11 min read
Development
Uncovering and Resolving Memory Leaks in Web Services

Introduction
Hello! I'm Cui from the Global Development Division at KINTO Technologies. I'm currently involved in the development of KINTO FACTORY, and this year, I collaborated with team members to investigate the cause of memory leaks in our web service, identify the issues, and implement fixes to resolve them. This blog post will outline the investigation approach, the tools utilized, the results obtained, and the measures implemented to address the memory leaks.
Background
The KINTO FACTORY site that we are currently developing and managing operates a web service hosted on AWS ECS. This service utilizes a member platform, an authentication service, and a payment platform, a payment processing service, both of which have been developed and managed by our company.
In January of this year, the CPU utilization of the ECS task for this web service spiked abnormally, leading to a temporary outage and making the service inaccessible. During this time, an incident occurred where a 404 error and an error dialog were displayed during certain screen transitions or operations on the KINTO FACTORY site.
A similar memory leak occurred last July, which was traced to frequent Full GCs (cleanup of the old generation), leading to a significant increase in CPU utilization.
In such cases, a temporary solution is to restart the ECS task. However, it is crucial to identify and resolve the root cause of the memory leak to prevent recurrence This article outlines the investigation and analysis of these events, offering solutions based on the findings from these cases.
Summary of Investigation Findings and Results
Details of Investigation
First, a detailed analysis of the event that occurred in this case revealed that the abnormally high CPU utilization of the web service was a problem caused by frequent Full GCs (cleanup of the old generation). Typically, after a Full GC is performed, a significant amount of memory is freed, and it shouldn't need to occur again for some time. Nonetheless, the frequent occurrence of Full GCs is likely to be excessive consumption of memory in use, suggesting that a memory leak is occurring. To test this hypothesis, we replicated the memory leak by continuously calling the APIs over an extended period, focusing primarily on those that were frequently called during the timeframe when the memory leak occurred. test this hypothesis, we reproduced the memory leak by continuously calling APIs for an extended period, mainly for those that were frequently called during the period when the memory leak occurred. The memory status and dumps were then analyzed to pinpoint the root cause of the issue. The tools used for the investigation were:
- API traffic simulation with JMeter
- Monitoring memory state using VisualVM and Grafana (local and verification environments)
- Filtering frequently called APIs with OpenSearch
Additionally, here's a brief explanation of the "old generation" memory frequently mentioned: In Java memory management, the heap is divided into two parts, the young generation and the old generation. The young generation consists of newly created objects. Objects that persist for a certain duration in this space are gradually moved through the survivor spaces into the old generation. The old generation stores long-lived objects, and when it becomes full, a Full GC will occur. The survivor spaces are part of the young generation that track how long objects have survived.
Result
A significant number of new connection instances were being created during external service requests, leading to memory leaks caused by excessive and unnecessary memory consumption.
Details of Investigation
1. Identify frequently called APIs
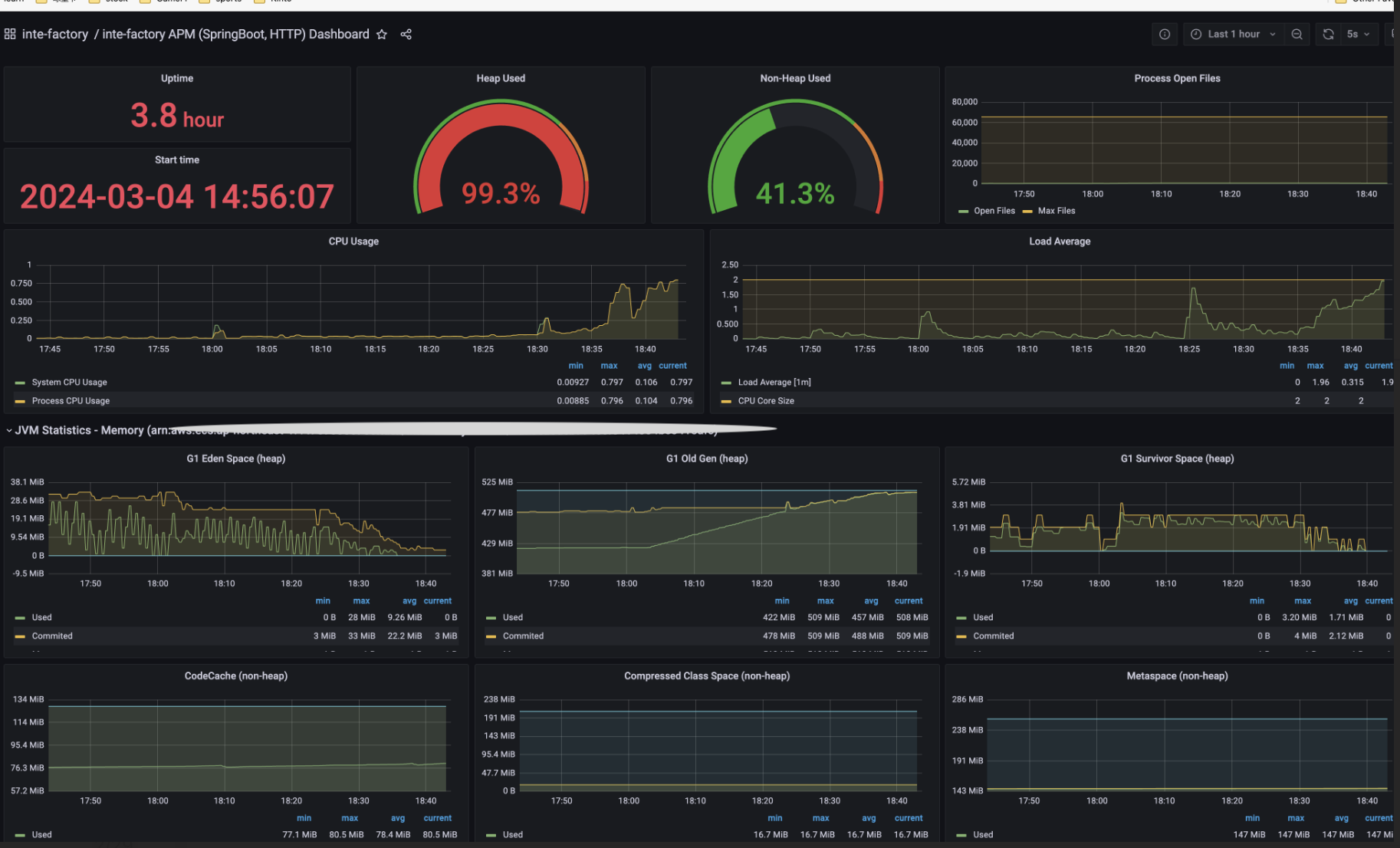
To get started, we created a dashboard in OpenSearch summarizing API calls to understand the most frequently called processes and their memory usage.
