UUIDとは何でしょう? どのバージョンを使用すればよいでしょうか?

UUIDとは何でしょう? どのバージョンを使用すればよいでしょうか?
最近、データベース内のキーが重複していたためにサービスがダウンするというインシデントに対応しなければなりませんでした。私のチームと私は、これらがUUIDだったため頭を悩ませていました。ご存知のとおり、これらは「一意」の識別子です。どうして重複が生じるのでしょうか?結局、この問題は、同じUUIDが2回生成されたことではなく、サービスが同じイベントを2回追加しようとしたことが原因であることがわかりました。この出来事がきっかけで、UUIDについて考えるようになりました。UUIDとは何でしょうか?UUIDはどのように生成されるのでしょうか?UUIDの使用例は?そして最も重要なのは、どのバージョンを使用すべきかということです。
UUIDとは何でしょう?
UUIDは通常、リソースのIDを提供するために使用されます。UUIDは「Universally Unique IDentifier(汎用一意識別子)」の略称です。その名称を見ると、生成される値の一意性が強く期待されているようです。これには十分な理由があります。例えば、数千兆のUUIDなど、膨大な量のUUIDを生成したとしても、それらが一意である確率は99.999%です。これらの確率の背後にある数学に興味がある方は、この非常に優れた記事を読むことをお勧めします。
UUIDは「保証された一意性」ではなく「実質的な一意性」です。衝突の可能性は非常に小さいため、ほとんどのアプリケーションでは、UUIDの衝突が発生する可能性よりも、ハードウェアが故障するか、宇宙線が原因でビットがマシンのメモリ内で反転する可能性の方が高くなります。
ただし、これらの確率は適切な乱数発生を前提としていることに注意してください。乱数発生器に欠陥があったり予測可能だったりすると、衝突の実際の確率ははるかに高くなる可能性があります。この記事の後半でもう少し詳しく説明します。
ソフトウェアに携わっている方であれば、UUIDがどのようなものかすでにご存知かと思いますが、念のため:UUIDは128ビット幅で、ハイフンで区切られた5つの部分で構成されます。それらは通常、16進数で表され、次のようになります。
- ccba8c00-cbed-11ef-ad79-1da827afd7cd
- 74febad9-d652-4f6b-901a-0246562e13a8
- 1efcbedf-13bf-61e0-8fb8-fe3899c4f6f1
- 01943a0e-dd73-72fd-81ad-0af7ce19104b
でも待ってください!これらのUUIDは実際には異なるバージョンのUUIDを使用して生成されました。上記のUUIDのリストにおいて、それらはバージョン1、バージョン4、バージョン6、バージョン7の順で使用して生成されます。UUIDにおいてバージョンがどこに示されているかを調べてみてください。
ヒント:中間あたりにあります。
UUIDのバージョンは、UUIDの真ん中にある、UUIDの3番目の部分の最初の文字に示されていることにお気づきだと思います。4番目の部分の最初の文字にもバリアントが示されています。バージョンはUUIDがどのように生成されたかを示すために使用され、バリアントはそのUUIDのレイアウトを示すために使用されますが、おそらくバリアントについて心配する必要はなく、バージョンが最も重要です。
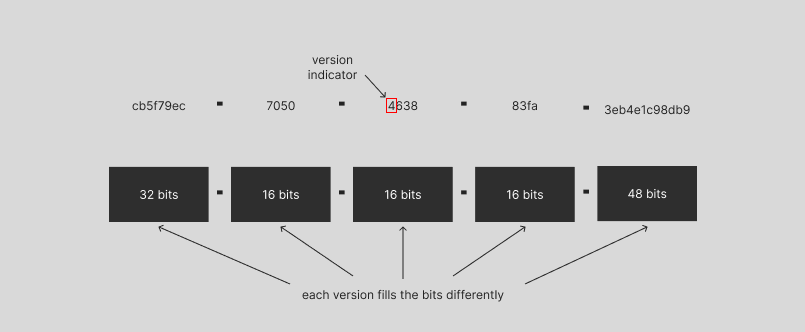
先ほど説明したように、UUID には複数のバージョンがあります。先ほど発見したバージョンインジケーターの他に、各バージョンの違いは何でしょうか?それらはすべて、一意のUUIDを同様に生成できるでしょうか?また、あるバージョンを他のバージョンよりも優先して使用する理由は何でしょうか?もちろん、最新かつ最良のUUIDバージョンを使用すべきですよね?とても良い質問です!UUIDの異なるバージョンを見てみましょう。
バージョン1とバージョン6
バージョン1および6のUUIDは、UUIDを生成したコンピューターの現在の時刻とMACアドレスを使用して生成されます。タイムスタンプ部分は UUIDの先頭にあり、コンピューターのCPUに応じてランダムビットまたは増分カウンターを含む場合があります。MACアドレス部分は最後にあるため、同じコンピューターを使用していれば、その部分が変化することはありません。興味深いことに、MACアドレスはUUIDから取得できるため、UUIDバージョン1または6を生成するとプライバシーのリスクが生じます。しかし、これはこのバージョンのUUIDの利点の1つでもあり、2台のコンピュータが同じUUIDを生成することはありません。そのため、これらのバージョンは、グローバルな一意性が求められる分散システムで役立ちます。
