Processing S3 events while taking care of data conflicts ~With Rust Lambda DynamoDB~

This article is part of day 6 of KINTO Technologies Advent Calendar 2024.
Introduction
Hello. I am Uehara (@penpen_77777), and I am part of the KINTO FACTORY Development Group. I joined in July 2024, and I was assigned to the backend development of KINTO FACTORY.
This time, using sample code, I will introduce the data conflicts that you should be cautious of when processing S3 events, and how to resolve them.
Intended Readers
- Those who are concerned with AWS S3 event notifications being duplicated or the order of notifications being changed.
- Those with basic knowledge of Rust, S3, DynamoDB, Lambda, and Terraform.
- Having this knowledge will make it easier to understand when reading the sample code.
S3 Event Overview
An S3 event[1] is an event that occurs when an operation such as uploading or deleting an object to S3 is triggered. By detecting S3 events using Lambda functions or SNS, various processes concerning S3 can be automated.
Issues with S3 Events
Something you should be cautious of when processing S3 events is that the event notifications could be duplicated or the order could be changed.
For example, let’s think about the process of creating an object after deleting an object for the same object key. In this case, first you will be notified of the object delete event, then you can expect to be notified of the create event (remove the same object => see the diagram of the expected S3 event reception order when created). However, there are times when the S3 event order isn’t secured, and the create event notification comes before the delete event notification (remove the same object => see the diagram of the order of reception of possible S3 events when created). As a result, the processing result by the event that deletes the object will be the latest, and the issue of data consistency not being guaranteed depending on the processing content occurs.
As a solution to this problem, there is a way to guarantee the order of events using the sequencer key included in S3 events[2]
One way to determine the sequence of events is to use the sequencer key. There is no guarantee that event notifications will be delivered in the order in which the event occurred. However, notifications and delete objects from events that create objects (PUT) include the sequencer. This can be used to determine the order of events for a particular object key.
When comparing the sequencer strings of two event notifications for the same object key, you can see that the event notification with the larger 16 hexadecimal value sequencer is the event that occurred later. When maintaining a separate database or index of Amazon S3 objects using event notifications, I recommend that you compare and save the sequencer value each time you process an event notification.
Please note the following:
The sequencer cannot be used to determine the order of events for multiple object keys.
The length of the sequencer may be different. To compare these values, first input 0 on the right of the shorter value, and then perform a lexicographic comparison.
To Summarize:
- The sequencer is a value included in an object's PUT or DELETE event, and can be used to determine the order of events.
- Lexicographically compare the sequencers. The larger the value, the later the event that occurred.
- If the lengths differ, compare after inputting 0 on the right side of the shorter value.
- It cannot be used to determine the order of S3 events between multiple objects.
- It is used to determine the order of PUT and DELETE events for the same object.
For example, if you want to implement the S3 event sequencer comparison in Rust, you can implement it as follows:
Define the fields and constructor of the structure S3Sequencer to express the nature of the S3 sequencer.
// 1. Define the structure S3Sequencer
use serde::{Deserialize, Serialize};
#[derive(Serialize, Deserialize, Debug, Clone)]
pub struct S3Sequencer {
bucket_name: String,
object_key: String,
sequencer: String,
}
// 2. Define the S3Sequencer constructor
// Take the bucket name, object key, and sequencer as argument
impl S3Sequencer {
pub fn new(bucket_name: &str, objcet_key: &str, sequencer: &str) -> Self {
Self {
bucket_name: bucket_name.to_owned(),
object_key: objcet_key.to_owned(),
sequencer: sequencer.to_owned(),
}
}
}
Next, to determine the order of events by comparing the size of the S3Sequencer, use the PartialOrd[3] and PartialEq trait[4] By implementing these two, you can compare the size of the sequencers using comparison operators such as ==, <, or > as shown below.
