BEエンジニア視点のGrafanaによるObservabilityの実践
はじめに
こんにちは!
KINTOテクノロジーズの新車サブスク開発グループに所属している丁(Jeong)です。
私たちの日々の業務は、ただコードを書くだけにとどまりません。技術の進化に伴い、マイクロサービスやサーバーレスアーキテクチャのような新しいトレンドに適応し、システムの健全性を維持することが重要になってきています。この記事では、Observability(オブザーバビリティ/可観測性)の重要性を理解し、Grafanaを活用してシステム監視とパフォーマンス最適化を行っているかを共有します。
Observabilityとは
Observability、または可観測性は、システムの状態やパフォーマンスを監視し、理解する能力を指します。この概念は、システム内で発生する問題を早期に特定し、解決するために不可欠です。特にマイクロサービスやクラウドベースのアーキテクチャでは、多数の動的コンポーネントが関連し合って動作するため、システム全体を継続的に監視する必要があります。
Observabilityの主な要素には、以下の三つがあります:
- ログ: システムのアクティビティやエラーを記録する詳細なデータ
- メトリクス: システムのパフォーマンスや状態を示す定量的データ
- トレース: E2E[1]のリクエストやトランザクションのパスを追跡するデータ
Grafanaとは
Grafanaは、Observabilityのための強力なオープンソースツールです。データの可視化、監視、および分析を行うために広く使われています。Grafanaの最大の特徴は、その柔軟性とカスタマイズ可能なダッシュボードにあります。ユーザーは、異なるデータソースからのメトリクスやログを統合し、簡単に理解できる形で表示することができます。
Grafanaの主な利点は以下の通りです:
- 多様なデータソースへの対応: Prometheus, Elasticsearch, InfluxDBなどと統合可能
- データ分析とアラート: システムの異常を即座に検出し、アラートを通知
- ダッシュボード: ユーザーのニーズに合わせてダッシュボードをカスタマイズできる
Grafanaでの実践例:分かりやすさを重視
新車サブスク開発グループでは、技術的な背景が異なるメンバー全員がデータを理解しやすいよう、Grafanaのダッシュボードを活用しています。ここでは、実際ダッシュボードのパネルで使用しているPromQLのクエリ例とその機能をご紹介します。
APIリクエストの監視
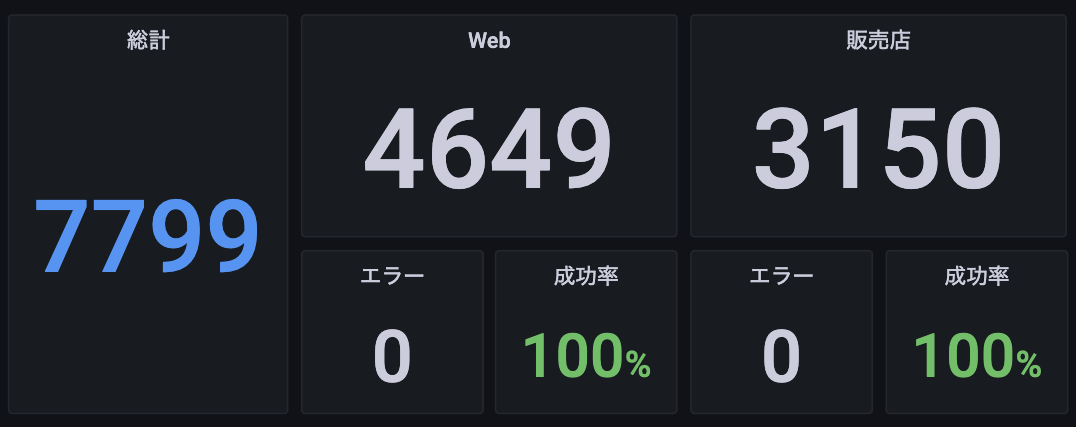
契約数 #値はサンプルです
最も基本となるクエリで、URIパターンに対するHTTPリクエストの数を追跡します。このクエリは、時間範囲内でのリクエスト数の増減を示し、トレンド分析に役立ちます。
sum(
increase(
http_server_requests_seconds_count{
uri=~”/foo”, method=“POST”, status=“200”
}[$__range]
)
) or vector(0)
- sum(...): 集計関数で、結果を合計します。ここでは、条件を満たすリクエストの総数を計算しています。
- increase(...): 時間範囲でのメトリックの増加量を計算します。リクエスト数の増減を捉えることができます。
- vector(0): 結果がない場合に0を返します。データがなくてもダッシュボードに表示するためのものです。
1時間ごとの申込数の計測
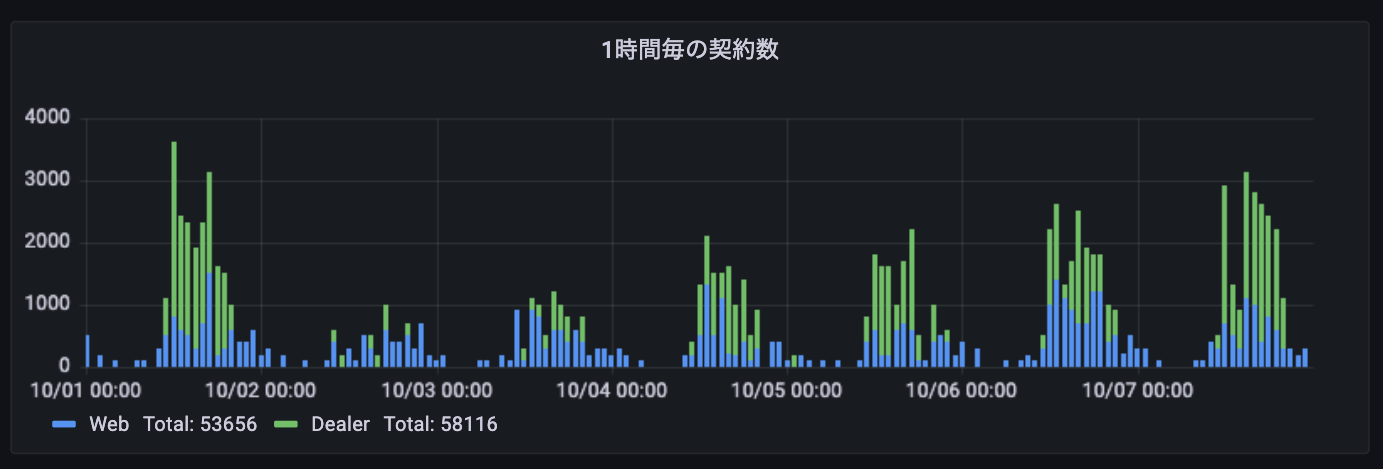
時間帯別契約数(サンプル) #夜はお眠り
APIリクエストの監視のPromQLを活用して1時間ごとにリクエスト数を計測し、時間帯による需要の変化を把握します。時間帯に応じて動的にリソースを割り当てるなどの参考データとして使います。
