KINTO FACTORY ローンチ半年記念:挑戦と学びの軌跡

はじめに
こんにちは、KINTO FACTORY のバックエンドエンジニアをしている西田です。
KINTO FACTORY をローンチして早いもので半年が経ったので、サービス運用を開始してからリリースやシステム監視を中心に遭遇した課題や、私たちが学んだことをみなさんと共有したいと思います。
KINTO FACTORY について
はじめに KINTO FACTORY のサービス概要を少しだけ。
お乗りのクルマに適合するハードウェア・ソフトウェアといった機能やアイテムをアップデートできるサービスとなります。
これまでのクルマのアップデートはディーラーでの作業が必要であったり、いわゆるメーカーオプションのような注文時にしか選択できないアイテムを KINTO FACTORY ではウェブ上から申込みができます。
また、KINTO 契約車両だけでなくトヨタ/レクサス/GRのクルマが対象となっており、適合するクルマであればアップデートを行うことができます。
今年の夏にローンチし、半年が経過しようとしています。
運用について
リリースは2週間に1回のペースで行い、GitHub Actions をメインに CI/CD を構築してデプロイしています。
サービスの監視は、運用チームといった専用の組織を設けずに開発メンバーが中心となり、当番を回して運用をしています。
ローテーションは PagerDuty のスケジュール機能を利用しています。