let seq1 = S3Sequencer::new("bucket1", "object1", "abc123");
let seq2 = S3Sequencer::new("bucket1", "object1", "abc124");
if seq1 < seq2 {
println!("seq1 is an older event than seq2");
} else if seq1 == seq2 {
println!("seq1 and seq2");
} else {
println!("seq1 is a newer event than seq2");
}
Implement the partial_cmp method required to implement the PartialOrd trait as shown below.
impl PartialOrd for S3Sequencer {
fn partial_cmp(&self, other: &Self) -> Option<std::cmp::Ordering> {
// Sequencers with different bucket names cannot be compared
if self.bucket_name != other.bucket_name {
return None;
}
// Sequencers with different object keys cannot be compared
if self.object_key != other.object_key {
return None;
}
// Compare by adding 0 to the end of the shorter one to match with the longer one
let max_len = std::cmp::max(self.sequencer.len(), other.sequencer.len());
let self_sequencer = self
.sequencer
.chars()
.chain(std::iter::repeat('0'))
.take(max_len);
let other_sequencer = other
.sequencer
.chars()
.chain(std::iter::repeat('0'))
.take(max_len);
Some(self_sequencer.cmp(other_sequencer))
}
Since there is no meaning in comparing sequencers with different bucket names and object keys, return None using early return if they are different. You can compare the sequencers once you confirm that the bucket names and object keys are the same, but the process will be in the following order.
- Compare the length of the sequencers, and store the longer one in
max_len - Add 0 to the end of the shorter sequencer to match
max_len - Compare the sequencers created in 2 in lexicographic order and return the size
The PartialEq trait is implemented as follows:
impl PartialEq for S3Sequencer {
fn eq(&self, other: &Self) -> bool {
self.partial_cmp(other)
.map_or(false, |o| o == std::cmp::Ordering::Equal)
}
}
Determine if the sequencer comparison results are equal using the partial_cmp method of the PartialOrd trait.
With the above implementations, it is now possible to compare sequencers for S3 events.
Example of S3 Event Processing Implementation Considering Data Consistency
Architecture Diagram
Now, I will introduce how to guarantee the order of S3 events using sequencers, along with sample code The sample code converts the image file uploaded to the S3 bucket to grayscale on Lambda and saves it to the S3 bucket for output. Below is an architecture diagram.

When an image file is uploaded to the image input bucket, the Lambda function is triggered through an S3 event. The launched Lambda function checks DynamoDB to confirm that it is not processing, then sets the processing flag and processes the image file. Once processing has finished, it clears the processing flag and waits for the next image file to be processed.
If the order of the create and delete event notifications is reversed, problems such as accidently deleting images that should exist could occur. For example, let’s assume that the process is implemented as follows.
- Image file A is deleted from the input bucket
- Image file A is re-uploaded to the input bucket
- Lambda receives a delete event (corresponding to 1) and deletes image file A from the output bucket
- Lambda receives a create event (corresponding to 2), processes image file A, converts it to grayscale, and saves it in the output bucket
However, there is a possibility of the notification order for 3 and 4 being reversed in S3 events, so the following flow may occur.
- Image file A is deleted from the input bucket
- Image file A is re-uploaded to the input bucket
- Lambda receives a create event (corresponding to 2), processes image file A, converts it to grayscale, and saves it in the output bucket
- Lambda receives a delete event (corresponding to 1) and deletes image file A from the output bucket
In this case, the problem occurs that even though image file A exists in the input bucket, the grayscaled image file A' does not exist in the output bucket.
In order to prevent problems such as this, use the S3 event sequencer to implement exclusive processing. Additionally, it is also necessary to implement exclusive processing to manage image processing status by DynamoDB. Use DynamoDB conditional write to set an in-progress flag in order to prevent multiple Lambda functions from processing the same image file at the same time.
The sample code is published on GITHUB. Take a look using the link below. (You will need to build an AWS infrastructure to run it, but it has been made easy to try using the terraform code.)
Implementing Sample Code with Rust
This time, I will implement a Lambda function using Rust. It is convenient to use cargo-lambda to implement Lambda functions.