最も時間がかかるリクエストの特定
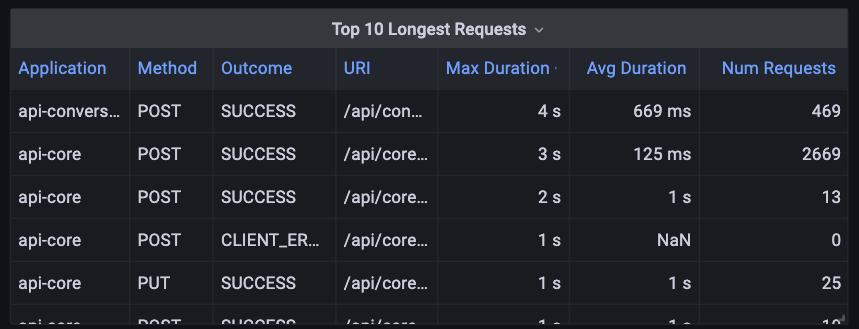
4秒以上かかるものもあります
パフォーマンス分析において、時間がかかるリクエストを特定することは、システムのボトルネックを見つける上で重要です。以下のPromQLクエリは、この目的を達成するのに役立ちます。
- 平均応答時間の計算
各リクエストの平均応答時間を計算します。応答時間の合計とリクエスト数をそれぞれ求め、その後これらの数値を使って割り算を行います。
sum by(application, uri, outcome, method) (
increase(http_server_requests_seconds_sum[$__range])
)
/
sum by(application, uri, outcome, method) (
increase(http_server_requests_seconds_count[$__range])
)
- sum by(...): ラベル(ここではapplication, uri, outcome, method)に基づいて結果をグループ化し、それぞれのグループの合計を計算します。
- increase(...): 時間範囲($__range)内でのメトリックの増加量を計算します。ここでは、応答時間の合計とリクエスト数を計算しています。
- リクエスト数の集計
リクエスト数を集計します。
sum by(application, uri, outcome, method) (
increase(http_server_requests_seconds_count[$__range])
)
- 最も長い応答時間を持つリクエストの特定
時間範囲内で最も応答時間が長かった上位10のリクエストを特定します。
topk(
10,
max(
max_over_time(http_server_requests_seconds_max[$__range])
) by(application, uri, outcome, method)
)
- topk(10, ...): 最も大きい値を持つ上位10の要素を返します。ここでは、最も応答時間が長かったリクエストのトップ10にしています。
- max(...): 各グループの最大値を計算します。
- max_over_time(...): 時間範囲内で各メトリックの最大値を計算し、ラベルで結果をグループ化します。これにより、応答時間が最も長かったリクエストを抽出できます。
クライアント側のエラーの監視
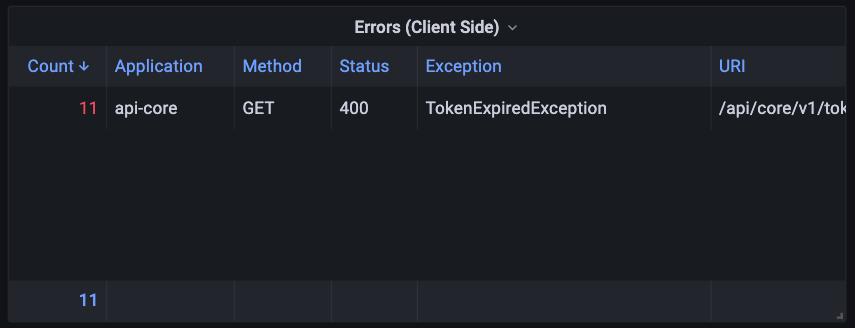
認証トークンの期限切れ
クライアント側で発生するエラーを監視し、原因を分析します。
label_replace(
sum by (application, method, uri, exception, status) (
increase(http_server_requests_seconds_count{
status=~”5..|4..”, exception!~”None|FooException”
}[$__range]
)
) > 0, ‘uri’, ‘$1/*$2’, ‘uri’, ‘(.*)\\/\\{.+\\}(.*)’
- label_replace(...): ラベルを変更または追加を行います。
- '> 0': 合計された値が0より大きい場合に結果を返します。つまり、エラーが発生している場合のみデータを表示します。
Grafana導入のメリットと実践事例
新車サブスク開発グループがGrafanaを活用し、どのようにシステム監視の質を向上させたかを詳しくお話しします。
