プラットフォームグループのご紹介

自己紹介
はじめまして、KINTOテクノロジーズ(株)でプラットフォームグループのグループマネージャをしている岩崎です。
私は2019年12月よりKINTOテクノロジーズ(株)の前身である株式会社KINTOの開発・編成部に入社しインフラエンジニアとしてシステム構築・運用を実施しながらグループの立ちあげを進めてまいりました。現在ではグループマネージャーの他にSRE、MSPとCCoEも担当しております。元はECサイトを手かげるIT企業出身。オンプレミスやプライベートクラウドなインフラ環境におけるServer Administrator、SREチームのエンジニアやマネジメントを手がけた後KINTOへ入社しております。
本記事の位置付け
本記事はプラットフォームグループのチーム紹介およびこれまでの活動とこれからについて皆様に知っていただき一緒に働いてみたい!と思っていただけることが目的となります。
プラットフォームグループ
役割
AWSを中心とするインフラ設計、構築、運用などを担当
特徴
「標準化されているもの」「これから導入するもの」が混在しているため積極的に他者を助けたり、逆に助けを得ながら未知を楽しんで活動しています。
組織構成
| チーム名 | 所属人数 | 拠点 |
|---|---|---|
| System Administrator | 6名 | 東京・大阪 |
| DevOps | 6名 | 東京 |
| SRE | 3名 | 東京 |
| DBRE | 4名 | 東京 |
| MSP | 3名 | 東京・名古屋 |
