8 min read
DataAnalytics
Building a Speedy Analytics Platform with Auto-Expansion ETL Using AWS Glue

My name is Nakagawa, and I am the team leader of the data engineering team in the analysis group at KINTO Technologies. Recently, I have become interested in golf and have started to pay attention to the cost per ball. My goal this year is to make my course debut!
In this article, we would like to introduce the efforts of our data engineering team in efficiently developing KINTO's analytics platform and providing the data necessary for analysis in line with service launches.
Data Engineering Team’s Goal
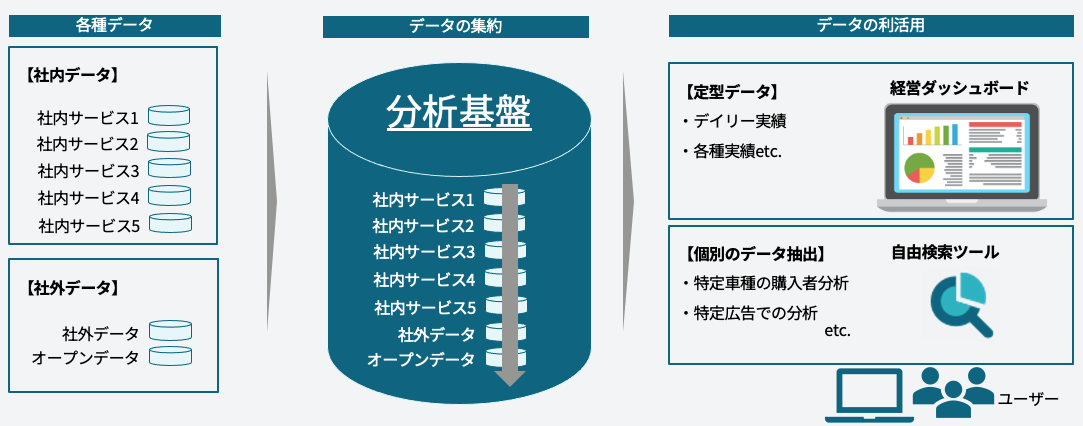
The data engineering team develops and operates an analytics platform. An analytics platform plays a behind-the-scenes role that involves collecting and storing data from internal and external systems, and providing it in a form that can be utilized for business. Our goal is as follows so that data can be utilized immediately upon the launch of services:
__ "In line with the launch of various services, we will aggregate data on our analytics platform and provide it immediately!"__
Challenges
However, with the expansion of the KINTO business and while we set the above-mentioned roles and goals, the following challenges have arisen.
- Limited development resources (as we are a small, elite team)
- An increase in systems to be linked due to business expansion
- An increase in modifications is proportional to an increase in the number of linked systems. (Note: The increase in modifications is also influenced by our agile business style of "starting small and growing big.")
Solutions
To solve the above challenges, we use AWS Glue for ETL. From the perspective of reducing workloads, we have focused on two aspects―operations and development. We have approached the challenges using the following methods.
