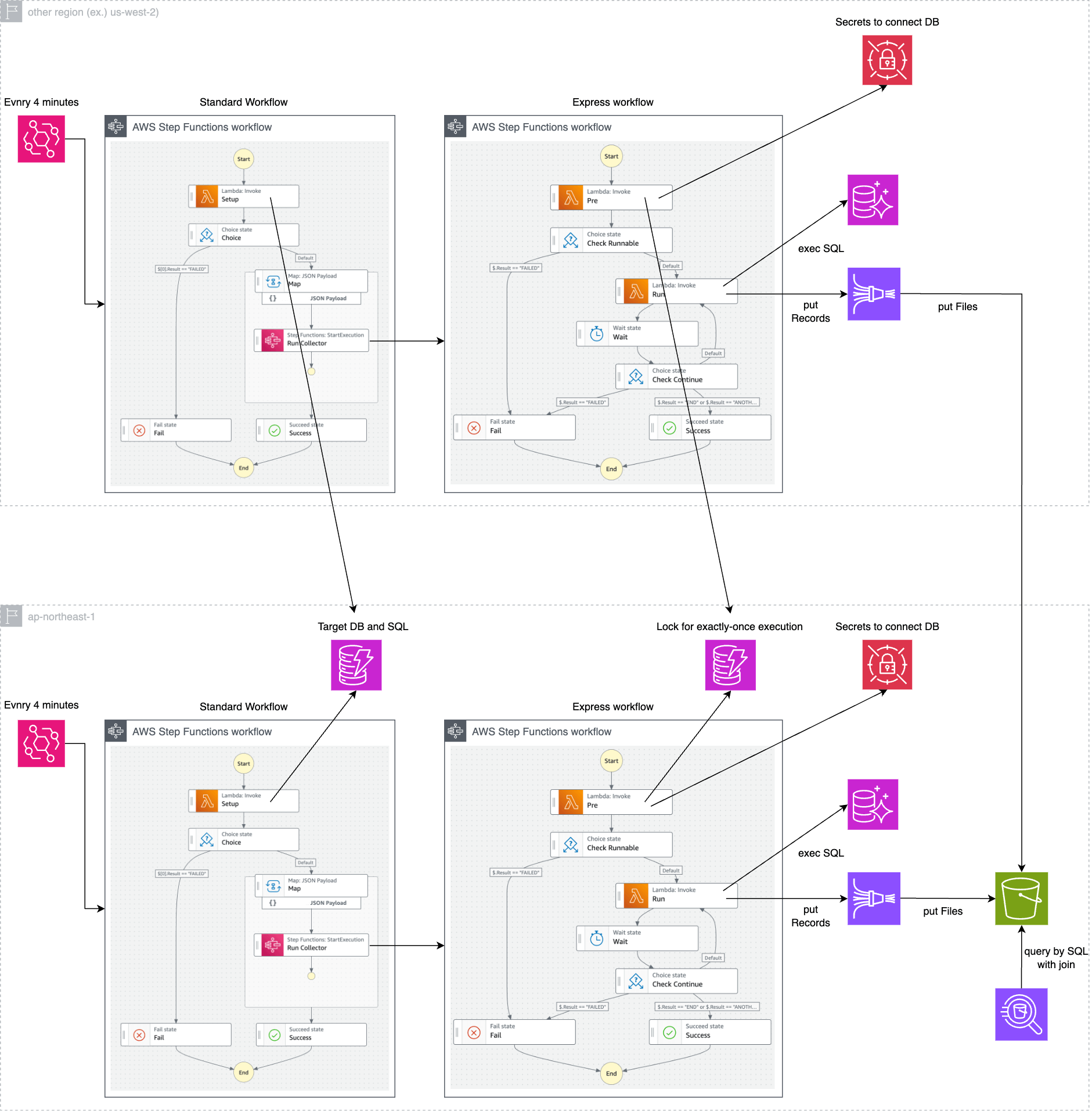
The main considerations are:
- Express Workflows terminate after four minutes because forced termination is treated as an error after five minutes.
- Since the number of accesses to DynamoDB is small and latency is not a bottleneck, it is aggregated in the Tokyo region.
- The data synchronization to S3 after putting to Firehose is asynchronous, so latency is not a bottleneck, and S3 is aggregated to the Tokyo region.