![]()
2. Continue invoking the identified APIs in the local environment for 30 minutes, and afterward, analyze the results.
Investigation Method
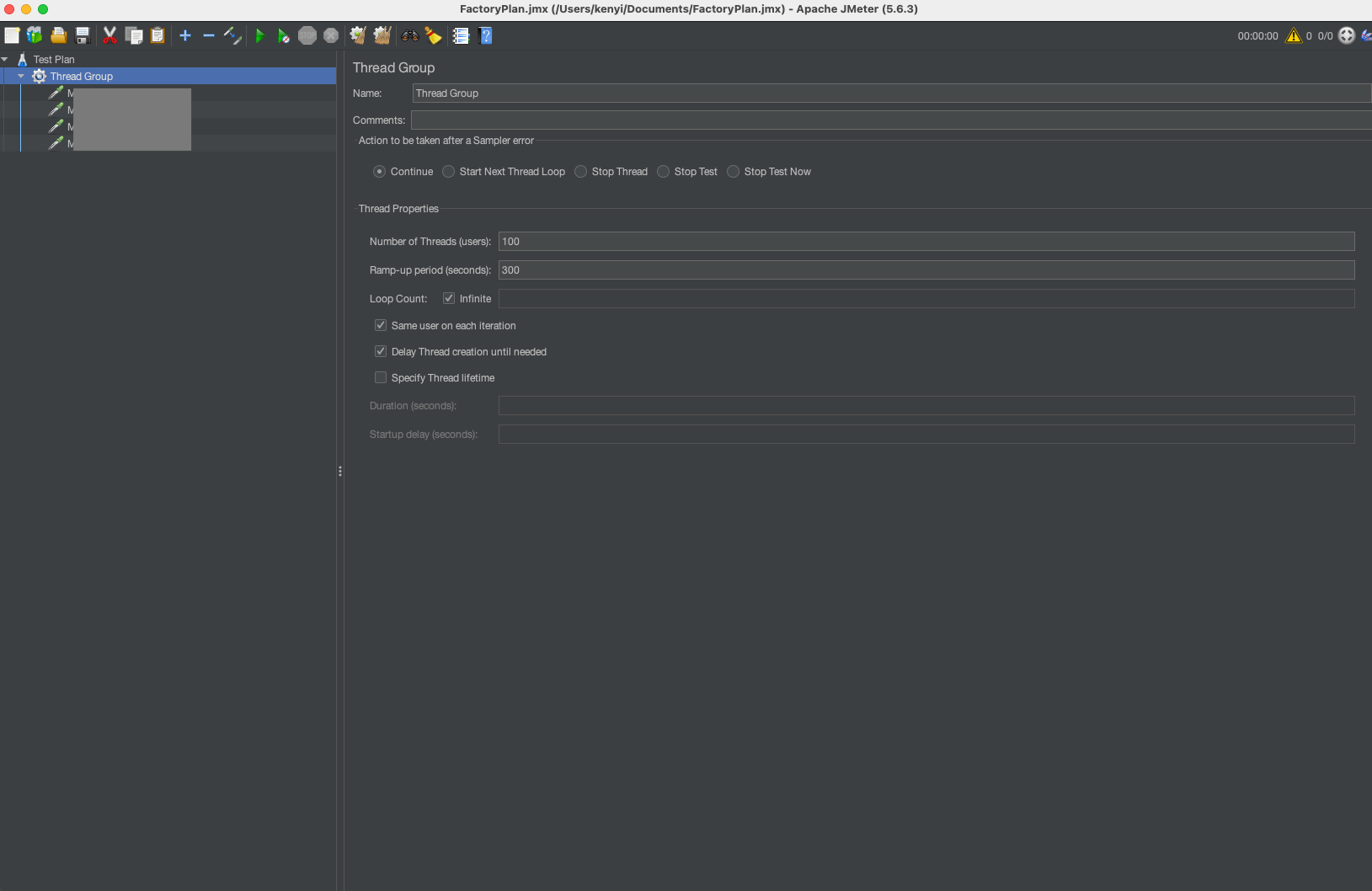
To reproduce the memory leak in the local environment and capture a memory dump for root cause analysis, we used JMeter with the following settings to call the APIs continuously for 30 minutes.
