約39分で読めます
SRE
Slothを使って楽にSLO監視をした話

自己紹介
こんにちは。KINTOテクノロジーズ株式会社(以降、KINTOテクノロジーズ)のPlatform Group/SRE Teamに所属している渡辺宇と申します。WEBサービスのアプリケーション開発・インフラ構築・CI/CD構築・保守運用をしてきた経験を活かして、自社サービスの信頼性向上をサポートしています。
はじめに
どんな優れたサービスでも、全く問題が発生しないという状態は現実的には存在しません。そのため、予めどれくらいの問題が発生しても許容範囲内であるかという目標を設定し、場合によってはこれをユーザーと共有し、合意を形成することが現代のサービス提供において重要な考え方となっています。
具体的には、Service Level Indicator(以降、SLI)を用いてサービスレベルの指標を定義し、Service Level Objective(以降、SLO)でその目標値を設定します。そして、Service Level Agreement(以降、SLA)を通じて、これらの目標値についてユーザーと合意を取ります。
SLOを設定したら次のステップは、目標違反が発生していないか監視することです。違反が発生した場合にはアラートを発信する必要があります。しかし、アラートを発信するルールは煩雑で、管理が困難になりがちです。
その問題を解決するために、今回の記事ではSlothというアラートルールのジェネレータを用いたアラートルールの生成と管理の効率化について紹介します。
背景
私たちKINTOテクノロジーズでは、以前に紹介した通り、「Prometheus + Grafana + X-Ray」のスタックを用いてテレメトリデータの取得を実現し、リクエスト・レスポンス型のWEBサービスの可観測性(Observability)を向上させています。
この取り組みのおかげで、特に、Spring Bootのアプリケーションメトリクスについては、アプリケーションコード上で特別に計装することなく、多様なメトリクスをPrometheusに格納できています。
格納されたメトリクスの中には、リクエスト単位の成功・失敗ステータスや応答速度のデータも含まれています。これにより、PromQLを用いて、可用性やレイテンシのSLIを表現することが可能になりました。
課題
一般的に、WEBサービスのCUJ(Critical User Journey)に対してSLI/SLOの定義をした後、本番サービスのエラーバジェットの消費状況を監視します。その際、SLO/SLA違反が発生しそうな場合は適切なタイミングでそれを検知する必要があります。そのためには、開発担当者が異変を検知できるように、アラートを設定しておく必要があります。
サイトリライアビリティワークブックでは、SLO違反の検知には「複数ウィンドウ、複数バーンレートのアラート(Multiwindow, Multi-Burn-Rate Alerts)」の手法が、最も現実的でおすすめできると書かれています。適合率・再現率・検出時間・リセット時間をうまくコントロールできるメリットがある、とのことなので積極的に使いたいです。
ウィンドウとバーンレートについて簡単に説明します:
- ウィンドウ
- 計測期間のことを指します。どの時点で計測を開始し、どの時点で計測を終了するかの期間です。SLOは比率で表現されるため、計測期間が終わると次の計測期間開始時にサービスレベルは100%に回復します。一般的に、ウィンドウサイズが大きいほど、アラートは発しにくく、かつ、終了しにくくなります。
- バーンレート
- エラーバジェットの消費速度のことを指します。エラーバジェットを全て消費してからアラートが発せられると遅いので、エラーバジェットがある程度消費された時点でアラートを発することが理想的です。“サービスのSLOに紐付くエラーバジェットがウィンドウの終わりにちょうど0になるようなバーンレート”を1(基準)とし、それと比較して何倍の速さでエラーバジェットが消費されているのかを計算し、その結果(基準と比べて何倍か)をバーンレートとして数値で保持します。バーンレートが事前に定められた値を超えた時にアラートが発せられるように設定します。
「複数ウィンドウ、複数バーンレートのアラート」について詳しく知りたい方は、サイトリライアビリティワークブックの5章「SLOに基づくアラート」をご覧ください。 英語版はWebで公開されています:
「複数ウィンドウ、複数バーンレートのアラート」の手法を利用するには、1つのSLI/SLO定義に対して複数のウィンドウとバーンレート、つまり、複数の異なるパラメータを指定したアラートルールを設定する必要があります。
よって、アラートルールの数が増えるため、アラートルールの管理が難しくなるという課題がありました。
やること
今回の記事では、Slothというオープンソースツールを活用して、この課題を解決していきます。
Slothを利用すると、シンプルな記述でSLI/SLOの仕様を入力し、それをもとに、複雑でエラーになりやすいPrometheusの記録ルールやアラートルール定義ファイルを生成することが可能となります。
私たちKINTOテクノロジーズでは、下図のような構成を採用しています。
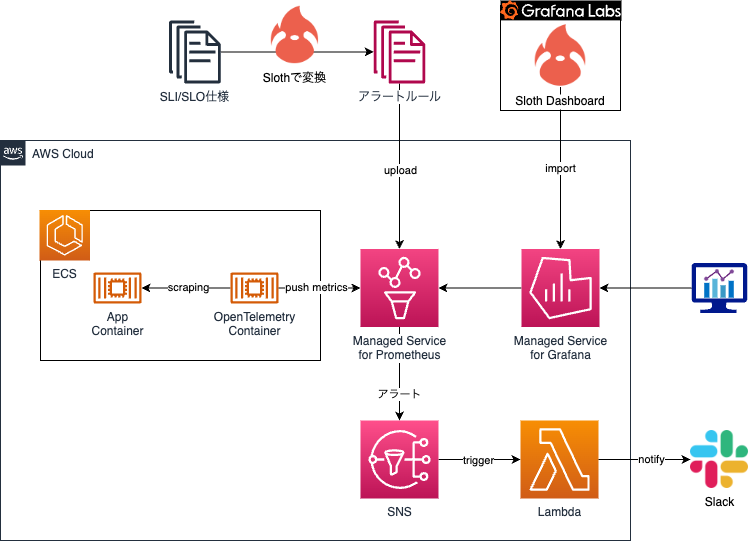
Slothには、デフォルトで複数ウィンドウ、複数バーンレートのアラートルールを生成する機能が備わっています。そのため、この記事ではSlothを使って「複数ウィンドウ、複数バーンレートのアラート」の設定をする方法を紹介します。
アラートルール生成
次の簡単なSLI/SLO仕様を、Slothの規格に基づいたYAMLファイルで表現してみます。
| Category | SLI | SLO |
|---|---|---|
| Availability | 30日のうち、アプリケーションで測定される成功したリクエストの割合。500~599と429以外のHTTPステータスは成功とみなします。actuator以外の全てのリクエストパスを統合して計測します。 | 99.5% |
version: "prometheus/v1"
service: "KINTO"
labels:
owner: "KINTO Technologies Corporation"
repo: "slo-maintenance"
tier: "2"
slos:
# We allow failing (5xx and 429) 5 request every 1000 requests (99.5%).
- name: "kinto-requests-availability"
objective: 99.5
description: "Common SLO based on availability for HTTP request responses."
sli:
events:
error_query: sum(rate(http_server_requests_seconds_count{application="kinto",status=~"(5..|429)",uri!~".*actuator.*"}[{{.window}}]))
total_query: sum(rate(http_server_requests_seconds_count{application="kinto",uri!~".*actuator.*"}[{{.window}}]))
alerting:
name: KINTOHighErrorRate
labels:
category: "availability"
annotations:
# Overwrite default Sloth SLO alert summmary on ticket and page alerts.
summary: "High error rate on 'KINTO SERVICE' requests responses"
page_alert:
labels:
severity: "critical"
ticket_alert:
labels:
severity: "warning"
http_server_requests_seconds_countはSpring Bootを使った場合のメトリクスです。
このファイルを./source/ディレクトリに保存した状態で、次のコマンドを実行します。
docker pull ghcr.io/slok/sloth
docker run -v /$(pwd):/home ghcr.io/slok/sloth generate -i /home/source/slo_spec.yml > slo_generated_rules.yml