- To reduce the financial cost of frequent access to Secrets Manager, secret retrieval is performed outside the state loop.
- To prevent each Express Workflow from being executed multiple times, a locking mechanism is implemented using DynamoDB.
- Note: Since Express Workflows employ an at-least-once execution model.
In the following sections, I will introduce the aspects devised during implementation.
Create a dedicated DB user for each DB
Only the following two permissions are required to execute the target SQL.
GRANT SELECT ON performance_schema.* TO ${user_name};
-- required to select information_schema.INNODB_TRX
GRANT PROCESS ON *.* TO ${user_name};
We have created a mechanism whereby DB users with only this permission are created for all Aurora MySQL. We have a batch process that connects to all Aurora MySQL on a daily basis and collects various information. This batch process has been modified to create DB users with the required permissions for all DBs. This automatically created a state in which the required DB users existed when a new DB was created.
Reduce DB load and data size stored in S3
Records can be retrieved from some of the six target collection tables even if blocking has not occurred. Therefore, if all the cases are selected every N seconds, the load on Aurora will increase unnecessarily, although only slightly, and data will be stored unnecessarily in S3 as well. To prevent this, the implementation ensures that all relevant tables are selected only when blocking is occurring. To minimize the load, SQL for blocking detection was also organized as follows.
Metadata blocking detection
The metadata blocking occurrence detection query is as follows.
select * from `performance_schema`.`metadata_locks`
where lock_status = 'PENDING' limit 1
Only when records are obtained by this query, execute the SELECT query on all three following tables and transmit the results to Firehose.
- performance_schema.metadata_locks
- performance_schema.threads
- performance_schema.events_statements_current
InnoDB blocking detection
The blocking occurrence detection query of InnoDB is as follows.
select * from `information_schema`.`INNODB_TRX`
where timestampdiff(second, `TRX_WAIT_STARTED`, now()) >= 1 limit 1;
Only when records are obtained by this query, execute the SELECT query on all three following tables and transmit the results to Firehose.
- performance_schema.data_lock_waits
- information_schema.INNODB_TRX
- performance_schema.data_locks
Parallel processing of queries using goroutine
Even if there is a slight deviation in the timing of SELECT execution on each table, if blocking continues, the probability of data inconsistency occurring when joining later is low. However, it is preferable to conduct them at the same time as much as possible. To achieve a state where "data continues to be collected at N-second intervals, it is also necessary to ensure that the Collector's Lambda execution time is as short as possible. Based on above two points, query execution is handled as concurrently as possible using goroutine.
Use of session variables to avoid unexpected overloads
Although we confirm in advance that the query load to be executed is sufficiently low, sometimes there may be situations where "the execution time is longer than expected" or "information gathering queries are caught in blocking." Therefore, we set max_execution_time and TRANSACTION ISOLATION LEVEL READ UNCOMMITTED at the session level to continue to obtain information as safely as possible.
To implement this process in the Go language, we override the function Connect() in the driver.connector interface in the database/SQL/driver package. The implementation image, excluding error handling, is as follows
type sessionCustomConnector struct {
driver.Connector
}
func (c *sessionCustomConnector) Connect(ctx context.Context) (driver.Conn, error) {
conn, err := c.Connector.Connect(ctx)
execer, _ := conn.(driver.ExecerContext)
sessionContexts := []string{
"SET SESSION max_execution_time = 1000",
"SET SESSION TRANSACTION ISOLATION LEVEL READ UNCOMMITTED",
}
for _, sessionContext := range sessionContexts {
execer.ExecContext(ctx, sessionContext, nil)
}
return conn, nil
}
func main() {
cfg, _ := mysql.ParseDSN("dsn_string")
defaultConnector, _ := mysql.NewConnector(cfg)
db := sql.OpenDB(&sessionCustomConnector{defaultConnector})
rows, _ := db.Query("SELECT * FROM performance_schema.threads")
...
}
Locking mechanism for Express Workflows
Since StepFunctions' Express Workflows employ an at-least-once execution model, the entire workflows can be executed multiple times. In this case, duplicate execution is not a major problem, but achieving exactly-once execution is preferable, so we implemented a simple locking mechanism using DynamoDB, with reference to the AWS Blog.
