Building Cloud-Native Microservices with Kotlin/Ktor (Observability Edition)

Building Cloud-Native Microservices with Kotlin/Ktor (Observability Edition)
Hello. My name is Narazaki from the Woven Payment Solution development group. At Woven by Toyota , we are involved in the backend development of the payment infrastructure used in Toyota Woven City, and we are developing it using Ktor, a web framework made with Kotlin. These backend applications run on City Platform, a Kubernetes-based infrastructure used in Woven City, forming the foundation of our microservices.
In this article, I would like to introduce some pain points of microservices when configuring a microservices architecture and some tips for improving observability, which is essential to resolving those pain points,
using as examples Ktor, a web framework that we use, and Kubernetes as a platform for hosting microservices.
In addition to Kubernetes, I would like to introduce a so-called "cloud native" technology stack. This time, I will use Loki as a log collection tool , Prometheus as a metrics collection tool, and Grafana as a visualization tool .
I hope this will be useful not only for those who are actually developing microservices using Java or Kotlin, but also for developers who are planning to introduce microservices and Kubernetes, regardless of the programming language they use.
Instructions on how to replicate these steps, along with sample code, are provided at the end of this post. If you have time, please give it a try!
First: The Challenges of Microservices
Generally speaking, by adopting microservices, various problems of monolithic applications can be resolved, but on the other hand, the complexity of the application increases, making it very difficult to isolate problems when they occur. Here, we will consider three specific pain points.
Pain Point 1: It is not clear when and which service caused the error. Pain Point 2: The operation status of dependent services must always be taken into consideration. Pain point 3: It is difficult to isolate resource-related performance degradation.
By improving observability, we can tackle these challenges. In this post, I’ll show how we can implement solutions for each pain point using Ktor as an example. The approach involves introducing just three plugins and adding a few lines of code.
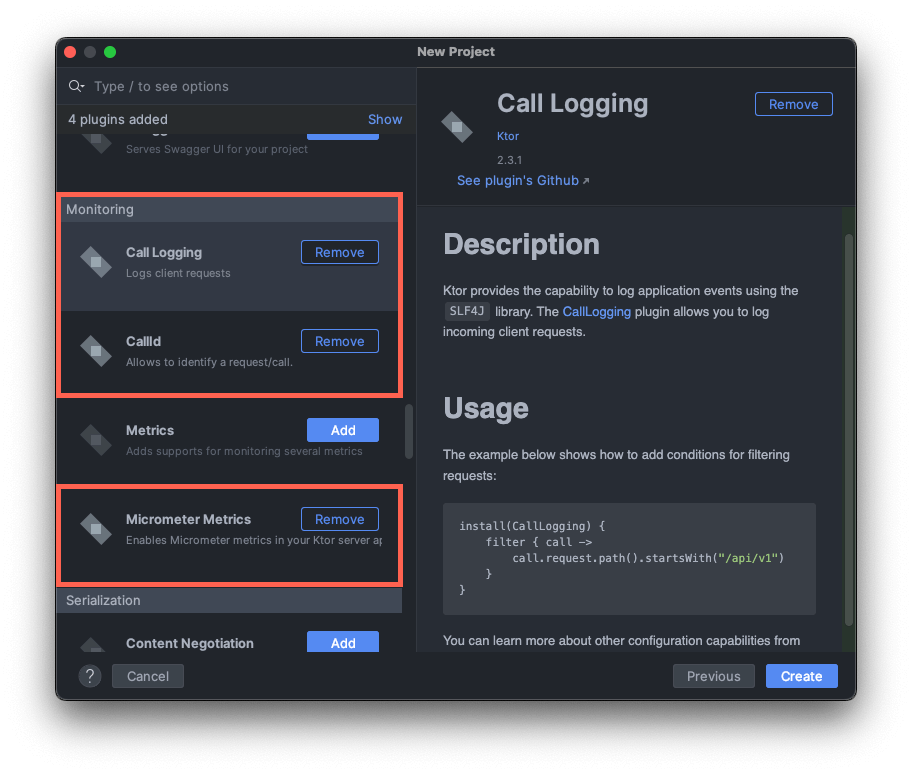 The three Ktor plugins that we are introducing
The three Ktor plugins that we are introducing
Solution 1. Introducing CallId
In this solution, I will create two services that frequently call APIs within the same cluster, as is common in microservices. Let's see how the logs are captured in this environment.
Logs will be output to standard output and collected by a log collection tool (Loki, in this case) deployed separately on Kubernetes. The services will be referred to as the caller (frontend) and the callee (backend). When monitoring, you may be able to see what is happening on each server by specifying the pod name, etc., using a logging platform, but requests across servers cannot be viewed in relation to each other. Especially as the number of requests increases, it becomes very difficult to isolate which application logs are related simply by displaying logs in chronological order.