| CCoE | 2名 | 東京・大阪 |
- 2022年11月現在
- チーム兼務あり
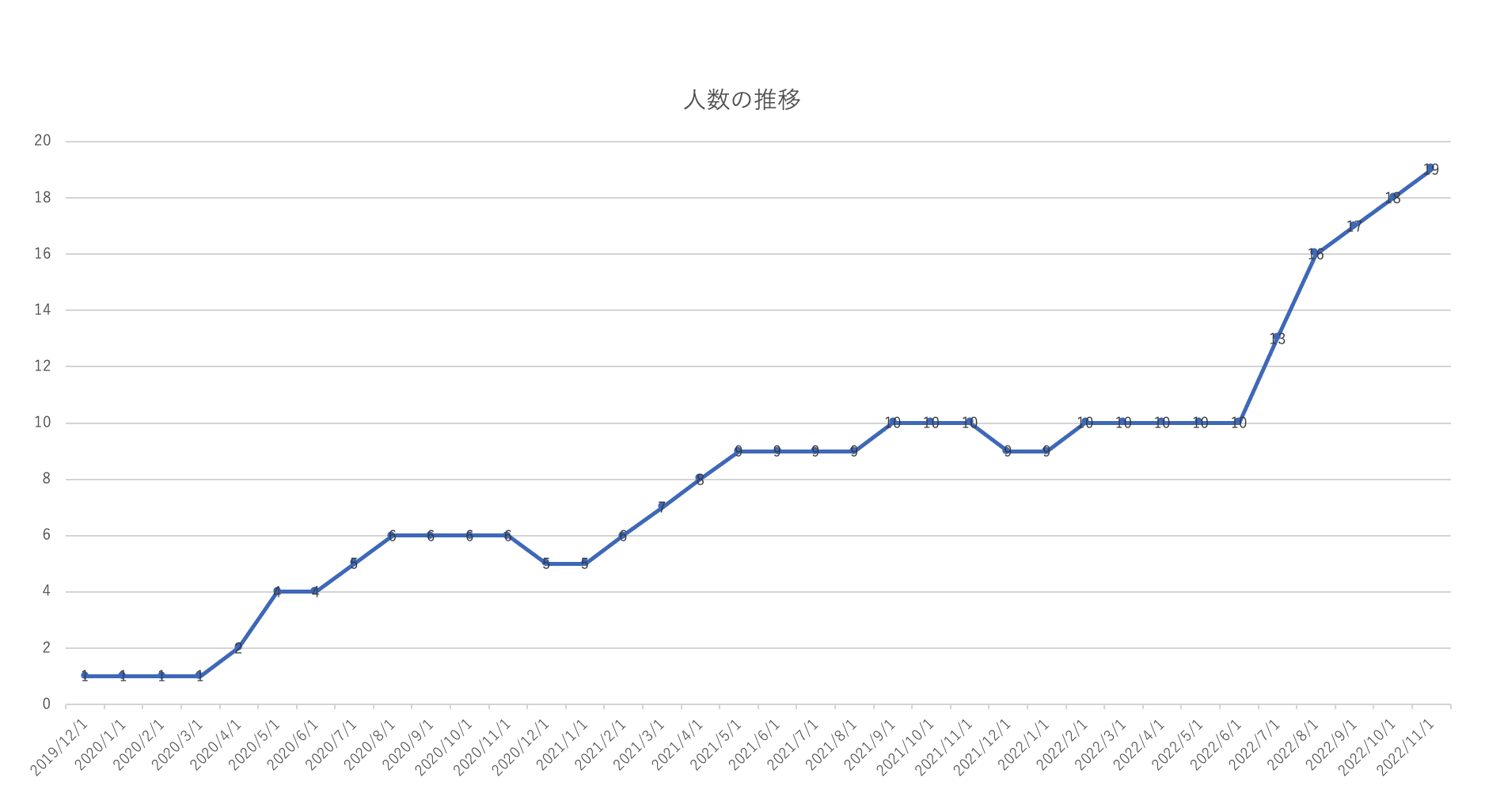
所属人数推移
まだ3年ですがムーアの法則とは行かないなりにも成長を続けております。
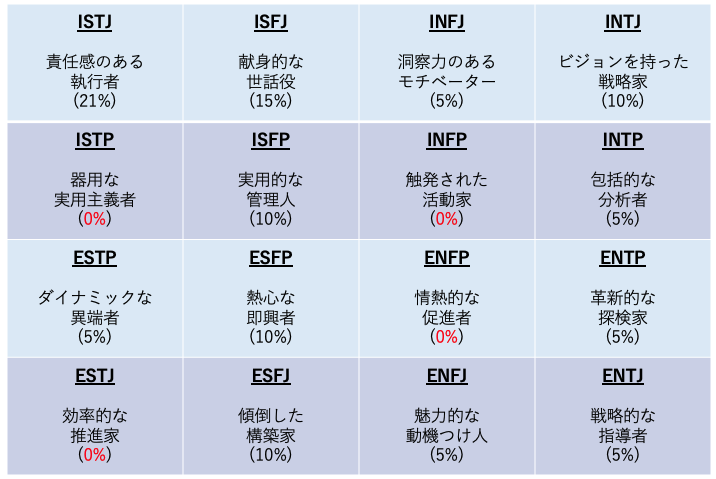
メンバーの性格
多種多様な性格の方が集まっています。
全16種制覇のためにまだいない性格の人は優遇?ではないですが来ていただけるとまたさまざまな議論ができそうで嬉しいです。
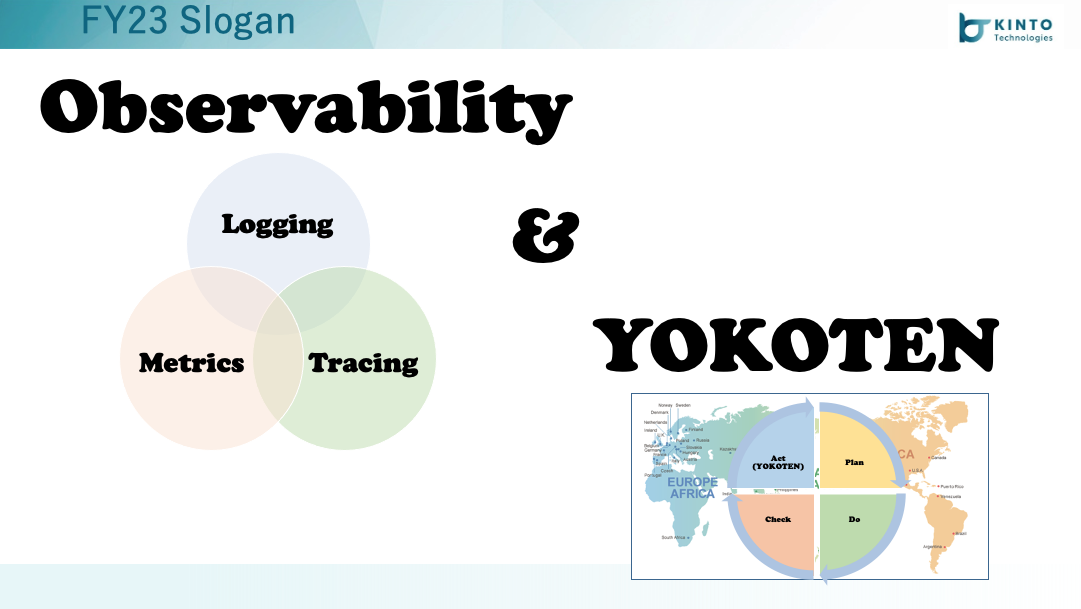
FY23グループスローガン
今期のスローガンはこちらにしております、前期までに色々とリリースをしてきたものの利用率をあげて成果をだせるところにスコープを置くことをイメージしてこちらに設定しております。
FY23グループミッション
今期のグループミッションはこちら↓です。元々、AgilityとStabilityに関しては4半期ベースで+10%を目指してやってきましたのでさらにそこへ加速できるために自分達が何ができるかをチャレンジしてもらうというメッセージを込めてます。

チーム紹介
System Administrator チーム
AWSのプロフェッショナルエンジニア集団、IaCによるシステム構築やシステム変更などの運用業務を担いながら、システムパックのリリースやアプリケーションモニタリングなど改善業務もこなすプラットフォームグループの中核。
採用募集ページ
DevOpsチーム