I will omit the details of how to use cargo-lambda.
Creating an Entry Point
When you run the initialization command on cargo-lambda, main.rs is automatically generated as shown below.
cargo lambda init
use lambda_runtime::{
run, service_fn,
tracing::{self},
Error,
};
mod handler;
mod image_task;
mod lock;
mod s3_sequencer;
#[tokio::main]
async fn main() -> Result<(), Error> {
tracing::init_default_subscriber();
run(service_fn(handler::function_handler)).await
}
Since handler:function_handler is specified as the entry point for the Lambda function, I will write the implementation in handler.rs
The function_handler is implemented as follows.
use crate::image_task::ImageTask;
use aws_lambda_events::event::s3::S3Event;
use lambda_runtime::{tracing::info, Error, LambdaEvent};
pub async fn function_handler(event: LambdaEvent<S3Event>) -> Result<(), Error> {
// Convert S3 events to ImageTask
let tasks: Vec<_> = event
.payload
.records
.into_iter()
.map(ImageTask::try_from)
.collect::<Result<Vec<_>, _>>()?;
// Use futures::future::join_all to create the task to be executed
let execute_tasks = tasks.iter().map(|task| task.execute());
// Use join_all to execute or wait all tasks
// Store the execution results in ret
let ret = futures::future::join_all(execute_tasks).await;
// Output the execution results to log
for (t, r) in tasks.iter().zip(&ret) {
info!("object_key: {}, Result: {:?}", t.object_key, r);
}
// Return error is there is an error
if ret.iter().any(|r| r.is_err()) {
return Err("Some tasks failed".into());
}
// Successful termination
Ok(())
}
- Convert the S3 event vector to an ImageTask structure vector. Since the conversion method implements the TryFrom trait, you just have to call the try_form method.
- Create an image processing task based on the ImageTask structure vector.
- Use the tokio crate join_all function to execute all tasks in parallel.
- Output the results returned by join_all in 3 to the log.
- If there is an error, return the error and terminate the Lambda function abnormally.
- If there are no errors it will successfully terminate.
Image Processing Implementation
The ImageTask structure used in 1 is defined as below and holds the information necessary to execute Lambda.
#[derive(Serialize, Deserialize, Debug, Clone)]
#[serde(tag = "type")]
pub enum TaskType {
Grayscale,
Delete,
}
#[derive(Serialize, Deserialize, Debug, Clone)]
pub struct ImageTask {
pub bucket_name: String,
#[serde(rename = "id")]
pub object_key: String,
pub sequencer: S3Sequencer,
pub task_type: TaskType,
pub processing: bool,
}
| Field name | Description |
|---|---|
| bucket_name | S3 bucket name |
| object_key | Object key |
| sequencer | S3 event sequencer |
| task_type | Enumeration indicating the type of task (Grayscale, Delete) |
| processing | Processing flag |
Implement specific image processing within the execute method of the ImageTask structure.
impl ImageTask {
pub async fn execute(&self) -> Result<(), Error> {
// 1. Acquire lock
let lock = S3Lock::new(&self).await?;
// 2. Process according to the task type
match self.task_type {
TaskType::Grayscale => {
// Convert image to grayscale and save in output bucket
let body = lock.read_input_object().await?;
let format = image::ImageFormat::from_path(&self.object_key)?;
let img = image::load_from_memory_with_format(&body, format)?;
let img = img.grayscale();
let mut buf = Vec::new();
img.write_to(&mut Cursor::new(&mut buf), format)?;
lock.write_output_object(buf).await?;
}
// Delete image from output bucket
TaskType::Delete => lock.delete_output_object().await?,
}
// 3. Release lock
lock.free().await?;
Ok(())
}
}
- Apply exclusive processing to prevent S3 object data inconsistencies
- Process according to the task type
- If a file was added to a previous bucket, convert the image to grayscale and save it in the output bucket
- If a file was deleted, delete the file from the output bucket
- Release lock when processing has finished
Implement Lock Processing
- Define the S3Lock structure to implement lock processing.
pub struct S3Lock {
dynamodb_client: aws_sdk_dynamodb::Client,
table_name: String,
s3_client: aws_sdk_s3::Client,
input_bucket_name: String,
input_object_key: String,
output_bucket_name: String,
output_object_key: String,
}
The specific lock acquisition process is implemented in the constructor. The code is a bit long, but roughly speaking, it is as follows.