- 包括的なシステムの可視化: AWS Managed Grafanaを使うことで、私たちはAWSサービス(RDS、SQS、Lambda、CloudFrontなど)からのデータと、アプリケーションのメトリクスを同時に可視化できるようになりました。これは、システム全体のパフォーマンスやボトルネックを一目で把握できることを意味し、問題解決へのアプローチが大幅に加速されました。
- 効率的なデータ分析とトラブルシューティング: 異なるデータソースを統合することで、問題発生時に必要な情報をすばやく取得できます。これにより、問題の根本原因を迅速に特定し、効率的な対応が可能になりました。
- APIの監視: Grafanaを通じて、特定のExceptionが異常に多発していることを発見しました。調査結果、フロントエンドで想定外のAPIが呼ばれていることが判明。この問題をフロントエンドチームへ伝え、修正を行った結果、APIの効率が向上し、システムの全体的な安定性とパフォーマンスが大きく改善されました。
さいごに
Observabilityは、ただシステムを見ること以上の意味を持ちます。それは、システムの健全性を保ち、問題が生じた際に迅速に対処できるようにするためのキーです。Grafanaの活用により、我々は複雑なデータを簡単に理解し、システム全体のパフォーマンスを効果的に管理できるようになりました。APIリクエストの監視からエラーの特定まで、Grafanaは多様なニーズに対応しています。
これは、SREや開発者に限らず、全てのチームメンバーが協力して取り組む価値があります。結局のところ、システムの透明性と信頼性の向上は、より良いサービスを提供し、お客様の満足度を高めるために不可欠です。
我々の経験が、皆さんの業務において新たな視点を提供し、より効率的なシステム監視とパフォーマンス最適化の手助けになれば幸いです。
E2E (End-to-End):システムやプロセスが最初から最後まで完全に連携して機能すること ↩︎
関連記事 | Related Posts
BEエンジニア視点のGrafanaによるObservabilityの実践
Getting Started with Prometheus, Grafana, and X-Ray for Observability (O11y)

Building Cloud-Native Microservices with Kotlin/Ktor (Observability Edition)

From Words to Worlds: The Magic of Amazon QuickSight Generative BI

KINTO ONE Operation: Preparations for the Launch of the New Prius

ChatGPT (GPT-4) Advanced Data Analysis (formerly Code Interpreter), how to output graphs, images, and PDF files with Japanese fonts to analyze X (formerly Twitter)
We are hiring!
ビジネスアナリスト(マーケティング/事業分析)/分析プロデュースG/東京・大阪・福岡
デジタル戦略部 分析プロデュースグループについて本グループは、『KINTO』において経営注力のもと立ち上げられた分析組織です。決まった正解が少ない環境の中で、「なぜ」を起点に事業と向き合い、分析を軸に意思決定を前に進める役割を担っています。
【データサイエンティスト】データサイエンスG/東京・名古屋・福岡
デジタル戦略部についてデジタル戦略部は、現在45名の組織です。
イベント情報
![[Mirror]不確実な事業環境を突破した、成長企業6社独自のエンジニアリング](/assets/banners/thumb1.png)

