Aurora MySQL におけるロック競合(ブロッキング)の原因を事後調査できる仕組みを作った話

こんにちは。 DBRE チーム所属の @p2sk です。
DBRE(Database Reliability Engineering)チームでは、横断組織としてデータベースに関する課題解決や、組織のアジリティとガバナンスのバランスを取るためのプラットフォーム開発などを行なっております。DBRE は比較的新しい概念で、DBRE という組織がある会社も少なく、あったとしても取り組んでいる内容や考え方が異なるような、発展途上の非常に面白い領域です。
弊社における DBRE チーム発足の背景やチームの役割については「KTC における DBRE の必要性」というテックブログをご覧ください。
本記事では、Aurora MySQL でロック競合(ブロッキング)起因のタイムアウトエラーが発生した際に根本原因を特定することができなかったので、原因を後追いするために必要な情報を定期的に収集する仕組みを構築した事例をご紹介します。尚、考え方自体は RDS for MySQL や、AWS 以外のクラウドサービスの MySQL の PaaS および、MySQL 単体にも適用できるものかと思いますので参考になりましたら幸いです。
背景 : ブロッキング起因のタイムアウトが発生
プロダクトの開発者から「アプリケーションのクエリタイムアウトが発生したため調査して欲しい」という問い合わせを受けました。エラーコードは SQL Error: 1205 とのことで、ロック獲得の待ち時間超過によるタイムアウトだと思われます。
弊社では、 Aurora MySQL のモニタリングに Performance Insights を使用しており、該当の時間帯のデータベース負荷を確認すると、確かに行ロック獲得待ちの時に発生する待ち事象「synch/cond/innodb/row_lock_wait_cond」が増加していました。
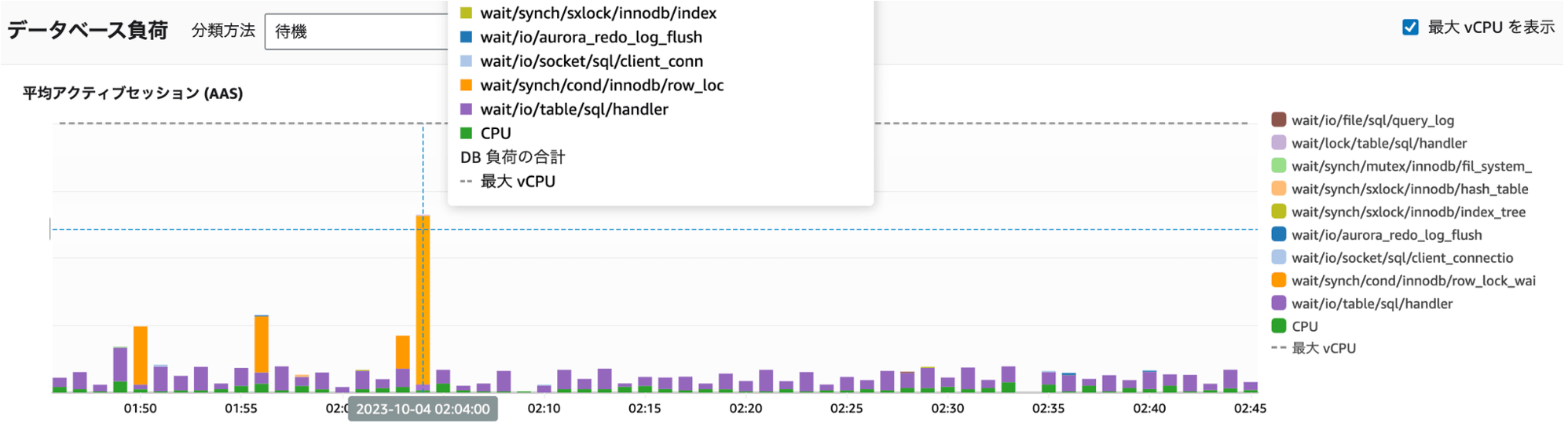
Performance Insights ダッシュボード : ロック待ち(オレンジ色)が増加している
Performance Insights には「トップ SQL」というタブがあり、任意の時間帯における「DB 負荷の寄与率が高い順」で実行されていた SQL を表示してくれます。こちらも確認すると下図のように UPDATE SQL が表示されましたが、タイムアウトした SQL、つまりブロックされている側の SQL だけが表示されている状況でした。
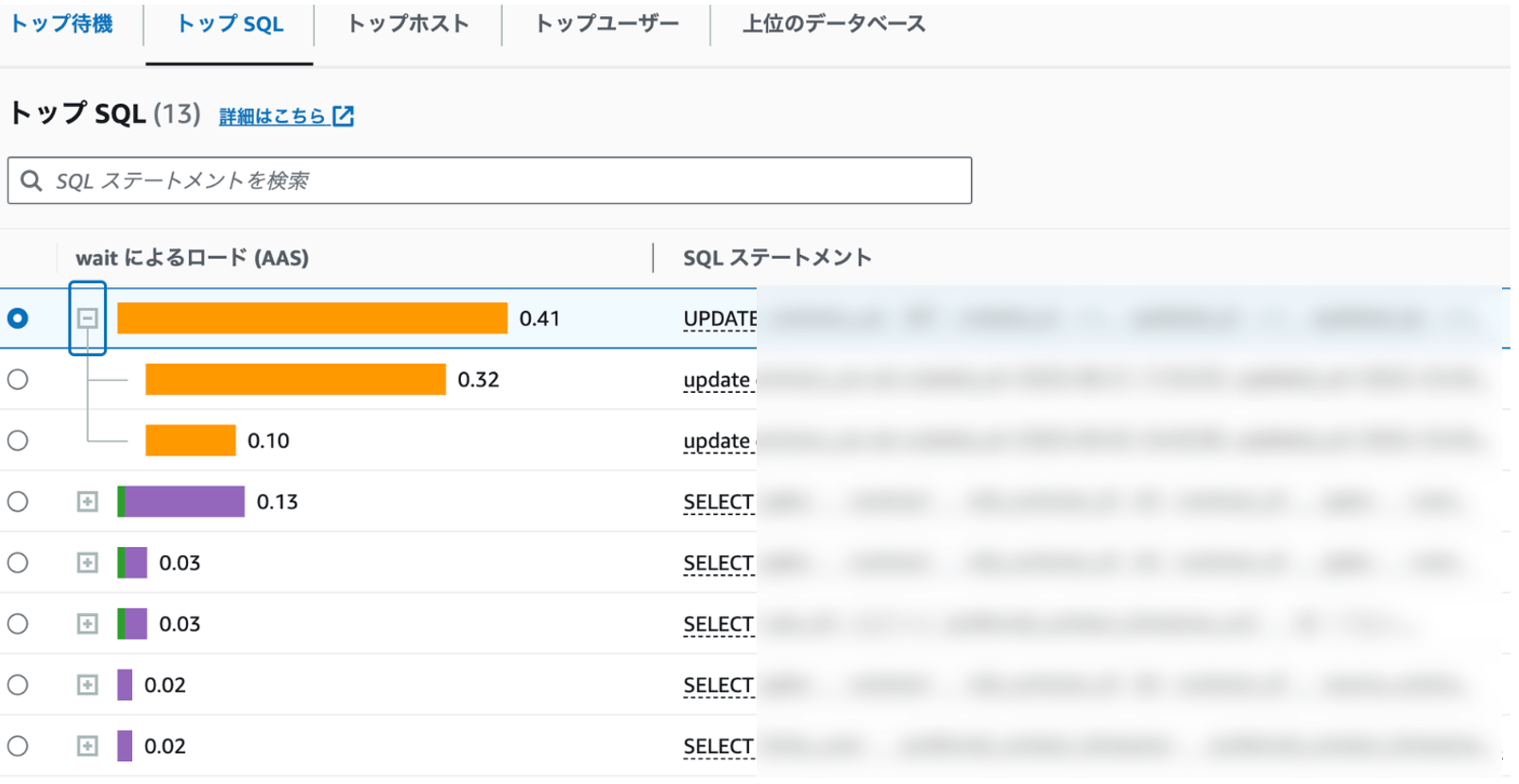
トップ SQL タブ : 表示された UPDATE ステートメントはブロックされている側のもの
「トップ SQL」は、例えば CPU 負荷が高いような状況下では、その寄与率が高い SQL を特定するのに大変便利な機能です。一方で、今回のようなブロッキングの根本原因を特定したい場合には有用ではないケースもあります。なぜなら、ブロッキングを起こしている根本原因の SQL(ブロッカー)自体は、それ単体ではデータベース負荷をかけていない場合もあるためです。
例えば、あるセッションで以下の SQL が実行されたとします。
-- クエリ A
start transaction;
update sample_table set c1 = 1 where pk_column = 1;
このクエリは Primary Key を指定した単一行の更新クエリのため、非常に高速に終了します。しかし、トランザクションを開いたままになっており、この後に別のセッションで以下の SQL を実行すると、ロック獲得待ちとなりブロッキングが発生します。
-- クエリ B
update sample_table set c2 = 2
クエリ B はブロッキングされ続けるため、待ち時間が長くなり「トップ SQL」に表示されます。一方でクエリ A は瞬時に実行が完了しており「トップ SQL」に表示されず、MySQL のスロークエリログにも記録されません。
この例は極端ですが、Performance Insights を用いたブロッカーの特定が難しいケースをご紹介しました。
一方で、Performance Insights でもブロッカーを特定できるケースはあります。例えば同一の UPDATE SQL が大量に実行されることで「Blocking Query = Blocked Query」となる状況です。この場合は Performance Insights で十分です。しかしブロッキングの発生原因は多様であり、現状の Performance Insights だと限界があります。
今回発生したインシデントも、Performance Insights ではブロッカーを特定できず、各種ログから原因の特定を試みました。Audit Log / Error Log / General Log / Slow Query Log の各種ログを確認しましたが、原因を特定できませんでした。
今回の調査を通して、現状だとブロッキングの原因特定を後から実施するための情報が不足していることが分かりました。しかし、今後同じような事象が発生しても「情報が不足しているため原因は分かりません」と回答するしかない状況は改善すべきです。したがってブロッキングの根本原因を特定するために「ソリューションの調査」を行うことにしました。
ソリューションの調査
この問題を解決するためにどうしたらいいか、下記について調査を行いました。
- Amazon DevOps Guru for RDS
- 監視系 SaaS
- DB 系の OSS、DB モニタリングツール
以降、それぞれについて説明します。
Amazon DevOps Guru for RDS
Amazon DevOps Guru は、監視対象の AWS リソースのメトリクス・ログを機械学習を使って解析し、パフォーマンスや運用上の問題を自動で検出し、問題の解決策に関する推奨事項を提案してくれるサービスです。DevOps Guru for RDS は、DevOps Guru における DB の問題検出に特化した機能です。Performance Insights との違いとしては、DevOps Guru for RDS は自動で問題分析と解決案の提示まで行ってくれる点が挙げられます。「インシデント発生時の課題解決までマネージドに」という世界を実現したい AWS の思想が伝わってきます。
実際にブロッキングを発生させると、以下のような推奨事項が表示されました。
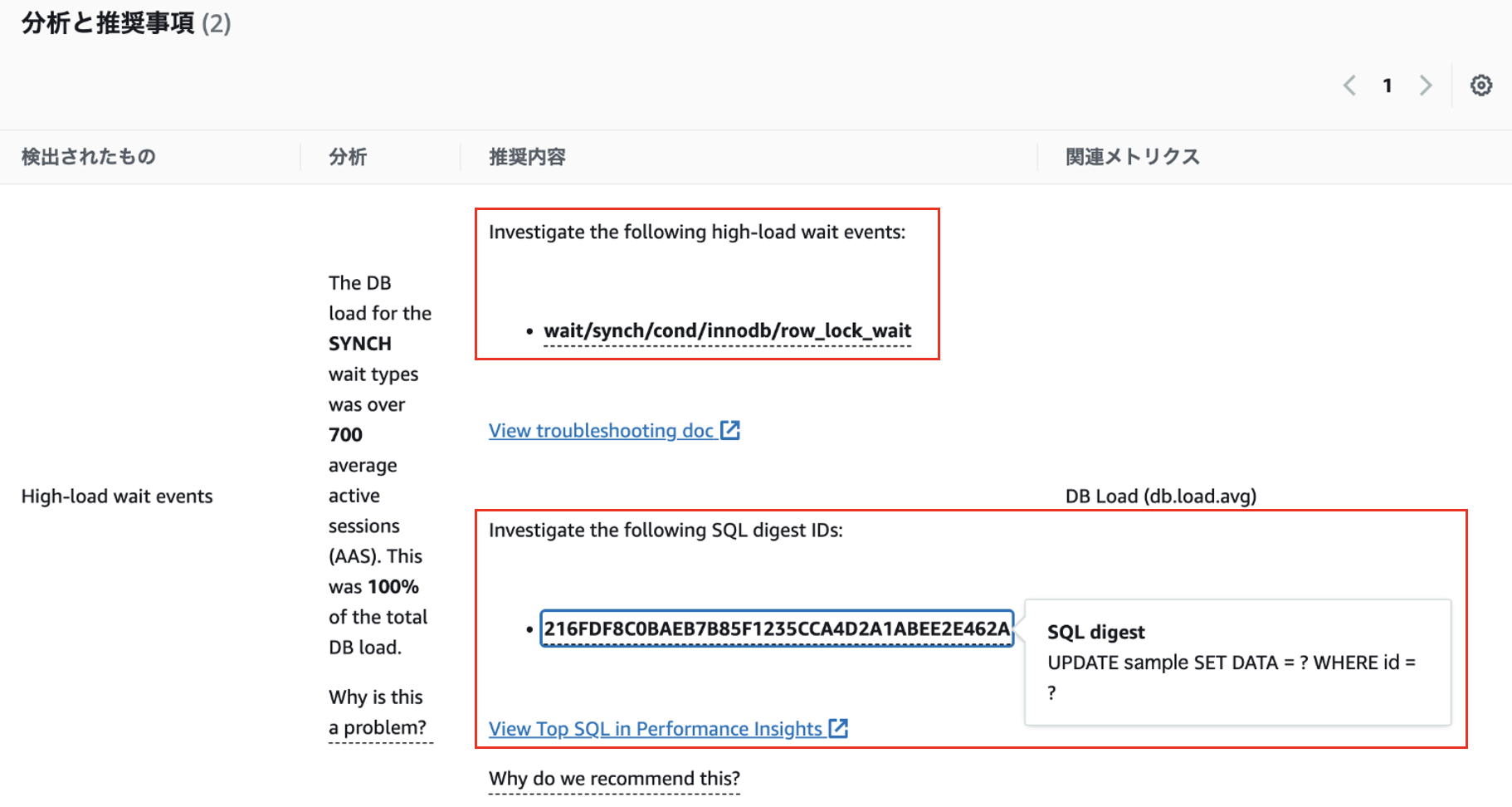
DevOps Guru for RDS の推奨事項 : 調査すべき待ち事象と SQL を提案
表示されている SQL はブロックされている側の SQL であり、ブロッカーの特定は難しそうでした。現状は「synch/cond/innodb/row_lock_wait」という待ち事象が DB 負荷に寄与している場合の調査方法を記したドキュメントへのリンクを提示するにとどめているようです。したがって現状は提案された原因や推奨事項を、人間が最終的に判断する必要がありますが、将来的にはよりマネージドなインシデント対応の体験が提供されるようになるのではと感じています。
