SageMaker勉強会と文化醸成 (4/4)

こんにちは。分析グループ(分析G)でMLOps/データエンジニアしてます伊ヶ崎(@_ikki02)です。
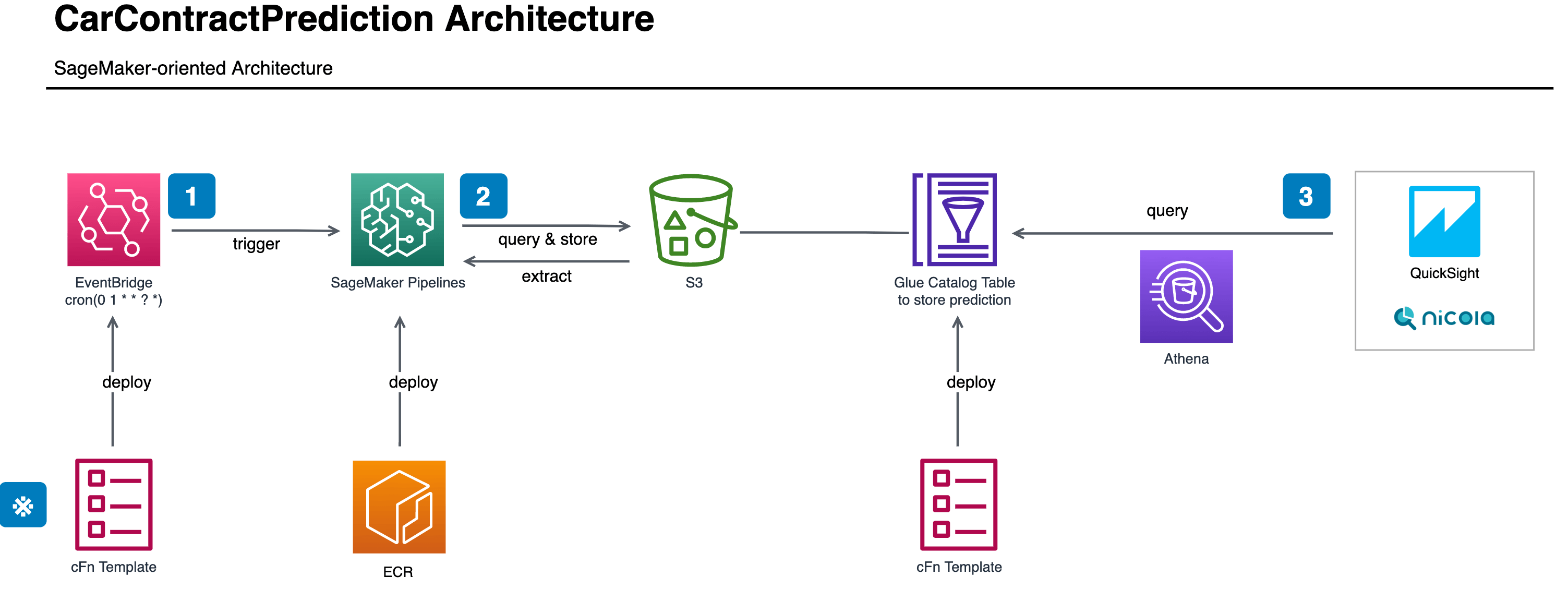
こちらは「KINTOテクノロジーズ株式会社にてどのようにMLOpsを適用していくのか」というテーマでの連載最終回です。1本目の記事「KINTOテクノロジーズのMLOpsを定義してみた」、2本目の記事「SageMakerを使った学習&推論のバッチパターン」および3本目の記事「SageMaker Experimentsを用いた実験管理」はそれぞれのリンクよりご確認ください。
背景(Situation)
1本目の記事では、MLOpsの定義とスコープについて紹介しましたが、一緒に働くメンバーと理解をすり合わせる活動にも取り組んできました。
エンジニアやデータサイエンティストといった異なる職掌がいる中で共通理解を得られるように布教するのは実際難しかったです。勉強会開始時点では、1本目の記事で紹介した図で言うと、ソフトウェアエンジニアは「(B) 信頼性を高めるシステム連携」の項目(推論基盤やIaC、CI/CDなど)が得意な一方、データサイエンティストは「(A) PJ管理・高速化」の項目(学習基盤、メタデータ管理(実験管理)など)に対する前知識があったように思います。このような背景や興味関心の違いは、ワードチョイスに微妙な違いがあったり、議論が右往左往してしまうことに繋がったりするように感じました。概念や用語の共通認識とそれを実装する方法を共有し、お互いの認識の差異を吸収する機会が必要だったように思います。