- If writing to DynamoDB is successful, the lock is considered to have been acquired.
- If writing fails, try again every 2 seconds.
- If the lock cannot be acquired within 30 seconds, a timeout occurs.
The lock processing sequence diagram is shown below.
The code in the constructor is as follows:
impl S3Lock {
pub async fn new(task: &ImageTask) -> Result<Self, Error> {
let table_name = std::env::var("DYNAMODB_TABLE_NAME").unwrap();
let output_bucket_name = std::env::var("OUTPUT_BUCKET_NAME").unwrap();
let require_lock_timeout = Duration::from_secs(
std::env::var("REQUIRE_LOCK_TIMEOUT")
.unwrap_or_else(|_| "30".to_string())
.parse::<u64>()
.unwrap(),
);
let interval_retry_time = Duration::from_secs(
std::env::var("RETRY_INTERVAL")
.unwrap_or_else(|_| "2".to_string())
.parse::<u64>()
.unwrap(),
);
let config = aws_config::load_defaults(aws_config::BehaviorVersion::v2024_03_28()).await;
let s3_client = aws_sdk_s3::Client::new(&config);
let dynamodb_client = aws_sdk_dynamodb::Client::new(&config);
// Acquire lock
Measure execution time
let start = Instant::now();
loop {
// It will time out if the lock cannot be acquired for more than 30 seconds.
if start.elapsed() > require_lock_timeout {
return Err("Failed to acquire lock, timeout".into());
}
Acquire sequencer from DynamoDB with strong read consistency
let item = dynamodb_client
.get_item()
.table_name(table_name.clone())
.key("id", AttributeValue::S(task.object_key.clone()))
.consistent_read(true)
.send()
.await?;
Compare sequencer if acquired item exists
if let Some(item) = item.item {
let item: ImageTask = from_item(item)?;
if task.sequencer <= item.sequencer {
If the sequencer itself is old, there is no need to process it, so skip it
return Err("Old sequencer".into());
}
If the sequencer itself is new, wait until other processing has finished
if item.processing {
warn!(
"Waiting for other process to finish task, retrying, remaining time: {:?}",
require_lock_timeout - start.elapsed()
);
thread::sleep(interval_retry_time);
continue;
}
}
// Acquire lock with conditional write to DynamoDB
// If the record exists at that time, only write if the processing flag is false
let resp = dynamodb_client
.put_item()
.table_name(table_name.clone())
.set_item(Some(to_item(&task).unwrap()))
.condition_expression("attribute_not_exists(id) OR processing = :false")
.expression_attribute_values(":false", AttributeValue::Bool(false))
.send()
.await;
Once acquired, exit the loop and continue processing
If it could not be acquired, continue trying until the lock can be acquired.
match resp {
Ok(_) => break,
Err(SdkError::ServiceError(e)) => match e.err() {
PutItemError::ConditionalCheckFailedException(_) => {
warn!(
"Failed to acquire lock, retrying, remaining time: {:?}",
require_lock_timeout - start.elapsed()
);
thread::sleep(Duration::from_secs(2));
continue;
}
_ => return Err(format!("{:?}", e).into()),
},
Err(e) => return Err(e.into()),
}
}
return Ok(Self {
dynamodb_client,
output_bucket_name,
s3_client,
table_name,
input_bucket_name: task.bucket_name.clone(),
input_object_key: task.object_key.clone(),
output_object_key: task.object_key.clone(),
});
}
}
The process to release the lock is implemented as shown below, and the lock is released by updating the processing flag to false.