監視系 SaaS
データベースのブロッキング原因を SQL レベルで調査できるソリューションとしては、Datadog のデータベースモニタリング機能があります。しかし、現時点では PostgreSQL と SQL Server にのみ対応しており、 MySQL には対応していません。また、New Relic や Mackerel においても同様にブロッキングの事後調査を実施できる機能は提供されていないようでした。
DB 系の OSS、DB モニタリングツール
他にも、以下の DB 系の OSS、DB モニタリングツールについて調査しましたが、ソリューションは提供されていないようでした。
一方、今回の調査で唯一 MySQL のブロッキング調査のソリューションを提供している可能性があるのが SQL Diagnostic Manager for MySQL でした。こちらは MySQL 用の DB モニタリングツールですが、今回の要件に対して機能がリッチすぎるのと、それに伴い価格面がネックとなり検証および導入を見送りました。
本調査を踏まえて、ほぼ既存のソリューションが存在しないことがわかり、自前で仕組みを作ることにしました。そのため、まずは「ブロッキング原因の手動での調査手順」について整理しました。尚、Aurora MySQL のバージョン 2(MySQL 5.7 系) が今年の 10 月 31 日に EOL を迎える予定であるため、対象は Aurora 3 系(MySQL 8.0 系)とします。また、対象のストレージエンジンは InnoDB とします。
ブロッキング原因の手動での調査手順
MySQL でブロッキングの情報を確認するためには、 下記 2 種類のテーブルを参照する必要があります。注意点として、MySQL のパラメータ performance_schema に 1 をセットして performance_schema を有効化しておく必要があります。
- performance_schema.metadata_locks
- 獲得済みのメタデータロックに関する情報が格納される
- lock_status = 'PENDING' なレコードでブロックされているクエリを確認
- performance_schema.data_lock_waits
- ストレージエンジンレベルでのブロッキング情報が格納される(行など)
例えば、メタデータ起因のブロッキングが発生している状況で performance_schema.data_lock_waits を SELECT してもレコードは取れません。そのため 2 種類のテーブルに格納されている情報を併用して調査を実施します。調査には、これらのテーブルと他のテーブルを組み合わせて分析しやすくした View が存在するため、そちらを使った方が便利です。以下に紹介します。
調査手順 1 : sys.schema_table_lock_waits を活用
sys.schema_table_lock_waits は、以下の 3 つのテーブルを使った SQL を ラップした View です。
- performance_schema.metadata_locks
- performance_schema.threads
- performance_schema.events_statements_current
リソースへのメタデータロック獲得で Wait が発生している時にこの View を SELECT すると、レコードが返ってきます。
例えば、以下のような状況です。
-- セッション 1 : lock tables でテーブルのメタデータロックを獲得し、保持し続ける
lock tables sample_table write;
-- セッション 2 : 互換性のない共有メタデータロックを獲得しようとして待たされる
select * from sample_table;
この状況で sys.schema_table_lock_waits を SELECT すると以下のようなレコードセットが取得できます。
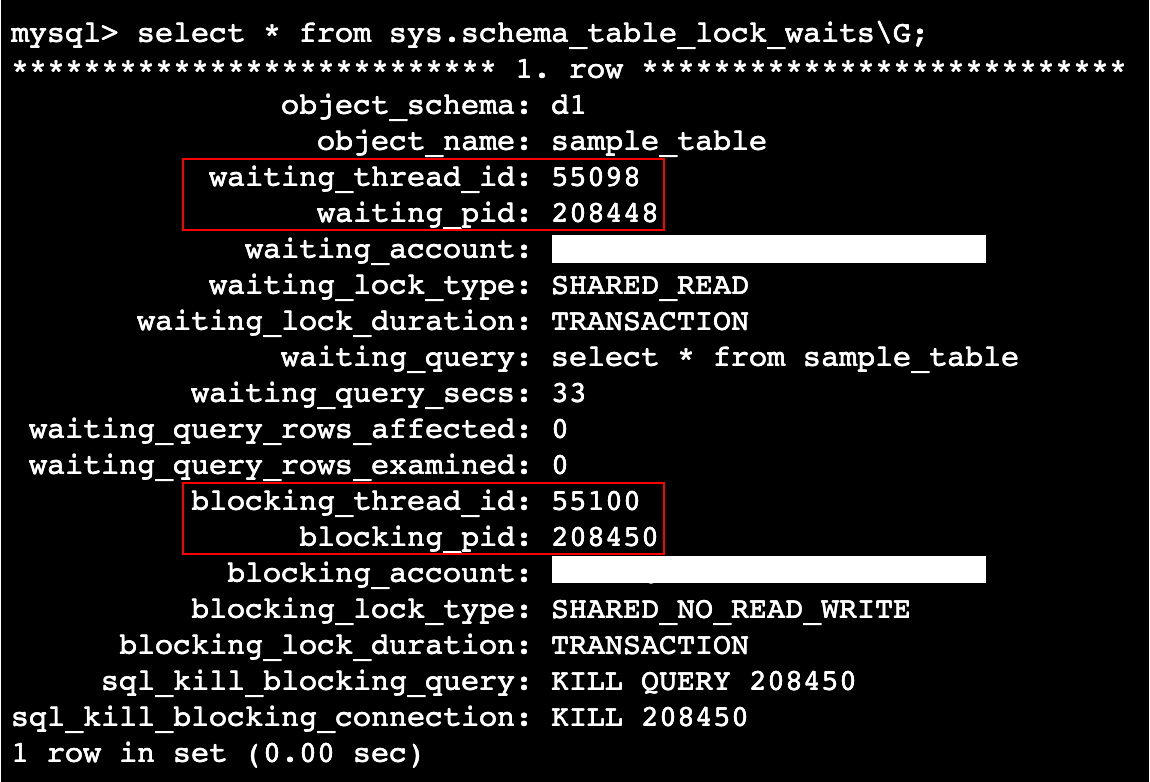
この View の結果からは、直接ブロッカーとなっている SQL を特定することはできません。waiting_query カラムでブロックされているクエリは特定できますが、blocking_query カラムは無いため、blocking_thread_id または blocking_pid を用いて SQL を特定します。
ブロッカーの特定方法 : SQL ベース
SQL ベースでブロッカーを特定する場合、ブロッカーのスレッド ID を用います。
performance_schema.events_statements_current を用いた以下のクエリを実行することで、該当スレッドが最後に実行していた SQL テキストを取得できます。
SELECT THREAD_ID, SQL_TEXT
FROM performance_schema.events_statements_current
WHERE THREAD_ID = 55100\G
実行結果は、例えば以下のようになります。sample_table への lock tables を実行していたことがわかり、ブロッカーを特定できました。

この方法には欠点があります。ブロッカーがロック獲得後に追加で別のクエリを実行した場合、その SQL が取得されてしまうためブロッカーが特定できません。例えば、以下のような状況です。
-- セッション 1 : lock tables でテーブルのメタデータロックを獲得し、保持し続ける
lock tables sample_table write;
-- セッション 1 : lock tables 実行後、別のクエリを実行
select 1;
この状態で、同様のクエリを実行すると以下の結果となります。

別の方法として performance_schema.events_statements_history を用いると、該当スレッドが過去に実行した直近 N 件の SQL テキストを取得できます。
SELECT THREAD_ID, SQL_TEXT
FROM performance_schema.events_statements_history
WHERE THREAD_ID = 55100
ORDER BY EVENT_ID\G;
結果は以下のようになります。
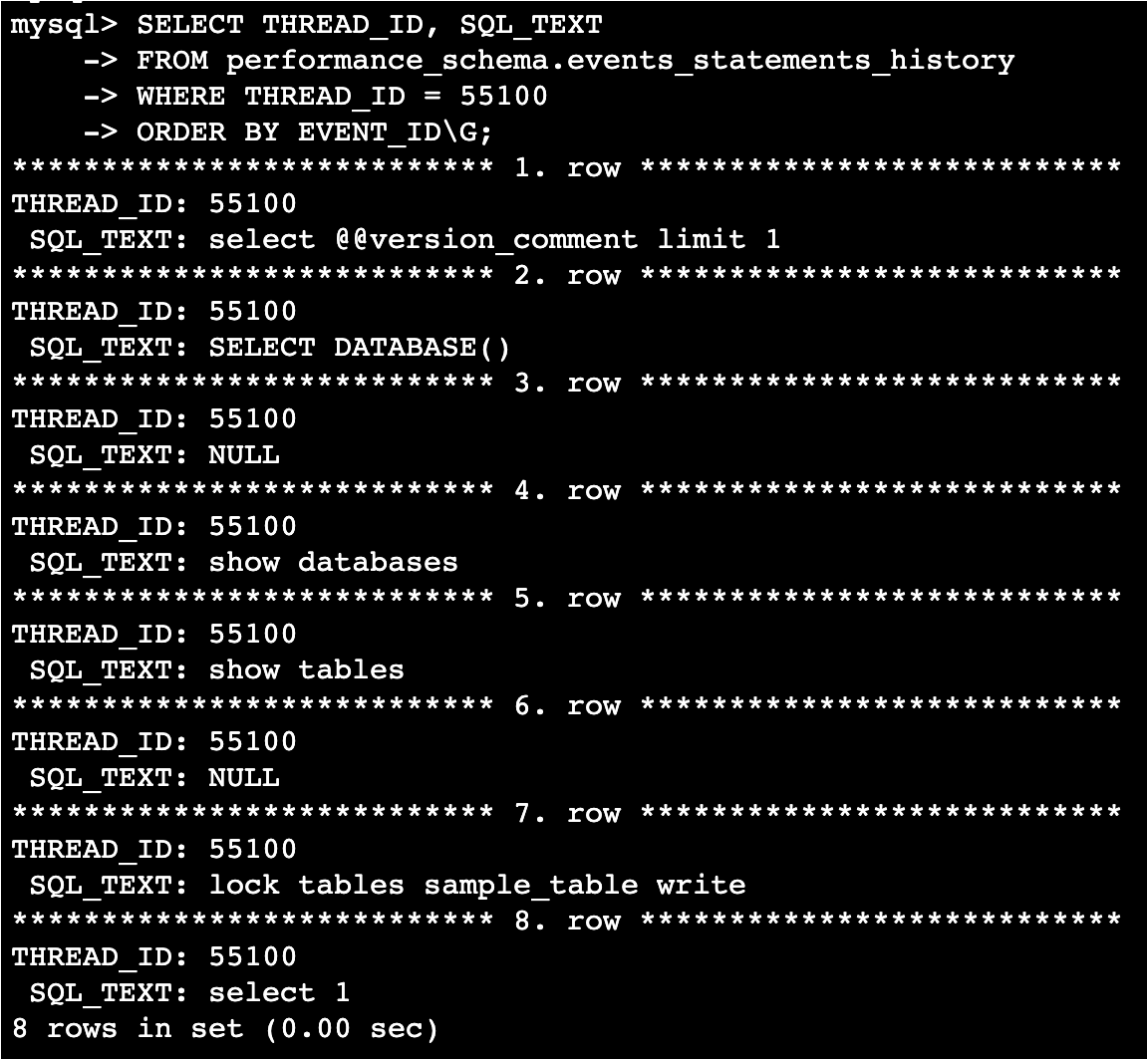