業務(Task)
その機会として勉強会を企画しました。共通の機械学習基盤たるSageMakerについてお互いが学び合う機会となることを期待したのでした。
ゴールとしては以下のように設定しました。
- MLOpsを進めるにあたって関係者の関係構築
- MLOpsおよびSageMakerに対する共通理解の形成
やったこと(Action)
私個人としては企画とファシリテーションに集中したかったのと、コンテンツの習熟をメンバーに促す趣旨から、コンテンツの準備に焦点を当てました。具体的な勉強会開催の流れは以下の通りです。
- 勉強会のスコープ策定
- 各勉強会の担当者割振。担当分のコンテンツ共有
- 勉強会用スライドおよびノートブックの作成準備(隔週開催)
- 勉強会開催
- 2に戻る
まず「勉強会のスコープ策定」を実施しました。SageMaker全体をスコープにすると膨大な量になるため、以下の7つの項目に絞りました。
- SageMaker全体像およびStudioの概要
- 訓練ジョブの作成
- 推論の実行(バッチ推論と推論エンドポイント)
- SageMaker Processing (ETL特化のジョブ)
- SageMaker Experiments (実験管理)
- SageMaker Pipelines (パイプライン)
- SageMaker Projects (CI/CD)
上記スコープを分析グループおよびプラットフォームグループのメンバーに提案し、4名のプレゼンター(データサイエンティスト1名、インフラ&DevOpsエンジニア3名)が集まりました。バックグラウンドの異なるメンバーが集まった中、なるべく準備に負担をかけずに一定の品質を担保したかったので、それぞれの得意領域を意識して、各勉強会の担当者を割振るようにしました。具体的には、「訓練ジョブ」や「SageMaker Experiments」はデータサイエンスの業務プロセスの理解が必要だったためデータサイエンティストへ割当て、「SageMaker Processing」や「SageMaker Projects」はコンテナ周りやCI/CDの知識が背景に求められるためエンジニアにお願いしました。
また、勉強会のコンテンツとしては、AWS公式のドキュメントである「developer guide」とそこに掲載されている「SageMaker関連のサンプルノートブック」を土台として作成を依頼しました。公式のドキュメントは画面のスクリーンショットやサンプルコードの掲載など、本当によくできているので(日本語の機械翻訳が面白いことがあるのはご愛嬌)、イチから新たに作り直すというよりは、そこにある内容を各個人の理解に合わせて切り貼りしてまとめてもらうのが良いと考えています(個人的にはdeveloper guideの良さを布教しつつ、一次ソースの引用癖を付つけていくのも狙いでした)。

結果(Result)
上記の内容で、2021年11月〜2022年1月までの期間で隔週開催しました。嬉しかったのは、勉強会後、参加メンバーがSageMaker Pipelinesのデプロイ方法を習熟し、社内で開発運用しているGitHubActionsのCI/CDのSageMaker版を構築したことでした(この連載でも触れたバッチパターンのCI/CD基盤としても活用しており、SageMaker Projectsとの差別化のお話などもいつかこちらのテックブログでご紹介できればいいなと思います)。
個人の想いとしては、ソフトウェアエンジニアリングとデータサイエンスという様々な知識や役割を超えて共通認識を構築していく勉強会は改めて大切な取組みだなと感じており、この勉強会が目的通り共通認識の形成と関係構築に少しでも貢献できていたらよいなと思います。
いかがでしたでしょうか?
本掲載にて「KINTOテクノロジーズ株式会社にてどのようにMLOpsを適用していくのか」というテーマでの連載は一旦最終回を迎えますが、プロジェクト的にも組織的にもまだまだ変化の多いフェーズのため、MLOpsも進化を続けなければなりません。プロダクト開発に機械学習を組込む取組み、そして価値提供を改善し続けていく取組みはまだまだ始まったばかりなので、引続きアップデートをお伝えしていければと思います(本テックブログのTwitterもありますのでフォローしてくれると嬉しいです)。
関連記事 | Related Posts


We are hiring!
【シニアデータサイエンティスト(Python)】データサイエンスG/東京・大阪・名古屋・福岡
募集背景KINTOでは、事業成長とともに、データを活用したマーケティング分析の重要性が高まっています。市場やお客様の変化を捉え、より良い顧客体験を提供するため、施策の評価や課題発見、改善提案を推進できる体制強化が必要となりました。
【ソフトウェアエンジニア(リーダークラス)】共通サービス開発G/東京・大阪・福岡
共通サービス開発グループについてWebサービスやモバイルアプリの開発において、必要となる共通機能=会員プラットフォームや決済プラットフォームなどの企画・開発を手がけるグループです。KINTOの名前が付くサービスやKINTOに関わりのあるサービスを同一のユーザーアカウントに対して提供し、より良いユーザー体験を実現できるよう、様々な共通機能や顧客基盤を構築していくことを目的としています。