Specifically, Lambda, which runs at the start of Express workflows, PUT data into a DynamoDB table with attribute_not_exists expression. The partition key specifies a unique ID generated by the parent workflow, it can be determined that "PUT succeeds = you are the first executor." If it fails, it determines that another child workflow is already running, skips further processing and exits.
Leveraging Amazon Data Firehose Dynamic Partitioning
Firehose Dynamic Partitioning feature is used to dynamically determine the S3 file path. The rule for dynamic partitioning (S3 bucket prefixes) was configured as follows, taking into account access control in Athena as described below.
!{partitionKeyFromQuery:db_schema_name}/!{partitionKeyFromQuery:table_name}/!{partitionKeyFromQuery:env_name}/!{partitionKeyFromQuery:service_name}/day=!{timestamp:dd}/hour=!{timestamp:HH}/
If you put json data to Firehose Stream with this setting, it will find the attribute that is the partition key from the attribute in json and automatically save it to S3 with the file path according to the rule.
For example, suppose the following json data is put into Firehose.
{
"db_schema_name":"performance_schema",
"table_name":"threads",
"env_name":"dev",
"service_name":"some-service",
"other_attr1":"hoge",
"other_attr2":"fuga",
...
}
As a result, the file path to be saved in S3 is as follows: There is no need to specify any file path when putting to Firehose. It automatically determines the file name and saves it based on predefined rules.
 The file stored by Firehose in S3: Dynamic Partitioning automatically determines file path
The file stored by Firehose in S3: Dynamic Partitioning automatically determines file path
Since schema names, table names, etc. do not exist in the SELECT results of MySQL tables, we implemented to add them as common columns when generating JSON to be put into Firehose.
Design of Athena tables and access rights
Here is an example of creating a table in Athena based on the table definition in MySQL.
The CREATE statement on the MySQL side for performance_schema.metadata_locks is as follows:
CREATE TABLE `metadata_locks` (
`OBJECT_TYPE` varchar(64) NOT NULL,
`OBJECT_SCHEMA` varchar(64) DEFAULT NULL,
`OBJECT_NAME` varchar(64) DEFAULT NULL,
`COLUMN_NAME` varchar(64) DEFAULT NULL,
`OBJECT_INSTANCE_BEGIN` bigint unsigned NOT NULL,
`LOCK_TYPE` varchar(32) NOT NULL,
`LOCK_DURATION` varchar(32) NOT NULL,
`LOCK_STATUS` varchar(32) NOT NULL,
`SOURCE` varchar(64) DEFAULT NULL,
`OWNER_THREAD_ID` bigint unsigned DEFAULT NULL,
`OWNER_EVENT_ID` bigint unsigned DEFAULT NULL,
PRIMARY KEY (`OBJECT_INSTANCE_BEGIN`),
KEY `OBJECT_TYPE` (`OBJECT_TYPE`,`OBJECT_SCHEMA`,`OBJECT_NAME`,`COLUMN_NAME`),
KEY `OWNER_THREAD_ID` (`OWNER_THREAD_ID`,`OWNER_EVENT_ID`)
)
This is defined for Athena as follows:
CREATE EXTERNAL TABLE `metadata_locks` (
`OBJECT_TYPE` string,
`OBJECT_SCHEMA` string,
`OBJECT_NAME` string,
`COLUMN_NAME` string,
`OBJECT_INSTANCE_BEGIN` bigint,
`LOCK_TYPE` string,
`LOCK_DURATION` string,
`LOCK_STATUS` string,
`SOURCE` string,
`OWNER_THREAD_ID` bigint,
`OWNER_EVENT_ID` bigint,
`db_schema_name` string,
`table_name` string,
`aurora_cluster_timezone` string,
`stats_collected_at_utc` timestamp
)
PARTITIONED BY (
env_name string,
service_name string,
day int,
hour int
)
ROW FORMAT SERDE 'org.openx.data.jsonserde.JsonSerDe'
LOCATION 's3://<bucket_name>/performance_schema/metadata_locks/'
TBLPROPERTIES (
"projection.enabled" = "true",
"projection.day.type" = "integer",
"projection.day.range" = "01,31",
"projection.day.digits" = "2",
"projection.hour.type" = "integer",
"projection.hour.range" = "0,23",
"projection.hour.digits" = "2",
"projection.env_name.type" = "injected",
"projection.service_name.type" = "injected",
"storage.location.template" = "s3://<bucket_name>/performance_schema/metadata_locks/${env_name}/${service_name}/day=${day}/hour=${hour}"
);
The point is the design of partition keys. This ensures that only those who have access permission to the original DB can access the data. We assign two tags to all AWS resources: service_name, which is unique to each service, and env_name, which is unique to each environment. We use these tags as a means of access control. By including these two tags as part of the file path to be stored in S3, and by writing the resource using policy variables for the IAM Policy that is commonly assigned to each service, you can only SELECT data for the partition corresponding to the file path in S3 for which you have access permission, even if they are the same tables.