- Standardization aimed at no-code
- Automatic column expansion for a faster, more flexible analytics platform
Our company’s AWS Analytics Platform Environment
Before explaining the two proposed improvements, I would like to explain our analytics platform environment. Our analytics platform uses AWS Glue for ETL and Amazon Athena for the database. In the simplest pattern, its structure is as shown in the diagram below. The structure involves loading data from source tables, accumulating raw data in a data lake in chronological order, and storing it in a data warehouse for utilization. 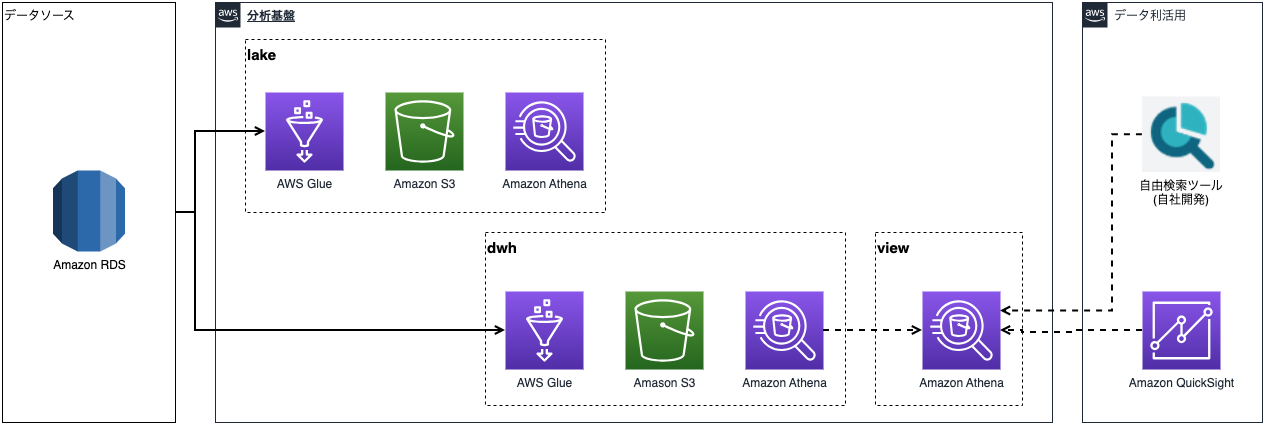
When developing workflows and jobs for data linkage using AWS Glue, KINTO Technologies use CloudFormation to deploy a series of resources, including workflows, triggers, jobs, data catalogs, Python, PySpark, and SQL. The main resources required for deployment are as follows:
- YAML file (workflow, job, trigger, and other configuration information)
- Python shell (for job execution)
- SQL file (for job execution)
As mentioned above, the development work workloads increased in proportion to an increase in services, tables and columns. This began to strain our development resources. As described in the previous solutions, we addressed the challenges by implementing two main improvements. I would like to introduce the methods we used.
Standardization aimed at no-code
"Standardization aimed at no-code" was carried out in the following steps.
- Step 1 in 2022: Standardization of Python programs
- Step 2 in 2023: Automatic generation of YAML and SQL files
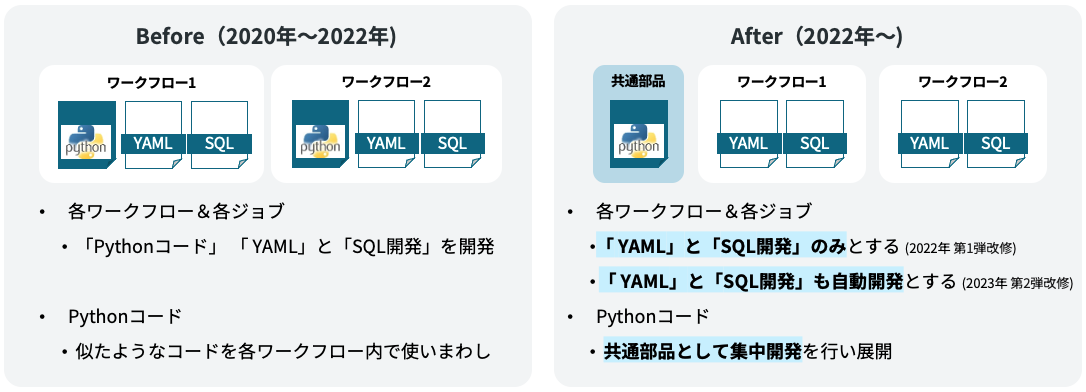 In the improvement related to Python shell in Step 1, we focused on the fact that, up until now, workflow development was performed on a per-service basis, and the Python shell was also developed, tested, and reviewed on a per-workflow basis. This approach led to an increase in workloads. We moved forward with program standardization by unifying parts of the code that had been reused with slight modifications across different workflows, and by making them more general-purpose to accommodate variations in data sources. As a result, while we are currently focusing on intensive development and review of the common code, there is no longer any need to develop source code for each workflow. If the data source is Amazon RDS or BigQuery, all processing, including data type conversion to Amazon Athena, can now be handled within the standardized part. Therefore, when starting data linkage for each service, it is now possible to achieve no-code data linkage by simply writing settings in a configuration file.