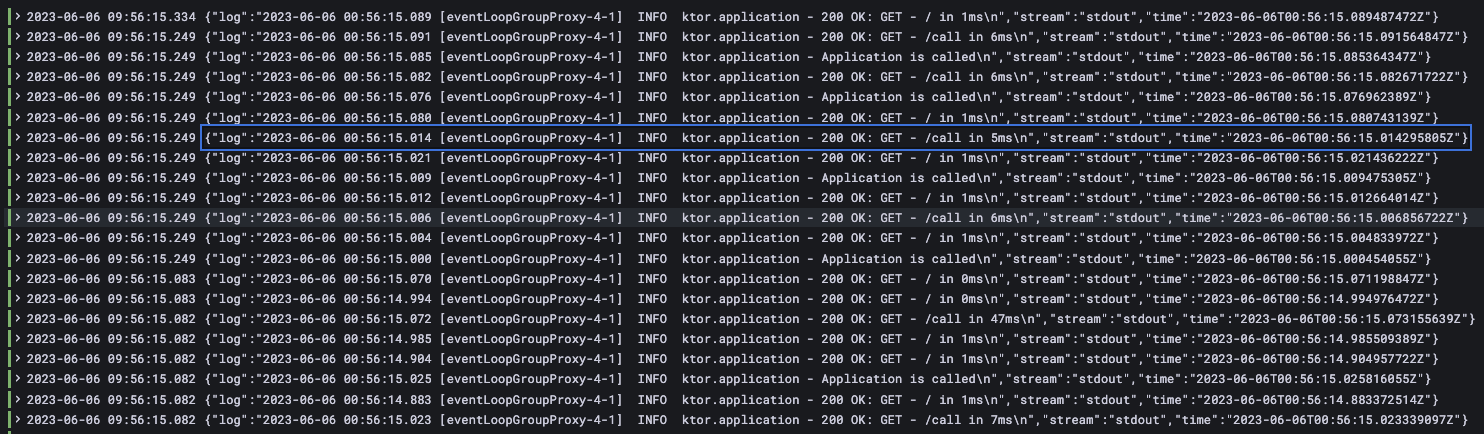 When a large number of requests come in, it becomes unclear which requests and responses are related...
When a large number of requests come in, it becomes unclear which requests and responses are related...
The mechanism that associates causally related events across servers over the network is called distributed tracing. In general, if you use a service mesh like Istio, you can visualize related requests with tools like Zipkin and Jaeger, making it intuitive to understand where errors occured. On the other hand, it is not very convenient to use when troubleshooting application logs, such as searching for keywords in the logs.
This is where Ktor's CallId comes into play. With this feature, you can search and view specific logs by using CallId as a keyword on the logging platform. Also, since there is no need to configure the network layer, it is flexible and can be completed by the application engineer without having to introduce a service mesh or similar. Let's actually run the application and check the logs in Grafana.
In this example, we will prepare the same container image for both the frontend and backend, so we only need to generate one project. Follow these steps to generate the source code from the template.
dependencies {
implementation("io.ktor:ktor-server-call-logging-jvm:$ktor_version")
implementation("io.ktor:ktor-server-call-id-jvm:$ktor_version")
implementation("io.ktor:ktor-server-core-jvm:$ktor_version")
}
The necessary libraries are referenced as shown above. The logging-related part of the generated code should be modified as follows. (Comments are included to explain each line; no further modifications are necessary.)
fun Application.configureMonitoring() {
install(CallLogging) {
level = Level.INFO
filter { call -> call.request.path().startsWith("/") } // Specify the conditions under which logs will be output
callIdMdc("call-id") // By setting this, the value can be embedded in the %X{call-id} part of logback.xml
}
install(CallId) {
header(HttpHeaders.XRequestId) // Specify which header will store the ID value
verify { callId: String ->
callId.isNotEmpty() // Verify if a value exists
}
+ generate {
+ UUID.randomUUID().toString() // If not, generate and embed a new value
+ }
}
In the HTTP client implementation, it’s recommended to set the header with this value so that the same CallId propagates across requests. Add the following dependencies to verify that the CallId propagates correctly between servers.
dependencies {
...
+ implementation("io.ktor:ktor-client-core:$ktor_version")
+ implementation("io.ktor:ktor-client-cio:$ktor_version")
...