- JMeter settings
- Number of threads: 100
- Ramp-up period*: 300 seconds
- Test environment
- Mac OS
- Java version: OpenJDK 17.0.7 2023-04-18 LTS
- Java configuration: -Xms1024m -Xmx3072m
*Ramp-up period is the amount of time in seconds during which the specified number of threads will be started and executed.
Result and hypothesis
No memory leak occurred. We assumed that the memory leak was not reproduced because it was different from the actual environment. Since the actual environment runs on Docker, we decided to put the application in a Docker container and validate it again.
![]()
3. Continue calling the APIs again in the Docker environment, then analyze the results
Investigation Method
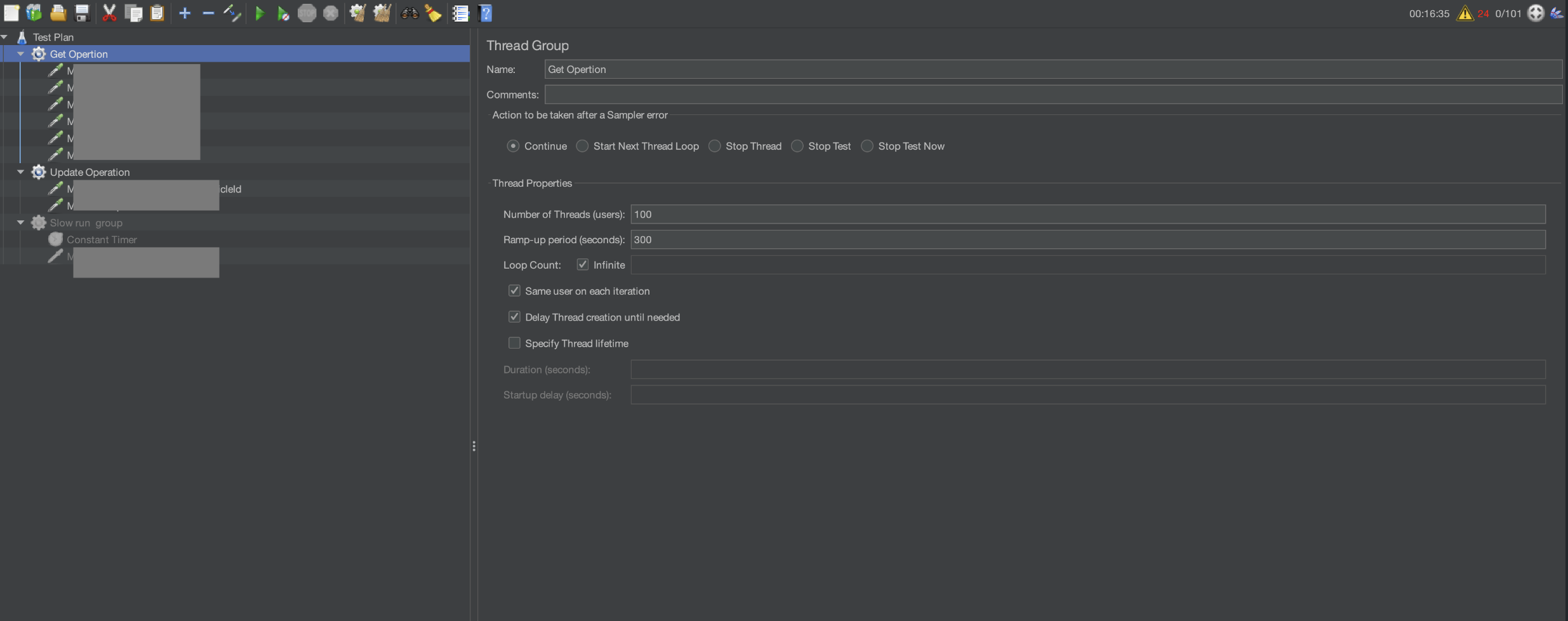
To reproduce the memory leak in the local environment, we used JMeter with the following settings and kept calling the APIs for one hour.
- JMeter settings
- Number of threads: 100
- Ramp-up period: 300 seconds
- Test environment
- Local Docker container on Mac
- Memory limits: 4 GB
- CPU limits: 4 cores
Results
No memory leak occurred even if the environment is changed in the local environment.
Hypothesis
- Different from actual environment
- No external APIs are being called
- API calls for an extended period may gradually accumulate memory
- Objects that are too large may not fit into survivor spaces and end up in the old generation
Since the issue could not be reproduced in the local environment, we decided to re-validate it in a verification environment that closely mirrors the production environment.
4. Continue making requests to the relevant external APIs in the verification environment for an extended period, and then analyze the results for any anomalies or issues.
Investigation Method
To reproduce the memory leak in the verification environment, we used JMeter with the following settings and kept calling the APIs.
- Called APIs: total 7
- Duration: 5 hours
- Number of users: 2
- Loop: 200 (Planned 1000, but changed to 200 due to low actual orders)
- Total Factory API calls: 4000
- Affected external platforms: Member platform (1600), Payment platform (200)
Results
No Full GC occurred, and memory leak was not reproduced.