履歴が取得できるためブロッカーも特定できました。スレッドあたり何件 SQL 履歴を保持するかは performance_schema_events_statements_history_size パラメータで変更できます(検証時は 10 を設定)。サイズを大きくするほどブロッカーの特定確率は上がりますが、使用するメモリサイズも増えることと、どれだけサイズを大きくしても限界はあるため、バランスが重要となります。なお、履歴の取得が有効化されているかどうかは performance_schema.setup_consumers を SELECT することで確認できます。Aurora MySQL の場合 performance_schema.events_statements_history の取得はデフォルトで有効化されているようです。
ブロッカーの特定方法 : ログベース
ログベースでブロッカーを特定する場合、General Log や Audit Log を用います。例えば Aurora MySQL で General Log の取得を有効化している場合、CloudWatch Logs Insights で以下のクエリを実行することで、該当プロセスが実行した SQL の履歴を全て取得できます。
fields @timestamp, @message
| parse @message /(?<timestamp>[^\s]+)\s+(?<process_id>\d+)\s+(?<type>[^\s]+)\s+(?<query>.+)/
| filter process_id = 208450
| sort @timestamp asc
このクエリを実行すると、以下のような結果を得ることができます。
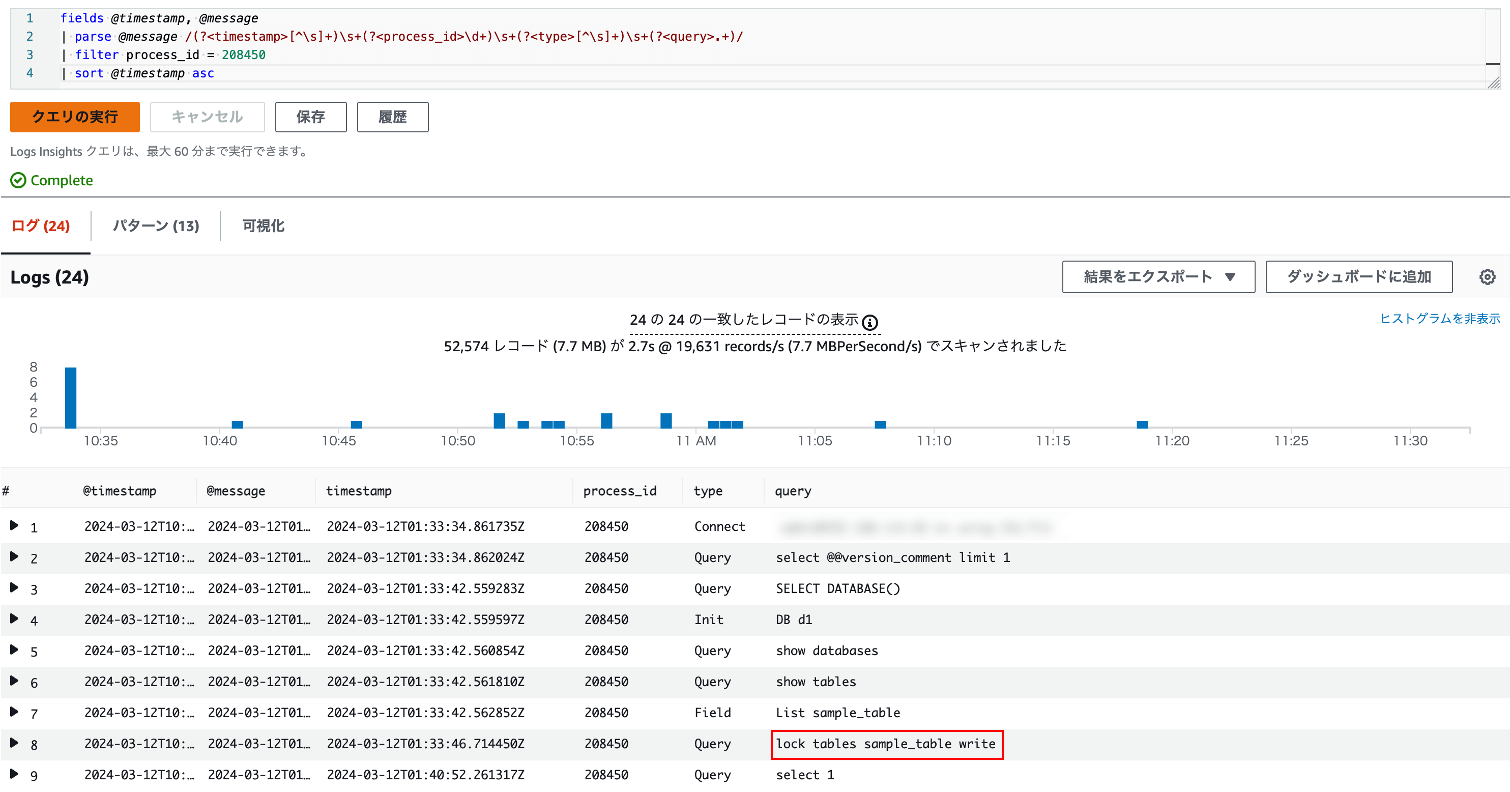
CloudWatch Logs Insights のクエリ実行結果 : 赤枠で囲まれた SQL がブロッカー
弊社では基本的に General Log の取得を有効化しています。SQL ベースだとブロッカーが履歴テーブルから削除されて特定できない懸念があります。したがって今回はログベースでの特定方法を採用することにしました。
ブロッカー特定における留意事項
ブロッカーの特定には、最終的には人間の目視確認と判断が必要です。理由としては、ロックの獲得情報はあくまでスレッドと直接紐づいており、スレッドが実行している SQL は時事刻々と変化していくからです。したがって例示したような「ブロッカーがクエリを実行し終わっているがロックは獲得している」状況の場合、ブロッカーのプロセスが実行した SQL の履歴から、根本原因となる SQL を推測する必要があります。
とはいえ、ブロッカーとなるスレッド ID やプロセス ID が分かるだけでも、根本原因の特定率の大幅な向上が期待できます。
調査手順 2 : sys.innodb_lock_waits を活用
以下の 3 つのテーブルを使った SQL を ラップした View です。
- performance_schema.data_lock_waits
- information_schema.INNODB_TRX
- performance_schema.data_locks
ストレージエンジン(InnoDB)で実装されているロックの獲得で wait が発生している時にこの View を Select すると、レコードが返ってきます。
例えば、以下のような状況です。
-- セッション 1 : レコードを UPDATE したトランザクションを開きっぱなしにしておく
start transaction;
update sample_table set c2 = 10 where c1 = 1;
-- セッション 2 : 同一レコードを更新しようとする
delete from sample_table where c1 = 1;
この状況で sys.innodb_lock_waits を SELECT すると以下のようなレコードセットが取得できます。
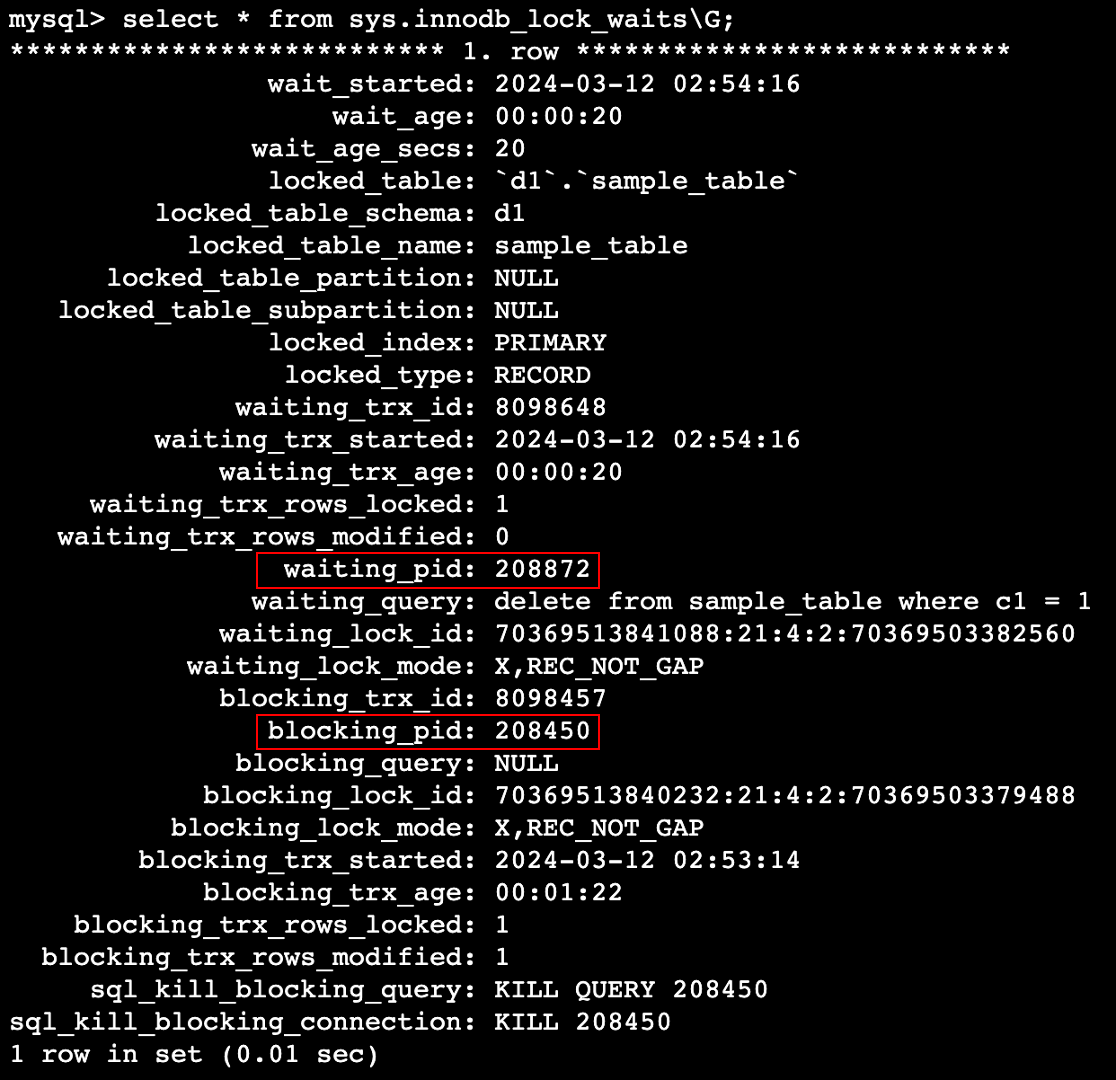
この結果からは sys.schema_table_lock_waits の時と同様に、直接ブロッカーを特定することはできません。したがって blocking_pid を用いて前述のログベースの方法でブロッカーを特定します。
fields @timestamp, @message
| parse @message /(?<timestamp>[^\s]+)\s+(?<process_id>\d+)\s+(?<type>[^\s]+)\s+(?<query>.+)/
| filter process_id = 208450
| sort @timestamp asc
このクエリを実行すると、以下のような結果を得ることができます。
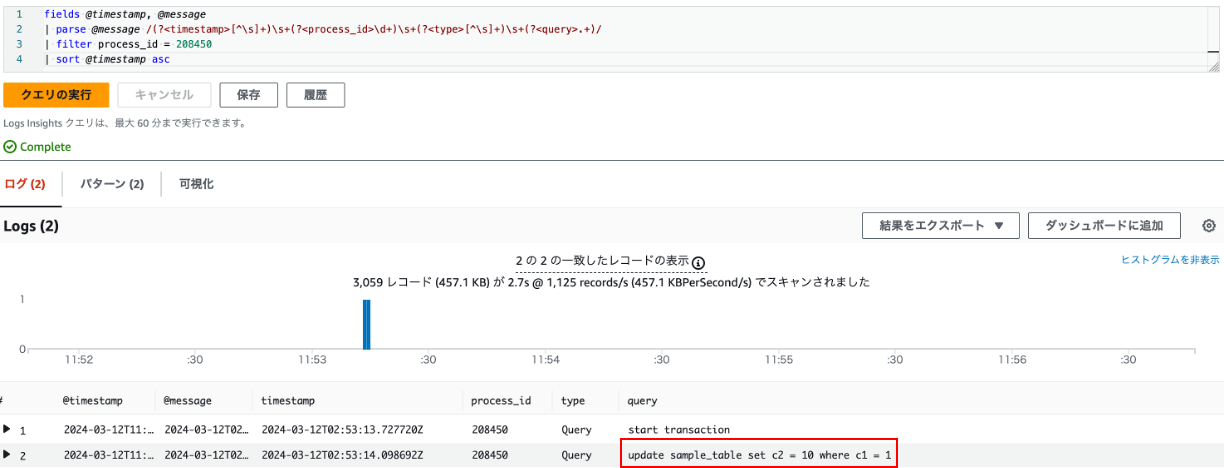
CloudWatch Logs Insights のクエリ実行結果 : 赤枠で囲まれた SQL がブロッカー
ここまでのまとめ
Aurora MySQL のブロッキングの根本原因を事後調査できる状態にするための第一歩として、ブロッキングが発生している時の根本原因の調査方法を整理しました。調査手順は以下の通りです。
sys.schema_table_lock_waitsとsys.innodb_lock_waitsという 2 種類の View を用いてブロッカーのプロセス ID を特定- CloudWatch Logs Insights を使って General Log から、該当のプロセス ID の SQL 実行履歴を取得
- 目視で確認しながら、根本原因となっている SQL を特定(推定)
手順 1 は「ブロッキングが発生している状況」でないと結果が取得できません。したがって、N 秒間隔で定期的に 2 種類の View 相当の情報を収集して保存しておけば、事後調査ができることになります。なお、N 秒 < アプリケーションタイムアウト時間 という関係性が成り立つような N を選定する必要があります。
ブロッキングについての補足
ブロッキングについて 2 点補足します。まずデッドロックとの違いについて、次にブロッキングツリーについて説明します。
デッドロックとの違い
ブロッキングはデッドロックと混同されることが稀にありますので、その違いについて整理しておきます。デッドロックもブロッキングの一種ですが、デッドロックの場合は「いずれかのプロセスを強制的にロールバックさせない限り、事象が解消しないことが確定」しています。したがって InnoDB がデッドロックを検出すると比較的すぐに自動解消が行われます。一方で、通常のブロッキングの場合はブロッカーのクエリが終了すれば解消するため InnoDB による介入はありません。両者に比較を表にまとめると以下のようになります。
| ブロッキング | デッドロック | |
|---|---|---|
| InnoDB による自動解消 | × | ⚪︎ |
| クエリの終了 | KILL やタイムアウトエラーで途中で終了しない限り、ブロックしている側もされている側も最終的には実行完了する | 片方のトランザクションは InnoDB によって強制的に終了させられる |
| 一般的な解消方法 | ブロッカーのクエリが実行完了することによる自然解消もしくは、アプリケーション側で設定したクエリタイムアウト時間経過後にタイムアウトエラー発生とともに解消 | InnoDB がデッドロックを検知後、片方のトランザクションを強制的にロールバックさせることで解消 |