In the improvement related to Python shell in Step 1, we focused on the fact that, up until now, workflow development was performed on a per-service basis, and the Python shell was also developed, tested, and reviewed on a per-workflow basis. This approach led to an increase in workloads. We moved forward with program standardization by unifying parts of the code that had been reused with slight modifications across different workflows, and by making them more general-purpose to accommodate variations in data sources. As a result, while we are currently focusing on intensive development and review of the common code, there is no longer any need to develop source code for each workflow. If the data source is Amazon RDS or BigQuery, all processing, including data type conversion to Amazon Athena, can now be handled within the standardized part. Therefore, when starting data linkage for each service, it is now possible to achieve no-code data linkage by simply writing settings in a configuration file.
Step 2, the automatic generation of YAML and SQL files, improves the configuration files that remained as necessary parts in Step 1, as well as View definitions required for linkage with the source side. We improved these by using GAS (Google Apps Script) to automatically generate configuration files such as YAML and SQL for the View. This minimizes the development work by simply setting the minimal necessary definitions, such as workflow ID and table names that need to be linked, on a Google Spreadsheet, which automatically generates YAML files for configuration and SQL files for the View.
Automatic column expansion for a faster, more flexible analytics platform
In "Automatic Column Expansion for a Faster, More Flexible Analytics Platform," before the improvement, table definitions and item definitions that have been already defined at the data linkage source had been also defined on the analytics platform side in YAML.[1] Therefore, at the time of initial establishment, it was necessary to define as many items on the analytics platform side as on the data linkage source side, resulting in a need for approximately 800 to 1,200 item definitions per service on average (20 to 30 tables × 20 items × both lake and DWH). Our company is constantly expanding its services based on the philosophy of “starting small and growing big,” which frequently results in backend database updates. This update process also requires carefully identifying and modifying relevant portions from among the previously set 800 to 1,200 definition items, which has significantly increased development workloads.
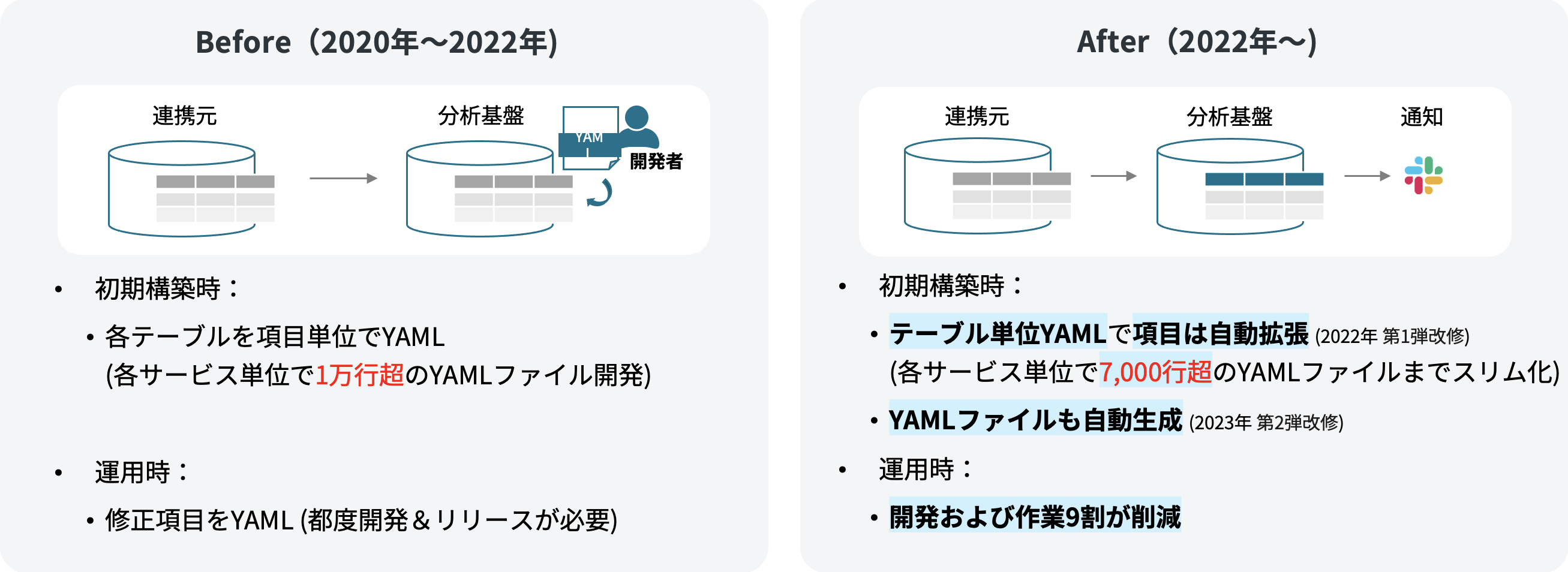 So what we came up with was a method in which, when accessing the data linkage source for data linkage, the item definition information is also linked at the same time, allowing automatic updates of the item definitions on the analytics platform. The idea is that since the properly developed information is already present on the source side, there is no reason not to take advantage of it!
