Claude Code の高カーディナリティメトリクスを Grafana Managed Recording Rule × Prometheus × Thanos で捌く

0. はじめに
弊社では Claude Code を全社的に導入しており、Claude Code のメトリクスとログを OpenTelemetry で収集し、Grafana で可視化しています。ところがある日、こんな声が飛んできました。
「ダッシュボード、また固まってるんだけど」
社内に Claude Code を展開して、いざ「みんなどれくらい使ってる?」を可視化しようとしたら、開いたダッシュボードがくるくる回り続けて何も出てこない。タイムアウト。リロードしてもまた回る。
原因は Claude Code が吐く 1 つのメトリクス claude_code_token_usage_tokens_total でした。これがカーディナリティ爆発(カーディナリティについては後述)を起こして、Thanos Query のメモリで使い倒していました。
この記事は、その障害を Grafana Managed Recording Rule × Prometheus × Thanos の構成でどう捌いたか、の記録です。打ち手を 3 案で比較した話と、採用案で実際にハマった「書き込み先(write 先)問題」を 2 段階でほどいた話がメインです。同じように AI ツールの利用状況を可視化したい人、そして高カーディナリティに殴られた経験のある Observability 担当者の参考になればと思います。
1. 何が起きていたか:claude_code_token_usage_tokens_total のカーディナリティ爆発
Claude Code は OpenTelemetry 経由でトークン使用量などのメトリクスを出力できます。その中心が claude_code_token_usage_tokens_total です。
問題はラベルでした。このメトリクスには session_id が付きます。セッションごとにユニークな ID が振られるので、利用が増えれば増えるほど系列(time series)が線形に増え続ける。さらに user_email、model、type(input/output/cacheRead など)も掛け算で効いてくる。
claude_code_token_usage_tokens_total{
session_id="...", # ← セッションごとにユニーク。爆発の主犯
user_email="...",
model="claude-...",
type="output"
}
カーディナリティとは
メトリクスにおけるカーディナリティとは、あるラベルが取りうる値の種類数のことです。たとえば type ラベルの値が input・output・cacheRead の 3 種類しか振られなければカーディナリティは低い。一方 session_id のようにセッションごとに異なる値が振られるラベルは、セッションが増えるほど無限に種類が増えていく「高カーディナリティ」なラベルです。ラベルの組み合わせが時系列(time series)の数になるため、高カーディナリティなラベルが 1 つあるだけで系列数が爆発的に膨れ上がります。