ブロッキングツリー
MySQL の正式な用語ではありませんが、ブロッキングツリーについて説明します。これは「ブロッカーとなっているクエリも、別のブロッカーによってブロックされている」ような状況を指します。
例えば以下のような状況です。
-- セッション 1
begin;
update sample_table set c1 = 2 where pk_column = 1;
-- セッション 2
begin;
update other_table set c1 = 3 where pk_column = 1;
update sample_table set c1 = 4 where pk_column = 1;
-- セッション 3
update other_table set c1 = 5 where pk_column = 1;
この状況では、sys.innodb_lock_waits を SELECT した時に、「セッション 1 が セッション 2 をブロックしている」という情報と「セッション 2 が セッション 3 をブロックしている」という情報の 2 レコードが取得できます。この場合、セッション 3 からみたブロッカーは セッション 2 ですが、問題の根本原因(Root Blocker)としてはセッション 1 です。このように、ブロッキングの発生は時にツリー状になることがあり、このようなケースではログベースでの調査がさらに困難になります。事前にブロッキングに関する情報を収集することの重要性は、このようなブロッキング関連の原因調査の難しさにあります。
以降では、ブロッキングの情報収集の仕組みの設計と実装についてご紹介します。
アーキテクチャ設計
弊社では、マルチリージョンかつ、リージョン内で複数の Aurora MySQL クラスタが稼働しています。したがって、リージョンおよびクラスタ横断でデプロイや運用の負荷を最小限に抑える構成にする必要がありました。
他にも、以下のような要件を整理しました。
機能要件
- 任意の SQL を Aurora MySQL に対して定期的に実行できる
- 任意のリージョンにある Aurora MySQL の情報を収集できる
- 実行対象の DB を管理できる
- クエリの実行結果を外部のストレージへ保管できる
- SQL ベースで格納したデータをクエリできる
- 収集元の DB への権限を持った人だけが収集したデータへアクセスできるように権限管理できる
非機能要件
- 収集対象の DB への負荷増(オーバーヘッド)は最小限に抑えられる
- 分析時のデータ鮮度は 5 分程度のタイムラグまでに抑える
- システムが稼働できない状況に陥った際は通知により気づける状態にある
- SQL ベースでの分析時のレスポンスが数秒で返ってくる
- 情報の収集先(なんらかのストレージ)は 1 箇所に集約できる
- 運用に必要な金銭的コストを最小限におさえる
また、収集対象のテーブルについて以下の通り整理しました。
収集対象のテーブル
sys.schema_table_lock_waits と sys.innodb_lock_waits の SELECT 結果を定期的に収集すればそれで OK なのですが、これらの View は複雑なため、元になっているテーブルを直接 SELECT するよりも負荷が高いです。したがって、非機能要件の「収集対象の DB への負荷増(オーバーヘッド)は最小限に抑えられる」を考慮し、View の元となっている以下の 6 テーブルを SELECT し、クエリエンジン側で View を構築し、クエリ負荷をクエリエンジン側にオフロードする構成にしました。
- sys.schema_table_lock_waits の元テーブル
- performance_schema.metadata_locks
- performance_schema.threads
- performance_schema.events_statements_current
- sys.innodb_lock_waits の元テーブル
- performance_schema.data_lock_waits
- information_schema.INNODB_TRX
- performance_schema.data_locks
最も簡単な方法としては、MySQL のタスクスケジューリング機能である MySQL Event で、これらのテーブルに対する SELECT クエリを N 秒間隔で実行し、結果を専用のテーブルに保存する、というものが考えられます。しかしこの方法では 対象 DB に高頻度で書き込み負荷が発生したり、結果を確認するために該当の DB に個別にログインする必要があるなど、要件に対して適当ではない性質があります。したがって別の方法を検討しました。
アーキテクチャ案
最初に抽象的なアーキテクチャ図を以下の通り作成しました。
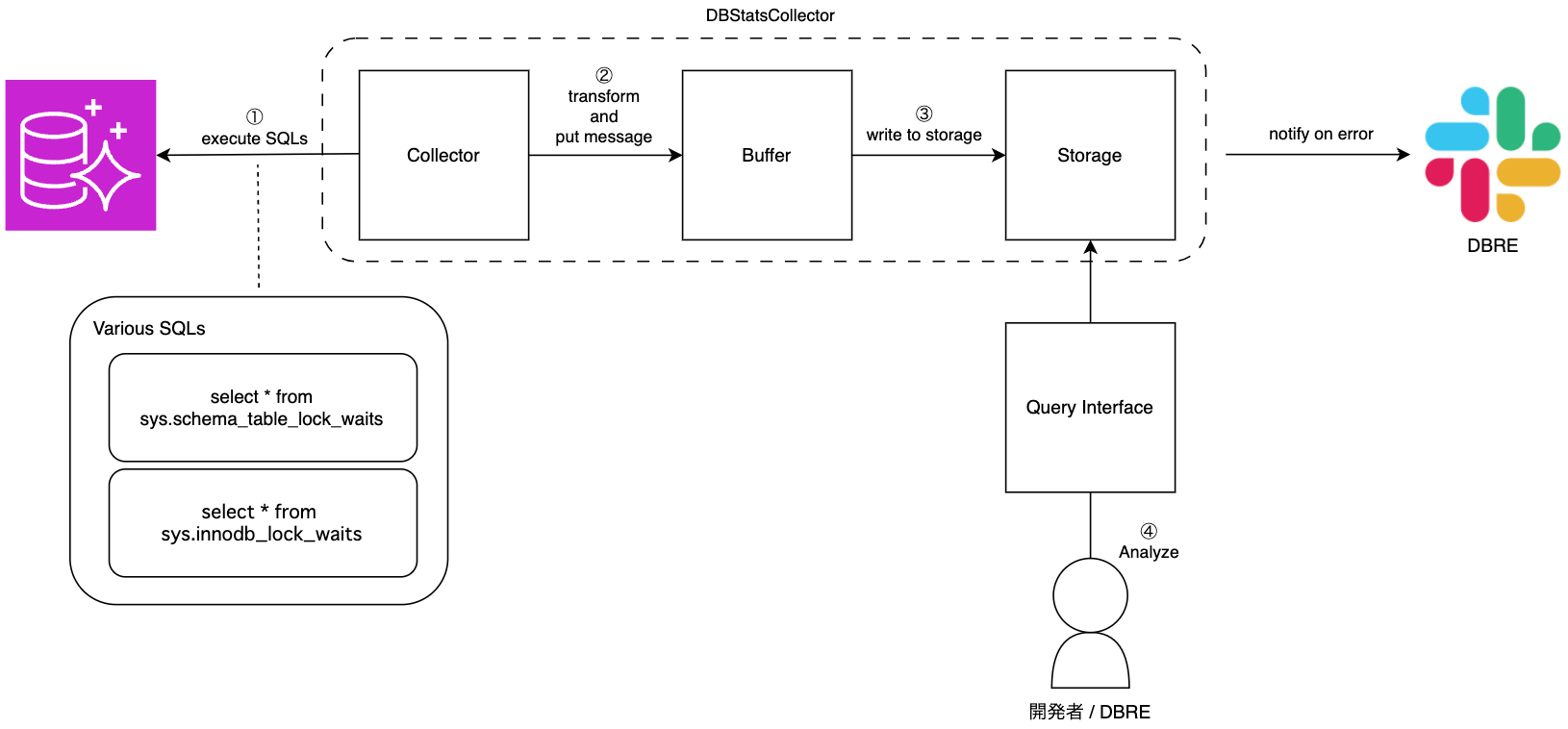
このアーキテクチャ図に対して、要件を踏まえつつ各レイヤーで使用する AWS サービスを選定していきました。
Collector のサービス選定
Collector の実装としては、弊社での利用実績を踏まえて以下のサービスを検討した結果、Lambda の使用をメインに設計を進めることにしました。
- EC2
- 今回のワークロードは常時 EC2 を実行するほどの処理能力は必要ないと想定され、管理面・コスト面から過剰と判断
- 仕組みが EC2 へのデプロイや、EC2 上の実行環境に依存
- ECS on EC2
- 今回のワークロードは常時 EC2 を実行するほどの処理能力は必要ないと想定され、管理面・コスト面から過剰と判断
- ECR などの Container Repository に依存
- ECS on Fargate
- Lambda 同様サーバーレスだが、ECR などの Container Repository には依存
- Lambda
- 他のコンピュートレイヤのサービスよりも独立性が高く、今回想定する軽量な処理を実行するのに最適と判断
Storage / Query Interface のサービス選定
Storage / Query Interface は S3 + Athena 構成としました。理由は以下の通りです。
- JOIN を含む SQL を実行したい
- Storage として CloudWatch Logs も検討したがこの要件により却下
- 高速な応答速度やトランザクション処理は求められない
- RDS / DynamoDB / Redshift などの DB サービスを使うメリットが無い
Buffer のサービス選定
Collector と Storage の間のバッファレイヤとして Amazon Data Firehose を採用しました。他にも Kafka / SQS / Kinesis Data Streams 等検討しましたが、以下の理由で Firehose を採用しました。