上記のコマンドを実行すると、カレントディレクトリに下記のファイルが生成されます。生成されたファイルはそのままPrometheusにアップロードできます。
slo_generate_rules.yml
---
# Code generated by Sloth (a9d9dc42fb66372fb1bd2c69ca354da4ace51b65): https://github.com/slok/sloth.
# DO NOT EDIT.
groups:
- name: sloth-slo-sli-recordings-KINTO-kinto-requests-availability
rules:
- record: slo:sli_error:ratio_rate5m
expr: |
(sum(rate(http_server_requests_seconds_count{application="kinto",status=~"(5..|429)",uri!~".*actuator.*"}[5m])))
/
(sum(rate(http_server_requests_seconds_count{application="kinto",uri!~".*actuator.*"}[5m])))
labels:
owner: KINTO Technologies Corporation
repo: slo-maintenance
sloth_id: KINTO-kinto-requests-availability
sloth_service: KINTO
sloth_slo: kinto-requests-availability
sloth_window: 5m
tier: "2"
- record: slo:sli_error:ratio_rate30m
expr: |
(sum(rate(http_server_requests_seconds_count{application="kinto",status=~"(5..|429)",uri!~".*actuator.*"}[30m])))
/
(sum(rate(http_server_requests_seconds_count{application="kinto",uri!~".*actuator.*"}[30m])))
labels:
owner: KINTO Technologies Corporation
repo: slo-maintenance
sloth_id: KINTO-kinto-requests-availability
sloth_service: KINTO
sloth_slo: kinto-requests-availability
sloth_window: 30m
tier: "2"
- record: slo:sli_error:ratio_rate1h
expr: |
(sum(rate(http_server_requests_seconds_count{application="kinto",status=~"(5..|429)",uri!~".*actuator.*"}[1h])))
/
(sum(rate(http_server_requests_seconds_count{application="kinto",uri!~".*actuator.*"}[1h])))
labels:
owner: KINTO Technologies Corporation
repo: slo-maintenance
sloth_id: KINTO-kinto-requests-availability
sloth_service: KINTO
sloth_slo: kinto-requests-availability
sloth_window: 1h
tier: "2"
- record: slo:sli_error:ratio_rate2h
expr: |
(sum(rate(http_server_requests_seconds_count{application="kinto",status=~"(5..|429)",uri!~".*actuator.*"}[2h])))
/
(sum(rate(http_server_requests_seconds_count{application="kinto",uri!~".*actuator.*"}[2h])))
labels:
owner: KINTO Technologies Corporation
repo: slo-maintenance
sloth_id: KINTO-kinto-requests-availability
sloth_service: KINTO
sloth_slo: kinto-requests-availability
sloth_window: 2h
tier: "2"
- record: slo:sli_error:ratio_rate6h
expr: |
(sum(rate(http_server_requests_seconds_count{application="kinto",status=~"(5..|429)",uri!~".*actuator.*"}[6h])))
/
(sum(rate(http_server_requests_seconds_count{application="kinto",uri!~".*actuator.*"}[6h])))
labels:
owner: KINTO Technologies Corporation
repo: slo-maintenance
sloth_id: KINTO-kinto-requests-availability
sloth_service: KINTO
sloth_slo: kinto-requests-availability
sloth_window: 6h
tier: "2"
- record: slo:sli_error:ratio_rate1d
expr: |
(sum(rate(http_server_requests_seconds_count{application="kinto",status=~"(5..|429)",uri!~".*actuator.*"}[1d])))
/
(sum(rate(http_server_requests_seconds_count{application="kinto",uri!~".*actuator.*"}[1d])))
labels:
owner: KINTO Technologies Corporation
repo: slo-maintenance
sloth_id: KINTO-kinto-requests-availability
sloth_service: KINTO
sloth_slo: kinto-requests-availability
sloth_window: 1d
tier: "2"
- record: slo:sli_error:ratio_rate3d
expr: |
(sum(rate(http_server_requests_seconds_count{application="kinto",status=~"(5..|429)",uri!~".*actuator.*"}[3d])))
/
(sum(rate(http_server_requests_seconds_count{application="kinto",uri!~".*actuator.*"}[3d])))
labels:
owner: KINTO Technologies Corporation
repo: slo-maintenance
sloth_id: KINTO-kinto-requests-availability
sloth_service: KINTO
sloth_slo: kinto-requests-availability
sloth_window: 3d
tier: "2"
- record: slo:sli_error:ratio_rate30d
expr: |
sum_over_time(slo:sli_error:ratio_rate5m{sloth_id="KINTO-kinto-requests-availability", sloth_service="KINTO", sloth_slo="kinto-requests-availability"}[30d])
/ ignoring (sloth_window)
count_over_time(slo:sli_error:ratio_rate5m{sloth_id="KINTO-kinto-requests-availability", sloth_service="KINTO", sloth_slo="kinto-requests-availability"}[30d])
labels:
owner: KINTO Technologies Corporation
repo: slo-maintenance
sloth_id: KINTO-kinto-requests-availability
sloth_service: KINTO
sloth_slo: kinto-requests-availability
sloth_window: 30d
tier: "2"
- name: sloth-slo-meta-recordings-KINTO-kinto-requests-availability
rules:
- record: slo:objective:ratio
expr: vector(0.995)
labels:
owner: KINTO Technologies Corporation
repo: slo-maintenance
sloth_id: KINTO-kinto-requests-availability
sloth_service: KINTO
sloth_slo: kinto-requests-availability
tier: "2"
- record: slo:error_budget:ratio
expr: vector(1-0.995)
labels:
owner: KINTO Technologies Corporation
repo: slo-maintenance
sloth_id: KINTO-kinto-requests-availability
sloth_service: KINTO
sloth_slo: kinto-requests-availability
tier: "2"
- record: slo:time_period:days
expr: vector(30)
labels:
owner: KINTO Technologies Corporation
repo: slo-maintenance
sloth_id: KINTO-kinto-requests-availability
sloth_service: KINTO
sloth_slo: kinto-requests-availability
tier: "2"
- record: slo:current_burn_rate:ratio
expr: |
slo:sli_error:ratio_rate5m{sloth_id="KINTO-kinto-requests-availability", sloth_service="KINTO", sloth_slo="kinto-requests-availability"}
/ on(sloth_id, sloth_slo, sloth_service) group_left
slo:error_budget:ratio{sloth_id="KINTO-kinto-requests-availability", sloth_service="KINTO", sloth_slo="kinto-requests-availability"}
labels:
owner: KINTO Technologies Corporation
repo: slo-maintenance
sloth_id: KINTO-kinto-requests-availability
sloth_service: KINTO
sloth_slo: kinto-requests-availability
tier: "2"
- record: slo:period_burn_rate:ratio
expr: |
slo:sli_error:ratio_rate30d{sloth_id="KINTO-kinto-requests-availability", sloth_service="KINTO", sloth_slo="kinto-requests-availability"}
/ on(sloth_id, sloth_slo, sloth_service) group_left
slo:error_budget:ratio{sloth_id="KINTO-kinto-requests-availability", sloth_service="KINTO", sloth_slo="kinto-requests-availability"}
labels:
owner: KINTO Technologies Corporation
repo: slo-maintenance
sloth_id: KINTO-kinto-requests-availability
sloth_service: KINTO
sloth_slo: kinto-requests-availability
tier: "2"
- record: slo:period_error_budget_remaining:ratio
expr: 1 - slo:period_burn_rate:ratio{sloth_id="KINTO-kinto-requests-availability",
sloth_service="KINTO", sloth_slo="kinto-requests-availability"}
labels:
owner: KINTO Technologies Corporation
repo: slo-maintenance
sloth_id: KINTO-kinto-requests-availability
sloth_service: KINTO
sloth_slo: kinto-requests-availability
tier: "2"
- record: sloth_slo_info
expr: vector(1)
labels:
owner: KINTO Technologies Corporation
repo: slo-maintenance
sloth_id: KINTO-kinto-requests-availability
sloth_mode: cli-gen-prom
sloth_objective: "99.5"
sloth_service: KINTO
sloth_slo: kinto-requests-availability
sloth_spec: prometheus/v1
sloth_version: a9d9dc42fb66372fb1bd2c69ca354da4ace51b65
tier: "2"
- name: sloth-slo-alerts-KINTO-kinto-requests-availability
rules:
- alert: KINTOHighErrorRate
expr: |
(
max(slo:sli_error:ratio_rate5m{sloth_id="KINTO-kinto-requests-availability", sloth_service="KINTO", sloth_slo="kinto-requests-availability"} > (14.4 * 0.005)) without (sloth_window)
and
max(slo:sli_error:ratio_rate1h{sloth_id="KINTO-kinto-requests-availability", sloth_service="KINTO", sloth_slo="kinto-requests-availability"} > (14.4 * 0.005)) without (sloth_window)
)
or
(
max(slo:sli_error:ratio_rate30m{sloth_id="KINTO-kinto-requests-availability", sloth_service="KINTO", sloth_slo="kinto-requests-availability"} > (6 * 0.005)) without (sloth_window)
and
max(slo:sli_error:ratio_rate6h{sloth_id="KINTO-kinto-requests-availability", sloth_service="KINTO", sloth_slo="kinto-requests-availability"} > (6 * 0.005)) without (sloth_window)
)
labels:
category: availability
severity: critical
sloth_severity: page
annotations:
summary: High error rate on 'KINTO SERVICE' requests responses
title: (page) {{$labels.sloth_service}} {{$labels.sloth_slo}} SLO error budget
burn rate is too fast.