session_id のような無限に増える値(unbounded label)が 1 つ混じるだけで、系列数は天井知らずになります。
そして Thanos Query は、クエリ時に対象系列をメモリ上に展開してから集計します。系列が数十万を超えてくると、sum by (user_email) のような一見シンプルな集計でもメモリを食い尽くし、タイムアウトか OOM で落ちる。ダッシュボードが固まっていた正体はこれでした。
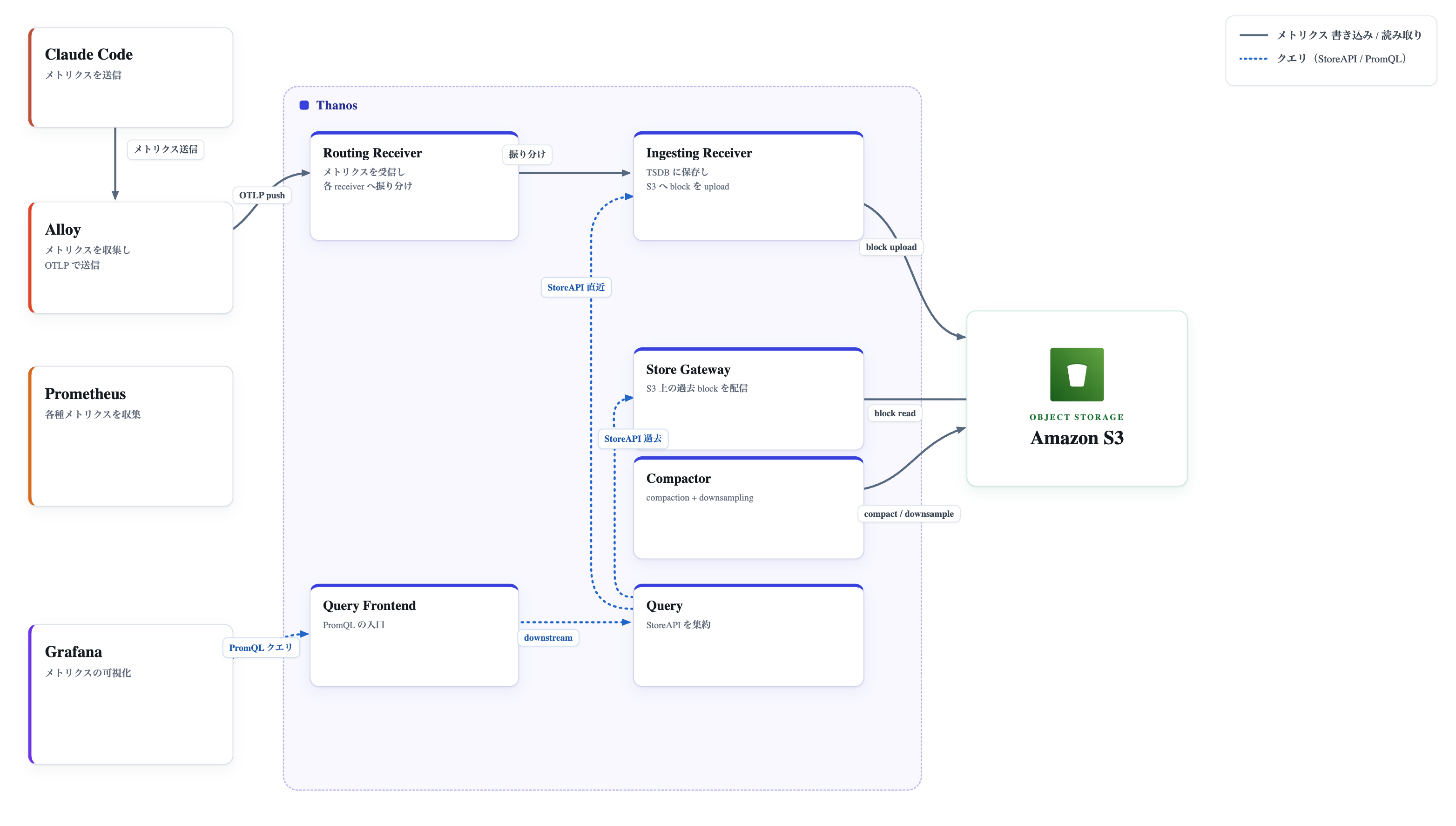
2. KTC のモニタリング基盤の構成
本題に入る前に、今回の話に登場するコンポーネントを整理します。
2-1. Alloy(OpenTelemetry Collector)
Grafana Alloy は OpenTelemetry ベースのコレクターです。KTC では各システムの AWS サービスのログやClaude Code からメトリクス・ログを収集する入口として機能しています。
2-2. Prometheus
Kubernetes 上のメトリクスを scrape する OSS の監視ツールです。KTC では scrape したメトリクスを Thanos Receiver への remote write で転送するリレー役を担っています。メトリクスの長期保存は Thanos に委ねる構成です。
2-3. Thanos
Prometheus をスケールアウト・長期保存対応させるための OSS です。KTC では以下のコンポーネントで構成しています。
| コンポーネント | 役割 |
|---|---|
| Routing Receiver | remote write の受口。hashring に従って Ingesting Receiver へルーティング |
| Ingesting Receiver | 実際の TSDB への書き込み。S3 へ flush |
| Store Gateway | S3 のブロックをクエリ可能にする読み取りゲートウェイ |
| Query | 実際にクエリーを実行するコンポーネント。 |
| Query Frontend | クエリのキャッシュ・スプリットを担当。Grafana からの入口 |
| Compactor | S3 のブロックを定期的に圧縮・ダウンサンプリング |
マルチテナント構成を採用しており、書き込み時は通常 THANOS-TENANT HTTP ヘッダーでテナントを指定します。
2-4. Grafana
Grafana は Thanos をデータソースとして接続し、ダッシュボードの描画と Recording Rule の管理を担います。KTC ではシステム単位でマルチテナント化した Grafana インスタンスを各チームに払い出しており、今回 Claude Code コスト可視化用に専用インスタンスを立ち上げました。
3. 課題とゴール
「じゃあ session_id を消せば終わりでは?」と思いますよね。でもそれが簡単に言えない理由がありました。