}
routing {
+ get("/call") {
+ application.log.info("Application is called")
+ val client = HttpClient(CIO) {
+ defaultRequest {
+ header(HttpHeaders.XRequestId, MDC.get("call-id"))
+ }
+ }
+ val response: HttpResponse = client.get("http://backend:8000/")
+ call.respond(HttpStatusCode.OK, response.bodyAsText())
+ }
Once you’re able to build and deploy using the sample code below, try running the following commands to make API calls:
curl -v localhost:8000/
curl -v -H "X-Request-Id: $(uuidgen)" localhost:8000/call
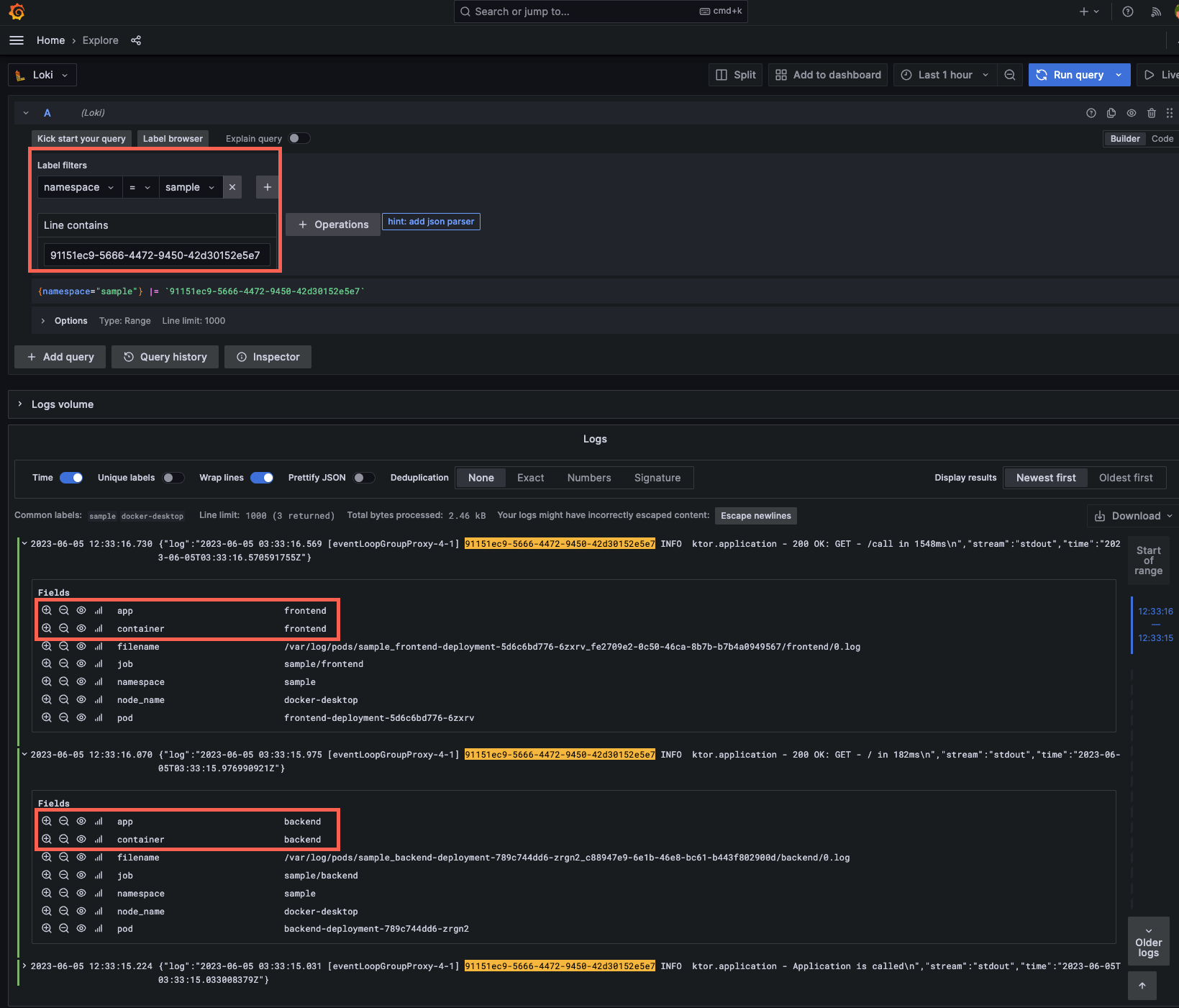 With this setup, the CallIds now propagates between servers, allowing it to be used as a searchable keyword
With this setup, the CallIds now propagates between servers, allowing it to be used as a searchable keyword
Even if you don't enter a value in the header, the CallId value will be added to the log. Also, if you search for the UUID value generated by this command, you will be able to correlate events on multiple servers.
Solution 2. Setting Up Liveness and Readiness Probes
In Kubernetes, liveness and readiness probes are mechanisms that communicate the application’s health status to the control plane. You can refer to this Google article for more information on each.
Liveness Probe: Reports the container’s own health status. Readiness Probe: Reports whether the application, including to dependent services, is ready for operation,
accessible through APIs. By setting these, you can efficiently recycle containers that have failed to start, or control traffic so that containers that have failed to start are not accessed.