Hypothesis
No Full GC was triggered because the number of loops was low. While memory usage was increasing, it had not yet reached the upper threshold. We will increase the number of API calls and reduce the memory limit to trigger a Full GC for further analysis.
5. Reduce the memory limit and continue hitting the APIs over an extended period to observe memory behavior and potential GC activity.
Investigation Method
We lowered the memory limit in the verification environment and kept calling the member platform-related APIs in JMeter for 4 hours.
- Duration: 4 hours
- APIs: 7 APIs the same as last time
- Frequency: 12 loops per minute (5 seconds per loop)
- Member platform call frequency: 84 times per minute
- Number of member platform calls in 4 hours: 20164
- Dump acquisition settings:
- export APPLICATION_JAVA_DUMP_OPTIONS='-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/var/log/app/ -XX:OnOutOfMemoryError="stop-java %p;" -XX:OnError="stop-java %p;" -XX:ErrorFile=/var/log/app/hs_err_%p.log -Xlog:gc*=info:file=/var/log/app/gc_%t.log:time,uptime,level,tags:filecount=5,filesize=10m'
- ECS memory limit settings:
- export APPLICATION_JAVA_TOOL_OPTIONS='-Xms512m -Xmx512m -XX:MaxMetaspaceSize=256m -XX:MetaspaceSize=256m -Xss1024k -XX:MaxDirectMemorySize=32m -XX:-UseCodeCacheFlushing -XX:InitialCodeCacheSize=128m -XX:ReservedCodeCacheSize=128m --illegal-access=deny'
Results
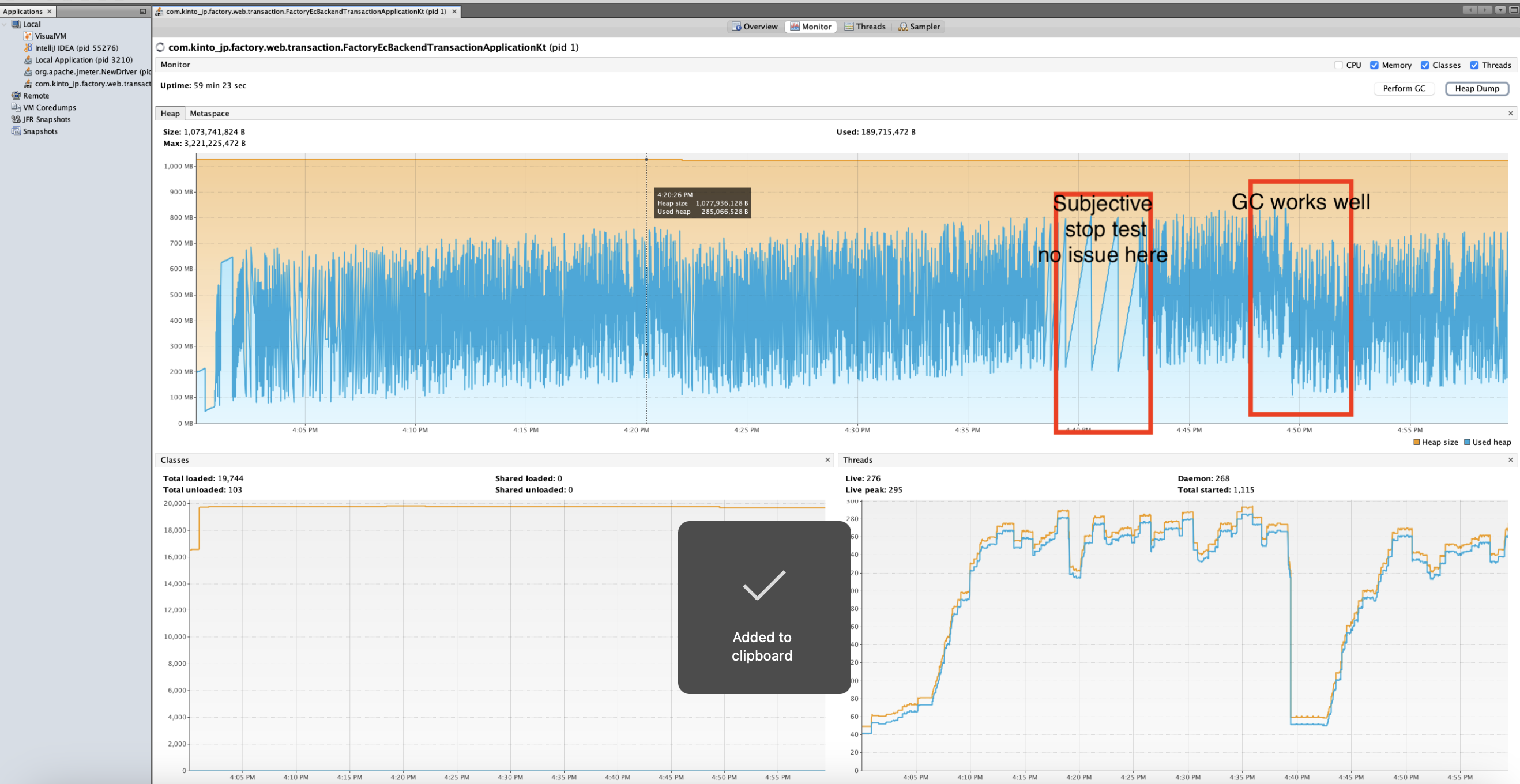
The memory leak was successfully reproduced and a dump was obtained.