バージョン1と6の違いは、UUIDでタイムスタンプの各部分が使用される順序です。バージョン1とは異なり、バージョン6のUUIDは時系列で並べ替えることができるため、データベース内での順序付けに役立ちます。

バージョン1および6では予測可能な要素(生成時刻とMACアドレス)を使用するため、UUIDを推測可能であり、UUIDを秘密にしておく必要がある用途には適していません。
バージョン2
バージョン2は、タイムスタンプと、UUIDを生成するコンピューターのMACアドレスを使用する点でバージョン1と似ています。ただし、バージョン2では、POSIX UIDまたはGIDという追加の識別子データも使用します。これにより、バージョン2はバージョン1および6よりもランダム性が低くなり、タイムスタンプの使用が少なくなります。その結果、特定の時点で生成できるUUID v2の数は限られており、ほとんどの用途においてあまり望ましくありません。これが使用されることは稀であり、通常、ほとんどのライブラリでサポートされていません。これは、UUID仕様にも記載されていません。
バージョン3と5
バージョン3と5は他のUUIDとはまったく異なります。他のバージョンはランダム性を目指していますが、バージョン3とバージョン5は決定論的であることを目指しています。これはどういう意味でしょう?いずれもハッシュアルゴリズムを使用してUUIDを生成するため、UUIDを再現可能にします。UUIDを生成するためにランダム性やタイムスタンプは使用されず、与えられた入力は常に同じUUIDを生成する必要があります。バージョン3ではMD5ハッシュアルゴリズムを使用し、バージョン5ではSHA1を使用します。
これらのバージョンは、同じ入力データから同じUUIDを繰り返し生成する必要がある場合に特に便利です。例えば、ユーザーの電子メールアドレスに基づいてユーザーのUUIDを作成するとします。異なるサーバーや時間にわたっても、同じ電子メールで常に同じUUIDが生成されるようにしたいとします。もう1つの良い例としては、重複を避けるために何らかのデータに基づいて主キーを生成する必要があるが、データ自体を主キーとして使用するのは良い選択肢ではない場合が挙げられます。
バージョン3とバージョン5のいずれかを選択する場合、SHA1の方が少し安全ですが、計算負荷も大きくなることに留意してください。それがユースケースで懸念事項である場合は、バージョン3を使用してコンピューティングリソースの使用量を削減することをお勧めしますが、ほとんどの場合、より安全なバージョン5を選択すべきです。また、SHA1よりもMD5と衝突が発生する可能性が高くなりますが、その確率は依然として非常に低いです。
バージョン4
バージョン4は、UUIDの最も広く使用されているバージョンです。バージョン4はランダムビットを使用してUUIDを生成するため、UUIDは一意で予測不可能になります。これは乱数発生に大きく依存していますが、すべての乱数発生器が実際に真の乱数を生成できるわけではありません。衝撃的ですよね。
多くのプログラミング言語では、疑似乱数発生器(PRNG)と呼ばれるものを使用しています。ほとんどの場合はこれで問題ありませんが、UUID生成の場合は、システムが暗号論的にセキュアな疑似乱数生成器(CSPRNG)を使用していることを確認する必要があります。
なぜかって?通常のPRNGは、出力を十分に分析すれば予測可能になる場合があります。一方、CSPRNGは、攻撃者が以前に生成されたすべての値を知っている場合でも、その出力を予測することが事実上不可能になるように特別に設計されています。最近のUUIDライブラリのほとんどがデフォルトでCSPRNGを使用していますが、念のため確認してみる価値はあります。
他のバージョンと同様に、予測可能な部分はバージョンインジケーターのみなので、その部分を推測して友達を感心させてみましょう。
これらは、大量のUUIDを生成する必要があり、後で並べ替えたり再現したりする必要がない場合など、ほとんどの用途に最適です。これらは、データベースにおいてキーとしてよく使用されます。
バージョン7
バージョン7は、バージョン4を時系列順に並べ替えられるバージョンとして設計されています。バージョン4と同様に、バージョン7はランダムビットを使用しますが、タイムスタンプを含むため、UUIDはソート(並び替え)可能かつ一意になります。一意性を保ちつつ、作成時間によって並べ替えたい場合に、バージョン7はバージョン4の優れた代替手段となります。
バージョン7でもタイムスタンプにエポックタイムを使用しますが、バージョン1と6では1582年10月15日以降、100ナノ秒間隔の数値を使用しています。これにより、バージョン7での作業が少し簡単になっています。
バージョン8
バージョン8はカスタムなので少し特殊です。ベンダーは希望どおりに実装できます。バージョン8を自分で実装することもできますが、UUIDの3番目の部分にあるUUIDバージョンを尊重する必要があります。おそらくそれを使用する必要はないでしょう。
では、何を使用すればよいでしょうか?