Let's implement these with Ktor. Here, no libraries are needed. The implementation policy is that the liveness probe is to inform Kubernetes of its own aliveness status, so it's fine to just return OK to the request. The readiness probe will send pings to dependent services and connected databases. To handle cases where responses aren’t received in time, set a request timeout.
routing {
...
get("/livez") {
call.respond("OK") // Simply returns a 200 status to indicate the web server is running
}
get("/readyz") {
// Implement pings to the DB or other dependent services based on the application’s requirements
// You can set request timeouts for SQL Client or HTTP Client to ensure connection are made within the expected time
call.respond("OK")
}
}
You need to tell the Kubernetes control plane that these API endpoints exist. Add the following to the Deployment definition. This configuration also allows you to set the time needed for the application to be ready to process requests, which will prevent false detections even if the initial startup takes longer.
...
livenessProbe:
httpGet:
path: /livez
port: 8080
readinessProbe:
httpGet:
path: /readyz
port: 8080
initialDelaySeconds: 15 # The readiness probe will start checking 15 seconds after the container starts; default is 0
periodSeconds: 20 # Runs every 20 seconds
timeoutSeconds: 5 # Expected to return results within 5 seconds
successThreshold: 1 # Considered successful after one success
failureThreshold: 3 # If it fails three consecutive times, the pod will restart
...
With this, the setup is complete. You can test the behavior by adding a sleep command within the endpoint or by adjusting these parameters. Also, although this is only a reference this time, we recommend building a system to notify you using Prometheus's Alertmanager or similar if an abnormality is detected.
Solution 3. Configuring Micrometer
By implementing the first two solutions, observability should be significantly improved. While Kubernetes allows monitoring at the Pod and Node levels, runtime-level monitoring within the application is still limited. Generally, Kotlin applications run on the JVM, allowing you to monitor runtime performance by tracking CPU and memory usage, as well as garbage collection behavior on the JMV. This helps detect unintended runtime-related performance degradation.
So, how should we approach this in a microservices architecture? In a monolith, it should be relatively simple to implement by installing an agent on the server where it will run. On the other hand, in Kubernetes, where containers are repeatedly created and destroyed, installing an agent is not very practical.
Ktor provides a plugin for Micrometer, the de facto standard in the Java ecosystem for collecting metrics, which can be integrated with Prometheus for monitoring.
When creating a project from the template described above, the following packages and source code will be added to the project.
implementation("io.ktor:ktor-server-metrics-micrometer-jvm:$ktor_version")
implementation("io.micrometer:micrometer-registry-prometheus:$prometeus_version")
val appMicrometerRegistry = PrometheusMeterRegistry(PrometheusConfig.DEFAULT)
install(MicrometerMetrics) {
registry = appMicrometerRegistry
}
routing {
get("/metrics-micrometer") {
call.respond(appMicrometerRegistry.scrape())
}
}
By specifying these in Kubernetes configuration files, Prometheus will automatically scrape the endpoints and collect the data.
kind: Service
metadata:
name: backend
namespace: sample
+ annotations:
+ prometheus.io/scrape: 'true'
+ prometheus.io/path: '/metrics-micrometer'
+ prometheus.io/port: '8080'