If you open the dump file in IntelliJ IDEA, you can see detailed memory information.
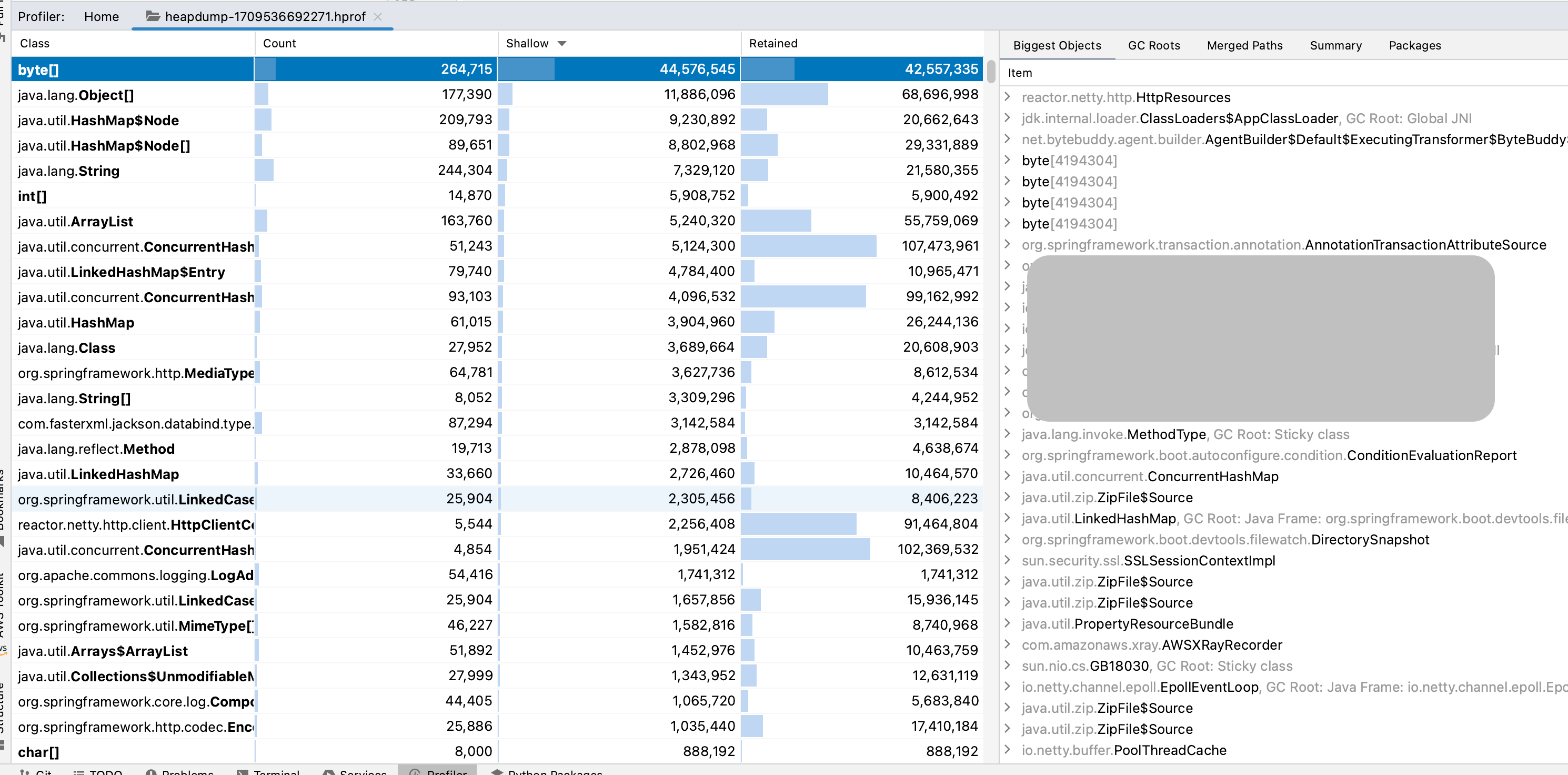
A detailed analysis of the dump file revealed that a significant number of new objects were being created with each external API request. Additionally, some utility classes were not being managed as singletons, contributing to the issue.
6. Heap dump analysis results
We found that 5,410 HashMap$Node were created in reactor.netty.http.HttpResources, which occupies 352,963,672 bytes (83.09%).