The image below shows the permissions granted to the IAM Policy, which is commonly granted to each service.
{
"Effect": "Allow",
"Action": [
"s3:GetObject"
],
"Resource": [
"arn:aws:s3:::<bukect_name>/*/${aws:PrincipalTag/env_name}/${aws:PrincipalTag/service_name}/*"
]
}
Also, this time I wanted to make the partitions maintenance-free, so I used partition projection. When using partition projection, the range of possible values for partition keys must be known, but by using injected projection type, the range of values does not need to be communicated to Athena, allowing for maintenance-free dynamic partitioning.
Reproduction of Views in Athena
Here is how to create six tables needed for post-blocking investigation in Athena and wrap them with Views, just as in MySQL. The View definition was modified based on the MySQL View definition, such as adding a common column and adding partition key comparisons to the JOIN clause.
The Athena definition of `sys.innodb_lock_waits<[1} is as follows.
CREATE OR REPLACE VIEW innodb_lock_waits AS
select
DATE_ADD('hour', 9, w.stats_collected_at_utc) as stats_collected_at_jst,
w.stats_collected_at_utc as stats_collected_at_utc,
w.aurora_cluster_timezone as aurora_cluster_timezone,
r.trx_wait_started AS wait_started,
date_diff('second', r.trx_wait_started, r.stats_collected_at_utc) AS wait_age_secs,
rl.OBJECT_SCHEMA AS locked_table_schema,
rl.OBJECT_NAME AS locked_table_name,
rl.PARTITION_NAME AS locked_table_partition,
rl.SUBPARTITION_NAME AS locked_table_subpartition,
rl.INDEX_NAME AS locked_index,
rl.LOCK_TYPE AS locked_type,
r.trx_id AS waiting_trx_id,
r.trx_started AS waiting_trx_started,
date_diff('second', r.trx_started, r.stats_collected_at_utc) AS waiting_trx_age_secs,
r.trx_rows_locked AS waiting_trx_rows_locked,
r.trx_rows_modified AS waiting_trx_rows_modified,
r.trx_mysql_thread_id AS waiting_pid,
r.trx_query AS waiting_query,
rl.ENGINE_LOCK_ID AS waiting_lock_id,
rl.LOCK_MODE AS waiting_lock_mode,
b.trx_id AS blocking_trx_id,
b.trx_mysql_thread_id AS blocking_pid,
b.trx_query AS blocking_query,
bl.ENGINE_LOCK_ID AS blocking_lock_id,
bl.LOCK_MODE AS blocking_lock_mode,
b.trx_started AS blocking_trx_started,
date_diff('second', b.trx_started, b.stats_collected_at_utc) AS blocking_trx_age_secs,
b.trx_rows_locked AS blocking_trx_rows_locked,
b.trx_rows_modified AS blocking_trx_rows_modified,
concat('KILL QUERY ', cast(b.trx_mysql_thread_id as varchar)) AS sql_kill_blocking_query,
concat('KILL ', cast(b.trx_mysql_thread_id as varchar)) AS sql_kill_blocking_connection,
w.env_name as env_name,
w.service_name as service_name,
w.day as day,
w.hour as hour
from
(
(
(
(
data_lock_waits w
join INNODB_TRX b on(
(
b.trx_id = cast(
w.BLOCKING_ENGINE_TRANSACTION_ID as bigint
)
)
and w.stats_collected_at_utc = b.stats_collected_at_utc and w.day = b.day and w.hour = b.hour and w.env_name = b.env_name and w.service_name = b.service_name
)
)
join INNODB_TRX r on(
(
r.trx_id = cast(
w.REQUESTING_ENGINE_TRANSACTION_ID as bigint
)
)
and w.stats_collected_at_utc = r.stats_collected_at_utc and w.day = r.day and w.hour = r.hour and w.env_name = r.env_name and w.service_name = r.service_name
)
)
join data_locks bl on(
bl.ENGINE_LOCK_ID = w.BLOCKING_ENGINE_LOCK_ID
and bl.stats_collected_at_utc = w.stats_collected_at_utc and bl.day = w.day and bl.hour = w.hour and bl.env_name = w.env_name and bl.service_name = w.service_name
)
)
join data_locks rl on(
rl.ENGINE_LOCK_ID = w.REQUESTING_ENGINE_LOCK_ID
and rl.stats_collected_at_utc = w.stats_collected_at_utc and rl.day = w.day and rl.hour = w.hour and rl.env_name = w.env_name and rl.service_name = w.service_name
)
)
In addition, the Athena definition of sys.schema_table_lock_waits is as follows.