- Firehose に Put すれば自動で S3 にデータを保存してくれる(追加のコーディングが不要)
- 時間またはデータサイズによりバッファリングして一括で S3 に保存できるため S3 側のファイル数を少なくできる
- 自動で圧縮してくれるため S3 側のファイルサイズが抑えられる
- 動的パーティショニング機能により、S3 のファイルパスを動的に決められる
上記で選定したサービスをベースに、アーキテクチャ案を 5 パターン作成しました。簡易的に、1 リージョンを対象に図示します。
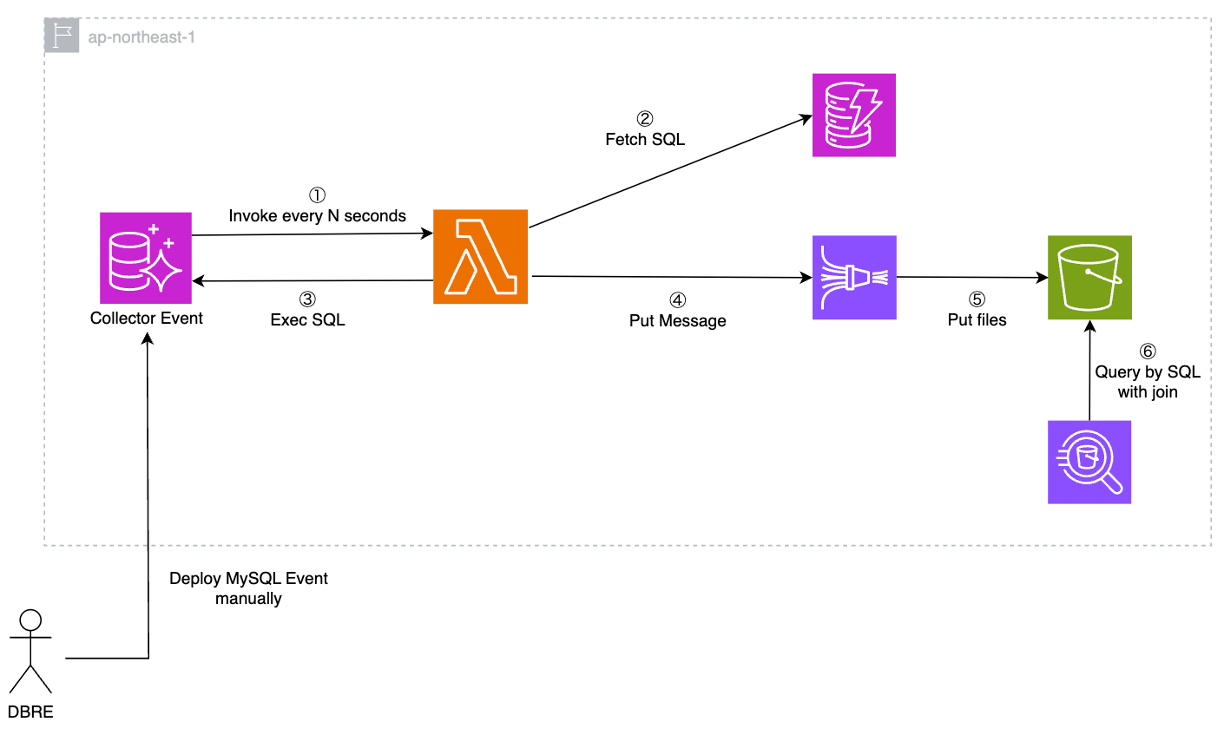
案 1 : MySQL Event で Lambda を実行
Aurora MySQL は Lambda と統合されています。これを利用して、MySQL Event を使って定期的に Lambda を Invoke するパターンです。アーキテクチャは以下の通りです。
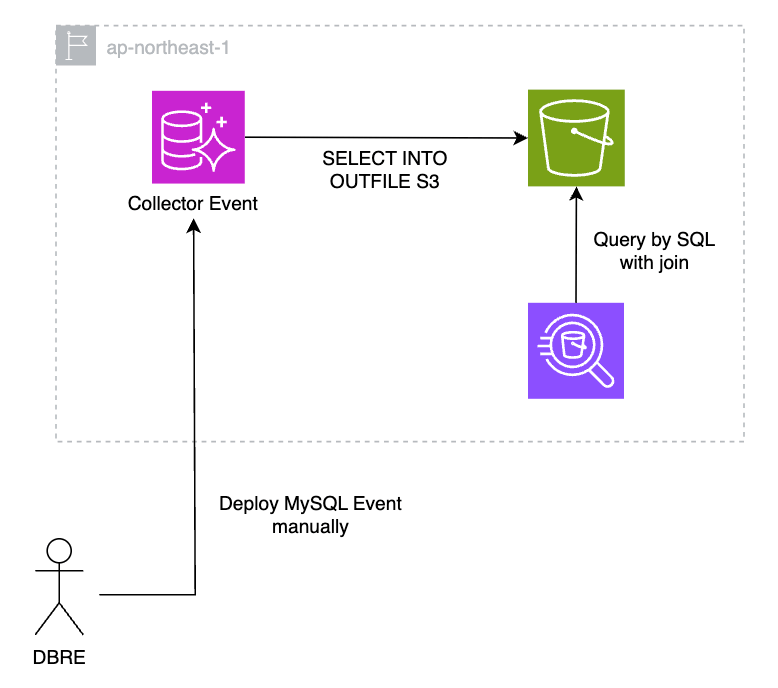
案 2 : Aurora から S3 に直接データを保存
Aurora MySQL は S3 とも統合されており、直接 S3 にデータを保存できます。アーキテクチャは下図の通り非常にシンプルになります。一方で、案1 も同様ですが MySQL Event のデプロイが必要なため、Event の新規作成や修正時に複数の DB クラスタに対して横断的なデプロイが必要になります。手動で個別に対応するか、対象の全クラスタにデプロイする仕組みを用意する必要があります。
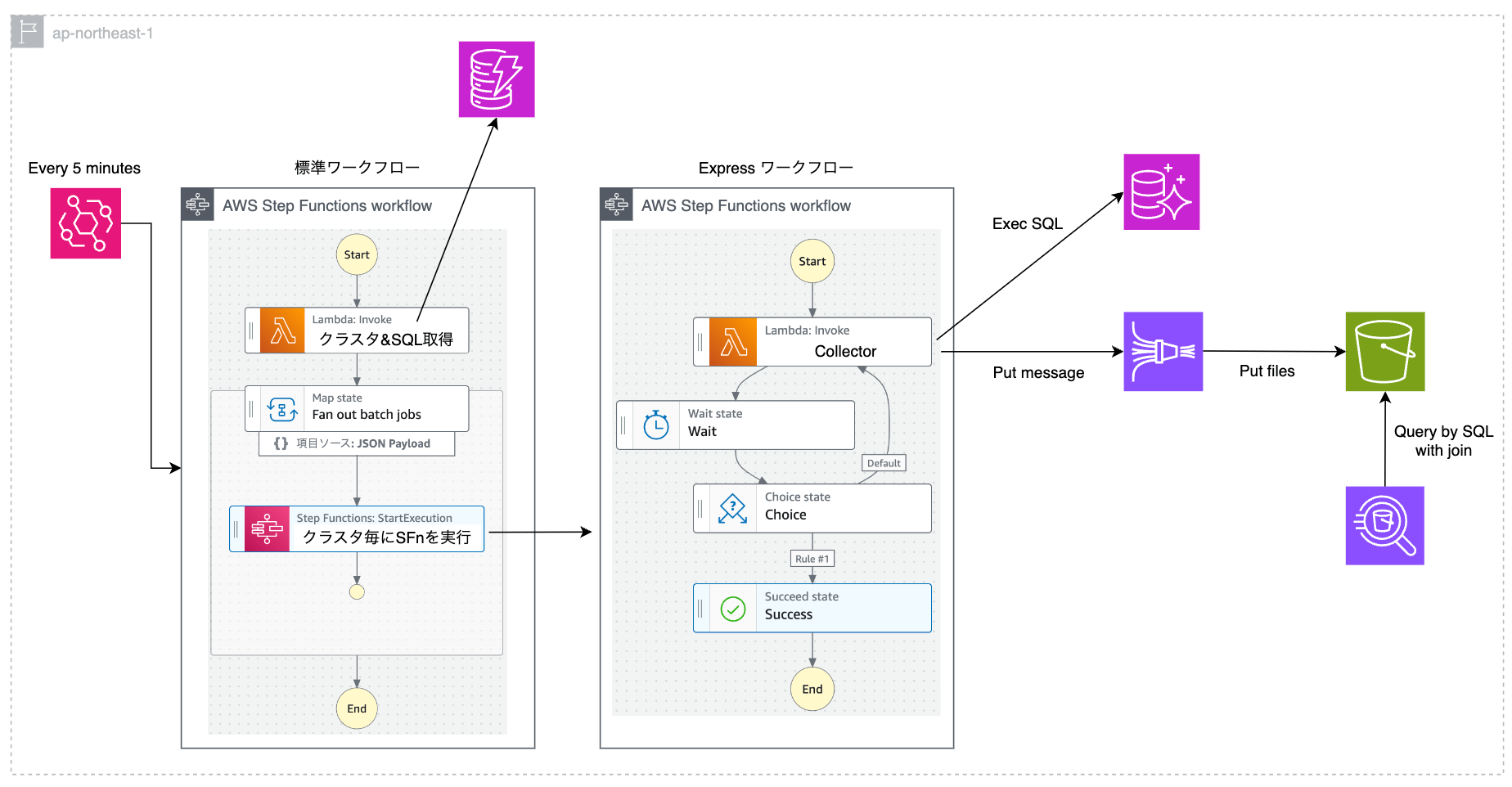
案 3 : Step Functions 案 A パターン
Step Functions と Lambda を組み合わせるパターンです。Map ステートを使うことで、対象のクラスタごとに Collector に相当する 子ワークフロー を並列で実行できます。「N 秒間隔で SQL を実行」という処理は Lambda と Wait ステートの組み合わせで実装します。この実装にするとステートの遷移数が非常に多くなります。Step Functions の標準ワークフローの料金体系ではステートの遷移数に対して課金が発生しますが、Express ワークフローは 1 回あたりの実行時間が最長 5 分という制約があるものの、ステートの遷移数は課金対象となりません。したがって、ステートの遷移数が多くなる箇所は Express ワークフローとして実装します。こちらの AWS Blog を参考にしました。
案 4 : Step Functions 案 B パターン
案 3 と同様、Step Functions と Lambda を組み合わせるパターンです。案 3 と違う点として「N 秒間隔で SQL を実行」という処理は Lambda 内に実装し「SQL を実行 -> N 秒 Sleep」を 10 分間繰り返し続けます。Lambda の実行は最長で 15 分という制約があるため、10 分ごとに EventBridge で Step Functions を起動します。ステートの遷移数が非常に少ないため、Step Functions の金銭的コストを抑えることができます。一方で、Sleep している時間も Lambda が起動し続けるため、Lambda の課金額は 案 3 よりも高くなることが想定されます。
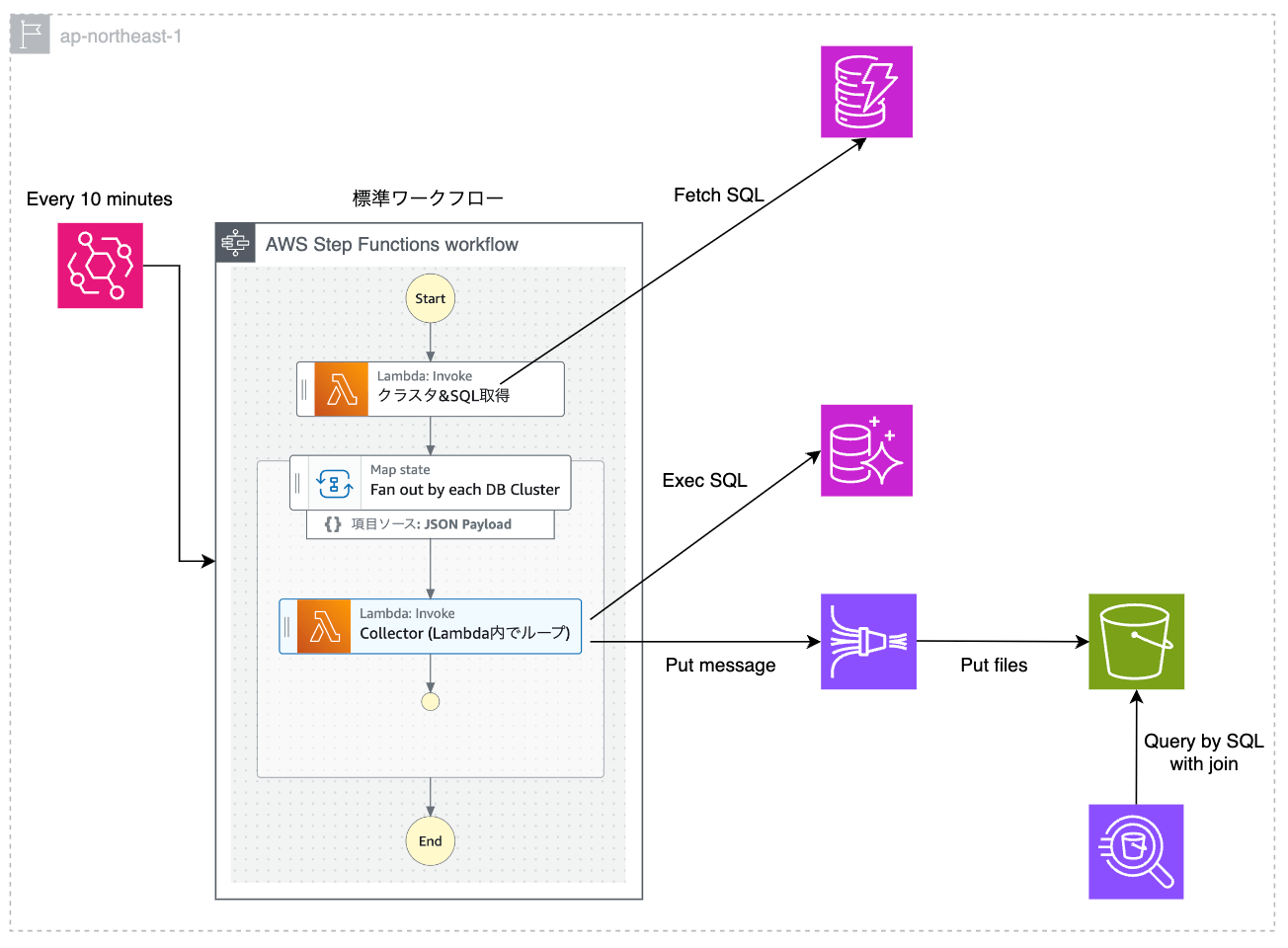
案 5 : Sidecar パターン
弊社ではコンテナオーケストレーションサービスとして主に ECS を使用しており、各 Aurora MySQL にアクセス可能な ECS クラスタが最低 1 つは存在するという前提を利用した案です。タスク内に新規実装した Collector を Sidecar として配置することで、Lambda などの追加のコンピューティングリソースコストが発生しないメリットがあります。ただし、Fargate のリソース内に収まらない場合は拡張が必要になります。
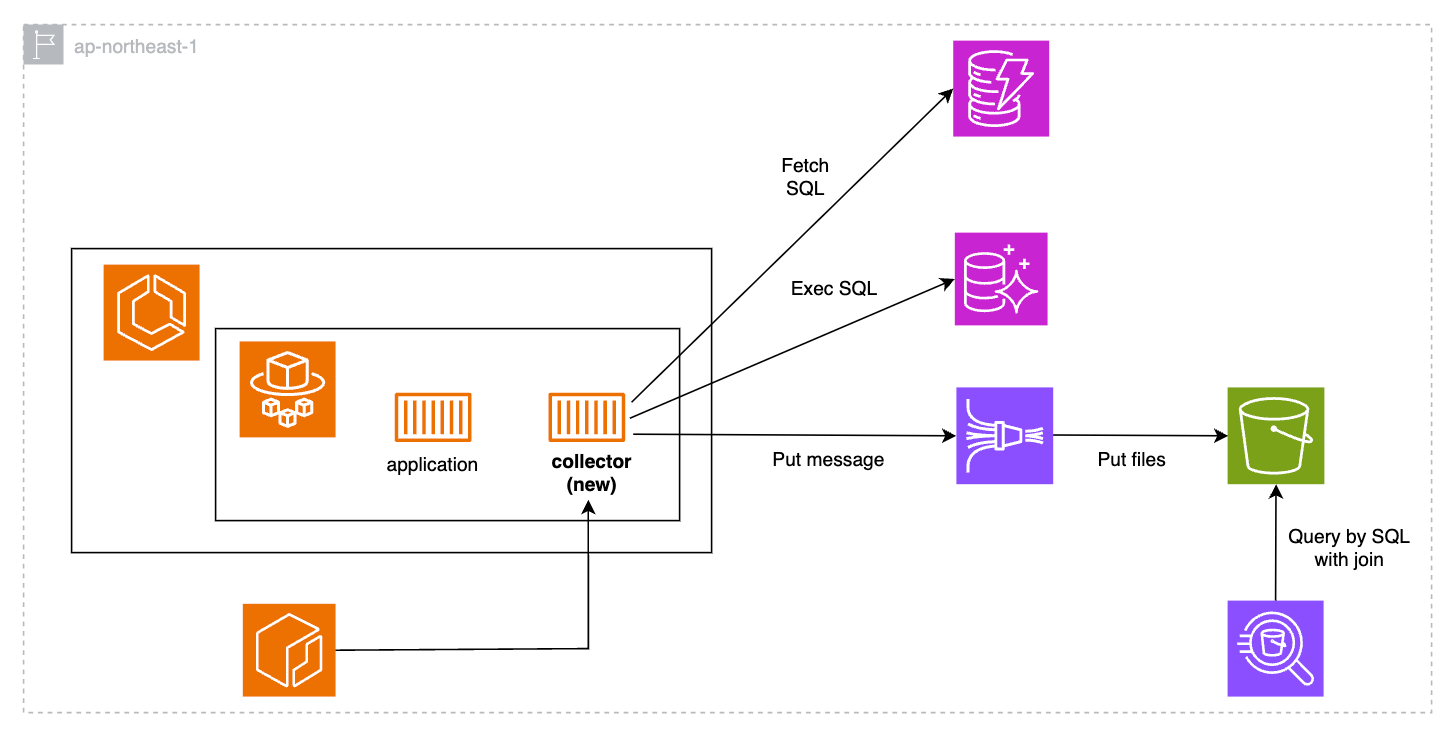
アーキテクチャ比較
各案を比較した結果を以下の通り表にまとめました。
| 案 1 | 案 2 | 案 3 | 案 4 | 案 5 | |
|---|---|---|---|---|---|
| 開発・運用者 | DBRE | DBRE | DBRE | DBRE | コンテナ周りは管轄外のため他チームに依頼が必要 |
| 金銭的コスト | ◎ | ◎ | ⚪︎ | △ | ◎ |
| 実装コスト | △ | ⚪︎ | △ | ⚪︎ | ⚪︎ |
| 開発のアジリティ | ⚪︎(DBRE) | ⚪︎(DBRE) | ⚪︎(DBRE) | ⚪︎(DBRE) | △(チーム間で要調整) |
| デプロイ容易性 | △(Event のデプロイが手動または専用の仕組み作りが必要) | △(Event のデプロイが手動または専用の仕組み作りが必要) | ⚪︎(既存の開発フローで IaC 管理可能) | ⚪︎(既存の開発フローで IaC 管理可能) | △(チーム間で要調整) |
| スケーラビリティ | ⚪︎ | ⚪︎ | ⚪︎ | ⚪︎ | △(Fargate 管轄のチームと要調整) |
| 固有の考慮事項 | Aurora から Lambda を起動するために IAM や DB ユーザーへの権限設定が必要 | バッファリングしないため、S3 への書き込みが同期かつ API 実行回数が多い | Express ワークフローが At least once モデルであることを考慮した実装が必要 | Lambda の実行時間が必要以上に長くなるため、最も金銭的コストが高い | Sidecar コンテナがタスク数と同じ数できるので、処理が重複して実行される |
以上の比較を踏まえて、案 3(標準ワークフローと Express ワークフローを併用した Step Functions を用いる案)を採用しました。理由は以下の通りです。
- 収集データの種類を拡充していく見込みがあり、自チーム(DBRE)で開発・運用をコントロールできる方がスピード感を持って対応できる
- MySQL Event を使用する案はシンプルな構成だが、横断的な IAM 権限の修正や DB ユーザーへの権限追加など気にすべき点が多く、自動化するにしても手動でカバーするにしても人的コストが高い
- 多少実装にコストがかかってもそれ以外でメリットを享受できる案 3 が最もバランスが取れていると判断
以降では、採用した案を実装する過程で工夫した点や最終的なアーキテクチャをご紹介します。
実装
DBRE チームではモノレポで開発を行っており、管理ツールとして Nx を採用しています。インフラストラクチャ管理は Terraform で行い、Lambda の実装は Go 言語で行っています。Nx を用いた DBRE チームの開発フローについては、弊社テックブログ「AWSサーバレスアーキテクチャをMonorepoツール - Nxとterraformで構築してみた!」をご覧ください。
最終的なアーキテクチャ図