impl S3Lock {
pub async fn free(self) -> Result<(), Error> {
// Release DynamoDB lock
// Only update the processing flag
self.dynamodb_client
.update_item()
.table_name(self.table_name)
.key("id", AttributeValue::S(self.input_object_key))
.update_expression("SET processing = :false")
.expression_attribute_values(":false", AttributeValue::Bool(false))
.send()
.await?;
Ok(())
}
}
Since I want to force a lock when touching an S3 object, I have created a method for manipulating S3 objects in S3Lock[5]
impl S3Lock {
pub async fn read_input_object(&self) -> Result<Vec<u8>, Error> {
// Acquire S3 object
let object = self
.s3_client
.get_object()
.bucket(&self.input_bucket_name)
.key(&self.input_object_key)
.send()
.await?;
let body = object.body.collect().await?.to_vec();
Ok(body)
}
pub async fn write_output_object(&self, buf: Vec<u8>) -> Result<(), Error> {
// Save S3 object
let byte_stream = ByteStream::from(buf);
self.s3_client
.put_object()
.bucket(&self.output_bucket_name)
.key(&self.output_object_key)
.body(byte_stream)
.send()
.await?;
Ok(())
}
pub async fn delete_output_object(&self) -> Result<(), Error> {
// Delete S3 object
self.s3_client
.delete_object()
.bucket(&self.output_bucket_name)