CREATE OR REPLACE VIEW schema_table_lock_waits AS
select
DATE_ADD('hour', 9, g.stats_collected_at_utc) as stats_collected_at_jst,
g.stats_collected_at_utc AS stats_collected_at_utc,
g.aurora_cluster_timezone as aurora_cluster_timezone,
g.OBJECT_SCHEMA AS object_schema,
g.OBJECT_NAME AS object_name,
pt.THREAD_ID AS waiting_thread_id,
pt.PROCESSLIST_ID AS waiting_pid,
-- sys.ps_thread_account(p.OWNER_THREAD_ID) AS waiting_account, -- Not supported because it is unnecessary, although it is necessary to include it in select when collecting information in MySQL.
p.LOCK_TYPE AS waiting_lock_type,
p.LOCK_DURATION AS waiting_lock_duration,
pt.PROCESSLIST_INFO AS waiting_query,
pt.PROCESSLIST_TIME AS waiting_query_secs,
ps.ROWS_AFFECTED AS waiting_query_rows_affected,
ps.ROWS_EXAMINED AS waiting_query_rows_examined,
gt.THREAD_ID AS blocking_thread_id,
gt.PROCESSLIST_ID AS blocking_pid,
-- sys.ps_thread_account(g.OWNER_THREAD_ID) AS blocking_account, -- Not supported because it is unnecessary, although it is necessary to include it in select when collecting information in MySQL.
g.LOCK_TYPE AS blocking_lock_type,
g.LOCK_DURATION AS blocking_lock_duration,
concat('KILL QUERY ', cast(gt.PROCESSLIST_ID as varchar)) AS sql_kill_blocking_query,
concat('KILL ', cast(gt.PROCESSLIST_ID as varchar)) AS sql_kill_blocking_connection,
g.env_name as env_name,
g.service_name as service_name,
g.day as day,
g.hour as hour
from
(
(
(
(
(
metadata_locks g
join metadata_locks p on(
(
(g.OBJECT_TYPE = p.OBJECT_TYPE)
and (g.OBJECT_SCHEMA = p.OBJECT_SCHEMA)
and (g.OBJECT_NAME = p.OBJECT_NAME)
and (g.LOCK_STATUS = 'GRANTED')
and (p.LOCK_STATUS = 'PENDING')
AND (g.stats_collected_at_utc = p.stats_collected_at_utc and g.day = p.day and g.hour = p.hour and g.env_name = p.env_name and g.service_name = p.service_name)
)
)
)
join threads gt on(g.OWNER_THREAD_ID = gt.THREAD_ID and g.stats_collected_at_utc = gt.stats_collected_at_utc and g.day = gt.day and g.hour = gt.hour and g.env_name = gt.env_name and g.service_name = gt.service_name)
)
join threads pt on(p.OWNER_THREAD_ID = pt.THREAD_ID and p.stats_collected_at_utc = pt.stats_collected_at_utc and p.day = pt.day and p.hour = pt.hour and p.env_name = pt.env_name and p.service_name = pt.service_name)
)
left join events_statements_current gs on(g.OWNER_THREAD_ID = gs.THREAD_ID and g.stats_collected_at_utc = gs.stats_collected_at_utc and g.day = gs.day and g.hour = gs.hour and g.env_name = gs.env_name and g.service_name = gs.service_name)
)
left join events_statements_current ps on(p.OWNER_THREAD_ID = ps.THREAD_ID and p.stats_collected_at_utc = ps.stats_collected_at_utc and p.day = ps.day and p.hour = ps.hour and p.env_name = ps.env_name and p.service_name = ps.service_name)
)
where
(g.OBJECT_TYPE = 'TABLE')
Results
Using the mechanism created, I will actually generate blocking and conduct an investigation in Athena.