アプリケーションのチューニングや運用や、AWSまで熟知したプロフェッショナル集団。GitHub ActionsによるCI/CDの提供やDevSecOpsの推進などを手がける。KINTOテクノロジーズ(株)のコンテナ(ECS)化の影の立役者、現在はAPMや分散トレーシング(X-Ray)などの導入・普及にも注意力している。
採用募集ページ:採用予定なし
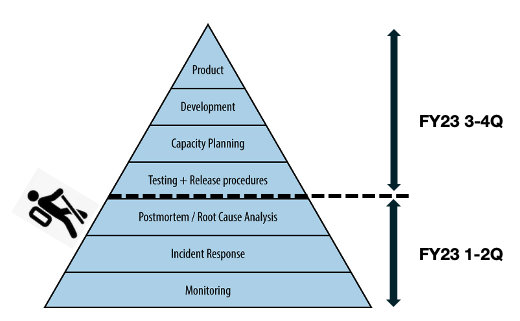
SREチーム
未来のプロダクト信頼性を担うプロフェッショナル集団。信頼性向上のためにどんな事ができるのかをSREヒエラルキーを下から積み上げながらSREガイドラインを作成中。プロダクトを絞って開発グループへのSREサポートも並行して実施しております。
採用募集ページ
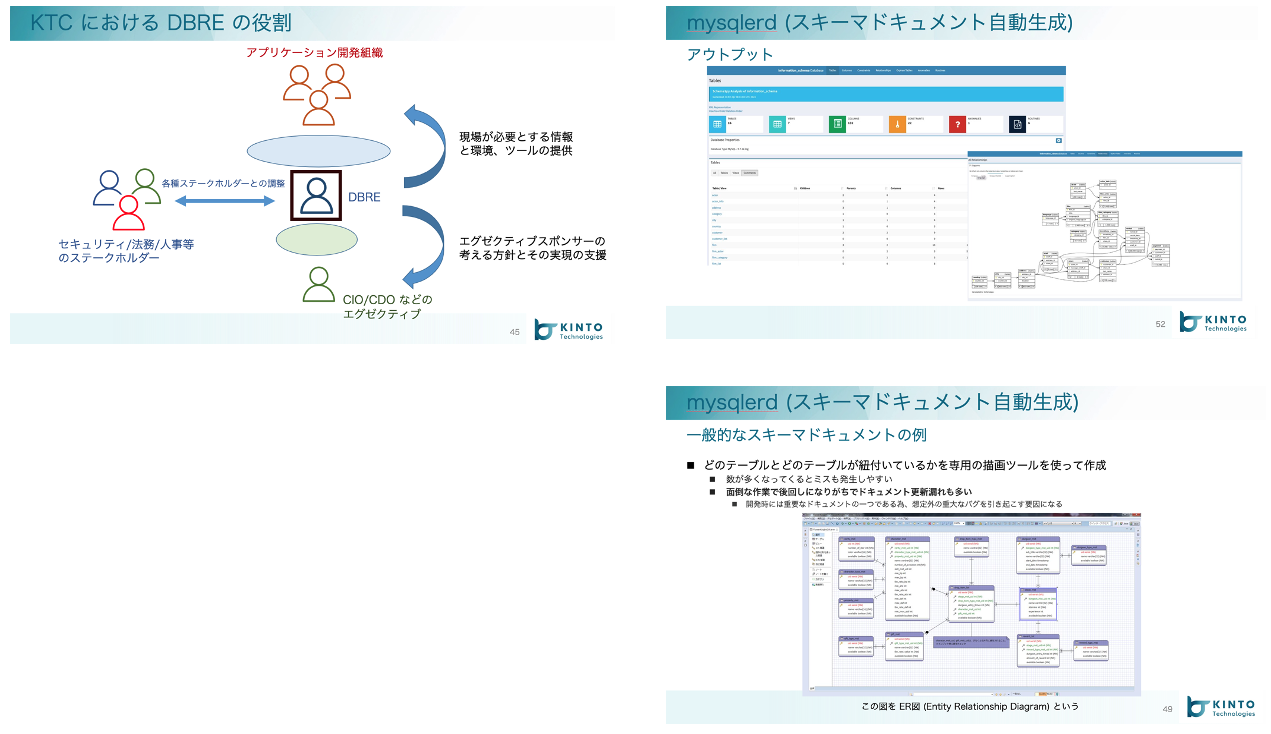
DBREチーム
データベースのスペシャリスト集団。データベースの信頼性向上のために見える化するツール提供から、セキュリティ対策やマスキング対策などの施策も順次準備中。
採用募集ページ
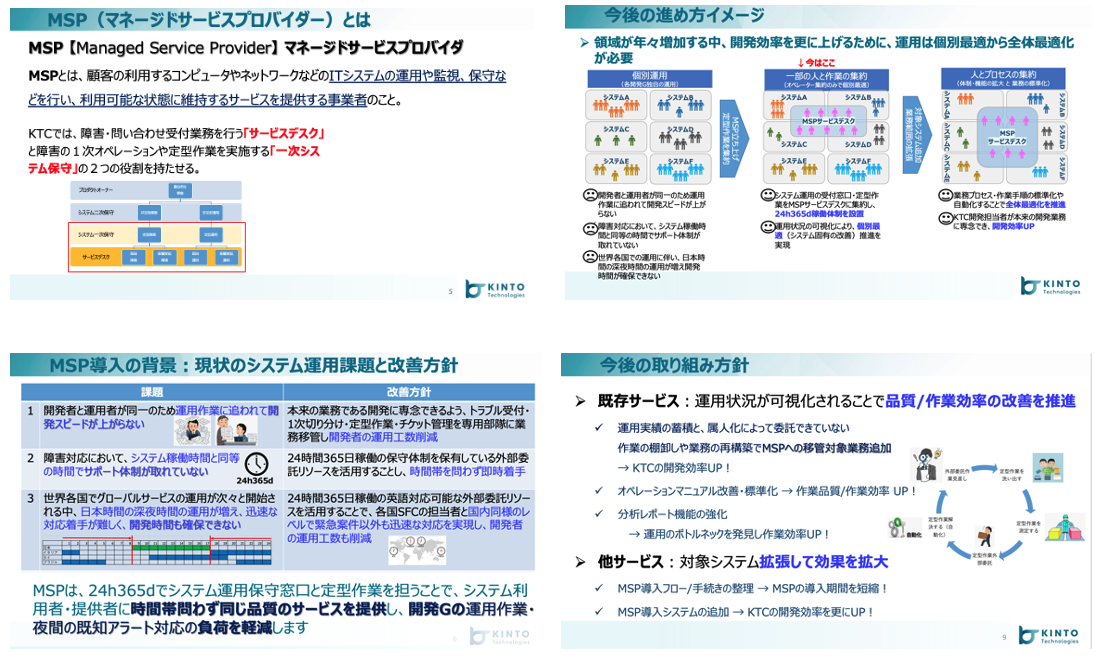
MSPチーム
アプリケーションの障害・問い合わせ受付業務を行う「サービスデスク」と障害の1次オペレーションや定型作業を実施する「一次システム保守」の2つの役割を担っていただける協力会社との連携を行う事務局的役割。
採用募集ページ:採用予定なし
CCoEチーム
クラウドセキュリティのスペシャリスト集団。クラウドセキュリティガイドラインの作成から、ガードレールの実装やAWS/GCPの教育サポートまでを手がける。