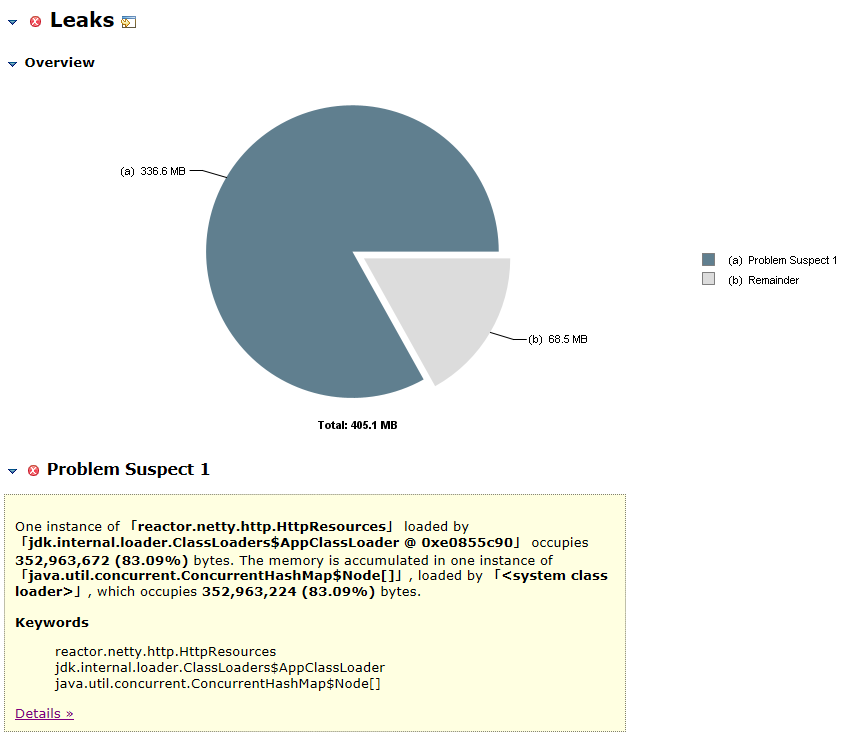
Identification of memory leak location
- There is a leak in
channelPools(ConcurrentHashMap)inreactor.netty.resources.PooledConnectionProvider, and we focused on the storing and retrieving logic. poolFactory(InstrumentedPool)Retrieving location- Create
holder(PoolKey)withchannelHashobtained fromremote(Supplier<?extends SocketAddress>)andconfig(HttpClientConfig) - Retrieve
poolFactory(InstrumentedPool)fromchannelPoolswithholder(PoolKey). Return an existing similar key if it exists, or create a new one if not.
- Create
The cause of the leak is that the same setting is not considered the same key: reactor.netty.resources.PooledConnectionProvider
public abstract class PooledConnectionProvider<T extends Connection> implements ConnectionProvider {
...
@Override
public final Mono<? extends Connection> acquire(
TransportConfig config,
ConnectionObserver connectionObserver,
@Nullable Supplier<? extends SocketAddress> remote,
@Nullable AddressResolverGroup<?> resolverGroup) {
...
return Mono.create(sink -> {
SocketAddress remoteAddress = Objects.requireNonNull(remote.get(), "Remote Address supplier returned null");
PoolKey holder = new PoolKey(remoteAddress, config.channelHash());
PoolFactory<T> poolFactory = poolFactory(remoteAddress);
InstrumentedPool<T> pool = MapUtils.computeIfAbsent(channelPools, holder, poolKey -> {
if (log.isDebugEnabled()) {
log.debug("Creating a new [{}] client pool [{}] for [{}]", name, poolFactory, remoteAddress);
}
InstrumentedPool<T> newPool = createPool(config, poolFactory, remoteAddress, resolverGroup);
...
return newPool;
});
- As the name suggests, channelPools are objects that hold channel information and are reused when similar requests come in.
- The PoolKey is created based on the hostname and HashCode in the connection settings, and the HashCode is further used.
channelHashRetrieving location
Hierarchy of reactor.netty.http.client.HttpClientConfig
Object
+ TransportConfig
+ ClientTransportConfig
+ HttpClientConfig
Lambda expression com.kinto_jp.factory.common.adapter.HttpSupport passed to PooledConnectionProvider
L5 the Lambda expression defined here is passed to PooledConnectionProvider as config#doOnChannelInit.
abstract class HttpSupport {
...
private fun httpClient(connTimeout: Int, readTimeout: Int) = HttpClient.create()
.proxyWithSystemProperties()
.doOnChannelInit { _, channel, _ ->
channel.config().connectTimeoutMillis = connTimeout
}
.responseTimeout(Duration.ofMillis(readTimeout.toLong()))
...
}
7. Behavior when retrieving channelPools (illustration)
Key match case (Normal)
- The information present in
channelPoolsis the key andInstrumentedPoolis reused.
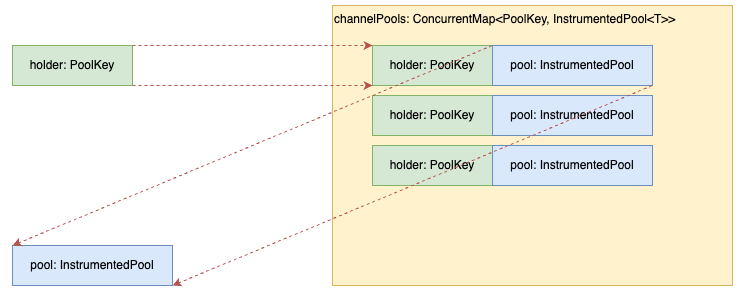
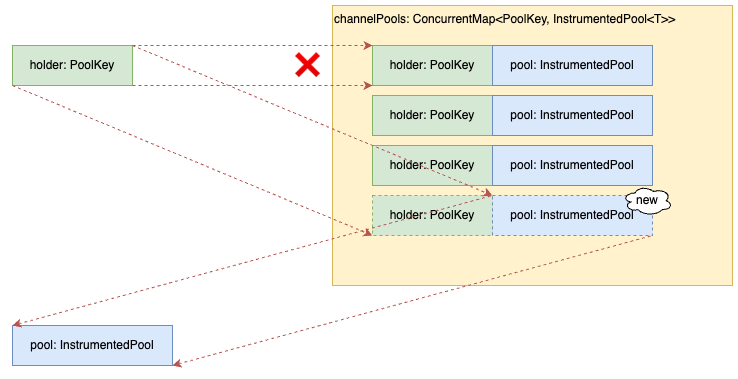
Key mismatch case (Normal)
- The information that does not exist in
channelPoolsis the key andInstrumentedPoolis newly created.