Additionally, by adding a Grafana dashboard from the marketplace, you can easily visualize JVM performance metrics, improving the transparency of your application.
 You can simply copy and paste the dashboard ID from the marketplace to register it
You can simply copy and paste the dashboard ID from the marketplace to register it
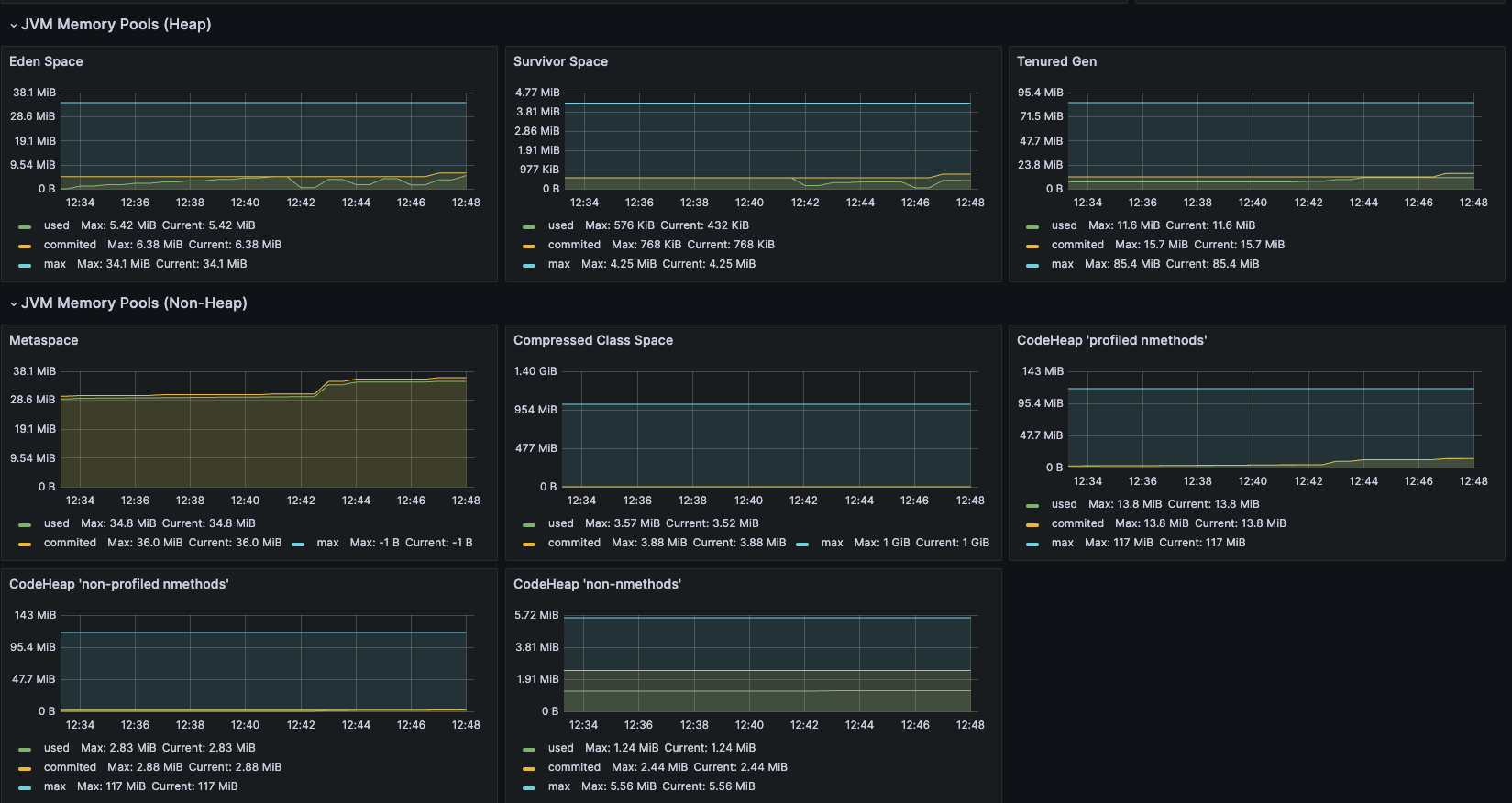 This setup allows you to display memory, CPU, garbage collection, and other metrics on a per-pod basis
This setup allows you to display memory, CPU, garbage collection, and other metrics on a per-pod basis
In addition, by monitoring how much CPU and memory an application is using at any given time from these metrics and setting the CPU resources for containers, you can improve the efficiency of resource usage across the Kubernetes cluster. (Setting these resources is also necessary to ensure proper scaling of the application.)
resources:
requests:
memory: "512Mi"
cpu: "500m"
limits:
memory: "512Mi"
cpu: "750m"
lastly
I hope you have seen that Ktor is a plugin-based web framework that can improve non-functional requirements without significantly changing the behavior of existing applications.
In complex systems, a single oversight can lead to untraceable issues, where hypotheses about bugs can’t be verified and debugging turns into a maze. Regardless of the architecture, it’s important to continuously reduce blind spots to prepare for potential issues.
I hope that this article has provided you with an introduction to the observability features of web frameworks for microservice applications. If you are considering adopting microservices in the future and are unsure of which framework to choose, you should also consider whether these features are available when selecting a technology.
There are also other best practices for building and smoothly operating microservices, such as implementing GitOps, managing inter-service authentication and authorization, and load balancing, which I hope to cover in a future post.
Finally, we are hiring for a variety of positions. If you’re interested, feel free to start with a casual chat.
(Reference) Environment Setup and Sample Code
To replicate this setup in your own, you’ll need a Java runtime environment, Docker Desktop with Kubernetes enabled, and Helm. These have been tested on Mac/Linux. (Windows users, please use WSL2.) This article assumes Kubernetes is running locally. If it’s in the cloud, adjust accordingly.
In this article, we used Loki for log collection, Prometheus for metrics collection, and Grafana for visualization. The source code is created from scratch using a template, and the Docker image is built using Jib as a Gradle build task. In the following example, we will run the build task in Gradle using Kotlin Script(.kts). We also recommend installing a tool called Skaffold to automate Docker tagging and Kubernetes deployment for your container cluster.
helm repo add grafana https://grafana.github.io/helm-charts
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
helm repo update
helm install prometheus prometheus-community/prometheus -n prometheus --create-namespace
helm install loki grafana/loki-stack -n grafana --create-namespace
helm install grafana grafana/grafana -n grafana
export POD_NAME=$(kubectl get pods --namespace grafana -l "app.kubernetes.io/name=grafana,app.kubernetes.io/instance=grafana" -o jsonpath="{.items[0].metadata.name}")
kubectl --namespace grafana port-forward $POD_NAME 3000
# Open another terminal to keep this command running after execution.
Kubectl get secret --namespace grafana grafana -o jsonpath="{.data.admin-password}" | base64 --decode # | pbcopy # For Mac users, uncomment this line to copy the password to the clipboard.