- alert: KINTOHighErrorRate
expr: |
(
max(slo:sli_error:ratio_rate2h{sloth_id="KINTO-kinto-requests-availability", sloth_service="KINTO", sloth_slo="kinto-requests-availability"} > (3 * 0.005)) without (sloth_window)
and
max(slo:sli_error:ratio_rate1d{sloth_id="KINTO-kinto-requests-availability", sloth_service="KINTO", sloth_slo="kinto-requests-availability"} > (3 * 0.005)) without (sloth_window)
)
or
(
max(slo:sli_error:ratio_rate6h{sloth_id="KINTO-kinto-requests-availability", sloth_service="KINTO", sloth_slo="kinto-requests-availability"} > (1 * 0.005)) without (sloth_window)
and
max(slo:sli_error:ratio_rate3d{sloth_id="KINTO-kinto-requests-availability", sloth_service="KINTO", sloth_slo="kinto-requests-availability"} > (1 * 0.005)) without (sloth_window)
)
labels:
category: availability
severity: warning
sloth_severity: ticket
annotations:
summary: High error rate on 'KINTO SERVICE' requests responses
title: (ticket) {{$labels.sloth_service}} {{$labels.sloth_slo}} SLO error budget
burn rate is too fast.
今回は簡単な例を生成してみましたが、実際にはより複雑なSLI/SLO仕様を複数定義することになるでしょう。Slothを使用しない場合、生成されたような長いコードを直接管理する必要がありますが、Slothを活用すればその手間が大幅に軽減されます。
設定手順
私たちKINTOテクノロジーズでは、「Amazon Managed Service for Prometheus」を活用しています。そのため、AWSのマネージドコンソールを通じて生成ファイルのアップロードが可能です。
「Amazon Managed Service for Prometheus」の詳細な利用方法については公式ドキュメンテーションをご参照ください:
もしくは、AWS CLIをワークフローから実行することもできます。ここでは、GitHub Actionsを利用した例を示します。
name: SLO set up
on:
workflow_dispatch:
jobs:
setup-slo:
name: Set up SLOs
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- name: Set AWS Credentials to EnvParam(Common)
uses: aws-actions/configure-aws-credentials@v2
with:
aws-access-key-id: ${{ 利用するAWSのアクセスキー }}
aws-secret-access-key: ${{ 利用するAWSのシークレットアクセスキー }}
aws-region: ${{ 利用するAWSのリージョン }}
## 定義ファイルから設定ファイルを生成
- name: download and setup generator binary
run: |
## 適宜、最新のリリース状況を確認してください。
wget https://github.com/slok/sloth/releases/download/vX.XX.X/sloth-linux-amd64
chmod +x sloth-linux-amd64
./sloth-linux-amd64 validate -i ./services/kinto/source/slo_spec.yml
./sloth-linux-amd64 generate -i ./services/kinto/source/slo_spec.yml -o ./services/kinto/configuration.yml
## Prometheusに設定ファイルをアップロード
- name: upload configuration file to APM
run: |
base64 ./services/kinto/configuration.yml > ./services/kinto/configuration_base_64.yml
aws amp create-rule-groups-namespace \
--data file://./services/kinto/configuration_base_64.yml \
--name slo-rules \
--workspace-id ${{ 利用するAMPワークスペースのID }} \
--region ${{ 利用するAWSのリージョン }}
可視化
Prometheusへルールファイルのアップロードが完了したら、次に行うのはデータの可視化です。私たちは、Grafanaを使用しています。Slothには生成したルールを可視化するためのダッシュボードのテンプレートがGrafana Labsにあるため、これをインポートすることで可視化することができます。
アラート設定の手順
「複数ウィンドウ、複数バーンレートのアラート」は、Prometheusから送信されます。アラートマネージャーの設定ファイルを作成し、それをPrometheusにアップロードします。
私たちKINTOテクノロジーズでは、CriticalアラートとWarningアラートのルーティングを分けるため、次のような設定ファイルを作成しています。送信されるSNSアトリビュートには、アラートの種類情報を含めています。
alertmanager_config: |
# The root route on which each incoming alert enters.
route:
# A default receiver
receiver: warning_alert
routes:
- receiver: critical_alert
matchers:
- severity="critical"
- receiver: warning_alert
matchers:
- severity="warning"