So what we came up with was a method in which, when accessing the data linkage source for data linkage, the item definition information is also linked at the same time, allowing automatic updates of the item definitions on the analytics platform. The idea is that since the properly developed information is already present on the source side, there is no reason not to take advantage of it!
The specific implementation method for column auto-expansion is carried out using the following steps.
glue_client.get_tableRetrieve table information from the AWS Glue Data Catalog.- Replace
table['Table']['StorageDescriptor']['Columns']with the item listcol_listobtained from the data linkage source. - Update AWS Glue's Data Catalog with
glue_client.update_table.
def update_schema_in_data_catalog(glue_client: boto3.client, database_name: str,
table_name: str, col_list: list) -> None:
"""
Args:
glue_client (boto3.client): Glue client
database_name (str): Databse naem
table_name (str): Table name
col_list (list): Column list of dictionary
"""
#AWS Glueのデータカタログからテーブル情報を取得
table = glue_client.get_table(
DatabaseName = database_name,
Name = table_name
)
#col_listでColumnsを置換え
data = table['Table']
data['StorageDescriptor']['Columns'] = col_list
tableInput = {
'Name': table_name,
'Description': data.get('Description', ''),
'Retention': data.get('Retention', None),
'StorageDescriptor': data.get('StorageDescriptor', None),
'PartitionKeys': data.get('PartitionKeys', []),
'TableType': data.get('TableType', ''),
'Parameters': data.get('Parameters', None)
}
#AWS Glueのデータカタログを更新
glue_client.update_table(
DatabaseName = database_name,
TableInput = tableInput
)
In addition to these, when creating an item list obtained from the linkage source, we also perform mapping of different data types for each database in the background. By doing so, we can generate item definitions on the analytics platform based on the schema information from the source side.
One point we paid attention to with the automatic updating of item definitions on the analytics platform side is that the table structure of the analytics platform under our management could change unexpectedly without our knowledge. To address this concern, we have implemented a system that sends a “notification” to Slack whenever a change occurs. By doing this, we can prevent the issue of the table structure changing unexpectedly without our knowledge. The system detects changes, and after checking the changes with the source system, linkage of the changes to subsequent systems as needed is possible.
Conclusion
What are your thoughts? This time, I have introduced two methods of using AWS Glue in our analytics platform: “standardization aimed at no-code” and “automatic column expansion for faster, more flexible analytics platform.” By improving these two points, we have succeeded in reducing the development workloads. Now, even for a data linkage job involving 40 tables, the development workloads can be reduced to about one person-day, which has enabled us to achieve our goal of "aggregating data into the analytics platform and providing it immediately in line with the launch of various services!" I hope this will serve as a useful reference for those who wish to reduce development workloads in a similar way!
I won’t go into details here, but AWS Glue includes a crawler that updates the data catalog. However, due to issues such as the inability to update with sample data or perform error analysis, we have decided not to use it. ↩︎