採用募集ページ
プラットフォームグループ活動の軌跡
インフラ設計・構築・運用の内製化
まず初めに実施したことは外部委託されていたシステム環境を自前のAWS環境へ移行し、同時に24x7監視を含めた運用含めて内製化を実現させました。内製化と言っても構築作業はもちろんのこと1人で24x7のPagerDutyを受け続けるという体制でのスタートとなっております。
IaC(Infrastructure as Code) Terraformを利用し、全体最適を意識したモジュールを作成
次に実施したのはIaC化です。優秀なエンジニアにJoinいただいたのでIaC化を本格的に進めることにしました。当時はマルチクラウドも意識してTerraformを採用しております。EC2構築にはPacker+AnsibleでOSイメージ(AMI)を作成し、Terraformで仕上げるところから始めています。
このTerraformモジュールの初期設計が後のECS化の礎となっております。
コンテナ化(EC2の脱却と共にECS化を推進)
次に仕掛けたのはコンテナ化(EC2->ECS)です。EKSでなくECSにしたのは当時はプロダクト単体で構築されるシステム構成が多くECSの方がCI/CDを含めた学習コストが低くコンテナ化しやすいと考えたからになります。コンテナ化した後のリリース業務などは開発グループ側へ権限付与を想定しておりましたのでなるべく開発グループのエンジニア負荷をさげて導入コストも抑えながらコンテナ化を実現したいという思いがありました。