# Amazon Managed Service for Prometheus,
# The only receiver currently supported is Amazon Simple Notification Service (Amazon SNS).
# If you have other types of receivers listed in the configuration, it will be rejected.
# Expect future revisions. https://docs.aws.amazon.com/ja_jp/prometheus/latest/userguide/AMP-alertmanager-config.html
receivers:
- name: critical_alert
sns_configs:
- topic_arn: arn:aws:sns:{AWS region}:{AWS account}:prometheus-alertmanager
sigv4:
region: {AWS region}
attributes:
severity: critical
slack_api_url: '<your slack api url>'
slack_channel: '#<your channel name>'
- name: warning_alert
sns_configs:
- topic_arn: arn:aws:sns:{AWS region}:{AWS account}:prometheus-alertmanager
sigv4:
region: {AWS region}
attributes:
severity: warning
slack_api_url: '<your slack api url>'
slack_channel: '#<your channel name>'
また、SNSトピックはAWS Lambdaで購読しています。Lambdaでは、トリガーとなったアトリビュートを利用し、Slackの通知先チャネルを動的に変更しています。実際には、Criticalアラートが発された場合にPagerDutyのAPIを叩くようにするなど、もっとカスタマイズします。
#
# this script based on https://aws.amazon.com/jp/premiumsupport/knowledge-center/sns-lambda-webhooks-chime-slack-teams/
#
import urllib3
import json
http = urllib3.PoolManager()
def lambda_handler(event, context):
print({"severity": event["Records"][0]["Sns"]["MessageAttributes"]["severity"]["Value"]})
url = event["Records"][0]["Sns"]["MessageAttributes"]["slack_api_url"]["Value"]
msg = {
"channel": event["Records"][0]["Sns"]["MessageAttributes"]["slack_channel"]["Value"],
"username": "PROMETHEUS_ALERTMANAGER",
"text": event["Records"][0]["Sns"]["Message"],
"icon_emoji": "",
}
encoded_msg = json.dumps(msg).encode("utf-8")
resp = http.request("POST", url, body=encoded_msg)
print(
{
"message": event["Records"][0]["Sns"]["Message"],
"status_code": resp.status,
"response": resp.data,
}
)
工夫した点
SLOs as Code
Slothを活用すれば、SLI/SLO仕様をYAMLファイル形式でコード化できます。これはコードなので、Gitなどを用いてバージョン管理することが可能です。また、GitHubなどのホスティングツールを利用することで、レビューしやすくなります。SLI/SLO仕様がPrometheusで対応可能なもの(PromQLで表現可能なもの)であれば、アプリケーションだけでなく、ロードバランサーや外形監視サービスなどのメトリクス監視にも適用できます。そのため、Slothの応用範囲は広いと言えます。
私たちKINTOテクノロジーズのSREチームでは、YAML形式のSLI/SLO仕様を一つのGitHubリポジトリに集約しています。SREチームはリポジトリにテンプレートを設け、開発チームはそのテンプレートに基づいてSLI/SLO仕様を定義し、それをコミットしプルリクエストを作成します。そしてSREチームはそのプルリクエストをレビューします。この流れで、SLI/SLO仕様の理解と監視への反映作業をスムーズに行うことができます。結果として管理コストが削減でき、KINTOテクノロジーズの開発組織全体であらゆるプロダクトのSLOが参照しやすくなります。
依存関係のサービスレベルは、自サービスのサービスレベルに大きく影響を与えます。KINTOテクノロジーズで開発されているサービスは、他のKINTOテクノロジーズ開発サービスとの依存関係にあるため、組織の垣根を越えてサービスレベルを共有することで、自サービスのサービスレベルを担保するのに役立ててもらいます。
LatencyのSLI
「遅さは新たなダウン」とも言われるため、5xx系エラーの有無だけでなく、レスポンスタイムについても監視が必要となります。
次の簡単なSLI/SLO仕様をSloth規格のYAMLファイルで表現してみます。
| Category | SLI | SLO |
|---|---|---|
| Latency | アプリケーションで測定される成功したリクエストの内、actuator以外の全てのリクエストパスを統合して計測します。30日のリクエストのうち、3000ミリ秒以内にレスポンスを返す比率。 | 99% |
version: "prometheus/v1"
service: "KINTO"
labels:
owner: "KINTO Technologies Corporation"
repo: "slo-maintenance"
tier: "2"
slos:
...