.key(&self.output_object_key)
.send()
.await?;
Ok(())
}
}
Trying it Out
Let’s try using the sample code.
I need to prepare an image that I want to convert to grayscale, so this time I will use Hyogo Prefectural Park Awaji Hanasajiki[6]. I took the photo. I will use the image from https://awajihanasajiki.jp/about/.

Infrastructure
First, use terraform apply to build the AWS infrastructure. Then, clone the GitHub repository and implement the following command.
cd terraform
# Modify variables.tf and provider.tf appropriately.
terraform init
terraform apply
Upload the Image File to the S3 Bucket
If infrastructure is completed, upload the image file to the input S3 bucket.
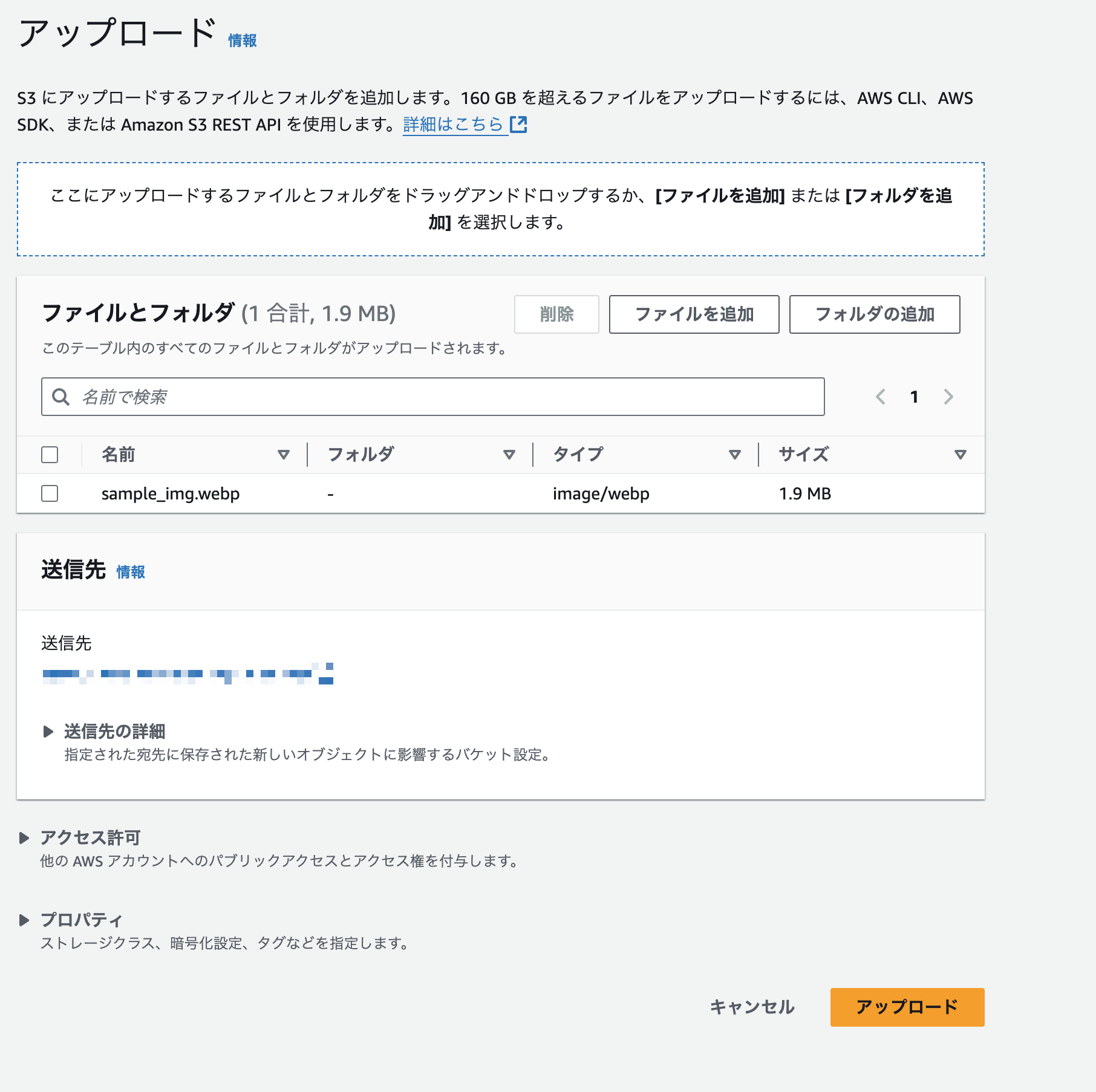
The Lambda function process begins when the upload finishes, and the item is added to the DynamoDB table. The image file is saved in the output S3 bucket when the process finishes, and the processing flag of the DynamoDB item is set to false.

You can see the image added to the output S3 bucket and converted to grayscale.

Delete the Image File from the S3 Bucket
When an object is deleted from the input bucket, it is also deleted from the output bucket. 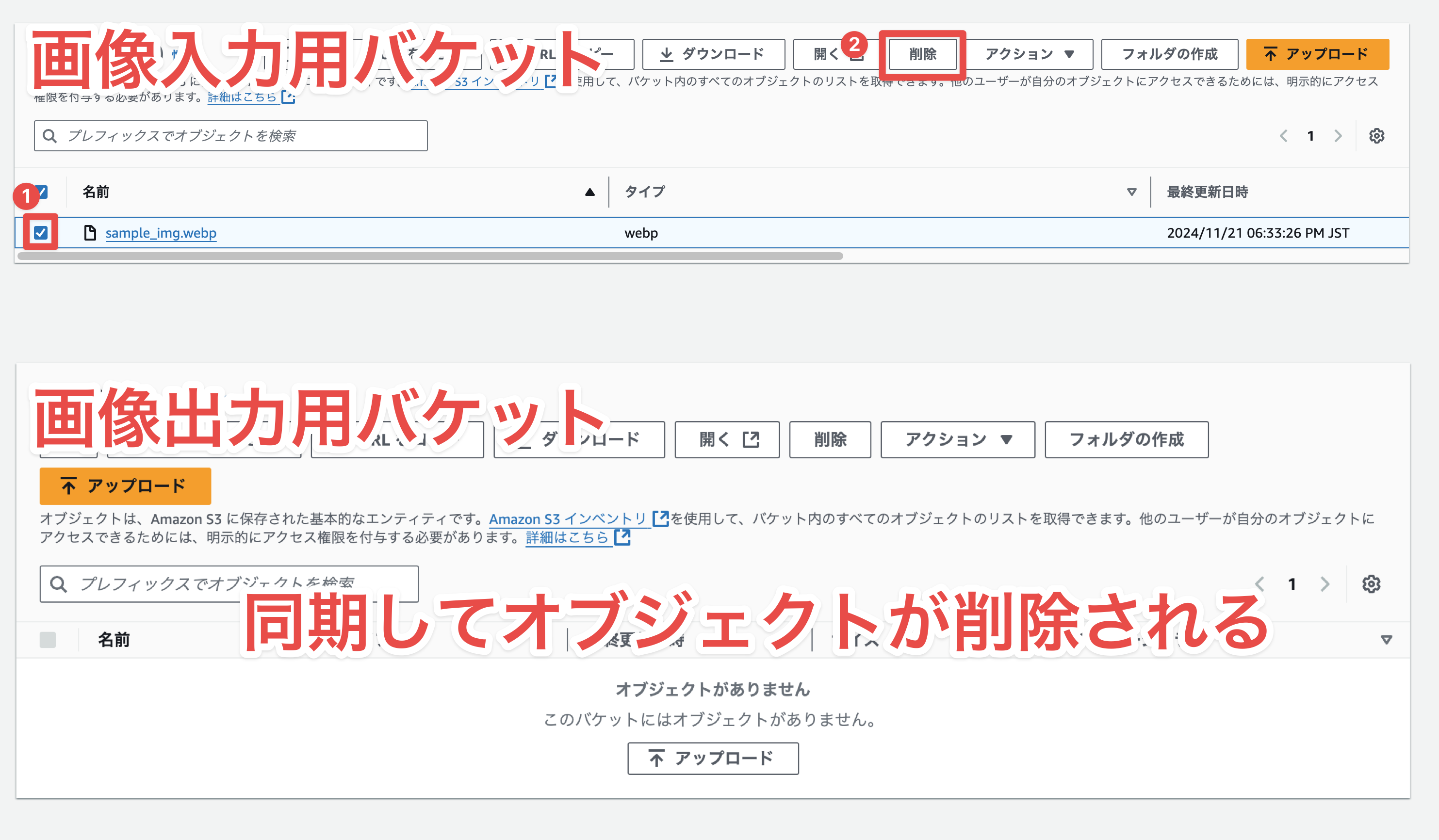