Now, access Grafana in your browser at http://localhost:3000. Use the user ID: admin and enter the password output from the last command to login. Configure each data source as follows:
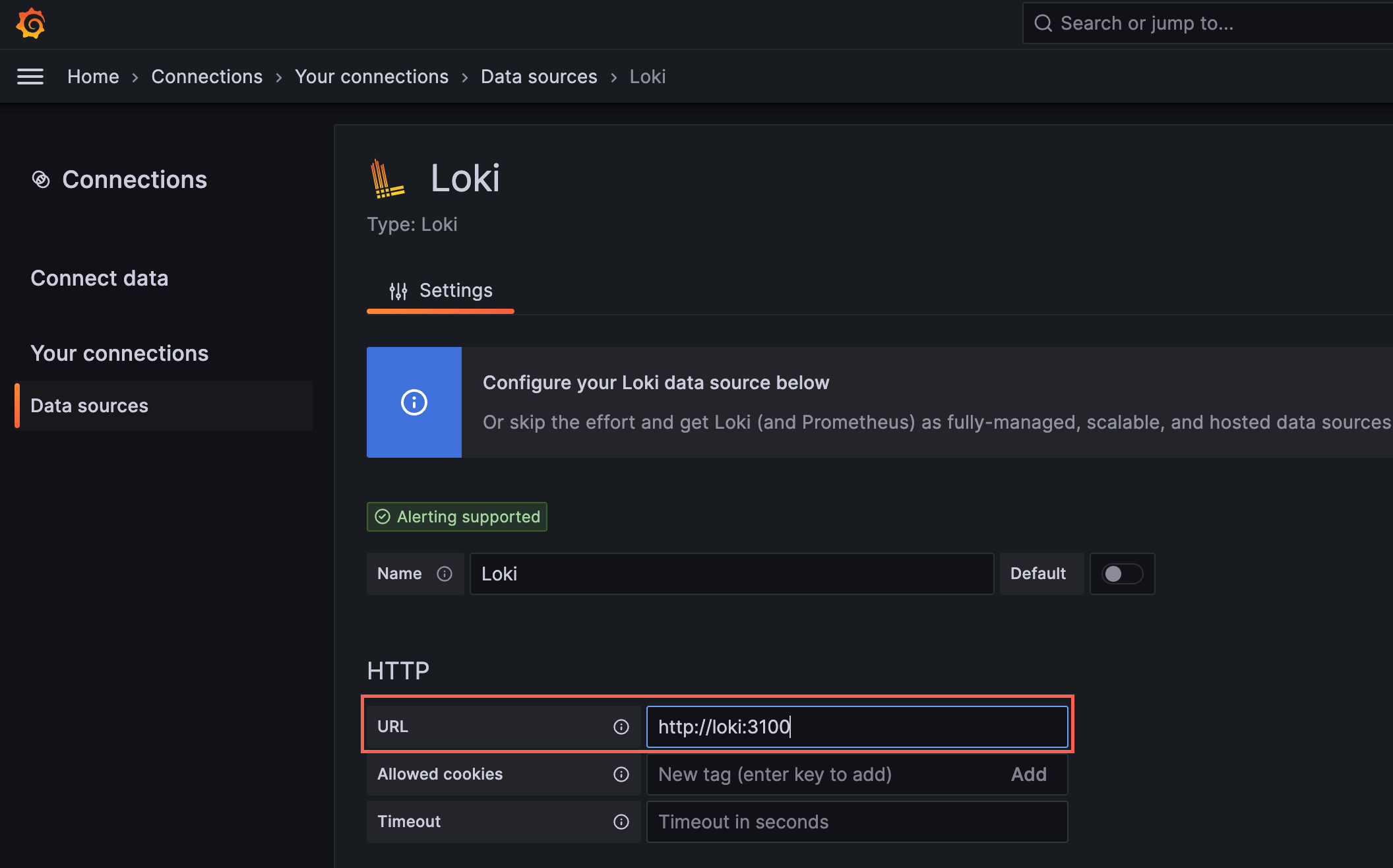 Loki:
Loki: http://loki:3100
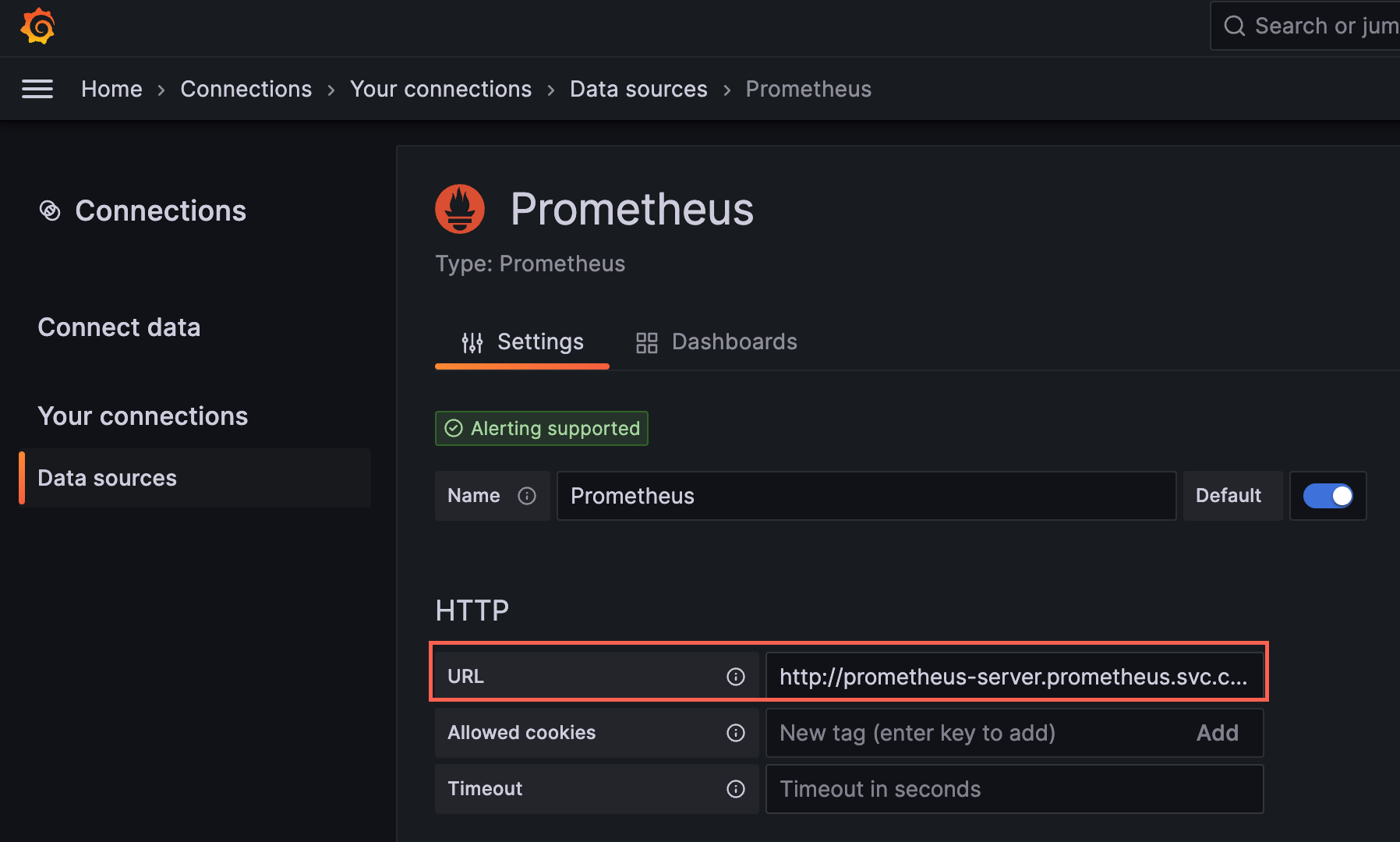 Prometheus:
Prometheus: http://prometheus-server.prometheus.svc.cluster.local
This completes the monitoring setup. For the code, create a new Ktor application from a template in InetelliJ. Select the following from IntelliJ. If you’re using VS Code, you can download it from this site. In this example, we will prepare the same container image for both the frontend and backend, so we only need to generate one project.
Add the following Jib configuration for building with Docker. Then, confirm that you can build by running the Jib Gradle task ./gradlew jibDockerBuild.
plugins {
application
kotlin("jvm") version "1.8.21"
id("io.ktor.plugin") version "2.3.1"
+ id("com.google.cloud.tools.jib") version "3.3.1"
}
...
+ jib {
+ from {
+ platforms {
+ platform {
+ architecture = "amd64"
+ os = "linux"
+ }
+ }
+ }
+ to {
+ image = "sample-jib-image"
+ tags = setOf("alpha")
+ }
+ container {
+ jvmFlags = listOf("-Xms512m", "-Xmx512m")
+ mainClass = "com.example.ApplicationKt"
+ ports = listOf("80", "8080")
+ }
+}
Let's change the log level of Logback so that we can keep an eye on the logs we added this time. Also, to avoid noise, we’ll hide the monitoring endpoints.