CI/CD(GitHub Actions)提供・教育・導入サポート実施
CI/CDはコンテナ化を推進するには提供が必須でした。ECSでのコンテナ使えますよと案内してもメリットを感じてもらえないと意味がありませんでした。そこでGitHub ActionsでのCI/CDを提供し、同時にSonarQubeも提供したCI/CDを使えば情報がPushされて静的解析されますよというDevSecOpsの要素も入れて提供を開始しました。
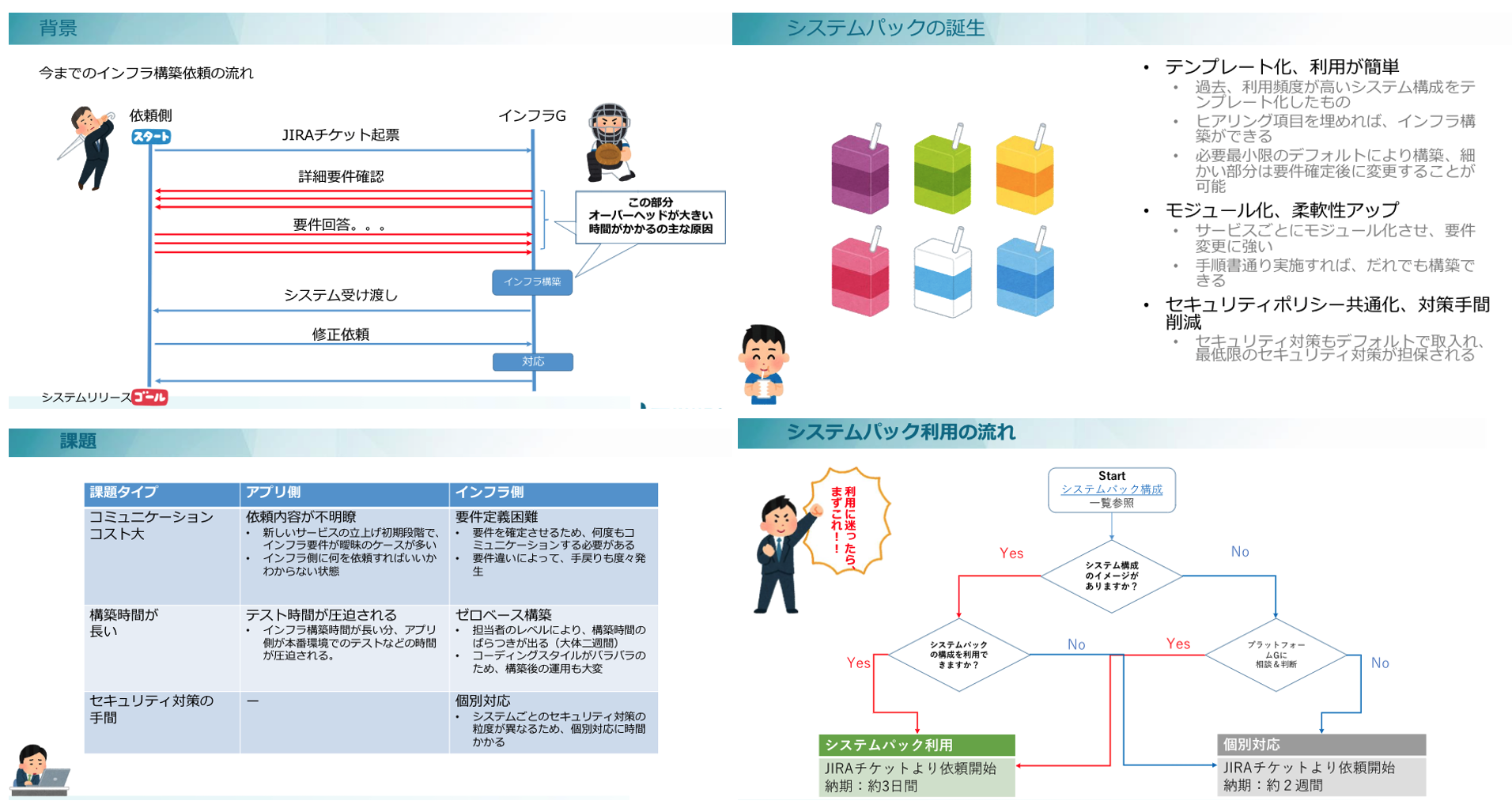
システムのリリース(1システム構成の構築を2週間から3日間へ短縮)
続いて仕掛けたのはシステムパックの提供です。システムパックとはあらかじめよく依頼されるシステムの型を6種類ほどに絞り必要最低限のインプット情報をいただければ3日間でAWS上にシステム構築してお渡ししますよというものになります。
これによりシステム設計時のヒアリングによるストレス軽減や時間の短縮が可能となり開発グループとの関係性改善にも寄与した試みだったと思います。今では7割ぐらいの依頼がシステムパックでDev環境構築を依頼され、その後アプリケーション設計を進める中でSTG、PRODとPackから要件として落とされた内容をシステムに反映したカスタマイズされるという流れができております。
MSP(Managed Service Provider)の導入・開発Gへの提供および導入サポート開始
システムパックと同時に仕掛けたのは開発グループ側の障害対応1次受けや、定型作業を外部委託先で運用いただくという試みになります。