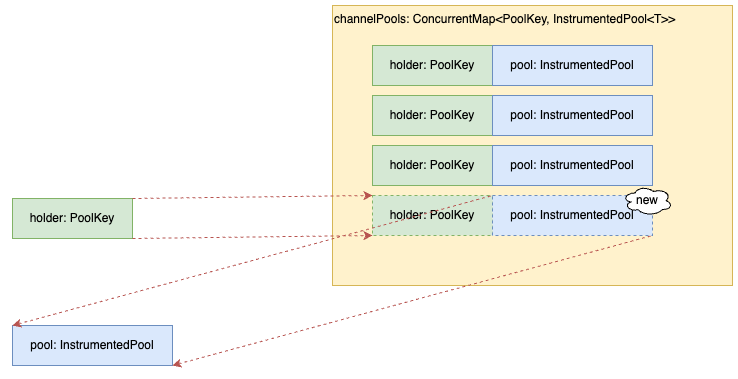
This case (Abnormal)
- The information present in
channelPoolsis the key, butInstrumentedPoolis not reused and is newly created.
Correction and verification of problems
Correction
- Rewrite the Lambda expression in question to a property call
Before correction
abstract class HttpSupport {
...
private fun httpClient(connTimeout: Int, readTimeout: Int) = HttpClient.create()
.proxyWithSystemProperties()
.doOnChannelInit { _, channel, _ ->
channel.config().connectTimeoutMillis = connTimeout
}
.responseTimeout(Duration.ofMillis(readTimeout.toLong()))
...
}
After correction
abstract class HttpSupport {
...
private fun httpClient(connTimeout: Int, readTimeout: Int) = HttpClient.create()
.proxyWithSystemProperties()
.option(ChannelOption.CONNECT_TIMEOUT_MILLIS, connTimeout)
.responseTimeout(Duration.ofMillis(readTimeout.toLong()))
...
}
Verification
Prerequisites
- Call
MembersHttpSupport#members(memberId: String)1000 times. - Check the number of objects stored in
PooledConnectionProvider#channelPools.
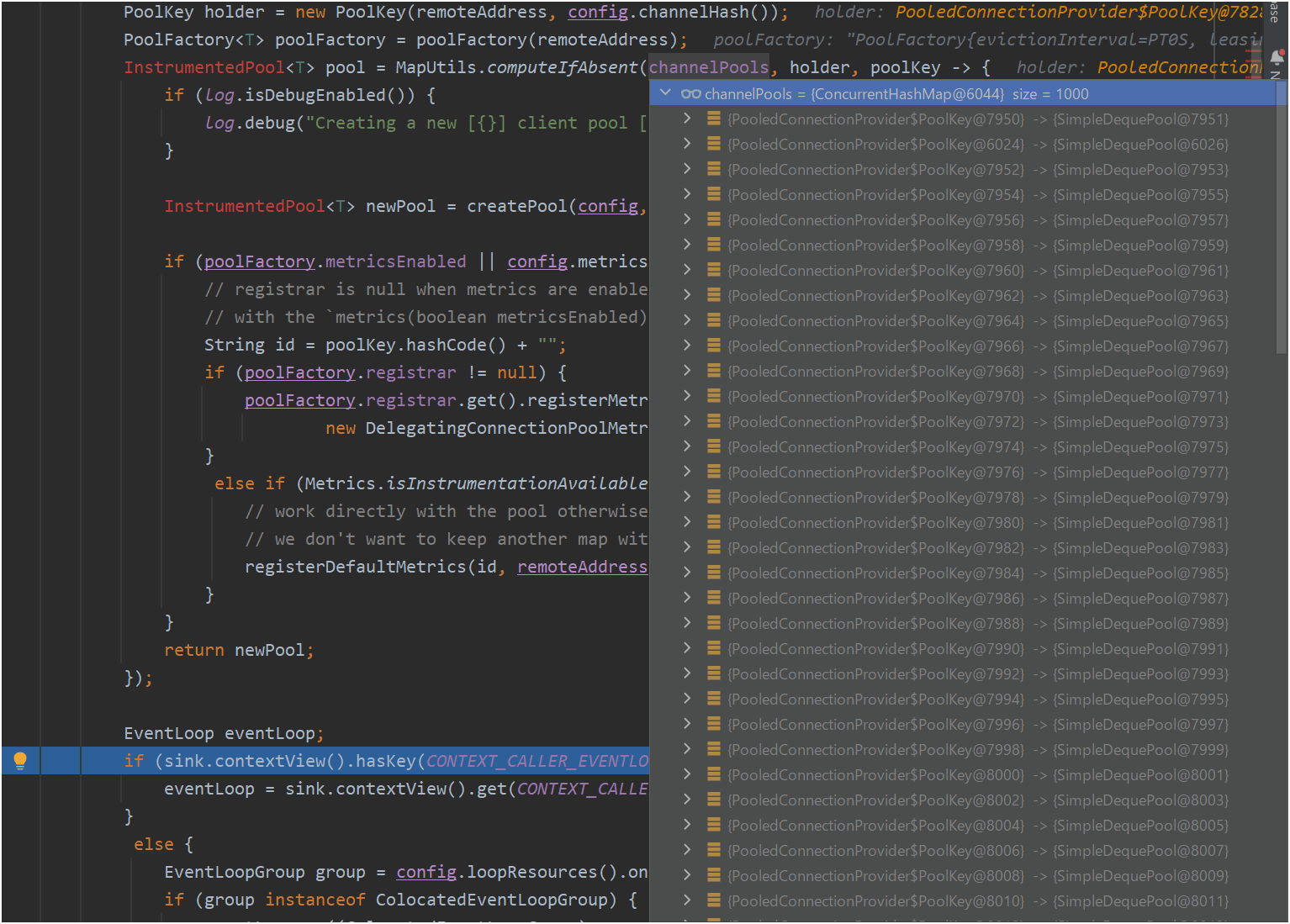
Results before correction
- When executed in the state before correction, we found that 1000 objects were stored in
PooledConnectionProvider#channelPools(cause of the leak).