社内で AI 活用を進めるには、まず測れることが前提になります。誰がどれくらい使っているのか、どのモデルにトークンが寄っているのか、1 セッションあたりの規模感はどうか。こういう粒度がないと「活用が進んでいるのか」を語れない。
特に session_id 単位の分析は、後から「効果的な使い方をしているチームの傾向を見たい」みたいな分析に効いてきます。つまり生データとしての session_id は手元に残したい。でもダッシュボードのクエリでそのまま頑張るのは無理。この二つを両立させるのが今回のお題でした。
ゴールはこう整理できます。
- 生データ(
session_id付き)は Thanos に貯め続ける - ダッシュボードは「集約済みの軽いメトリクス」を見る
- 利用者がセルフサービスで見たい情報を見れるように調整ができること
4. 案比較
カーディナリティへの対象策はいくつかあります。今回は 3 案を並べて比較しました。
| 案 | やること | メリット | 採用/不採用の理由 |
|---|---|---|---|
| 案1: Alloy でラベルドロップ | 収集段階で session_id を捨てる |
一番手前で止められて確実 | 生データから session_id が消え、後の分析が永久にできなくなるため、今回は不採用 |
| 案2: Thanos Ruler | サーバ側の Recording Rule で集約 | 集約結果が Thanos に永続化される | ルールの Apply が Platform 側でのオペレーションのみになる運用を実施しているため、利用者とPlatformでのやりとりが増えて運用負荷が高いため、今回は不採用 |
| 案3: Grafana Managed Recording Rule | Grafana 側で集約ルールを定義し書き戻す | 利用者が UI で自分でルールを作れる | 生データを残しつつ、ルールの主権を利用者に渡せるため、 今回は 採用 |
判断の軸は 2 つでした。
- 生データを失わないか(
session_idを残せるか) - ルールを誰が育てられるか(利用者が回せるか)
案1 は軸1で不採用。収集段階で捨てるとデータ分析に利用できません。案2 は軸2で不採用。Thanos Ruler はサーバ側のルールファイルを Platform が管理する世界なので、「ちょっとこの集約を試したい」が毎回 Platform への依頼になってしまう。これは Platform チームのボトルネック化も招きます。
残った案3 が、両方の軸をクリアしました。
5. Remote Write 先問題を 2 段階で解いた
案3 を進める上でも課題がありました。Grafana Managed Recording Rule は「集約した結果をどこかに書き戻す」必要があります。メトリクスの管理に使っているThanosの場合はここがうまく設定できませんでした。
5-1. 詰まり1: Datasource に Thanos Receiver を直接指定できない