- <root level="trace">
+ <root level="info">
install(CallLogging) {
level = Level.INFO
- filter { call -> call.request.path().startsWith("/") }
+ filter { call -> !arrayOf("/livez", "/readyz", "/metrics-micrometer")
+ .any { it.equals(call.request.path(), ignoreCase = true) }}
callIdMdc("call-id")
}
Once you have added this to the source, the container image will be deployed to Kubernetes with the following command and the application will be executed. Check Grafana to see if logs and metrics are being streamed correctly. Since the services.yaml file is a bit lengthy, it’s provided at the very end.
./gradlew jibDockerBuild && kubectl apply -f services.yaml # Update the Docker tag with each build
# If you have Skaffold installed, you can use the following commands:
skaffold init # Generates yaml files
skaffold run # Builds and deploys the application once
skaffold dev # Continuously builds and deploys each time you update the source code
Including portForward in the Skaffold file makes it convenient to access the application at localhost:8000 automatically.
apiVersion: skaffold/v4beta5
kind: Config
metadata:
name: observability
build:
artifacts:
- image: sample-jib-image
- buildpacks: # Remove this as it slows down the build
- builder: gcr.io/buildpacks/builder:v1
+ jib: {} # Make sure JAVA_HOME is set to the correct PATH to avoid execution errors.
manifests:
rawYaml:
- service.yaml
+portForward:
+ - resourceType: service
+ resourceName: frontend
+ namespace: sample
+ port: 8000
+ localPort: 8000
apiVersion: v1
kind: Namespace
metadata:
name: sample
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: backend-deployment
namespace: sample
spec:
replicas: 2
selector:
matchLabels:
app: backend
template:
metadata:
labels:
app: backend
spec:
containers:
- name: backend
image: sample-jib-image:alpha
imagePullPolicy: IfNotPresent
ports:
- containerPort: 8080
# Comment out until implementing the liveness and readiness probes
# livenessProbe:
# httpGet:
# path: /livez
# port: 8080
# initialDelaySeconds: 15
# periodSeconds: 20
# timeoutSeconds: 5
# successThreshold: 1
# failureThreshold: 3
# readinessProbe:
# httpGet:
# path: /readyz
# port: 8080
resources:
requests:
memory: "512Mi"
cpu: "500m"
limits:
memory: "512Mi"
cpu: "750m"
---
apiVersion: v1
kind: Service
metadata:
name: backend
namespace: sample
annotations:
prometheus.io/scrape: 'true'
prometheus.io/path: '/metrics-micrometer'
prometheus.io/port: '8080'
spec:
selector:
app: backend
ports:
- protocol: TCP
port: 8000
targetPort: 8080
type: ClusterIP
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: frontend-deployment
namespace: sample
spec:
replicas: 2
selector:
matchLabels:
app: frontend
template:
metadata:
labels:
app: frontend
spec:
containers:
- name: frontend
image: sample-jib-image:alpha
imagePullPolicy: IfNotPresent
ports:
- containerPort: 8080
# Comment out until implementing the liveness and readiness probes
# livenessProbe:
# httpGet:
# path: /livez
# port: 8080
# initialDelaySeconds: 15
# periodSeconds: 20
# timeoutSeconds: 5
# successThreshold: 1
# failureThreshold: 3
# readinessProbe:
# httpGet:
# path: /readyz
# port: 8080
resources:
requests:
memory: "512Mi"
cpu: "500m"
limits:
memory: "512Mi"
cpu: "750m"
---
apiVersion: v1
kind: Service
metadata:
name: frontend
namespace: sample
annotations:
prometheus.io/scrape: 'true'
prometheus.io/path: '/metrics-micrometer'
prometheus.io/port: '8080'
spec:
selector:
app: frontend
ports:
- protocol: TCP
port: 8000
targetPort: 8080
type: LoadBalancer
Thank you for following along this far. Let’s delete the resources created in this blog using the following commands.
skaffold delete
docker rmi $(docker images | grep 'sample-jib-image')
# Kubectl delete all --all -n sample # If you didn’t use skaffold
helm uninstall grafana -n grafana
helm uninstall loki -n grafana
helm uninstall prometheus -n prometheus
関連記事 | Related Posts


We are hiring!
【福岡拠点立ち上げ】オープンポジション(エンジニア)
やっていること国内サービスでは、トヨタのクルマのサブスクリプションサービスである『 KINTO 』を中心に、移動のよろこびを提供する『 モビリティーマーケット 』、MaaSサービスの『 my route(マイルート) 』など、トヨタグループが展開する各種サービスの開発・運営を担っています。
【大阪拠点】オープンポジション(エンジニア)
やっていること国内サービスでは、トヨタのクルマのサブスクリプションサービスである『 KINTO 』を中心に、移動のよろこびを提供する『 モビリティーマーケット 』、MaaSサービスの『 my route(マイルート) 』など、トヨタグループが展開する各種サービスの開発・運営を担っています。