ほとんどの人にとって、バージョン4になります。バージョン4は、一意性の保証が最も大きく、比較的安全です(乱数発生器が予測不可能な限り)。UUIDを作成時間によって並べ替えられるようにしたい場合は、MACアドレスの漏洩によるプライバシーの懸念がない限り、バージョン7またはバージョン6を使用できます。場合によってはバージョン3と5が便利ですが、ほとんどのアプリケーションではそれらの使用は制限されます。
データベースキー?
データベースキーにUUIDを使用することに関する議論を見たことがあるかもしれませんが、データベースキーにUUIDを使用することを検討している場合は、覚えておくべき事実がいくつかあります。
- UUIDは大きく、128ビットを占めます。大量のデータを保存する予定がない場合は、UUID用に追加で占有されるスペースが大きくなる可能性があります。あるいは、32ビットの自動増分整数(オートインクリメント整数)では約2147483647行が得られますが、それでも足りない場合は、64ビットのBIGINTで最大18446744073709551615になります。ほとんどのユースケースの場合、これで十分でしょう。
- 一部のデータベースでは、キーにUUIDを使用すると、挿入性能が低下する可能性があります。挿入性能が懸念される場合は、自動増分整数の使用を検討するか、少なくともUUIDを使用してデータベースの性能をテストすることをお勧めします。
- UUIDは、データの移行を容易にします。自動増分整数を使用すると衝突が発生しますが、UUIDではその問題は発生しないでしょう。
- 一部のUUIDはソート(並び替え)可能ですが、読みやすくはありません。2つのUUIDに着目すると、どちらが先に来たのかを知るのは非常に困難です。これは非常に些細なことですが、留意すべきです。
ほとんどのデータベースには、UUIDを生成するための何らかのモジュールまたは関数があるため、データベースのドキュメントをチェックしてUUIDの生成方法を確認できます。UUIDを使用する際に性能上の問題や考慮すべき特別な事項がある場合は、おそらくそこで判明するでしょう。
結論
この記事を読む前よりも、UUIDとそれらのさまざまなバージョンについて少し理解が深まったと思います。
バージョン4 UUIDは、ほとんどのアプリケーションで依然として定番です。バージョン4 UUIDは、強力な一意性保証と予測不可能性を備えており、おそらくこれがUUIDに求められるものです。バージョン4 UUIDは主に、データベースキー、分散システム、および調整なしでグローバルに一意な識別子が必要なシナリオで使用されます。
バージョン7は、ランダム性とソート(並び替え)可能性とのバランスが取れているため、時系列的ソートが望ましい場合に適した代替手段です。
バージョン1と6は、グローバルな一意性が必要な分散システムでは役立ちますが、MACアドレスが含まれるためプライバシーに関する懸念を伴います。
バージョン3と5は、特定の入力からUUIDを再現する必要がある場合に便利ですが、MD5はSHA1ほど安全ではないことに注意してください。
自分のシステムでUUIDを使用する予定の場合は、UUIDバージョンを選択する際に次の要素を考慮してください。
- 一意性に関する自身の要件
- 時系列的ソートが必要か否か
- プライバシーに関する懸念 (特に MACアドレスを含むバージョンを使用する場合)
- ストレージ スペースの制約 (あなたのキーに128ビットは必要ないかもしれません)
UUIDの衝突は理論的には起こり得ますが、暗号的に安全な乱数発生器を使用した適切な実装をしている限り、その可能性は非常に低いため、システム設計において大きな懸念事項にはならないはずです。UUIDの衝突が発生した場合(天文学的な確率を覆した場合!)、実際のUUID生成衝突ではなく、重複したイベント処理などのアプリケーションロジック問題が原因である可能性が高くなります。そのような場合は、UUID生成自体に疑問を抱くよりも、アプリケーションの一意性制約の処理を調べることに重点を置いてください。
関連記事 | Related Posts



We are hiring!
【UI/UXデザイナー】クリエイティブ室/東京・大阪・福岡
クリエイティブGについてKINTOやトヨタが抱えている課題やサービスの状況に応じて、色々なプロジェクトが発生しそれにクリエイティブ力で応えるグループです。所属しているメンバーはそれぞれ異なる技術や経験を持っているので、クリエイティブの側面からサービスの改善案を出し、周りを巻き込みながらプロジェクトを進めています。
【SRE】DBRE G/東京・大阪・名古屋・福岡
DBREグループについてKINTO テクノロジーズにおける DBRE は横断組織です。自分たちのアウトプットがビジネスに反映されることによって価値提供されます。