Thanosにおいて、メトリクスの書き込み先は Thanos Receiver であるので、 Grafana の Datasource で Thanos Receiver を指定することを考えました。
ところが Datasource として登録できませんでした。理由はこうです。
- Grafana の Datasource は基本的に Query(読み取り)系に対して作るもの
- Thanos Receiver は Write 専用で、Query を受け付けられない
- だから Receiver は Datasource として成立しない
ここで再検討した結果、既に別用途で使用していた Prometheus でした。Prometheus は Query も Write(remote write 受信)も両方できる。そこで Prometheus を Grafana の Datasource として指定することにしました。
- Grafana の Datasource → Prometheus(Query を受け付けらるので Datasource になれる)
- Recording Rule の書き戻し → Prometheus の
/api/v1/writeで受ける(※) - Prometheus が remote write で Thanos Receiver へ流す
という形にしました。Prometheus が「Query 窓口」と「Write の中継」を兼ねることで、Datasource 問題が解けました。
※ Prometheusはデフォルト設定では、Queryを受け付けられないので --web.enable-remote-write-receiver フラグを有効にし、外部から /api/v1/write でメトリクスを受け付けられる** にしています。
5-2. 詰まり2: マルチテナントへの書き込み(HTTP ヘッダーを操作できない)
次の壁はマルチテナントでした。Thanos Receiver はテナントを分けて受け取れますが、その振り分けは通常 HTTP ヘッダー(THANOS-TENANT) で指定します。
ところが Grafana Managed Recording Rule の設定項目には、書き戻し時の HTTP ヘッダーを差し込む設定がありません。ルールの式と書き戻し先は指定できても、ヘッダーは触れない。AI 活用用のテナントへ正しく振り分けたいのに、その手段が塞がれている状態でした。
解決には Thanos Receiver 側の機能を使いました。
thanos receive \
--receive.split-tenant-label-name="tenant_id"
--receive.split-tenant-label-name を指定すると、Receiver は HTTP ヘッダーではなくメトリクスのラベル値を見てテナントを振り分けてくれます。つまり、
- Recording Rule の集約結果に
THANOS-TENANT="ai-usage"のようなラベルを付けておく - Receiver がそのラベルを読んで AI 活用用のテナントへ流し込む
ヘッダーが操作できないなら、振り分けの判断材料をラベルに寄せる。発想を「ヘッダーで指定する」から「ラベルで宣言する」に切り替えたのがポイントでした。