Confirm that Exclusive Processing is Working
When the processing flag of an item added to DynamoDB is set to true, processing will wait even if an S3 event that should be processed arrives. To confirm this behavior, let's intentionally set the DynamoDB processing flag to true and upload a file with the same name. 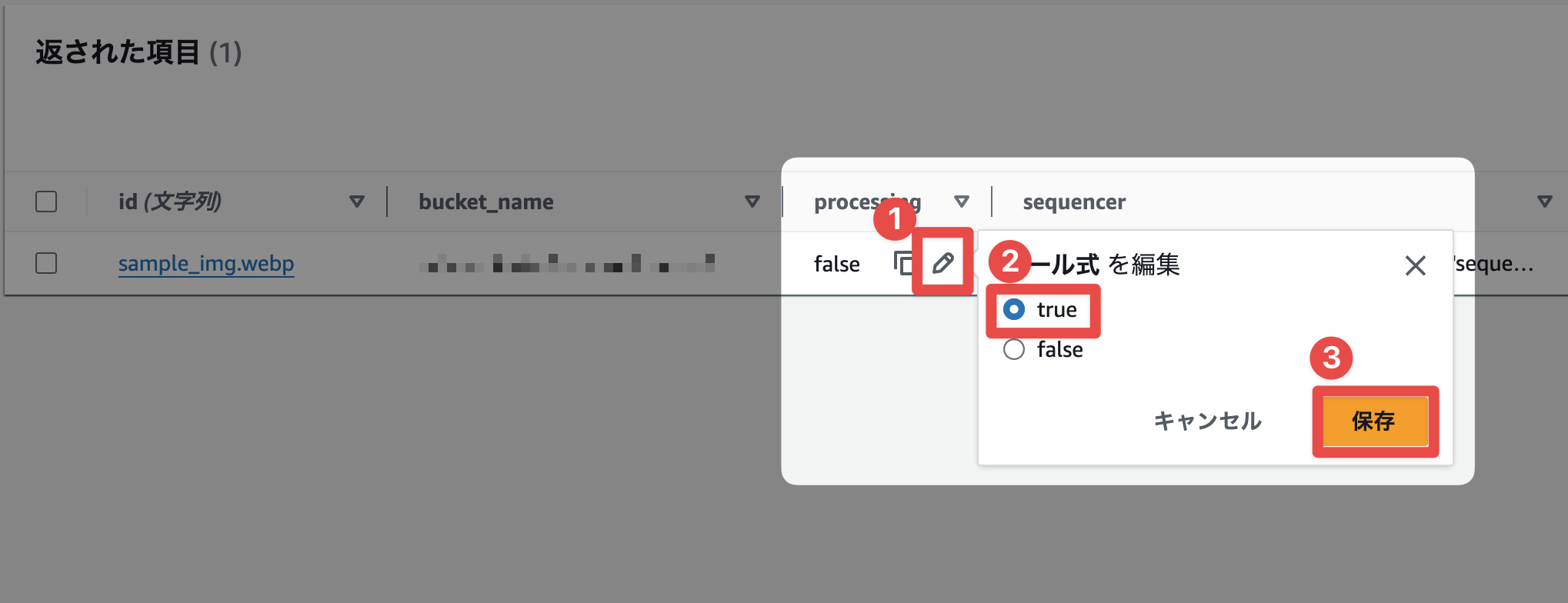
If you look at CloudWatch Logs, you can see that it waits for other processes to complete without processing newly generated S3 events. The log message will indicate that Lambda is waiting.
Setting the DynamoDB processing flag back to false will restart processing. When the DynamoDB item's processing flag is set back to false, the log will indicate that processing is completed.
Thanks to exclusive processing, the order of processing is guaranteed even if delete and upload events occur at approximately the same time.
Conclusion
This time, I introduced sample code for image processing that uses a sequencer to guarantee the order of S3 events. To guarantee the order of S3 events, you need to utilize a sequencer to compare the order of events. I implemented the sample code in Rust as my own hobby, but it should be possible to implement something similar in other languages. Please feel free to use this as a reference.