select *
from innodb_lock_waits
where
stats_collected_at_jst between timestamp '2024-03-01 15:00:00' and timestamp '2024-03-01 16:00:00'
and env_name = 'dev'
and service_name = 'some-service'
and hour between
cast(date_format(DATE_ADD('hour', -9, timestamp '2024-03-01 15:00:00'), '%H') as integer)
and cast(date_format(DATE_ADD('hour', -9, timestamp '2024-03-01 16:00:00'), '%H') as integer)
and day = 1
order by stats_collected_at_jst asc
limit 100
If you execute the above query in Athena, specifying the time period during which the blocking occurred, the following results will be returned. 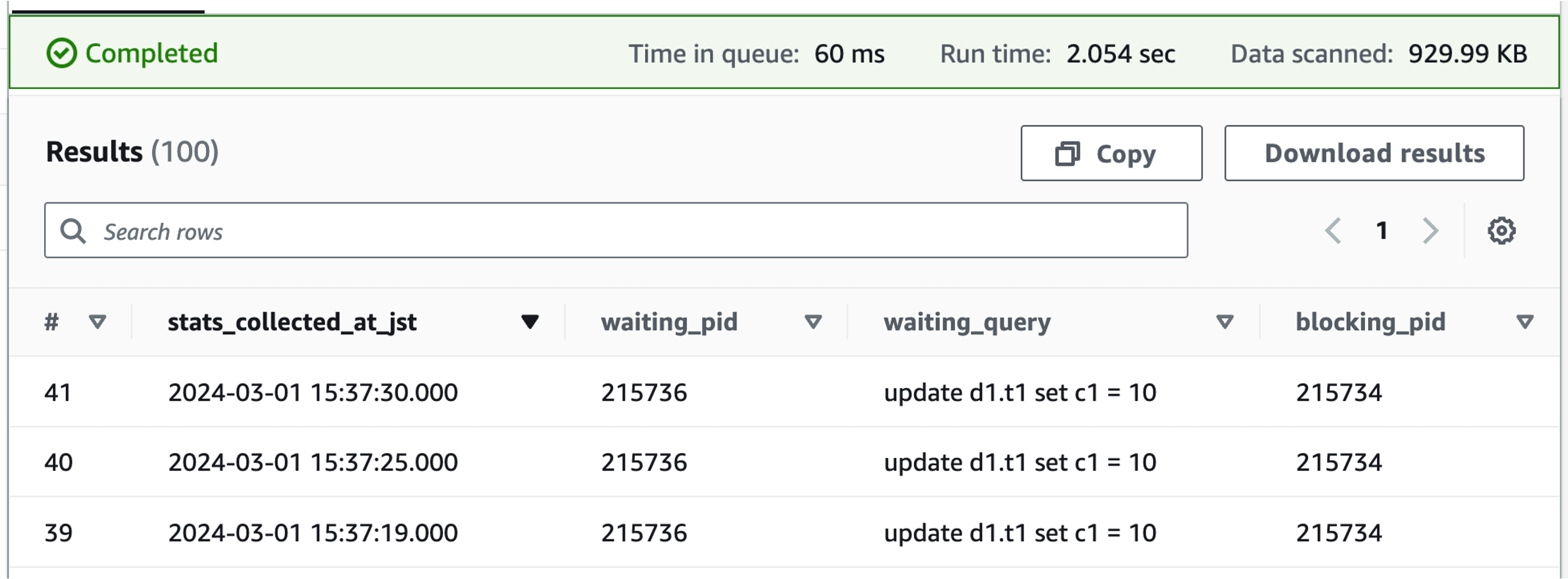
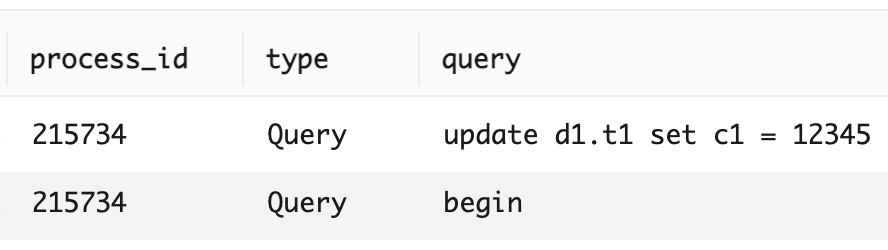
Since we do not know the blocker's SQL, we use CloudWatch Logs Insights based on the process ID (blocking_pid column) to check the history of SQL executed by the blocker.