マルチリージョン対応やその他の点を考慮し、最終的なアーキテクチャは下図のようになりました。
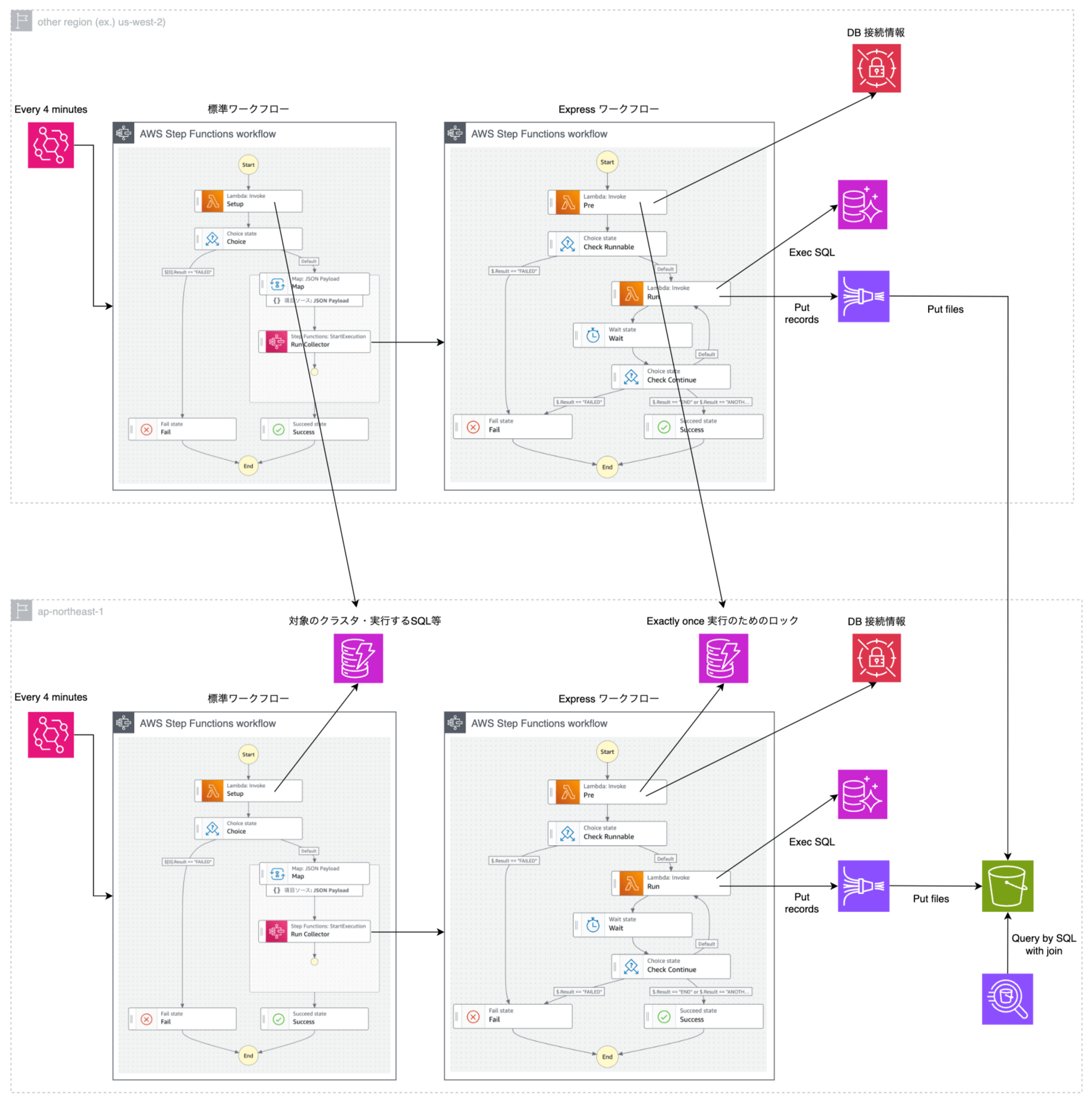
主な考慮事項は以下の通りです。
- Express ワークフローは 5 分で強制終了でエラー扱いとなるため、4 分間経過後に終了
- DynamoDB へのアクセス回数は少なくレイテンシもネックにならないため東京リージョンに集約
- Firehose へ Put した後の S3 へのデータ同期は非同期であるためレイテンシがネックにならず、S3 を東京リージョンに集約
- Secrets Manager への高頻度アクセスによる金銭的コストを抑えるために、シークレットの取得はステートのループ外で実施
- 各 Express ワークフローが複数回実行されるのを防ぐためのロック機構を DynamoDB を使って実装
- ※ Express ワークフローは At least once 実行モデルであるため
以降では、実装時に工夫した点をいくつかご紹介します。
各 DB に専用の DB ユーザーを作成
今回対象の SQL を実行するのに必要な権限は以下の 2 つだけです。
GRANT SELECT ON performance_schema.* TO ${user_name};
-- information_schema.INNODB_TRX の SELECT に必要
GRANT PROCESS ON *.* TO ${user_name};
この権限だけを持つ DB ユーザーが全ての Aurora MySQL に対して作成される仕組みを作りました。弊社では、全ての Aurora MySQL に対して日次で接続し、様々な情報を収集するバッチ処理が存在します。このバッチ処理を修正し、全 DB に対して必要な権限を持った DB ユーザーを作成するようにしました。これにより、新しい DB が作成されても自動で必要な DB ユーザーが存在する状態になりました。
DB 負荷および S3 に保存されるデータサイズの低減
収集対象の 6 テーブルのうちいくつかは、ブロッキングが発生していなくてもレコードが取得できます。そのため N 秒間隔で毎回全件 SELECT すると、わずかではありますが Aurora への負荷が無駄に増え、S3 にもデータが無駄に溜まってしまいます。これを避けるために、ブロッキングが発生している時だけ関連するテーブルを全件 SELECT するような実装にしました。ブロッキング検知用の SQL も負荷を最小限に抑えることを意識して、以下の通り整理しました。
メタデータのブロッキング発生検知
メタデータのブロッキング発生検知クエリは以下の通りです。
select * from `performance_schema`.`metadata_locks`
where lock_status = 'PENDING' limit 1
このクエリでレコードが取得できた時だけ、以下の 3 テーブルを全件 SELECT して Firehose へ Put します。
- performance_schema.metadata_locks
- performance_schema.threads
- performance_schema.events_statements_current
InnoDB のブロッキング発生検知
InnoDB のブロッキング発生検知クエリは以下の通りです。
select * from `information_schema`.`INNODB_TRX`
where timestampdiff(second, `TRX_WAIT_STARTED`, now()) >= 1 limit 1;
このクエリでレコードが取得できた時だけ、以下の 3 テーブルを全件 SELECT して Firehose へ Put します。
- performance_schema.data_lock_waits
- information_schema.INNODB_TRX
- performance_schema.data_locks
goroutine を用いたクエリの並行処理
各テーブルへの SELECT 実行タイミングに多少のズレがあっても、ブロッキングが継続していれば後で JOIN したときにデータ不整合が発生する確率は低いといえます。しかし、できるだけ同じタイミングで実施した方が望ましくはあります。また「N 秒間隔でデータが収集され続ける」という状態を達成するためには、Collector の Lambda の実行時間を可能な限り短く終了させる必要もあります。以上 2 点を踏まえて、クエリ実行は goroutine を用いて可能な限り並行処理しています。
想定外の過負荷を避けるためのセッション変数の使用
事前に実行予定のクエリ負荷が十分に低いことは確認していますが、時には「想定以上に実行時間が長くなる」「情報収集のクエリがブロッキングに巻き込まれる」といった状況も考えられます。したがって、できる限り安全に情報を取得し続けるために max_execution_time と TRANSACTION ISOLATION LEVEL READ UNCOMMITTED をセッションレベルで設定しています。
Go 言語でこの処理を実装するために、database/sql/driver パッケージの driver.Connector インタフェースの関数 Connect() をオーバーライドしています。エラー処理を除いた実装イメージとしては以下のとおりです。
type sessionCustomConnector struct {
driver.Connector
}
func (c *sessionCustomConnector) Connect(ctx context.Context) (driver.Conn, error) {
conn, err := c.Connector.Connect(ctx)
execer, _ := conn.(driver.ExecerContext)
sessionContexts := []string{
"SET SESSION max_execution_time = 1000",
"SET SESSION TRANSACTION ISOLATION LEVEL READ UNCOMMITTED",
}
for _, sessionContext := range sessionContexts {
execer.ExecContext(ctx, sessionContext, nil)
}
return conn, nil
}
func main() {
cfg, _ := mysql.ParseDSN("dsn_string")
defaultConnector, _ := mysql.NewConnector(cfg)
db := sql.OpenDB(&sessionCustomConnector{defaultConnector})
rows, _ := db.Query("SELECT * FROM performance_schema.threads")
...