AWS document regarding S3 event notifications https://docs.aws.amazon.com/ja_jp/AmazonS3/latest/userguide/EventNotifications.html ↩︎
document regarding S3 event structure. ↩︎
Mathematically speaking, it can represent a partially ordered set. There is also a full ordered set that implements the ‘Ord’ trait. It is interesting that traits are intentionally divided to implement comparison methods. I will implement https://doc.rust-lang.org/std/cmp/trait.PartialOrd.html https://ja.wikipedia.org/wiki/順序集合#半順序集合 ↩︎
PartialEq trait definition https://doc.rust-lang.org/std/cmp/trait.PartialEq.html ↩︎
I feel that reusability will be lower if I create it in S3Lock, but for simplicity I will define it in the same structure. Though there seems to be a better way... ↩︎
a beautiful flower garden on Awaji Island https://awajihanasajiki.jp/about/ ↩︎
関連記事 | Related Posts


We are hiring!
【クラウドエンジニア】Cloud Infrastructure G/東京・大阪・福岡
KINTO Tech BlogWantedlyストーリーCloud InfrastructureグループについてAWSを主としたクラウドインフラの設計、構築、運用を主に担当しています。
【SRE】DBRE G/東京・大阪・名古屋・福岡
DBREグループについてKINTO テクノロジーズにおける DBRE は横断組織です。自分たちのアウトプットがビジネスに反映されることによって価値提供されます。