5-3. 全体アーキテクチャ
2 つの詰まりを解いた結果、データの流れはこうなりました。まず全体像を俯瞰します。
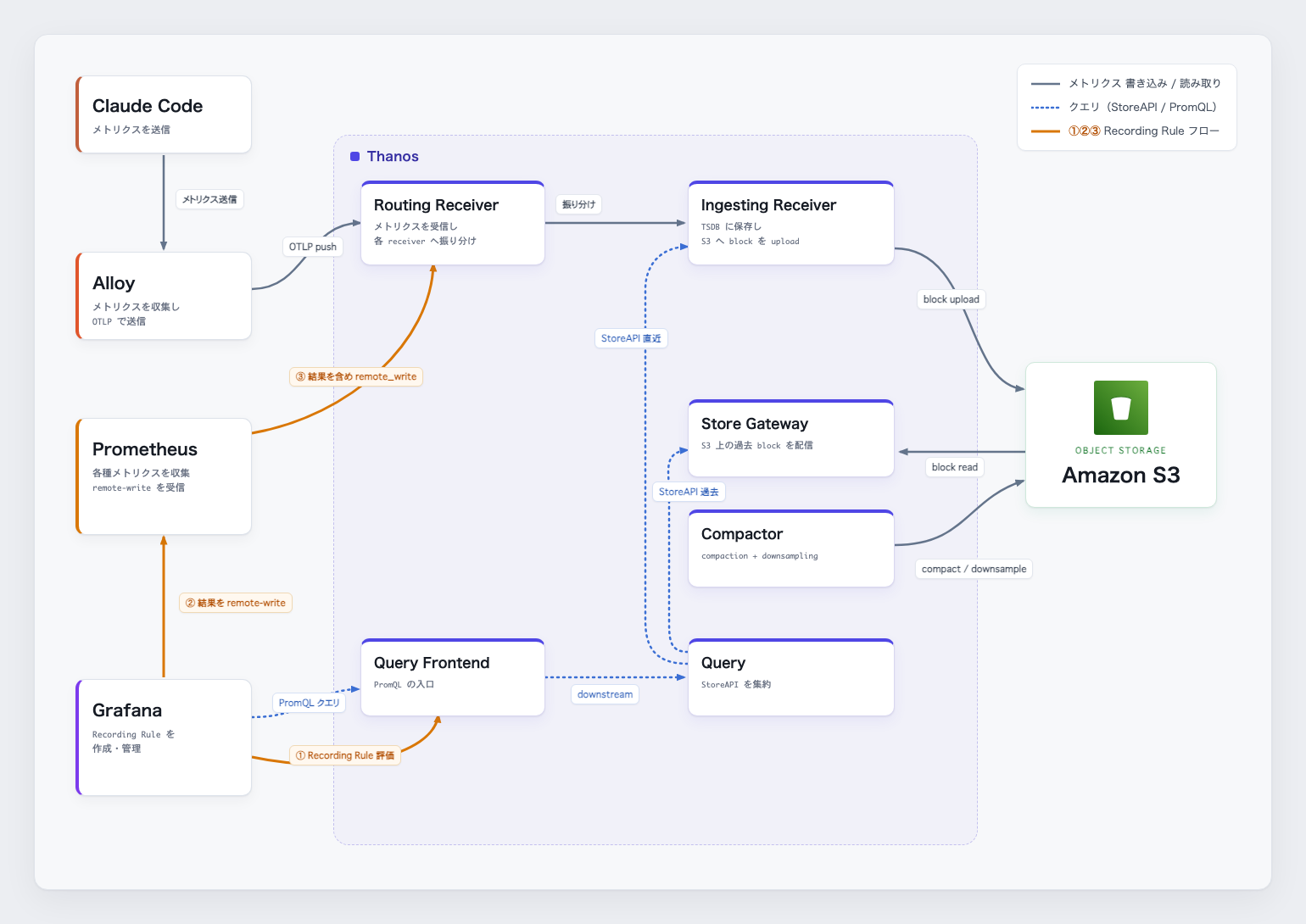
ポイントをまとめると:
- Prometheus が二役:Grafana からの write を受け取る
--web.enable-remote-write-receiverと、Thanos への転送(remote_write)を同時に担う - テナント振り分けはラベルベース:Routing Receiver の
--receive.split-tenant-label-name=THANOS-TENANTにより、Recording Rule で付けたTHANOS-TENANTラベルの値でテナントが決まる。HTTP ヘッダーを操作できない制約をラベルで回避した
6. Before / After:タイムアウトが消えた
検証段階での効果はシンプルです。
| 観点 | Before | After |
|---|---|---|
| ダッシュボード表示 | タイムアウト / 描画されない | 集約済みメトリクスを描画できる |
| Thanos Query への負荷 | 高カーデ系列をメモリ展開して OOM 級 | 集約済みの軽い系列を読むだけ |
session_id 単位の生データ |
残る | 残る(Thanos に蓄積継続) |
| 集約ルールの主権 | (案2なら Platform) | 利用者が UI で保持・編集 |
ダッシュボードが普通に開く、という当たり前を取り戻しつつ、生データも分析の主権も手放さずに済んだ、というのが今回のゴールでした。
7. まとめ
今回やったことを、次に同じ状況に出会った人が調査・検討できる粒度で残しておきます。
- 無限増殖するラベル(
session_id等)はカーディナリティ爆発の主犯。 - 生データを収集段階で捨てる前に「後の分析で使うか」を問う。Alloy でのドロップは確実だが取り返しがつかない
- Thanos Receiver は Write 専用なので Datasource にできない。Query も Write もできる Prometheus を中継に挟む
- Grafana Managed Recording Rule は書き戻し時に HTTP ヘッダーを操作できない。テナント振り分けは
--receive.split-tenant-label-nameでラベルベースに寄せる
ここまで読んでいただきありがとうございました!
関連記事 | Related Posts




We are hiring!
Cloud Engineer(トヨタグループ内製化支援)/Cloud Infrastructure G/東京・名古屋・大阪・福岡
トヨタグループのクラウド活用を、最前線で支える。1社にとどまらないスケールで、移行・生成AI・内製化まで幅広く挑戦できるポジションです。
【データサイエンティスト】データサイエンスG/東京・大阪・名古屋・福岡
デジタル戦略部についてデジタル戦略部は、現在45名の組織です。