}
Express ワークフローのためのロック機構
StepFunctions の Express ワークフローは At least once 実行モデルのため、ワークフロー全体が複数回実行される可能性があります。今回のケースだと重複実行されても大きな問題ではないのですが、Exactly once の方が望ましくはあるため、AWS Blog を参考に DynamoDB を用いた簡易的なロック機構を実装しました。
具体的には、Express ワークフロー開始時に実行される Lambda で、DynamoDB のテーブルに attribute_not_exists 条件式つきでデータを PUT します。パーティションキーには、親ワークフローで生成した一意な ID を指定するため「PUT が成功する = 自分自身が初回実行者」である、と判断できます。失敗した場合は既に別の子ワークフローが稼働中と判断し、以降の処理をスキップして終了します。
Amazon Data Firehose の動的パーティショニングの活用
Firehose の動的パーティショニング機能を使って、S3 のファイルパスを動的に決定しています。動的パーティショニングのためのルール(S3 バケットプレフィクス)は、後述の Athena でのアクセス制御も考慮して以下のように設定しました。
!{partitionKeyFromQuery:db_schema_name}/!{partitionKeyFromQuery:table_name}/!{partitionKeyFromQuery:env_name}/!{partitionKeyFromQuery:service_name}/day=!{timestamp:dd}/hour=!{timestamp:HH}/
この設定を入れた Firehose の Stream に json データを Put すると、json 内の属性からパーティションキーとなる属性を探して、自動でルール通りのファイルパスで S3 へ保存してくれます。
例えば、以下の json データを Firehose へ Put したとします。
{
"db_schema_name":"performance_schema",
"table_name":"threads",
"env_name":"dev",
"service_name":"some-service",
"other_attr1":"hoge",
"other_attr2":"fuga",
...
}
その結果 S3 へ保存されるファイルパスは以下のようになります。Firehose へ Put する際にファイルパスを指定する必要は一切なく、事前に定義しておいたルールに基づいて Firehose が自動でファイル名を決定して保存してくれています。

Firehose が S3 に保存したファイル : 動的パーティショニングでファイルパスは自動で決定
スキーマ名やテーブル名などは MySQL テーブルの SELECT 結果には存在しないため、Firehose に Put する json を生成するタイミングで共通のカラムとして追加するように実装しています。
Athena のテーブルとアクセス権限の設計
MySQL 側のテーブル定義をもとに、Athena 側でテーブルを作成する例を 1 テーブル分ご紹介します。
performance_schema.metadata_locks の MySQL 側の CREATE 文は以下の通りです。
CREATE TABLE `metadata_locks` (
`OBJECT_TYPE` varchar(64) NOT NULL,
`OBJECT_SCHEMA` varchar(64) DEFAULT NULL,
`OBJECT_NAME` varchar(64) DEFAULT NULL,
`COLUMN_NAME` varchar(64) DEFAULT NULL,
`OBJECT_INSTANCE_BEGIN` bigint unsigned NOT NULL,
`LOCK_TYPE` varchar(32) NOT NULL,
`LOCK_DURATION` varchar(32) NOT NULL,
`LOCK_STATUS` varchar(32) NOT NULL,
`SOURCE` varchar(64) DEFAULT NULL,
`OWNER_THREAD_ID` bigint unsigned DEFAULT NULL,
`OWNER_EVENT_ID` bigint unsigned DEFAULT NULL,
PRIMARY KEY (`OBJECT_INSTANCE_BEGIN`),
KEY `OBJECT_TYPE` (`OBJECT_TYPE`,`OBJECT_SCHEMA`,`OBJECT_NAME`,`COLUMN_NAME`),
KEY `OWNER_THREAD_ID` (`OWNER_THREAD_ID`,`OWNER_EVENT_ID`)
)
これを Athena 用として以下のように定義しました。
CREATE EXTERNAL TABLE `metadata_locks` (
`OBJECT_TYPE` string,
`OBJECT_SCHEMA` string,
`OBJECT_NAME` string,
`COLUMN_NAME` string,
`OBJECT_INSTANCE_BEGIN` bigint,
`LOCK_TYPE` string,
`LOCK_DURATION` string,
`LOCK_STATUS` string,
`SOURCE` string,
`OWNER_THREAD_ID` bigint,
`OWNER_EVENT_ID` bigint,
`db_schema_name` string,
`table_name` string,
`aurora_cluster_timezone` string,
`stats_collected_at_utc` timestamp
)
PARTITIONED BY (
env_name string,
service_name string,
day int,
hour int
)
ROW FORMAT SERDE 'org.openx.data.jsonserde.JsonSerDe'
LOCATION 's3://<bucket_name>/performance_schema/metadata_locks/'
TBLPROPERTIES (
"projection.enabled" = "true",
"projection.day.type" = "integer",
"projection.day.range" = "01,31",
"projection.day.digits" = "2",
"projection.hour.type" = "integer",
"projection.hour.range" = "0,23",
"projection.hour.digits" = "2",
"projection.env_name.type" = "injected",
"projection.service_name.type" = "injected",
"storage.location.template" = "s3://<bucket_name>/performance_schema/metadata_locks/${env_name}/${service_name}/day=${day}/hour=${hour}"
);
ポイントはパーティションキーの設計です。これにより「元の DB へのアクセス権限を持った人だけがデータにアクセスできる」状態にしています。弊社では、各サービスに固有の service_name と、環境ごとに固有の env_name という 2 つのタグを全ての AWS リソースに付与しており、このタグをアクセス制御手段の 1 つとして活用しています。この 2 つのタグを S3 に保存するファイルパスの一部に含め、各サービスに共通で付与している IAM Policy に対してポリシー変数を用いて Resource を記述することで、同じテーブルであってもアクセス権限を持っている S3 のファイルパスに相当するパーティションのデータしか SELECT できない、という状態にしています。
各サービスに共通で付与している IAM Policy に付与する権限のイメージは以下の通りです。
{
"Effect": "Allow",
"Action": [
"s3:GetObject"
],
"Resource": [
"arn:aws:s3:::<bukect_name>/*/${aws:PrincipalTag/env_name}/${aws:PrincipalTag/service_name}/*"
]
}
また、今回はパーティションをメンテナンスフリーにしたかったので、パーティション射影を使っています。パーティション射影を使う場合、基本的にはパーティションキーの取りうる値の範囲が既知である必要がありますが、injected 射影型を使うことで値の範囲を Athena に伝える必要なく、メンテナンスフリーな動的パーティショニングを実現しています。
Athena 側での View の再現
ブロッキングの事後調査に必要な 6 つのテーブルを Athena に作成し、MySQL 側と同様に View でラップした方法をご紹介します。View の定義は、MySQL 側の View 定義をもとに、前述の共通カラムを付与したり、パーティションキーの比較を JOIN 句に追加するなどの修正を加えました。
sys.innodb_lock_waits の Athena 側での定義は以下の通りです。
CREATE OR REPLACE VIEW innodb_lock_waits AS
select
DATE_ADD('hour', 9, w.stats_collected_at_utc) as stats_collected_at_jst,
w.stats_collected_at_utc as stats_collected_at_utc,
w.aurora_cluster_timezone as aurora_cluster_timezone,
r.trx_wait_started AS wait_started,
date_diff('second', r.trx_wait_started, r.stats_collected_at_utc) AS wait_age_secs,
rl.OBJECT_SCHEMA AS locked_table_schema,
rl.OBJECT_NAME AS locked_table_name,
rl.PARTITION_NAME AS locked_table_partition,
rl.SUBPARTITION_NAME AS locked_table_subpartition,
rl.INDEX_NAME AS locked_index,
rl.LOCK_TYPE AS locked_type,
r.trx_id AS waiting_trx_id,
r.trx_started AS waiting_trx_started,
date_diff('second', r.trx_started, r.stats_collected_at_utc) AS waiting_trx_age_secs,
r.trx_rows_locked AS waiting_trx_rows_locked,
r.trx_rows_modified AS waiting_trx_rows_modified,
r.trx_mysql_thread_id AS waiting_pid,
r.trx_query AS waiting_query,
rl.ENGINE_LOCK_ID AS waiting_lock_id,
rl.LOCK_MODE AS waiting_lock_mode,
b.trx_id AS blocking_trx_id,
b.trx_mysql_thread_id AS blocking_pid,
b.trx_query AS blocking_query,
bl.ENGINE_LOCK_ID AS blocking_lock_id,
bl.LOCK_MODE AS blocking_lock_mode,
b.trx_started AS blocking_trx_started,
date_diff('second', b.trx_started, b.stats_collected_at_utc) AS blocking_trx_age_secs,
b.trx_rows_locked AS blocking_trx_rows_locked,
b.trx_rows_modified AS blocking_trx_rows_modified,
concat('KILL QUERY ', cast(b.trx_mysql_thread_id as varchar)) AS sql_kill_blocking_query,
concat('KILL ', cast(b.trx_mysql_thread_id as varchar)) AS sql_kill_blocking_connection,
w.env_name as env_name,
w.service_name as service_name,
w.day as day,
w.hour as hour
from
(
(
(
(
data_lock_waits w
join INNODB_TRX b on(
(
b.trx_id = cast(
w.BLOCKING_ENGINE_TRANSACTION_ID as bigint
)
)
and w.stats_collected_at_utc = b.stats_collected_at_utc and w.day = b.day and w.hour = b.hour and w.env_name = b.env_name and w.service_name = b.service_name
)
)
join INNODB_TRX r on(
(
r.trx_id = cast(
w.REQUESTING_ENGINE_TRANSACTION_ID as bigint
)
)
and w.stats_collected_at_utc = r.stats_collected_at_utc and w.day = r.day and w.hour = r.hour and w.env_name = r.env_name and w.service_name = r.service_name
)
)
join data_locks bl on(
bl.ENGINE_LOCK_ID = w.BLOCKING_ENGINE_LOCK_ID