こちらは当時のプラットフォームグループで受けるべき作業ではなかったのかもしれないのですが、まだまだ会社として成長途中でしたので開発グループへの貢献をよりできないかという観点から開発グループの一部のメンバーや外部委託と協力してサポート開始しております。
今ではMSPが事業部や関連会社からの問い合わせ窓口の中心になりつつあり重要な存在となっております。
アプリケーションモニタリング強化
次に仕掛けたのはモニタリング強化です。但し、インフラのモニタリングは既にシステム設計と共にほぼ完成されておりましたのでターゲットとしてはアプリケーション監視となりました。
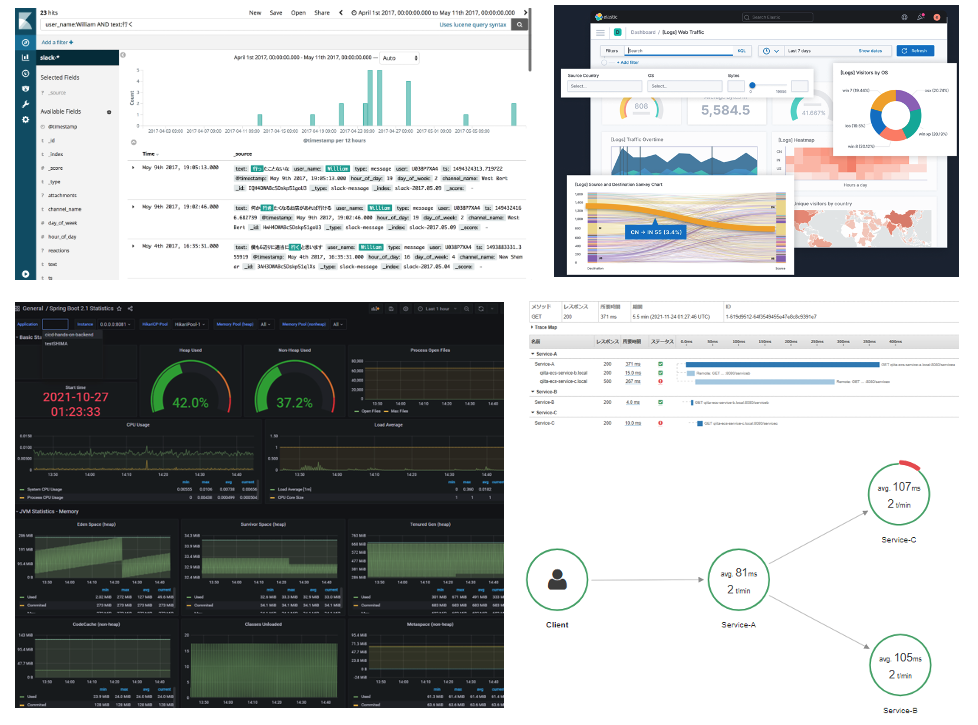
ログ基盤(OpenSearch)導入・導入サポート開始
ログ基盤として初期はCloudWatchのみを提供しておりましたが、ログ格納時にJSON形式で格納しないとログが閲覧時に時系列でバラバラになりさらに複数サーバから送信されると解析しにくいという問題がありました。
これに対応するためにAWSのManaged ServiceであるOpenSearchを構築して提供しております。
この時にOpenSearchだけを提供しても利用促進とならないことはわかっておりましたので同時にECSのサイドカーとしてOpenSearchへログを送信するサイドカー(fluentbit)のコンテナイメージ化とCI/CDのテンプレートへ導入するなどして同時に提供しております。
APM(Application Performance Management:Prometheus+Grafana)導入・導入サポート開始