Results after correction
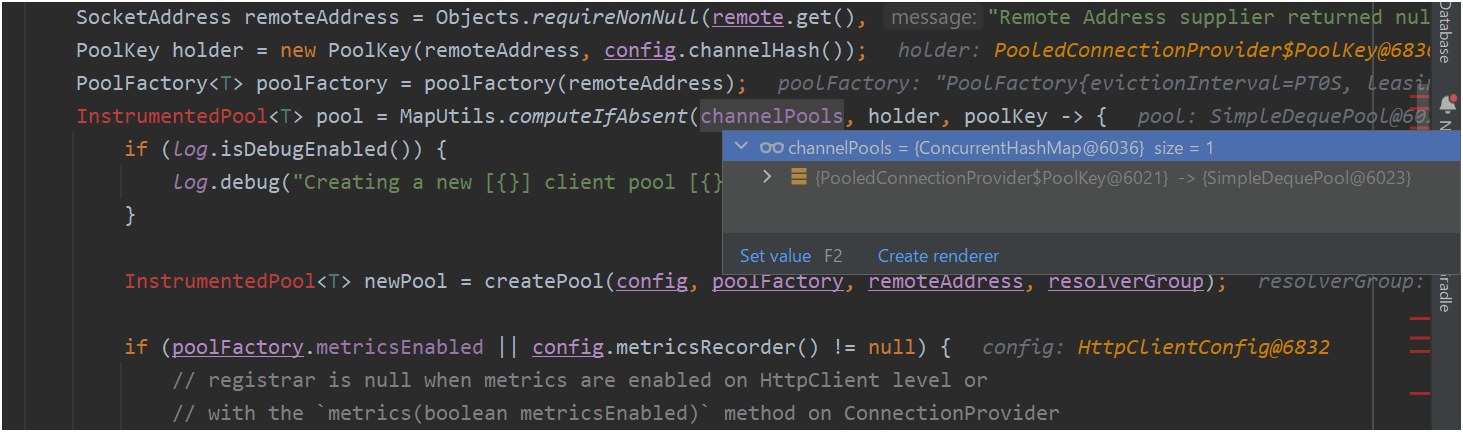
- When executed in the state after correction, we found that one object is stored in
PooledConnectionProvider#channelPools(leak resolved).
Summary
Through this investigation, we successfully identified the cause of the memory leak in KINTO FACTORY's web service and resolved the issue by implementing the necessary corrections. Specifically, the memory leak was caused by the creation of a large number of new objects during external API calls. This issue was resolved by replacing the Lambda expression with a property call, which reduced object creation.
Through this project, the following important lessons were learned:
-
Continuous monitoring: We recognized the importance of continuous monitoring through abnormal ECS service CPU utilization and frequent Full GCs. By continuously monitoring system performance, potential issues can be detected early and addressed promptly, preventing them from escalating.
-
Early problem identification and countermeasures: By suspecting memory leaks in the web service and repeatedly calling the APIs over an extended period to reproduce the issue, we identified that a large number of new objects were being created during external service requests. This allowed us to quickly identify the cause of the issue and implement appropriate corrections.
-
Importance of teamwork: When tackling complex issues, the key to success lies in effective collaboration and teamwork, with all members working together towards a common goal. This correction and verification were accomplished through the cooperation and effort of the entire development team. In particular, the collaboration at each stage—investigation, analysis, correction, and verification—was crucial to the success of the process.
During the investigative phase, there were many challenges. For example, reproducing memory leaks was difficult in the local environment, and it was necessary to re-validate in a verification environment similar to the actual environment. It also took a lot of time and effort to reproduce memory leaks and identify the cause by making prolonged calls to the external API.
However, by overcoming these challenges, we were ultimately able to resolve the problem, leading to a strong sense of accomplishment and success.
Through this article, we have shared practical approaches and valuable lessons learned to enhance system performance and maintain long-term stability. We hope this information will be helpful to developers facing similar challenges, providing them with insights to address such issues effectively.
That's all for now!