fields @timestamp, @message
| parse @message /(?<timestamp>[^\s]+)\s+(?<process_id>\d+)\s+(?<type>[^\s]+)\s+(?<query>.+)/
| filter process_id = 215734
| sort @timestamp desc
The following results indicate that the blocker SQL is update d1.t1 set c1 = 12345.
The same procedure can now be used to check metadata-related blocking status in schema_table_lock_waits.
Future Outlook
As for the future outlook, the following is considered:
- As deployment to the product is scheduled for the future, accumulate knowledge on incidents caused by blocking through actual operations.
- Investigate and tune bottlenecks to minimize Lambda billed duration.
- Expand collection targets in performance_schema and information_schema
- Expand the scope of investigations, including analysis of index usage.
- Improve the DB layer's problem-solving capabilities through a cycle of expanding the information collected based on feedback from incident response.
- Visualization with BI services such as Amazon QuickSight
- Create a world where members unfamiliar with performance_schema can investigate the cause.
Summary
This article details a case where investigating the cause of timeout errors due to lock contention in Aurora MySQL led to the development of a mechanism for periodically collecting necessary information to follow up on the cause of the blocking. In order to follow up on blocking information in MySQL, we need to periodically collect wait data on two types of locks, metadata locks and InnoDB locks, using the following six tables.
- Metadata locks
- performance_schema.metadata_locks
- performance_schema.threads
- performance_schema.events_statements_current
- InnoDB locks
- performance_schema.data_lock_waits
- information_schema.INNODB_TRX
- performance_schema.data_locks
Based on our environment, we designed and implemented a multi-region architecture capable of collecting information from multiple DB clusters. Consequently, we were able to create a SQL-based post-investigation with a time lag of up to five minutes after the occurrence of blocking, with results returned in a few seconds. Although these features may eventually be incorporated into SaaS and AWS services, our DBRE team values proactively implementing features on our own if deemed necessary.
KINTO Technologies' DBRE team is looking for people to join us! Casual chats are also welcome, so if you are interested, feel free to DM me on X. Don't forget to follow us on our recruitment Twitter too!
Appendix : References
The following articles provide a clear summary of how to investigate blocking in the MySQL 8.0 series, and use them as a reference.
- Checking the row lock status of InnoDB [Part 1]
- Checking the row lock status of InnoDB [Part 2]
- Isono, Let's Show MySQL Lock Contention
Once the blocker is identified, further investigation is required to determine the specific locks causing the blocking. The following article provides a clear and understandable summary of MySQL locks.
I also referred to the MySQL Reference Manual.
関連記事 | Related Posts
Developing a System to Investigate Lock Contention (Blocking) Causes in Aurora MySQL

本番環境で発生したAurora MySQL 3 系のデッドロックの原因を調査した話
Aurora MySQL でレコードが存在するのに SELECT すると Empty set が返ってくる事象を調査した話
Investigating Why Aurora MySQL Returns “Empty set” in Response to SELECT, Even Though Corresponding Records Exist
データベースのパスワードを安全にローテーションする仕組みの導入
見えないエラーの原因とは? Amazon Aurora MySQL 2で発生したDatabase Collationによるmysqldumpコマンドがエラーメッセージなしで処理が終了する現象について
We are hiring!
【SRE】DBRE G/東京・大阪・名古屋・福岡
DBREグループについてKINTO テクノロジーズにおける DBRE は横断組織です。自分たちのアウトプットがビジネスに反映されることによって価値提供されます。
シニア/フルスタックエンジニア(JavaScript・Python・SQL)/契約管理システム開発G/東京
契約管理システム開発グループについて◉KINTO開発部 :66名・契約管理開発G :9名★←こちらの配属になります・KINTO中古車開発G:9名・KINTOプロダクトマネジメントG:3名・KINTOバックエンド開発G:16名・KINTO開発推進G:8名・KINTOフロントエンド...