コンテナ(ECS)化を推進したことでコンテナ内アプリケーションのリソースモニタリングが必要となりました。これに対応するためAWS ManagedのPrometheus+GrafanaでのAPMを提供しております。
こちらもログ基盤と同様にサイドカー(Open Telemetry)を提供して利用しやすい環境を提供しております。
分散トレーシング(X-Ray)導入・導入サポート開始
モニタリング強化の3本柱として分散トレーシング(X-Ray)の提供も開始しました。これによりコンテナ間通信やバックエンドのエンドポイントやDBへの通信状況の見える化ができ問題点も瞬時にわかるようになりました。
さいごに
グループは立ち上げ段階をへて成長期に入っております。入社後の受け入れとしてOn boardingコンテンツも充実させておりますのでご興味のある方はカジュアル面談からでもお気軽にご応募ください
関連記事 | Related Posts



We are hiring!
Cloud Engineer(トヨタグループ内製化支援)/Cloud Infrastructure G/東京・名古屋・大阪・福岡
トヨタグループのクラウド活用を、最前線で支える。1社にとどまらないスケールで、移行・生成AI・内製化まで幅広く挑戦できるポジションです。
【クラウドプラットフォームエンジニア】プラットフォームG/東京・大阪・福岡
プラットフォームグループについてAWS を中心とするインフラ上で稼働するアプリケーション運用改善のサポートを担当しています。