# We allow failing (less than 3000ms) and (5xx and 429) 990 request every 1000 requests (99%).
- name: "kinto-requests-latency-99percent-3000ms"
objective: 99
description: "Common SLO based on latency for HTTP request responses."
sli:
raw:
# Get the average satisfaction ratio and rest 1 (max good) to get the error ratio.
error_ratio_query: |
1 - (
sum(rate(http_server_requests_seconds_bucket{le="3",application="kinto",status!~"(5..|429)",uri!~".*actuator.*"}[{{.window}}]))
/
sum(rate(http_server_requests_seconds_count{application="kinto",status!~"(5..|429)",uri!~".*actuator.*"}[{{.window}}]))
)
alerting:
name: KINTOHighErrorRate
labels:
category: "latency"
annotations:
summary: "High error rate on 'kinto service' requests responses"
page_alert:
labels:
severity: "critical"
ticket_alert:
labels:
severity: "warning"
その際、ヒストグラムでデータを取得するため、application.ymlに次の設定を追加します。
management:
...
metrics:
tags:
application: ${spring.application.name}
distribution:
percentiles-histogram:
http:
server:
requests: true
slo:
http:
server:
requests: 100ms, 500ms, 3000ms
management.metrics.distribution以下の設定を追加することにより、summary型のpercentilesではなく、histogram型のpercentiles-histogramでメトリクスを取得するように設定しています。この理由として、percentilesは特定のパーセンタイルのレスポンスタイムをタスク単位で直近1分間のみ集計するので複数タスクでの集計ができず、30日間といった任意の範囲での集計もできないためです。これに対し、percentiles-histogramは閾値以内のレスポンスタイムだったリクエスト件数を値として保持するため、PromQLを用いて複数タスクを横断した任意の範囲での集計が可能です。
そうすることで、リクエスト件数と総件数との比率を用いて、LatencyのSLI仕様を表現しています。
議論
設定可能なSLOは94%以上推奨
サイトリライアビリティワークブックでは、エラーバジェットの消費率を検知したい場合に推奨されるウィンドウとバーンレートの閾値が定められています。
Slothは、デフォルトでサイトリライアビリティワークブックに記載の複数のバーンレートに対応しています。よって、アラートが発生する最大バーンレートの閾値は14.4となります。
その場合、例えば、SLOが93%の時のエラーバジェットは7%になります。ここで試しに、バーンレートが14.4のときのエラーレートを計算してみると、14.4 * 7 = 100.8 になります。基本的にエラーレートは、「エラーリクエスト/全てのリクエスト」によって算出されるため、エラーレートが100を超えることはありません。従って、SLOを93%と設定したときにバーンレートが14.4を超える事態を報告するアラートが発砲される可能性は0となります。
そのため、設定するSLOは94%以上を推奨しています。
おわりに
ここまで、私たちKINTOテクノロジーズのSREチームの取り組みについて紹介してきました。いかがでしたでしょうか。現状、組織全体として、非常に厳格なサービスレベル管理が求められているわけではありませんが、今回紹介した手法を用いて、手軽に有益なアラートを試せることに満足しています。
Platform Groupでは一緒に働ける仲間を募集しています。少しでも興味を持ったり話を聞いてみたいと思った方は、お気軽にご連絡ください!
関連記事 | Related Posts



We are hiring!
【クラウドセキュリティエンジニア】クラウドセキュリティG/東京・名古屋・大阪・福岡
ミッションクラウドセキュリティの専門組織として、KINTO テクノロジーズのマルチクラウド環境のセキュリティガバナンスに責任を持ちます。 セキュリティリスクを発生させない セキュリティリスクを常に監視・分析する セキュリティリスクが発生したときに速やかに対応する 業務内容ミッションを達成するために様々な業務を実施します。
【PdM】契約管理システム開発G/東京
契約管理システム開発グループについて契約管理システム開発グループは、クルマのサブスクリプションサービス『KINTO』(新車・中古車)を中心とした国内向けサービスにおいて、申込から契約満了(中途解約を含む)までの社内業務プロセスのシステム化と、契約状態の管理を担っています。