また、インシデントの検知は次のようなイメージで構成されています。
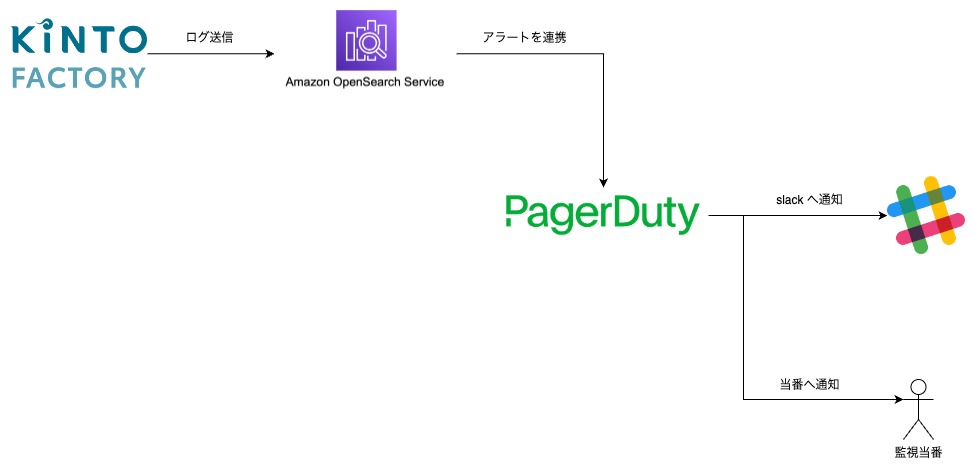
アプリケーションログやサービス監視の情報を OpenSearch に連携し、ユーザー影響を判断して PagerDuty に通知が行われます。(画像は対応完了後のものです)
その後 Slack にも通知がされることで監視当番が対応を行います。
基本的には担当者が対応しますが、必要に応じて有識者を巻き込んで対応をするようにしています。
また、対応者だけでなくチームとして把握ができるように翌日のデイリースクラムで対応内容を共有しています。
課題と対応
運用を始めてから遭遇した課題と、それをどのように対応したかを共有します。
リリース準備の負担が大きい
テンプレート化されていないこともありリリースのたびにデプロイのための準備を1から行っていて、粒度も統一されておらず時間がかかっていました。
中でもリリース手順書周りは Confluence ベースで管理していて、手順の確認や修正が煩雑でした。
⇒ リリース手順書をコード管理へ移行することで、バージョン管理やテンプレート化、差分確認をできるようにすることで、リリース準備の負担を軽減することができました。
インシデント検知が多発
ローンチ後、数日間のインシデントの件数が↓の通りで
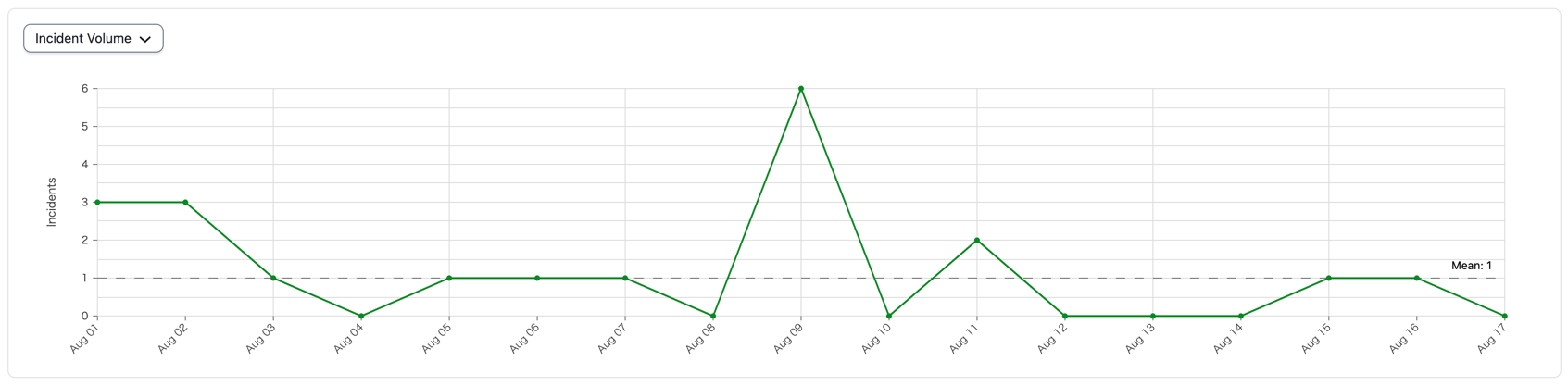
アプリケーション側のエラーハンドリング設計が甘かったため、ユーザー影響がないものであってもクリティカル扱いとして検知され、運用開始後は毎日のようにインシデントが発生し監視の負荷が大変なことに...
⇒ 対応するには数が多く一括で対応が難しかったため、緊急度が高くないものは出力を見直すように修正、修正がすぐできない場合は通知されないように除外設定を組み込んで最適化を図りました。
インシデント対応の初動に時間がかかる
対応フローの手順などが整っていなかったためメンバーによって認識の差があり、対処に時間がかかってしまう場面がありました。
PagerDuty の操作に慣れていないこともあり確認済みステータスへの更新が漏れてたりも。。。
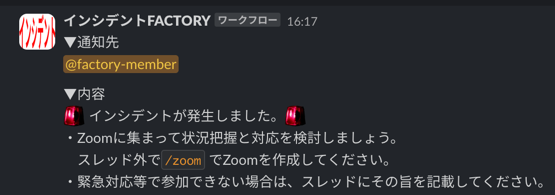
⇒ Slack でワークフローを定義して、コマンド入力でインシデント対応を開始して手順に沿って対応が進められるように環境を整えて改善を図りました。
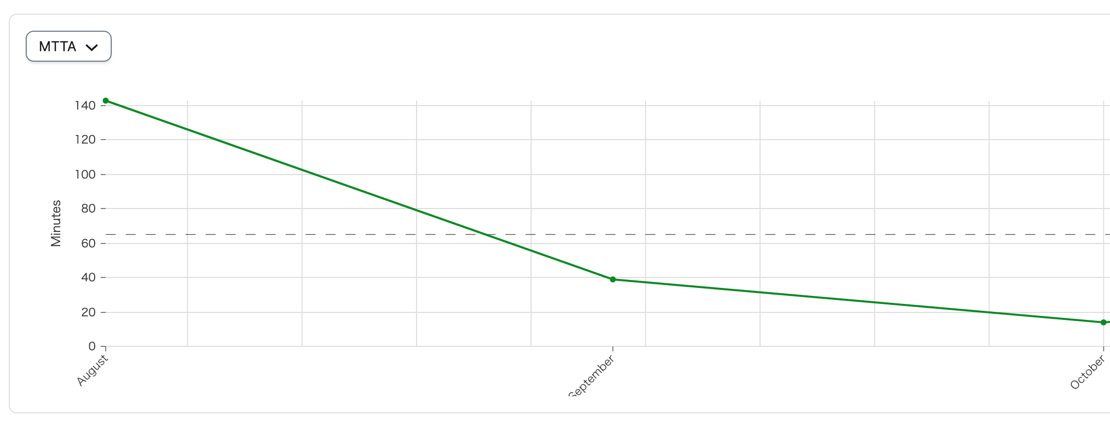
また、インシデントVSチームという構図になるようにまずは全員が集まって対応をモブ作業として行い、認識を擦り合わせながら対応をすることで、アラートが発火してから対応開始するまでの時間を1/10以下に短縮することができました。
まとめ
ローンチ直後は色んな課題が起きてバタバタな日々を過ごしていましたが、継続的に改善を行うことで少しずつ改善されてきました。
あらためてふりかえるとメンバーの経験値や知識による対応の差があったため、事前にどういった運用をしていくのかをきちんと整理しながら運用を開始することで、立ち上がりもスムーズにできたのかなと実感しました。
まだまだ改善の余地はありますが、これからもユーザーにとってより良いサービスを提供できるように運用を継続していきます!
さいごに
今回はサービス運用で遭遇した課題とその対応を共有しました。
私たちの経験が何かの参考になれば嬉しいです。
また、KINTO FACTORY では新たな仲間を募集していますので、ご興味があればぜひ下記の求人をチェックしてみてください!
関連記事 | Related Posts



We are hiring!
【シニアソフトウェアエンジニア】業務システムG/東京
業務システムグループについて TOYOTAのクルマのサブスクリプションサービスである『 KINTO 』を中心とした国内向けサービスのプロジェクト立ち上げから運用保守に至るまでの運営管理を行っています。
【PdM】オープンポジション/東京・名古屋・大阪
募集背景KINTOテクノロジーズでは新たな事業展開と共に開発するプロダクトが拡大しています。サービスの新規立ち上げ、立ち上げたプロダクトのグロースを推進し、KINTOの事業展開を支えるプロダクトマネージャーを求めています。