and bl.stats_collected_at_utc = w.stats_collected_at_utc and bl.day = w.day and bl.hour = w.hour and bl.env_name = w.env_name and bl.service_name = w.service_name
)
)
join data_locks rl on(
rl.ENGINE_LOCK_ID = w.REQUESTING_ENGINE_LOCK_ID
and rl.stats_collected_at_utc = w.stats_collected_at_utc and rl.day = w.day and rl.hour = w.hour and rl.env_name = w.env_name and rl.service_name = w.service_name
)
)
また、sys.schema_table_lock_waits の Athena 側での定義は以下の通りです。
CREATE OR REPLACE VIEW schema_table_lock_waits AS
select
DATE_ADD('hour', 9, g.stats_collected_at_utc) as stats_collected_at_jst,
g.stats_collected_at_utc AS stats_collected_at_utc,
g.aurora_cluster_timezone as aurora_cluster_timezone,
g.OBJECT_SCHEMA AS object_schema,
g.OBJECT_NAME AS object_name,
pt.THREAD_ID AS waiting_thread_id,
pt.PROCESSLIST_ID AS waiting_pid,
-- sys.ps_thread_account(p.OWNER_THREAD_ID) AS waiting_account, -- MySQL 側での情報収集時に select に含めておく必要があるが、不要なため未対応
p.LOCK_TYPE AS waiting_lock_type,
p.LOCK_DURATION AS waiting_lock_duration,
pt.PROCESSLIST_INFO AS waiting_query,
pt.PROCESSLIST_TIME AS waiting_query_secs,
ps.ROWS_AFFECTED AS waiting_query_rows_affected,
ps.ROWS_EXAMINED AS waiting_query_rows_examined,
gt.THREAD_ID AS blocking_thread_id,
gt.PROCESSLIST_ID AS blocking_pid,
-- sys.ps_thread_account(g.OWNER_THREAD_ID) AS blocking_account, -- MySQL 側での情報収集時に select に含めておく必要があるが、不要なため未対応
g.LOCK_TYPE AS blocking_lock_type,
g.LOCK_DURATION AS blocking_lock_duration,
concat('KILL QUERY ', cast(gt.PROCESSLIST_ID as varchar)) AS sql_kill_blocking_query,
concat('KILL ', cast(gt.PROCESSLIST_ID as varchar)) AS sql_kill_blocking_connection,
g.env_name as env_name,
g.service_name as service_name,
g.day as day,
g.hour as hour
from
(
(
(
(
(
metadata_locks g
join metadata_locks p on(
(
(g.OBJECT_TYPE = p.OBJECT_TYPE)
and (g.OBJECT_SCHEMA = p.OBJECT_SCHEMA)
and (g.OBJECT_NAME = p.OBJECT_NAME)
and (g.LOCK_STATUS = 'GRANTED')
and (p.LOCK_STATUS = 'PENDING')
AND (g.stats_collected_at_utc = p.stats_collected_at_utc and g.day = p.day and g.hour = p.hour and g.env_name = p.env_name and g.service_name = p.service_name)
)
)
)
join threads gt on(g.OWNER_THREAD_ID = gt.THREAD_ID and g.stats_collected_at_utc = gt.stats_collected_at_utc and g.day = gt.day and g.hour = gt.hour and g.env_name = gt.env_name and g.service_name = gt.service_name)
)
join threads pt on(p.OWNER_THREAD_ID = pt.THREAD_ID and p.stats_collected_at_utc = pt.stats_collected_at_utc and p.day = pt.day and p.hour = pt.hour and p.env_name = pt.env_name and p.service_name = pt.service_name)
)
left join events_statements_current gs on(g.OWNER_THREAD_ID = gs.THREAD_ID and g.stats_collected_at_utc = gs.stats_collected_at_utc and g.day = gs.day and g.hour = gs.hour and g.env_name = gs.env_name and g.service_name = gs.service_name)
)
left join events_statements_current ps on(p.OWNER_THREAD_ID = ps.THREAD_ID and p.stats_collected_at_utc = ps.stats_collected_at_utc and p.day = ps.day and p.hour = ps.hour and p.env_name = ps.env_name and p.service_name = ps.service_name)
)
where
(g.OBJECT_TYPE = 'TABLE')
結果
構築した仕組みを使って実際にブロッキングを発生させ、Athena 側で調査を行なってみます。
select *
from innodb_lock_waits
where
stats_collected_at_jst between timestamp '2024-03-01 15:00:00' and timestamp '2024-03-01 16:00:00'
and env_name = 'dev'
and service_name = 'some-service'
and hour between
cast(date_format(DATE_ADD('hour', -9, timestamp '2024-03-01 15:00:00'), '%H') as integer)
and cast(date_format(DATE_ADD('hour', -9, timestamp '2024-03-01 16:00:00'), '%H') as integer)
and day = 1
order by stats_collected_at_jst asc
limit 100
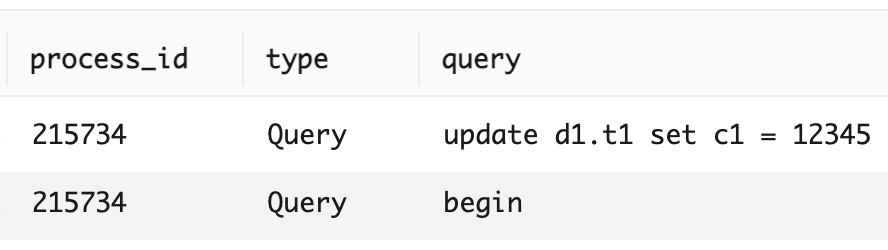
ブロッキングが発生していた時間帯を指定して Athena で上記クエリを実行すると、以下のような結果が返ってきます。
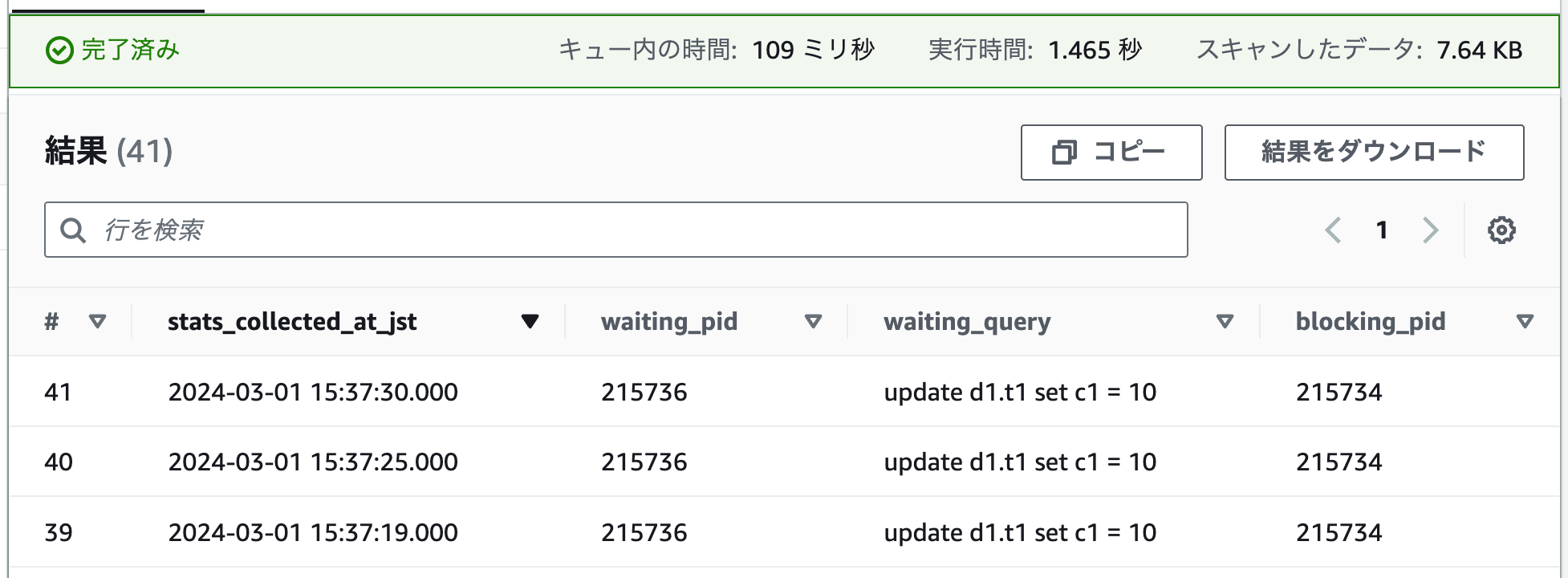
ブロッカーの SQL は分からないため、プロセス ID(blocking_pid カラム)をもとに CloudWatch Logs Insights を使ってブロッカーが実行した SQL の履歴を確認します。
fields @timestamp, @message
| parse @message /(?<timestamp>[^\s]+)\s+(?<process_id>\d+)\s+(?<type>[^\s]+)\s+(?<query>.+)/
| filter process_id = 215734
| sort @timestamp desc
以下のような結果が得られ、ブロッカーの SQL が update d1.t1 set c1 = 12345 であることを特定できました。
同様の手順で schema_table_lock_waits でもメタデータ関連のブロッキング状況を確認することができるようになりました。
今後の展望
今後の展望としては、以下のようなことを考えています。
- プロダクトへの展開はこれからなので、実運用を通してブロッキング起因のインシデントに関する知見をためる
- Lambda の 課金時間(Billed Duration) を最小化するためのボトルネック調査とチューニング
- performance_schema と information_schema における収集対象の拡充
- インデックス使用状況の分析など調査の幅を広げる
- インシデント対応からのフィードバックで収集情報を拡充するサイクルを回すことで、DB レイヤーの課題解決力を向上
- Amazon QuickSight などの BI サービスによる可視化
- performance_schema 等に精通していないメンバーでも原因調査できる世界にする
まとめ
本記事では、Aurora MySQL で発生したロック競合(ブロッキング)起因のタイムアウトエラーの原因調査をきっかけに、ブロッキング原因を後追いするために必要な情報を定期的に収集する仕組みを構築した事例をご紹介しました。MySQL でブロッキングの情報を後追いするためにはメタデータロックと InnoDB のロックという 2 種類のロックに関する待ち情報を以下の 6 テーブルを使って定期的に収集する必要があります。
- メタデータロック
- performance_schema.metadata_locks
- performance_schema.threads
- performance_schema.events_statements_current
- InnoDB のロック
- performance_schema.data_lock_waits
- information_schema.INNODB_TRX
- performance_schema.data_locks
弊社の環境を踏まえてマルチリージョンかつ、複数の DB クラスタに対して情報収集を実施できるアーキテクチャを設計し、実装しました。その結果、ブロッキング発生から最長 5 分のタイムラグで SQL ベースで事後調査が実施でき、結果が数秒で返ってくるような仕組みを構築することができました。いずれ SaaS や AWS サービスへも組み込まれる機能かもしれませんが、DBRE チームでは必要と判断すれば積極的に自分たちで機能を実装することを大切にしています。
KINTO テクノロジーズ DBRE チームでは一緒に働いてくれる仲間を絶賛募集中です!カジュアルな面談も歓迎ですので、 少しでも興味を持っていただけた方はお気軽に X の DM 等でご連絡ください。併せて、弊社の採用 Twitter もよろしければフォローお願いします!
Appendix : 参考記事
MySQL 8.0 系におけるブロッキングの調査方法は、以下の記事にとても分かりやすくまとまっており参考にさせていただきました。
また、ブロッカーが分かった後は「どんなロックが起因でブロッキングが起きていたか」といった深掘りも必要ですが、MySQL のロックについては以下の記事にとてもわかりやすくまとまっております。
MySQL のリファレンスも参考にさせていただきました。
関連記事 | Related Posts

Aurora MySQL におけるロック競合(ブロッキング)の原因を事後調査できる仕組みを作った話

Investigating the Cause of a Deadlock in Aurora MySQL 3 series in a Production Environment
本番環境で発生したAurora MySQL 3 系のデッドロックの原因を調査した話
Investigating Why Aurora MySQL Returns “Empty set” in Response to SELECT, Even Though Corresponding Records Exist
Aurora MySQL でレコードが存在するのに SELECT すると Empty set が返ってくる事象を調査した話
What is the cause of invisible errors? Concerning the issue observed in Amazon Aurora MySQL 2, where the mysqldump command unexpectedly terminates without displaying an error message, attributed to the database collation.
We are hiring!
シニアQAエンジニア(責任者候補)/Quality Engineering G/東京・大阪
「テストするQA」から「品質戦略を描くQA」へ。AIがコードを書くことが当たり前になりつつある今、品質保証のあり方そのものが問われています。
【クラウドセキュリティエンジニア】クラウドセキュリティG/東京・名古屋・大阪・福岡
ミッションクラウドセキュリティの専門組織として、KINTO テクノロジーズのマルチクラウド環境のセキュリティガバナンスに責任を持ちます。 セキュリティリスクを発生させない セキュリティリスクを常に監視・分析する セキュリティリスクが発生したときに速やかに対応する 業務内容ミッションを達成するために様々な業務を実施します。

